 夜雨聆风
夜雨聆风





理解分词:NLP 中的 BPE、WordPiece 和 SentencePiece
分词(Tokenization)是自然语言处理(NLP)中一个基础性的预处理步骤,它在原始文本和机器学习模型之间搭建了一座桥梁。这个过程将文本拆解成更小的单元,称为词元(tokens),随后将这些词元转换为数字化的标识符(IDs)。这些标识符作为大语言模型(LLMs)的输入,最终被映射为嵌入(embeddings)——也就是能够捕捉语义信息的向量表现形式。选择什么样的分词方法,对大语言模型的性能和效率都有着至关重要的影响。
在本文中,我们将深入探讨三种主流的子词分词算法:字节对编码(BPE)、WordPiece 和 SentencePiece。每种算法都采用独特的方式将文本分割成词元,而理解它们的运作机制、优势及局限性,对于构建高效的 NLP 工作流程至关重要。以上分词方法解决了这篇文章所带来的问题。
1. 什么是分词?
分词是将非结构化的原始文本,转化为机器学习模型能够理解的结构化格式的过程。其核心在于,将一段文本——无论是一个句子、一个段落还是一篇文档——切分成更小、更易于处理的单元,这些单元被称为”词元”。根据所采用的分词策略,这些词元可以是单词、子词,甚至是单个字符。
分词完成后,每个词元都会被赋予一个来自预定义词表的数字化标识符(ID),从而将文本转换为一串数字序列。
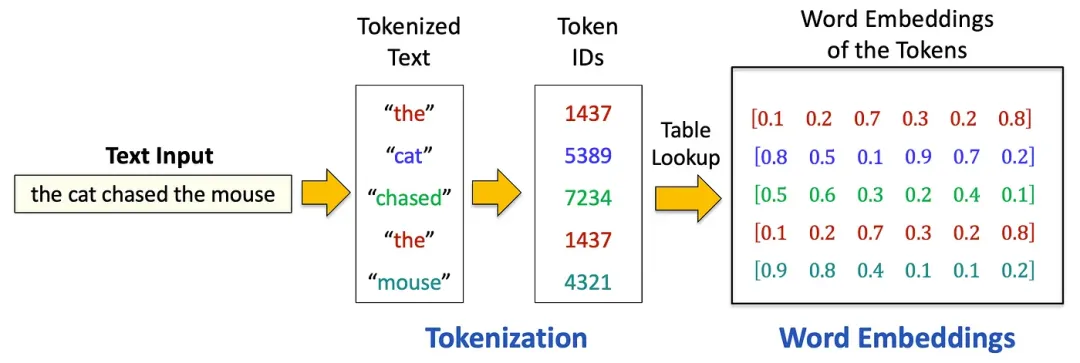
接下来,通过查表操作,从一个预训练的嵌入矩阵中,为每个词元 ID 提取出对应的词嵌入——也就是稠密的向量表示。这些嵌入向量捕捉了词元的语义信息,使得模型能够理解词语之间的关系,例如识别出”猫”和”小猫”之间的相似性。这个过程是 NLP 任务的基石,它赋予了模型处理和生成人类语言的能力。
2. 分词的几种类型
根据生成词元的粒度粗细,分词策略也各不相同。主要有三种类型:字符级、单词级和子词级分词。每种方法都有其优缺点,具体选择取决于 NLP 任务的实际需求。
2.1 字符级分词
在字符级分词中,文本被切分成单个的字符。例如,句子“low lower lowest”会被切分成 [“l”, “o”, “w”, “ ”, “l”, “o”, “w”, “e”, “r”, “ ”, “l”, “o”, “w”, “e”, “s”, “t”]。每个字符(包括空格)都是一个词元。
优点:
-
• 能很好地处理生僻词或词汇表外的词,因为所有可能的字符都已经包含在词表中了。 -
• 对于词形变化复杂,或者词语边界不清晰的语言(如中文、日文)很有用。 -
• 相比单词级分词,词表规模小得多。
缺点:
-
• 生成的序列会非常长,这会增加模型的计算负担。 -
• 丢失了单词级别的语义信息,让模型更难捕捉词与词之间的关系。
2.2 单词级分词
在单词级分词中,文本被切分成独立的单词。用同样的例子,句子“low lower lowest”会被切分成 [“low”, “lower”, “lowest”]。每个完整的单词就是一个词元;词表必须包含单词的所有形态。
优点:
-
