 夜雨聆风
夜雨聆风





用 MCP 给 AI 编辑器接上"外挂":Figma、数据库、浏览器全打通
为啥?因为它「看不到你的设计稿、连不上数据库、也没法打开浏览器帮你验证页面」。它就像一个高手被关在小黑屋里,你说啥它都能回答得头头是道,但让它真正动手做事?抱歉,手脚被绑着呢。
今天要聊的 MCP,就是来「给 AI 松绑」的。
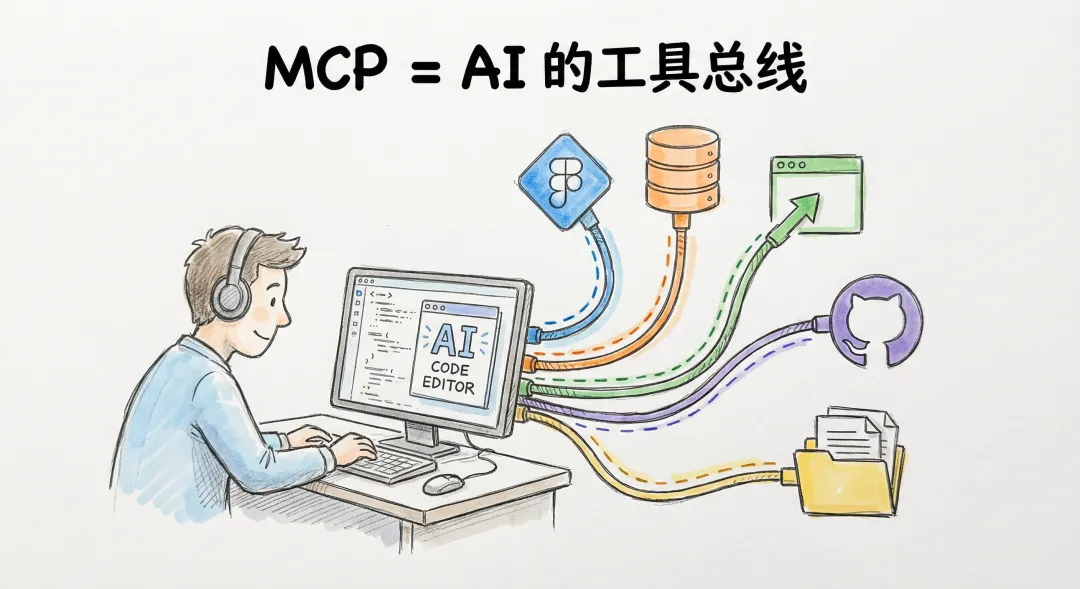
先说说 MCP 到底是啥
MCP,全称 Model Context Protocol(模型上下文协议)。名字很唬人,但本质很简单——
「它就是 AI 世界的 USB-C 接口。」
你想啊,以前我们的手机充电线、数据线一堆,安卓一个头、苹果一个头、耳机又一个头。后来 USB-C 统一了,一根线搞定所有。
MCP 干的就是这个事儿:以前 AI 编辑器想接 Figma 得写一套适配,想接数据库又得写一套。每接一个新工具,就要重新搞一遍对接。太累了。
MCP 说:「大家别各搞各的了,来,我定一个标准协议,你们都按这个格式来,一次接入到处能用。」
所以现在,不管你用 Cursor、Claude Desktop、VS Code 还是别的 AI 工具,只要它支持 MCP,就能用同一套 MCP Server 来接入 Figma、GitHub、数据库、浏览器……
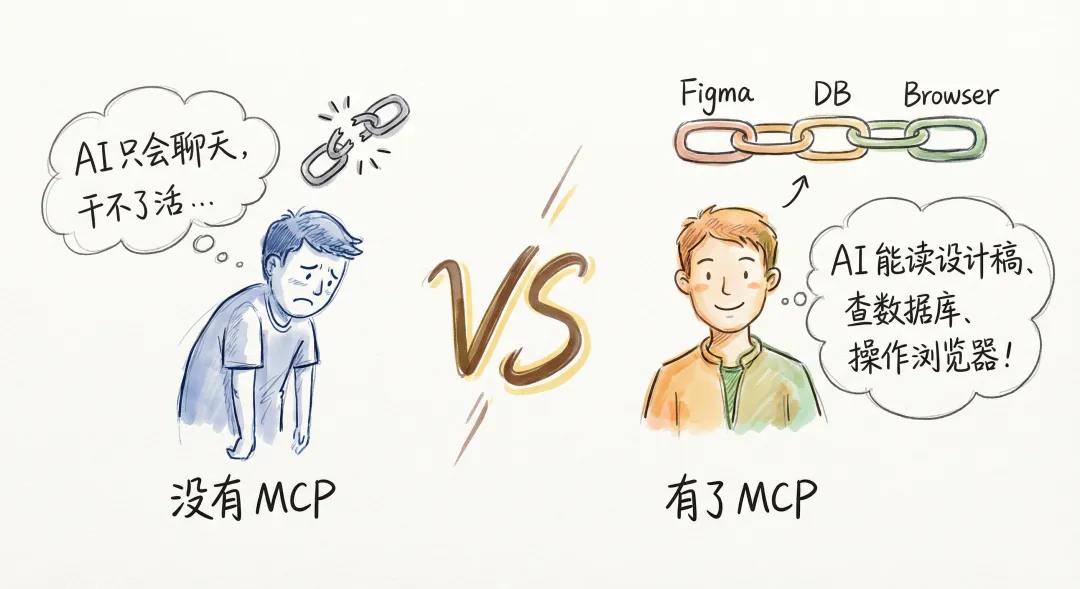
Skills 和 MCP 是什么关系?
上篇讲的 Skills 和这篇讲的 MCP,刚好是一对搭档:
- 「Skills 决定 AI “会不会做”」
——你教它团队规范、编码习惯、工作流程 - 「MCP 决定 AI “能不能拿到东西去做”」
——你给它接上工具、数据、外部系统
打个比方:Skills 像是你给新同事写的”入职手册”,MCP 像是你帮他开通了代码仓库权限、设计工具账号、数据库访问权……光有手册没权限,啥也干不了。光有权限不看手册,干出来的活不对味。
「两个一起配,才是完整的 AI 搭档。」
MCP 怎么工作的?3 个角色先搞懂
别被”协议”俩字吓到,MCP 的架构其实特别好理解。就三个角色:
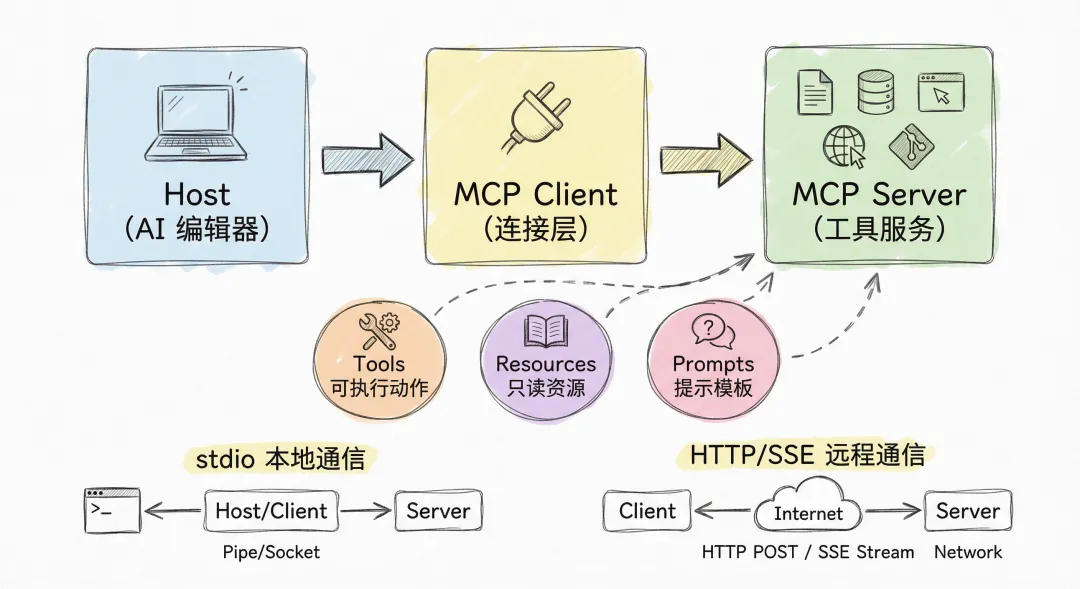
「1)Host(宿主)—— 就是你的 AI 编辑器」
