 夜雨聆风
夜雨聆风





代码是副产品:AI Coding 时代,真正的源码变了
最近在读 Stanford 的 AI 编程课程,有一篇阅读材料,引发了我的思考和关注。
文章的题目叫《Specs Are the New Source Code》,作者是 Ravi Mehta 和 Danny Martinez。观点很简单,但说透了会让人不太舒服:在 AI Coding 的时代,代码正在变成一种副产品。真正的源码,是你写的那份 Spec。
我想用自己的语言把这件事再说一遍,因为它影响的不只是产品经理,也在影响每一个写代码的人。
先说清楚 Vibe Coding 是什么
Vibe Coding 是一种新的编程方式:你把需求描述给 AI,AI 生成代码,你看结果、调整方向、继续迭代。写代码这件事本身,变成了一个被 AI 大量承担的环节。
举个你可能已经在做的事:用 Claude Code 或者 Codex 描述一个功能,五分钟后 AI 给你一个可以跑的版本;不满意就改 Prompt 再跑一次;跑通了就继续往前走。这个过程里,你几乎不直接写代码,但你是整个过程的导演。
这件事带来的变化,比很多人意识到的要深。
代码变便宜了,但不是所有东西都变便宜了
当代码可以在几分钟内生成,当你不满意可以随时扔掉重来——代码的边际成本开始无限接近于零。
这不是说代码不重要了。运行着的代码当然重要。但生产一行代码的成本已经不再是瓶颈。以前你要花几天写一个功能,现在可能几个小时就有了。
那瓶颈在哪?
在于你到底想要什么,以及你能不能把”想要什么”说清楚。
Spec 为什么成了新的源码
原文提出了一个概念叫 Lossy Projection(有损投影),我觉得这是全文最有价值的一个洞察。
代码是你意图的一次有损压缩。它告诉你”做了什么”,但不告诉你”为什么这么做”、“边界条件是什么”、“什么情况下算成功”。代码里没有上下文,没有决策理由,没有你和用户之间的那些对话。
写完的代码是静态的,它记录的是一个历史时刻。
而一份好的 Spec 不一样。它包含了意图、方法、验收标准,以及做决策时的上下文。它不只能生成代码,还能生成文档、测试用例,甚至能在三个月后帮你回忆起”当时为什么这么设计”。
换句话说,代码是从 Spec 里生成出来的,而不是反过来。丢掉代码可以重新生成,但如果你丢掉了那份 Spec,你就真的丢掉了那个决策本身。
这是为什么说 Spec 是新的源码:它才是那个不可再生的东西。