• 保留了单词级别的语义,让模型更容易理解词语之间的关系。 -
• 相比字符级分词,生成的序列更短,计算开销也更小。
缺点:
-
• 难以处理生僻或未见过的词,这就是常说的”未登录词”问题。模型通常会用特殊的”UNK”(未知)标记来代替它们,导致信息丢失。 -
• 词表规模会变得非常庞大,特别是在处理形态丰富的语言或特定领域的专业术语时,这会增加模型的复杂度。
2.3 子词级分词
子词级分词在字符和单词级方法之间找到了一个平衡点。它将单词拆分成更小的单元,比如前缀、后缀或其他有意义的子词组件。
例如,句子“low lower lowest”的子词级分词结果可能是 [“low”, “low”, “er”, “low”, “e”, “s”, “t”]。可以看到,子词 “low” 在三个单词中被重复使用。相比单词级分词,这大大缩小了词表规模。流行的子词分词算法包括字节对编码、WordPiece(用于 BERT 模型)和 SentencePiece。
优点:
-
• 平衡了字符级和单词级分词的优缺点:比单词级分词更能优雅地处理未登录词,同时又比字符级分词生成的序列更短。 -
• 捕捉了词形信息,这对于处理单词结构复杂的语言非常有用。 -
• 在保留一定语义的同时,减小了词表规模。
缺点:
-
• 需要仔细调参,避免子词切分得过于细碎或不够细。 -
• 对于词边界不那么清晰的语言,仍然可能会引入一些歧义。
3. 字节对编码
BPE 是一种子词分词算法。它通过反复合并最常见的字符或子词对,来构建词表。这种方法的好处是:常见的单词保持完整,而生僻词则被拆成更小的子词单元,这样既能高效处理未知词,又不会让序列长度变得太长。BPE 最早用于数据压缩,后来被 OpenAI 改造,用在了 GPT 这类模型中。
BPE 一个很关键的优点是能最大限度地减少或避免 “UNK”(未知)标记的出现,这种标记对模型性能是有害的。当模型遇到词表里没有的词时,就会出现 UNK,这会导致:
-
• 信息丢失:模型会丢掉与这个词相关的所有上下文和含义。 -
• 语言表达低效:过多的 UNK 标记会干扰模型对输入的理解。 -
• 泛化能力差:如果 UNK 标记太多,模型就很难很好地理解和处理没见过的文本。 -
• 后续任务效果变差:像翻译、摘要这类任务,会因为理解错误而表现不佳。
3.1 BPE 是如何工作的
-
1. 预分词:首先,对输入的文本进行初步切分,通常是按空格或标点来切。比如,”applied deep learning” 这句话会被切成 ["applied", "deep", "learning"]。 -
2. 初始词表:初始词表里只有单个字符,并且通常会给每个单词末尾加一个特殊标记(比如 </w>表示词尾)。拿 “deep” 这个词来说,初始状态就是["d", "e", "e", "p", "</w>"]。 -
3. 反复合并:BPE 会不断找出并合并出现频率最高的相邻字符对(或子词对)。例如,如果 ("e", "e")这对组合出现次数最多,它就会被合并成一个新的词元"ee",并加入词表。 -
4. 更新词表:这个合并过程会一直持续,直到词表大小达到我们预设的目标,或者找不到可以合并的高频词对为止。 -
