 夜雨聆风
夜雨聆风





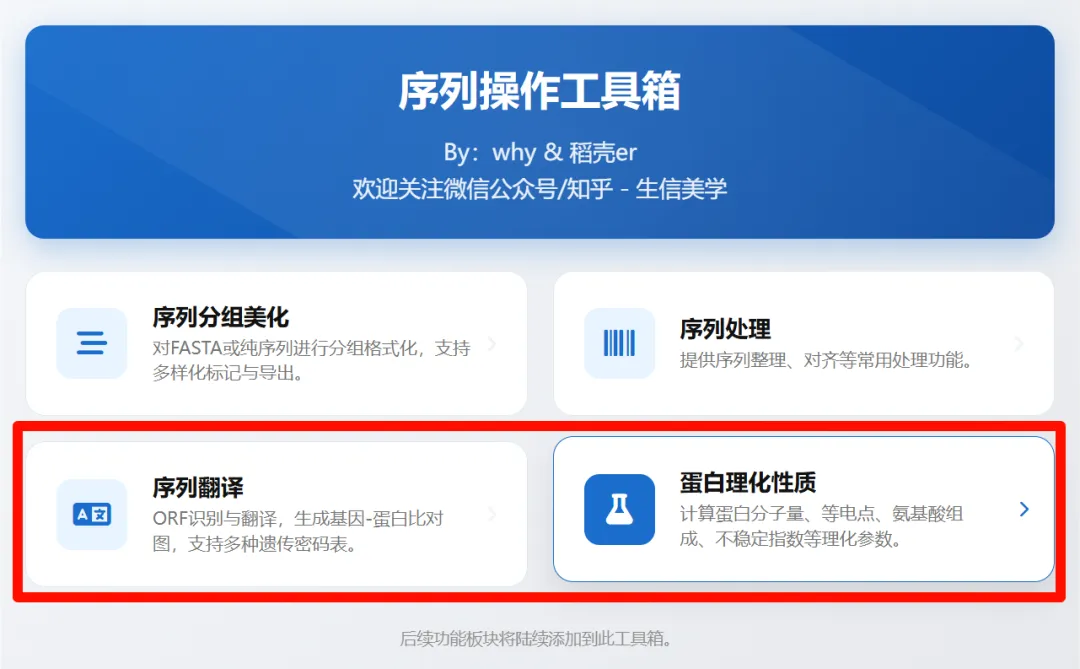
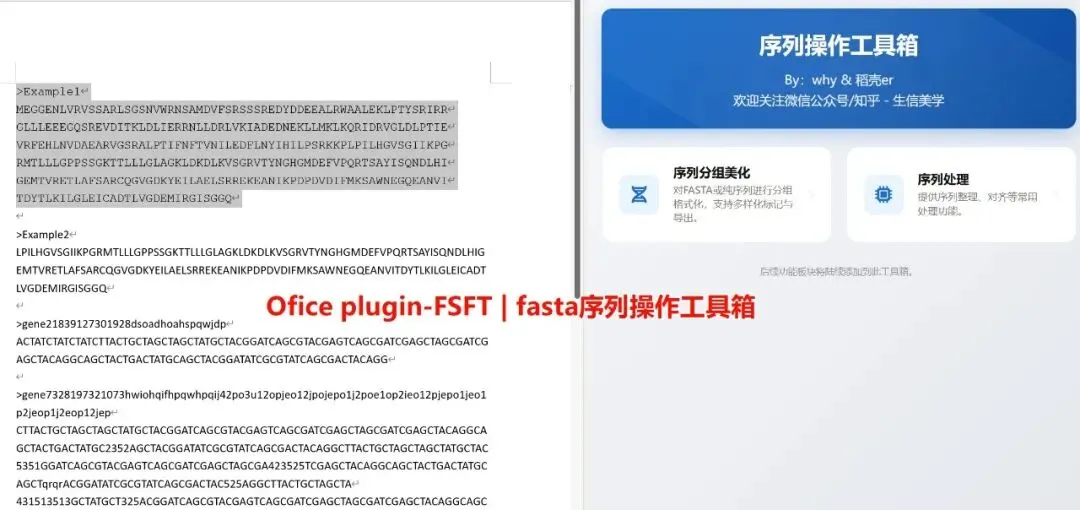
重磅更新 | office插件-序列处理工具箱
之前我们开发了序列分组美化工具的office插件版本,为了更加便捷的进行序列处理和其他需