比如 Cursor、Claude Desktop、VS Code + Copilot。它是你直接交互的那个”壳”,负责接收你的指令,也负责把结果展示给你。
「2)MCP Client(客户端)—— 藏在 Host 里的”连接层”」
你看不到它,但它在后台默默工作。每当 Host 需要调用外部工具时,就是 Client 在帮你”打电话”给对应的 Server。
「3)MCP Server(服务端)—— 真正干活的那一方」
比如 Filesystem Server 负责读写文件,GitHub Server 负责查 issue 和 PR,Playwright Server 负责操控浏览器。每个 Server 就是一个”专项能力包”。
整个流程就是:
「你提需求 → Host 判断需要啥能力 → Client 去调对应的 Server → Server 返回结果 → Host 展示给你」
是不是有点像前端的微服务架构?Host 是 BFF 网关,Server 是各个后端微服务。设计思路就是「解耦」——每个 Server 独立部署、独立维护,想加就加、想换就换。
MCP Server 能提供哪三类东西?
每个 MCP Server 可以对外提供三类能力,但你日常开发最常用的主要是前两个:
「Tools(工具)—— 能”做”事情」
这是最核心的。比如:
-
查一下仓库最近的 open issues -
在数据库里跑一条 SELECT 查询 -
打开浏览器、点击按钮、截个图 -
读取 Figma 设计稿里某个组件的间距和色值
这些都是”动作”,AI 通过调用 Tool 来完成具体操作。
「Resources(资源)—— 能”看”东西」
只读的数据源。比如项目文档、配置文件、知识库片段。AI 可以读取但不会修改。
「Prompts(提示模板)—— 固化的常见流程」
比如你经常让 AI “帮我 review 这段代码,按安全性、性能、可读性三个维度打分”,这种高频指令可以做成一个 Prompt 模板,下次一键调用。
「新手建议:先把 Tools 用熟,Resources 用到了再学,Prompts 锦上添花。」
两种传输方式,怎么选?
MCP 底层用的是 JSON-RPC 2.0 来通信,但你不用管这个细节。你只需要知道有两种连接方式:
「stdio(本地模式)—— 适合个人开发」
就是本地启一个进程,通过标准输入输出通信。配置简单,启动快,适合你一个人在本地搞开发。