5. 最终分词:有了最终词表后,再对新文本进行分词时,就会用上学到的这些子词单元,把单词拆成词表里能找到的最大的子词组合。
3.2 举例:分词 “low lower lowest”
我们来一步步看 BPE 是怎么处理 “low lower lowest” 这句话的。
-
• 第 1 步:初始的字符级切分(带词尾标记) ["l", "o", "w", "</w>", "l", "o", "w", "e", "r", "</w>", "l", "o", "w", "e", "s", "t", "</w>"]
(这里只是一个概念性的表示) -
• 第 2 步:统计所有词中相邻字符对的出现频率 -
• ("l", "o"):出现 3 次(来自 “low”, “lower”, “lowest”) -
• ("o", "w"):出现 3 次 -
• ("e", "r"):出现 1 次 -
• ("e", "s"):出现 1 次 -
• …等等
当前最频繁的字符对是:("l", "o")(3次) -
• 第 3 步:合并最频繁的字符对
新词元:"lo"
更新后的序列:["lo", "w", "</w>", "lo", "w", "e", "r", "</w>", "lo", "w", "e", "s", "t", "</w>"] -
• 第 4 步:再次统计词对频率
当前最频繁的词对是:("lo", "w")(3次) -
• 第 5 步:合并最频繁的词对
新词元:"low"
更新后的序列:["low", "</w>", "low", "e", "r", "</w>", "low", "e", "s", "t", "</w>"] -
• 第 6 步:再次统计词对频率 -
• ("e", "r"):1次 -
• ("e", "s"):1次 -
• …(假设其他词对频率更低)
我们这里就选("e", "r")来合并。 -
• 第 7 步:合并选中的词对
新词元:"er"
更新后的序列:["low", "</w>", "low", "er", "</w>", "low", "e", "s", "t", "</w>"]
经过这样几步合并后,最终 “low lower lowest” 这句话可能会被分成类似这样的词元:["low</w>", "low", "er</w>", "low", "e", "s", "t</w>"]
3.3 BPE 的优点和局限
优点:
-
• 能处理未登录词:可以把生僻或没见过的词,拆成模型认识的子词。 -
• 词表自适应:词表是从训练数据中直接学出来的,所以能很好地适应不同语言和领域。 -
• 词元长度可变:生成的词元有长有短,在字符和单词之间找到了平衡。
局限:
-
• 需要预分词:BPE 依赖于先把文本按空格等规则切成”单词”。这对于像中文、日文这样没有明显单词边界的语言来说,是个挑战。 -
• 贪心合并:BPE 的合并策略是贪心的,总是选当前出现次数最多的对进行合并,这样得到的子词单元不一定在语义上是最优的。
4. WordPiece
