夜雨聆风
夜雨聆风





12行Python 代码搞定 Excel 分时段求和!告别加班,财务/运营人手必备
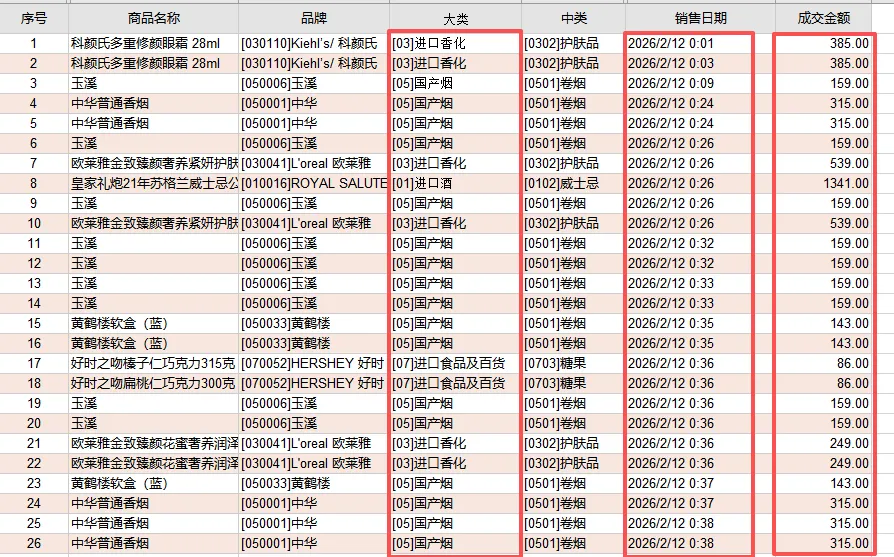
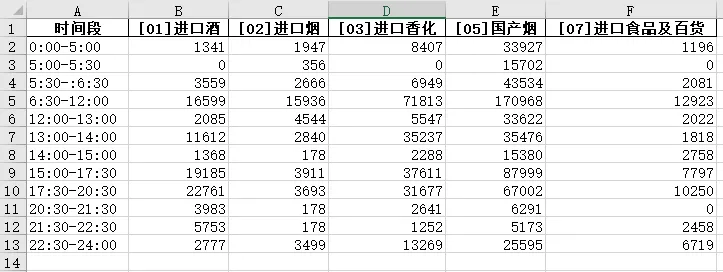
import pandas as pddf = pd.read_excel(r"E:\123123123.xlsx",sheet_name="Report")df = df.dropna(subset="大类")df['时间'] = pd.to_datetime(df.loc[:, "销售日期"], errors='coerce')df['总分钟数'] = df['时间'].dt.hour * 60 + df['时间'].dt.minutebins = [0, 300, 330,360,720,780, 840, 900, 1050,1230,1290,1350,1440]labels = ['0:00-5:00', '5:00-5:30', '5:30-:6:30', '6:30-12:00','12:00-13:00', '13:00-14:00','14:00-15:00','15:00-17:30','17:30-20:30','20:30-21:30','21:30-22:30','22:30-24:00']df['时间段'] = pd.cut(df['总分钟数'], bins=bins, labels=labels)result = pd.pivot_table(df,index="时间段",columns="大类",values="成交金额",aggfunc='sum').reset_index()result.to_excel(r"E:\123123123_汇总后.xlsx",index = False)
import pandas as pddf = pd.read_excel(r"E:\123123123.xlsx",sheet_name="Report")df = df.dropna(subset="大类")
df['时间'] = pd.to_datetime(df.loc[:, "销售日期"], errors='coerce')df['总分钟数'] = df['时间'].dt.hour * 60 + df['时间'].dt.minutebins = [0, 300, 330,360,720,780, 840, 900, 1050,1230,1290,1350,1440]labels = ['0:00-5:00', '5:00-5:30', '5:30-:6:30', '6:30-12:00','12:00-13:00', '13:00-14:00','14:00-15:00','15:00-17:30','17:30-20:30','20:30-21:30','21:30-22:30','22:30-24:00']df['时间段'] = pd.cut(df['总分钟数'], bins=bins, labels=labels)
result = pd.pivot_table(df,index="时间段",columns="大类",values="成交金额",aggfunc='sum').reset_index()result.to_excel(r"E:\123123123_汇总后.xlsx",index = False)