「HTTP/SSE(远程模式)—— 适合团队共享」
Server 跑在远程服务器上,多人共用。适合团队场景,比如大家共享同一个 Figma Server、同一个数据库 Server。
「我的建议:先 stdio 跑通,确认好使了,再考虑要不要上远程。」 别一上来就整复杂架构,先把流程验证了再说。
实操:30 分钟跑通你的第一个 MCP
说了一堆原理,该动手了。我给你一套”傻瓜式”上手路径,照着走就行。
第一步:先挑 2 个最有用的 Server
别贪多,新手先接两个就够了:
- 「Filesystem」
—— 让 AI 能安全地读写你的项目文件 - 「GitHub」
—— 让 AI 能看 PR、查 Issue、了解仓库动态
为啥是这俩?因为它们覆盖了你最日常的场景:写代码要读文件、协作开发要看 GitHub。投入产出比最高。
第二步:配置 MCP Server
不同编辑器的配置文件位置不太一样,但格式基本类似。以 Cursor 为例,你需要在项目根目录或全局配置里加上类似这样的内容:
{"mcpServers":{"filesystem":{"command":"npx","args":["-y","@modelcontextprotocol/server-filesystem","/你的项目路径"]},"github":{"command":"npx","args":["-y","@modelcontextprotocol/server-github"],"env":{"GITHUB_TOKEN":"你的 GitHub Token"}}}}几个注意点:
-
路径和 Token 不要硬编码到代码里,用环境变量管理 -
先配一两个,跑通了再加别的 -
不确定的参数,看看对应 Server 的 README,写得都很清楚
第三步:用 3 个小任务验证连通性
配完了别急着搞大项目,先用几个简单任务确认 MCP 是不是真的通了:
-
试试说:”帮我列出当前项目 src 目录下的所有文件”(验证 Filesystem) -
试试说:”帮我看一下这个仓库最近 5 个 open 的 issue”(验证 GitHub) -
试试说:”读取 package.json 里的 dependencies 列表”(验证文件读取)
3 个都能正常返回结果?恭喜,你的 MCP 已经跑通了!