WordPiece 是一种子词分词算法,它和 BPE 很像,但核心区别在于如何选择要合并的词元对。BPE 是挑出现次数最多的对来合并,而 WordPiece 则是选择那个能让训练数据(整体出现的)概率最大化的词对。这种设计让它特别适合 BERT 这样的模型,也是谷歌广泛采用的方法。
4.1 WordPiece 是如何工作的
-
1. 初始词表:和 BPE 一样,WordPiece 也是从单个字符(或预切分好的单词)开始。通常会给不是单词开头的子词加上特殊前缀(比如 BERT 里用的 ##,用来表示这个词元是接在前面的)。 -
2. 概率最大化:WordPiece 会计算合并每一对候选词元后,能让训练数据整体概率提升多少。具体来说,它会计算一个得分,比如 P(词元1, 词元2) / (P(词元1) * P(词元2))。这里的 P 代表某个词元或词元序列在训练语料中出现的概率。得分最高的那一对,就是
能让概率提升最大的,就会被选中合并。
-
3. 反复合并:选中的词对会被合并成一个新词元,加入词表。这个过程不断重复,直到词表大小达到我们预设的目标。 -
4. 最终分词:分词时,会用学到的这些子词单元,优先匹配更长、更常见的那些。如果一个子词不是某个单词的开头部分,它前面通常会加上 ##前缀(比如["un", "##believ", "##able"]就组成了 “unbelievable”)。
4.2 WordPiece 的优点和局限
优点:
-
• 子词语义更合理:因为追求概率最大化,WordPiece 学出来的子词单元往往在语言上更有意义。 -
• 非常适合 BERT:这种设计特别契合像 BERT 这种”掩码语言模型”的训练方式。 -
• 能处理未登录词:和 BPE 一样,也能把没见过的词拆成认识的子词。
局限:
-
• 需要预分词:和 BPE 一样,它也依赖于先把文本按空格等规则切成”单词”,这对于中文、日文这类语言来说同样是个难题。 -
• 前缀标记不太直观:像 ##这种表示词中子词的标记,对人来说看起来可能不太习惯,理解起来稍微有点绕。
5. SentencePiece
SentencePiece 是一种分词算法,它的设计初衷就是为了克服 BPE 和 WordPiece 需要预分词(预先按空格拆分)的局限性。与它们不同,SentencePiece 把输入文本(包括空格在内)看作一个原始的字符流,不需要事先切分单词。这种方法让它能轻松处理像中文、日文、韩文这样词边界不清晰的语言,因此成为处理多语言和非空格分隔语言的理想选择。它被广泛应用于 T5 和 ALBERT 等模型中。
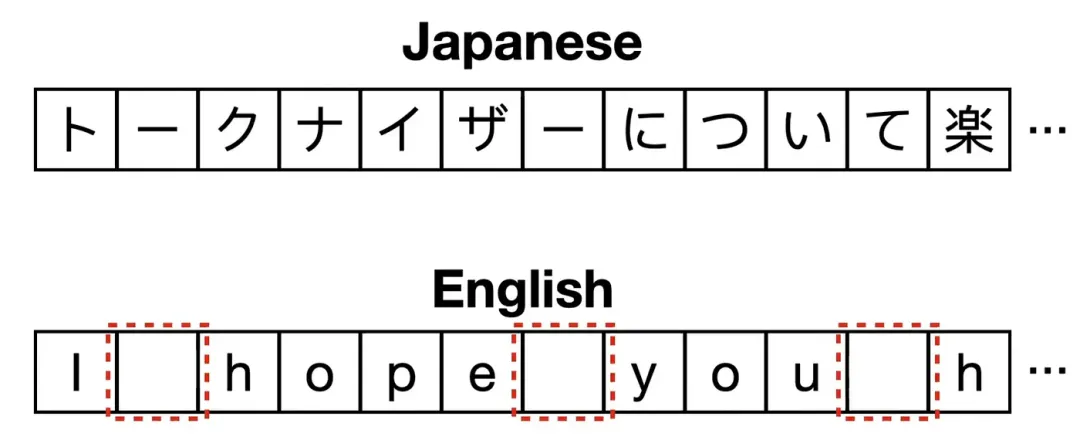
5.1 SentencePiece 是如何工作的
-
1. 输入视为字符流:SentencePiece 不会先把文本切成单词,而是把整个输入(包括空格)都当作一个连续的字符序列。它会把空格替换成一个特殊的占位符(通常是 _下划线)。 -
2. 合并算法:它可以选择使用类似 BPE 的合并算法(即合并最频繁的字符/子词对),也可以使用 Unigram 语言模型分词器。 -
• 类似 BPE 的合并:和标准 BPE 一样,反复合并出现频率最高的字符或子词对来构建词表。 -