求,我们对该工具箱进行了升级,新增两个主要功能板块,分别是序列翻译和蛋白理化性质分析(完全复刻Expasy网站中的计算方法),下面就详细介绍一下这两个功能板块的使用方法。
度盘下载地址:https://pan.baidu.com/s/1KxKUHKYTsfQ6QQt1tRZfew?pwd=5p6x 提取码: 5p6x
目前此工具已经完全在GitHub开源,开源仓库为:https://github.com/jianbai-design/Fasta-Sequence-Manipulation-Toolkit
安装与打开请参考之前的推送《office插件 | fasta序列工具箱》,如果你安装了v1.0版本,无需卸载,安装时会自动覆盖。
一,序列翻译功能介绍
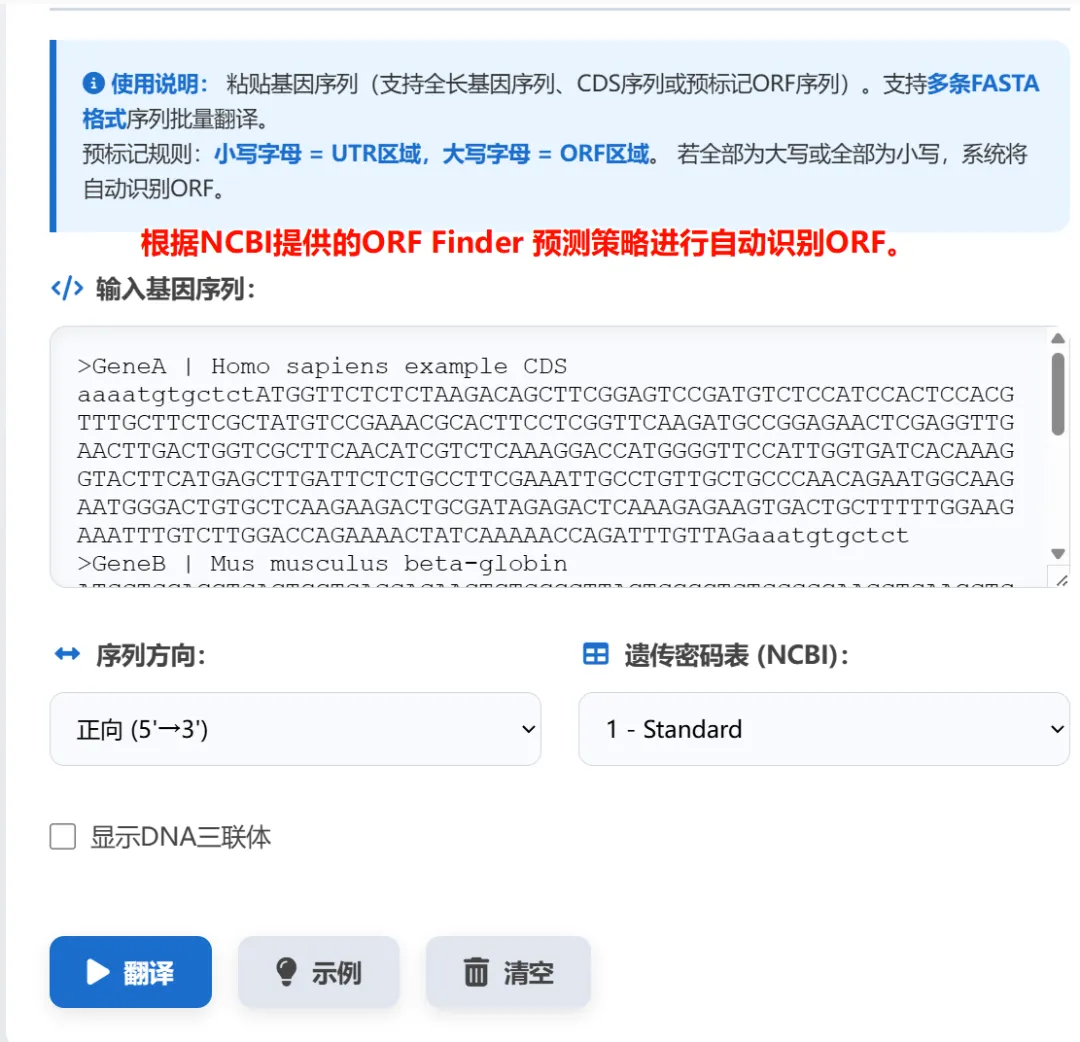
1,序列翻译主要用于将碱基序列翻译成氨基酸,完全复刻NCBI中33个密码子表,同时也支持批量翻译,你可以输入纯CDS序列,也可以输出整个基因序列,系统自动识别最长的阅读框进行翻译。
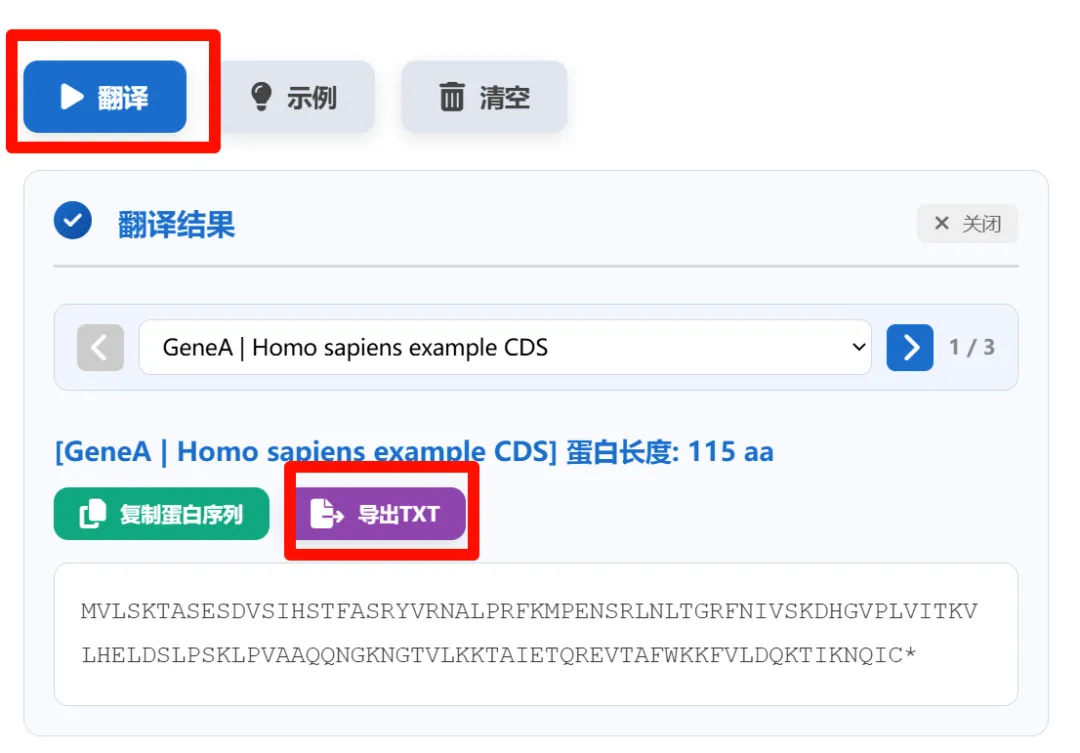