第四步:逐步扩展,接更多 Server
跑通了基础的之后,按需加入更多能力:
- 「Playwright / Browser」
—— 让 AI 帮你自动化测试、回归验证、截图对比 - 「Figma」
—— 让 AI 读设计稿参数,减少”设计还原”来回沟通 - 「数据库(PostgreSQL / MySQL / SQLite)」
—— 让 AI 帮你查表结构、验证 SQL - 「Fetch / HTTP 类」
—— 让 AI 帮你调试接口、验证响应格式
第五步:把高频动作固化成工作流
当你接了好几个 Server 之后,有些操作链路会变得很常见,比如:
「需求来了 → 读 Figma 设计稿 → 生成页面骨架代码 → 启动浏览器验证 → 提交 PR 并写好说明」
这个时候就可以配合上篇讲的 Skills,把这条链路写成一个标准流程。AI 知道”该做什么”(Skills),也知道”怎么拿到东西去做”(MCP),两者一配合,效率直接起飞。
GitHub 上那么多 MCP 项目,怎么挑?
你去 GitHub 搜 MCP,一搜一大堆。光 awesome-mcp-servers 这类清单就好几个,里面收录了几千个 Server。看着眼花缭乱,到底怎么选?
我给你一套实战筛选法:
「第一步:先看清单找方向」
推荐从这些聚合仓库入手:
- 「wong2/awesome-mcp-servers」
(带网页版,方便搜索筛选) - 「TensorBlock/awesome-mcp-servers」
(7000+ 收录,分类最全) - 「modelcontextprotocol 官方组织」
(官方参考实现,最靠谱)
清单适合”逛街”,帮你发现有哪些可能有用的 Server。
「第二步:用 4 个指标判断靠不靠谱」
找到感兴趣的 Server 后,别急着装,先看 4 个东西:
- 「最近更新时间」
—— 超过 3 个月没更新的,慎用 - 「README 完整度」
—— 安装步骤、权限说明、参数文档齐不齐 - 「是否支持你的编辑器」
—— 有些 Server 只适配了特定客户端 - 「Issue 区」
—— 有没有大量未解决的 bug 或兼容性问题
这 4 个都 OK 的,基本就能放心试了。
「第三步:按这个流程接入」
每次接一个新 Server,都走一遍这个标准流程:
-
本地 stdio 模式启动 -
配到编辑器的 mcpServers里 -
用 3 个小任务验证(读、查、做) -
加权限限制(目录白名单、只读账号等) -
跑稳了再推给团队
「靠谱的团队不是追新最快的,而是把每一步都跑稳了再往前走。」
前端团队最常用的 MCP 有哪些?