• Unigram 分词器:这个方法则相反。它一开始会准备一个非常大、包含很多潜在词元的词表,然后一步步地剪枝,移除那些对训练数据整体概率影响最小的词元,直到词表缩小到我们想要的大小。 -
3. 空格处理:SentencePiece 把空格当作普通字符一样来学习和处理。在分词时,它用 _下划线来代表空格,这样就能保证原始文本可以被完美地还原。
-
4. 句子还原:只需要把生成的词元连接起来,再把 _下划线替换回空格,就能完美地恢复出原始句子。
5.2 举例
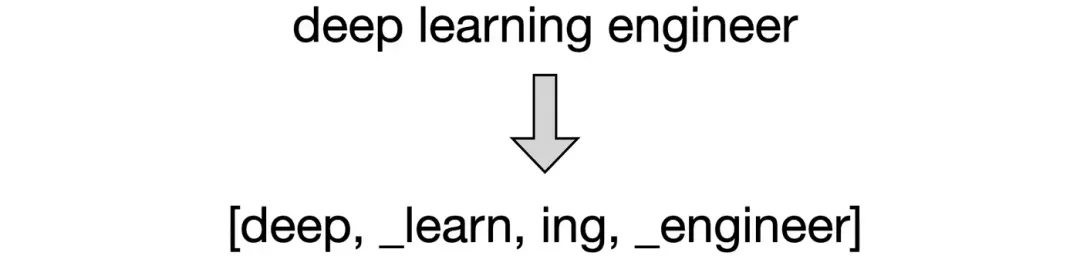
对于句子 “deep learning engineer”:
-
• 输入被处理成: deep_learning_engineer(空格被替换成了_) -
• SentencePiece 可能生成的词元: [“deep”, “_learning”, “_engineer”](假设这些是学到的子词单元)。 -
• 这里的 _就代表了空格,之后只要把词元拼起来,再把_换回空格,就能得到原句。
5.3 SentencePiece 的优点和局限
优点:
-
• 语言无关性:通过把输入当作原始字符流处理,它能很好地支持各种语言,特别是那些没有明确单词边界的语言。 -
• 无需预分词:省去了为不同语言单独配置预分词器的麻烦,大大简化了多语言任务的流程。 -
• 完美还原:由于明确地处理了空格,它能保证从词元序列中毫无损失地还原出原始文本。 -
• 灵活的算法:既可以用 BPE,也可以用 Unigram 语言模型来学习词表。
局限:
-
• 词元不太直观:用 _来表示空格,使得分词后的结果对人类来说阅读和调试起来,可能不如单词级分词那么直观。 -
• 处理空格的额外开销:与隐式处理空格的方法相比,显式地学习空格可能会略微增加词表的大小或序列的长度。
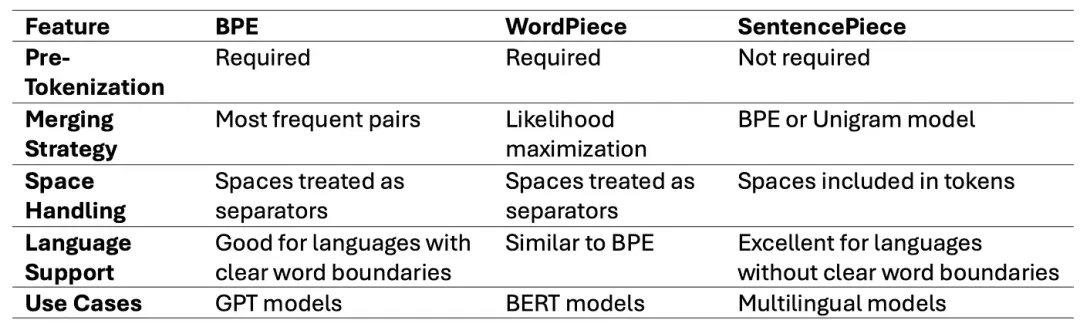
6. BPE、WordPiece 和 SentencePiece 的对比
简单来说,这三种算法的核心区别在于:
-
• BPE 基于频率进行合并。 -
• WordPiece 基于**概率(似然)**进行合并。 -
• SentencePiece 则将文本视为原始字符流,它可以采用类似 BPE 的合并方式,也可以使用 Unigram 方法。
总结
分词是为大语言模型准备文本数据时一个至关重要但又常被忽视的环节。我们讨论的这三种子词算法——BPE、WordPiece 和 SentencePiece——各有千秋,适用于不同的场景。
-
• BPE 提供了一种稳健、通用的方法,被 GPT 和 Llama 等模型广泛采用。 -
• WordPiece 凭借其基于概率的合并策略,在 BERT 等模型中表现出色,能捕捉到高度相关的子词单元。 -
• SentencePiece 则通过直接在字符流上操作,为处理多语言和没有空格分隔的语言提供了无与伦比的灵活性。
深入理解这些算法的特点和细微差别,能帮助我们在面对具体的 NLP 任务时,更明智地选择合适的分词方法,从而构建出更高效、更强大的语言模型。