2,点击翻译,你可以导出txt文件,里面包含了全部的氨基酸序列,或者复制当前序列。
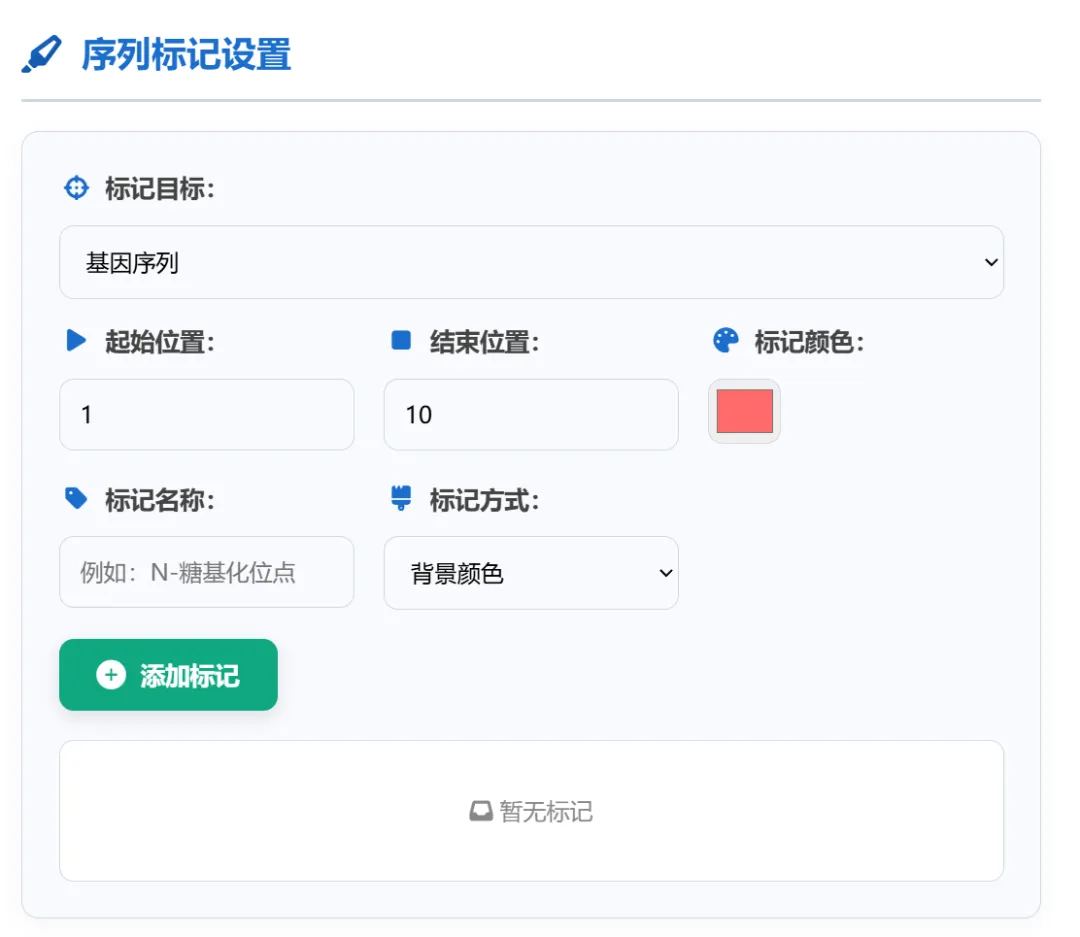
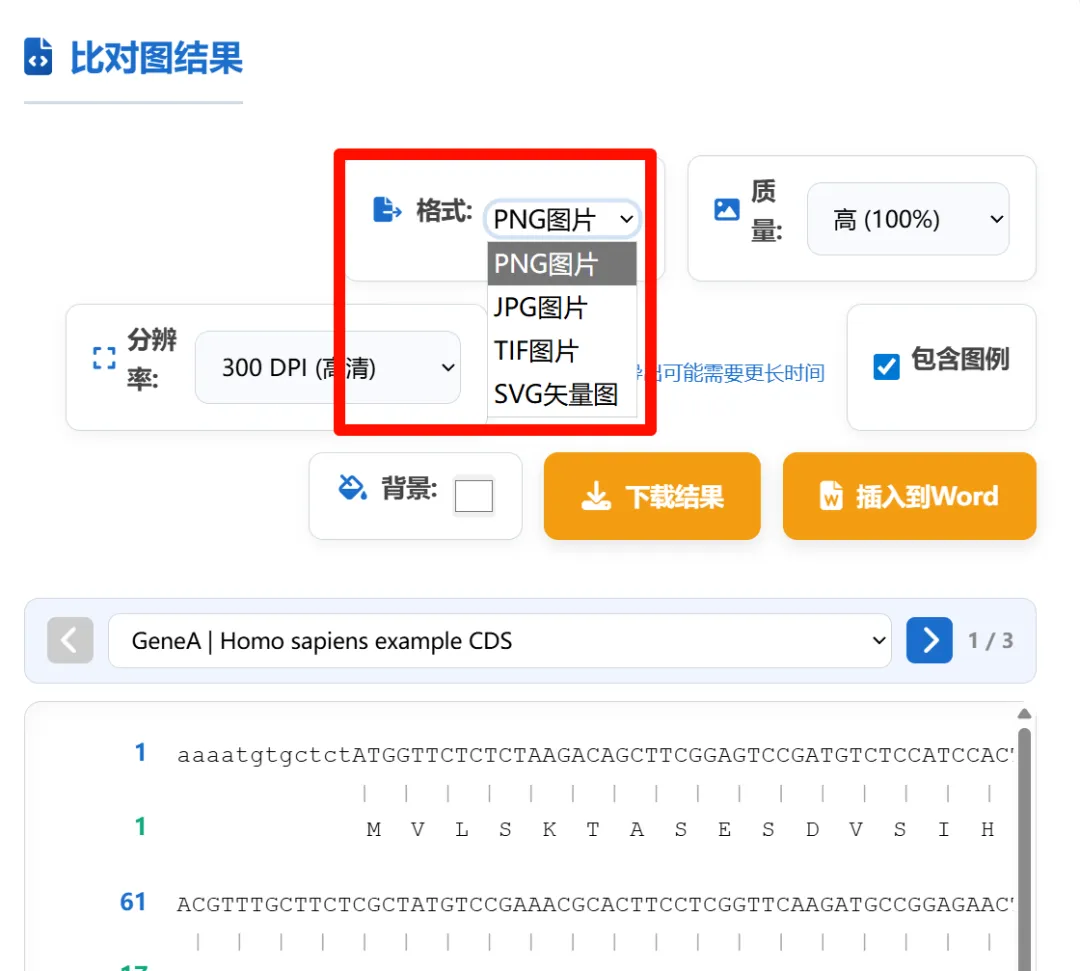
3,生成比对图,相关设置如下,尤其注意基因和蛋白序列间距和行间距的区别。