聊了这么多,到底哪些 MCP Server 对前端开发最有用?我按使用场景整理了一份清单,按优先级排序:
|
|
|
|
|---|---|---|
|
|
「Filesystem」 |
|
|
|
「GitHub / Git」 |
|
|
|
「Playwright / Browser」 |
|
|
|
「Figma」 |
|
|
|
「PostgreSQL / MySQL / Supabase」 |
|
|
|
「Notion / Confluence」 |
|
|
|
「Fetch / HTTP 工具类」 |
|
「如果你只能先接一个,选 Filesystem。如果能接两个,加上 GitHub。」 这俩覆盖了 80% 的日常场景。
另外特别说一下 「use-mcp」,这是 MCP 官方出的一个 React Hook,专门给前端项目用的。如果你在自己的 AI 产品里想接入 MCP 能力,三行代码就能搞定:
import { useMcp } from'use-mcp/react'functionMyAIApp() {const { tools, callTool, state } = useMcp({url: 'https://your-mcp-server.com',clientName: 'My App', })// state === 'ready' 说明连接成功,tools 里就是可用的工具列表// callTool('search', { query: 'xxx' }) 调用具体工具}GitHub 仓库:https://github.com/modelcontextprotocol/use-mcp
如果你在做 AI 相关的前端产品,这个 Hook 值得收藏。
避坑指南:MCP 很香,但要带护栏用
MCP 是好东西,但用不好也会翻车。这几个坑是我自己踩过的,提前帮你避开:
1. 权限一定要收紧
「文件系统不要给根目录访问。」 你以为 AI 只会读 src/,结果它可能顺手去看了 .env 里的密钥。给 Filesystem Server 配目录白名单,只开放项目相关的路径。
「数据库一定用只读账号。」 至少在前期验证阶段,别给 AI 写权限。万一 AI 理解错了你的意思,一条 DELETE 下去可不是闹着玩的。
2. 先让 AI “只看不动”
新接入任何一个 Server,都建议先观察 1-2 周:让 AI 只做查询、读取类操作,确认它理解得对、返回的数据准确。稳定了再慢慢开放写入权限。
「就像新来的实习生,先让人家看看代码、了解了解业务,别上来就让人改线上代码。」
3. 关键操作加个”确认开关”
删文件、改配置、跑数据库迁移、批量替换……这些操作一旦搞错就很难回头。建议在 AI 编辑器里开启”关键操作需确认”的选项(大多数编辑器都支持)。
「自动化是好事,但”自动事故”不是。」
4. 记好日志,出了问题能回溯
至少记录这几样:
-
谁触发了什么工具 -
输入参数是什么 -
输出了什么结果 -
有没有报错
这不是强迫症,是出了问题能帮你 5 分钟定位根因,而不是一脸懵地排查一下午。
总结
MCP 不是什么高深的新概念,它本质上就是在做一件事:「把 AI 编辑器从”只会说”变成”能动手”。」
在这之前,AI 编辑器是一个”学富五车但手脚被绑”的高手——你问它什么都知道,但让它实际去读个设计稿、查个数据库、验证个页面?做不到。
MCP 就是来解绑的。接上 Filesystem,AI 能操作你的项目文件。接上 GitHub,它能帮你看 PR 和 issue。接上 Playwright,它能帮你跑自动化测试。接上 Figma,它能直接读设计稿里的参数……
如果你已经在用 AI 写代码了,MCP 基本是你的”下一步必修课”。
「建议你今天就做一件小事:在你的编辑器里配一个 Filesystem Server,然后让 AI 帮你列出项目目录结构。」 就这么简单的一步,你就能直观感受到 MCP 带来的变化。
想要快速上手,这几个资源值得收藏:
- 「MCP 官方文档」
:https://modelcontextprotocol.io - 「官方 GitHub 组织」
:https://github.com/modelcontextprotocol - 「use-mcp(React Hook)」
:https://github.com/modelcontextprotocol/use-mcp - 「awesome-mcp-servers(清单)」
:https://github.com/wong2/awesome-mcp-servers
下一篇我们接着聊系列的第三篇:「Context 工程——如何把正确的上下文喂给 AI」,把”AI 搭档”这条路继续走下去。