工作流变了
原文对比了新旧两种开发流程,我觉得值得原文照搬一遍:
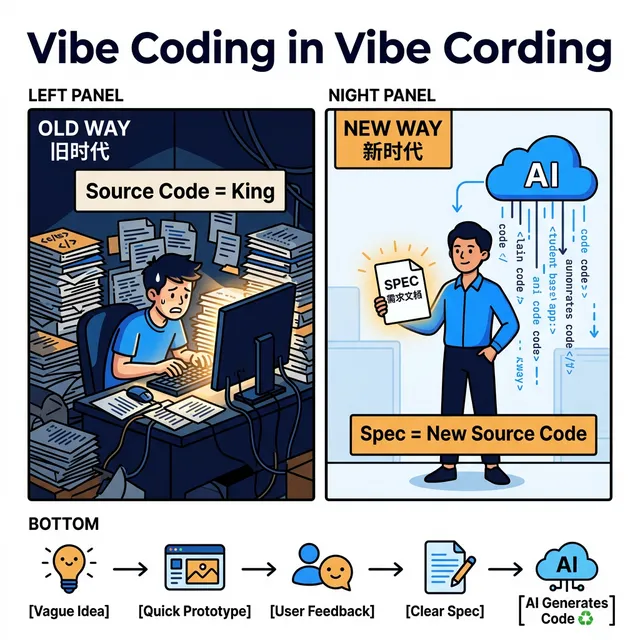
旧的流程:模糊想法 → 线框图 → 设计稿 → 工程师构建 MVP → 客户反馈 → 痛苦的 Spec 修改 → 重构 → 祈祷。
新的流程:模糊想法 → 快速原型 → 客户反馈 → 清晰的 Spec → AI 辅助实现。
注意这里有个根本性的顺序翻转。
以前,你要在拿到真实用户反馈之前,就写清楚所有需求。这很难,因为你在用假设驱动开发,Spec 写出来大概率有很多地方是错的。
现在,你可以先用 AI 快速做出一个能跑的东西,拿去跟真实用户碰,再根据真实反馈写 Spec。Spec 变成了一个输出,而不只是输入。 你是在用验证过的认知去写需求,而不是在黑暗中猜测。
这不只是快了一点,这是本质的不同。
谁会在这个变化里变得更值钱
原文有一句话说得很直接:
在不久的将来,沟通最有效的人就是最有价值的程序员。
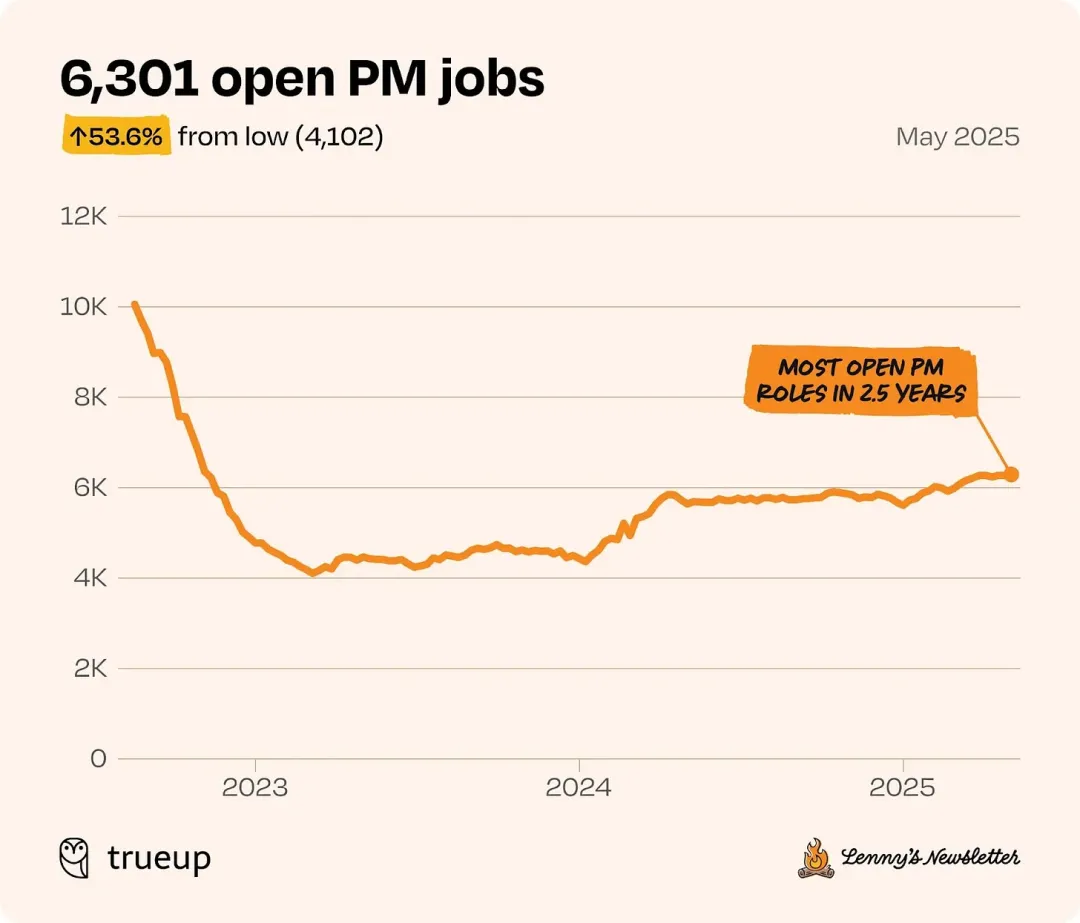
这句话值得停下来想一下。事实上,这一趋势已经有数据在验证了:PM 的需求并没有因为 AI 而减少,反而在增长——因为工程交付速度上去了,“说清楚要做什么”这件事的瓶颈就更突出了。
以前,程序员的核心价值是把想法转化成代码的能力。这件事现在正在被 AI 大量承担。但有一件事 AI 还做不了:理解用户真正想要什么,并且把这个”想要什么”清晰地表达出来。
这正是 Spec 在做的事。一份好的 Spec 的前提,是你真的搞懂了用户的问题——不是表面上的需求,而是背后的真实动机。
所以有意思的事情发生了:以前被认为是”软技能”的能力——理解需求、定义问题、表达清楚——变成了这个时代最硬的硬技能。
这对工程师的影响可能比看起来更大。以前你可以用”我不太会表达,但我代码写得好”来站立。现在这个护城河正在变窄——因为”代码写得好”只是执行层面,而执行层越来越多地被 AI 接管了。
写好一份 Spec,需要什么
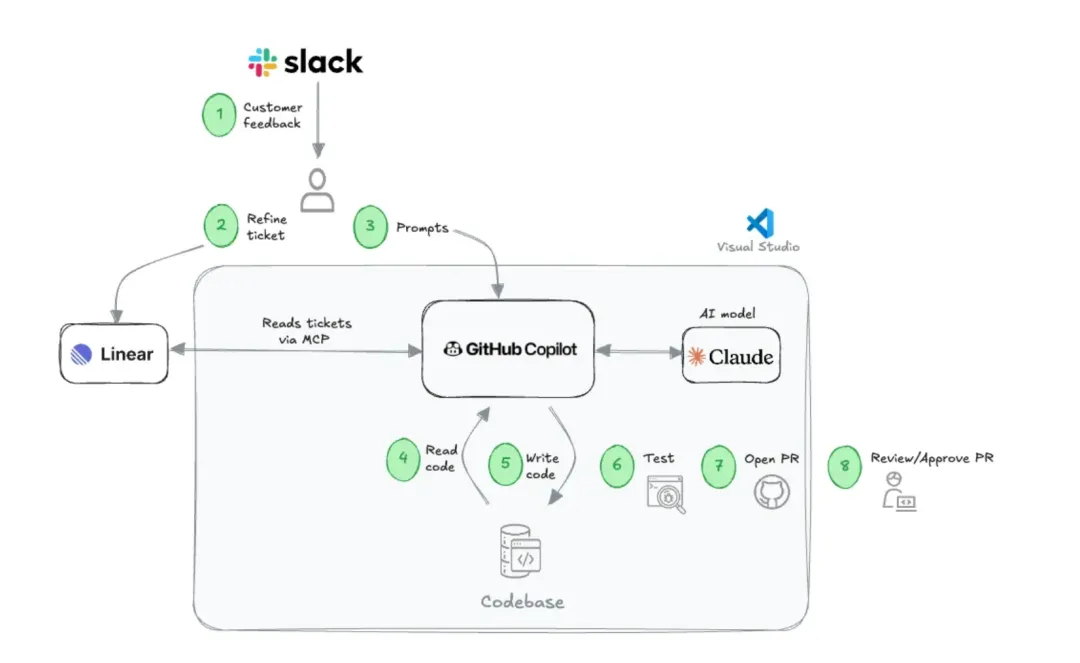
文章里分享了一个实践案例。非技术人员通过自己写 Spec,直接让 AI 修改代码库、开 PR,然后等资深工程师审核。这个流程能跑起来,靠的是三个前提条件:
具体性(Being Specific):模糊的 Spec 会直接导致代码库混乱。“做一个更好用的搜索”这种描述给 AI 是没有用的。你要能说清楚:搜索结果按什么排序、什么情况下返回空、边界输入怎么处理。
选择性(Being Selective):目前这套方式适合边界清晰的任务。越复杂、越需要对整体架构有深度理解的任务,仍然需要专家介入。知道”这件事可以交给 AI”和”这件事不能交给 AI”本身,就是一种判断力。
把关制(Gatekeeping):AI 生成的代码必须由有能力的人审核。这不是不信任 AI,这是任何负责任的工程实践的基本要求。
写好一份 Spec,某种程度上,就是把你对一个任务的理解精确地外化出来。这件事本身就是一种能力,不是每个人都能做。
理解工作的价值在上升
文章里有一段引言,我想原文引进来:
如今,AI 带来的收益极度不均。有些领域——如生成代码、文本、图像——已经实现了量子飞跃,正以”AI 速度”运行;而另一些领域——如与用户沟通、挖掘需求——仍停留在”人类速度”。这种不均衡正在重塑团队。关注的焦点正从执行工作转向理解工作。
“理解工作”和”执行工作”——我觉得这是这篇文章最值得记住的一对概念。
执行工作:把需求转化成代码,把设计转化成界面,把草稿转化成完整文档。这些事 AI 正在快速接管。
理解工作:搞清楚用户真正的问题是什么、什么方案值得做、为什么这么设计。这些事还停留在人类速度。
当执行被自动化,理解的稀缺性就会凸显出来。 能把”模糊的想法”变成”精确的 Spec”的人,他的工作很难被替代——因为那份精确本身,来自于他对问题的深度理解。
我现在怎么做
说说实践层面。我个人现在每次开始一个 AI 编程任务,第一件事不是写代码,而是写一份短文档,通常包括:
- 这个任务要解决的问题是什么
- 预期的方案思路
- 什么情况下算做完了(验收标准)
- 哪些地方是边界,不要碰
这件事以前我只是有时候做、随手做。现在我把它当成每次任务的强制步骤。
原因不是仪式感,而是我发现它确实有效。写清楚的任务 AI 完成得好,写模糊的任务经常要反复修正。长期下来,这份文档积累起来的,其实是我对这个项目最精确的认知外化。
代码可以推翻重写,那份文档扔了就真的没了。
最后
Vibe Coding 是真实正在发生的变化,不是科幻。工具在变,流程在变,有价值的东西的定义也在变。
代码变成了副产品——这不是贬低代码,而是说生产代码这件事的门槛大幅降低了,而真正贵重的部分向上移了一层:你怎么定义问题,你怎么描述需求,你怎么知道什么算”做对了”。
这是新的源码。