再就是进行序列标记和之前的标记类似,另外新增了对氨基酸序列进行标记的选择。

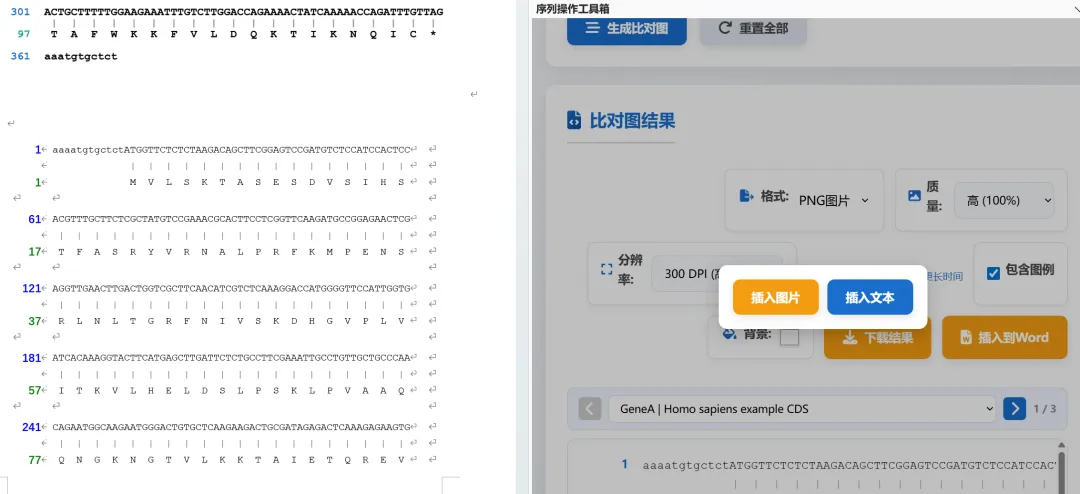
4,导出比对结果,这里尤其注意只有切换一次图片类型后才会弹出质量和分辨率的设置;下载结果只能下载图片,导入word可以选择图片导入或者以文本形式直接导入。
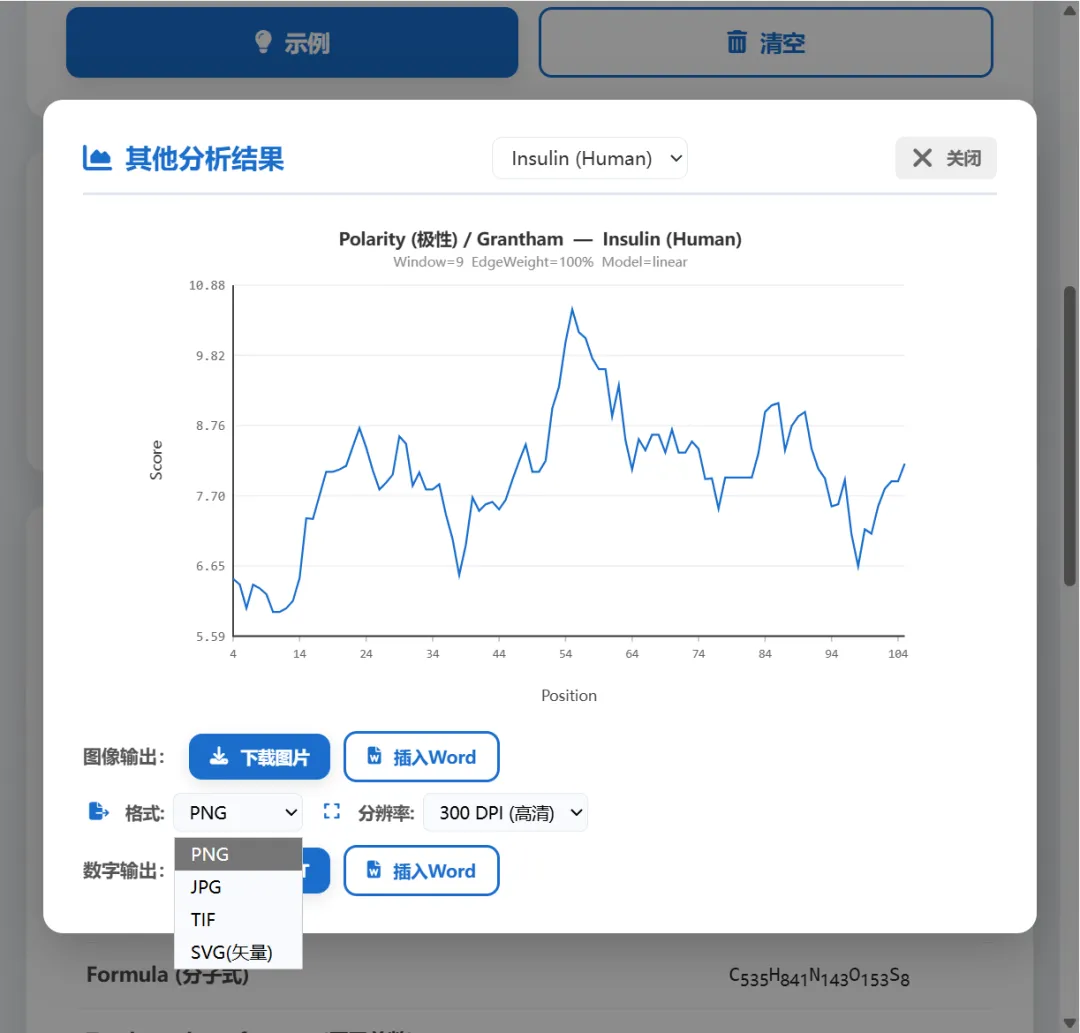
二,蛋白理化性质功能介绍
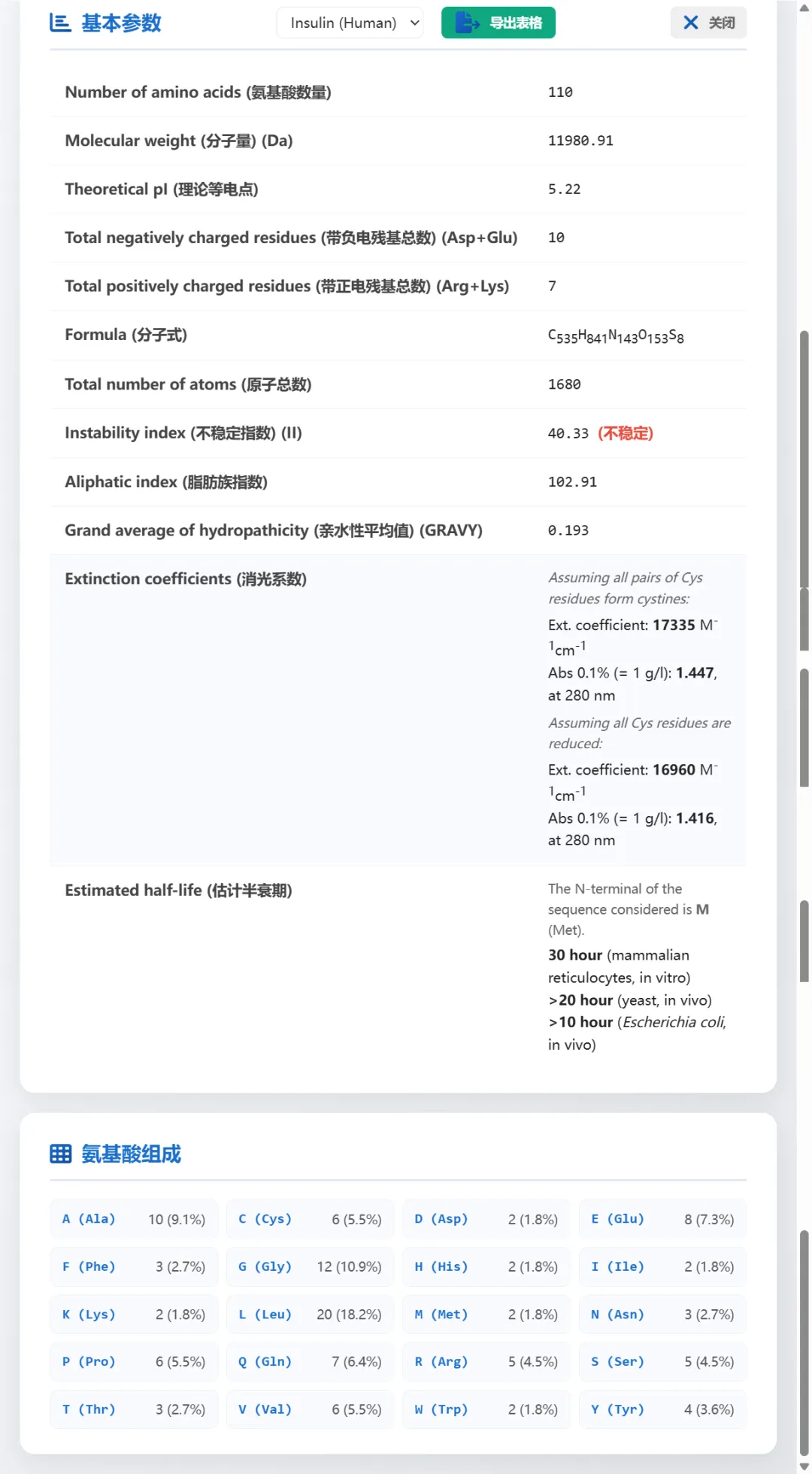
1,输入fasta格式序列,支持批量,这里分为基础性质和其他分析。基础性质包含分子量,化学式,等电点,亲水性平均值,氨基酸组成等等,支持将结果一键导出表格。

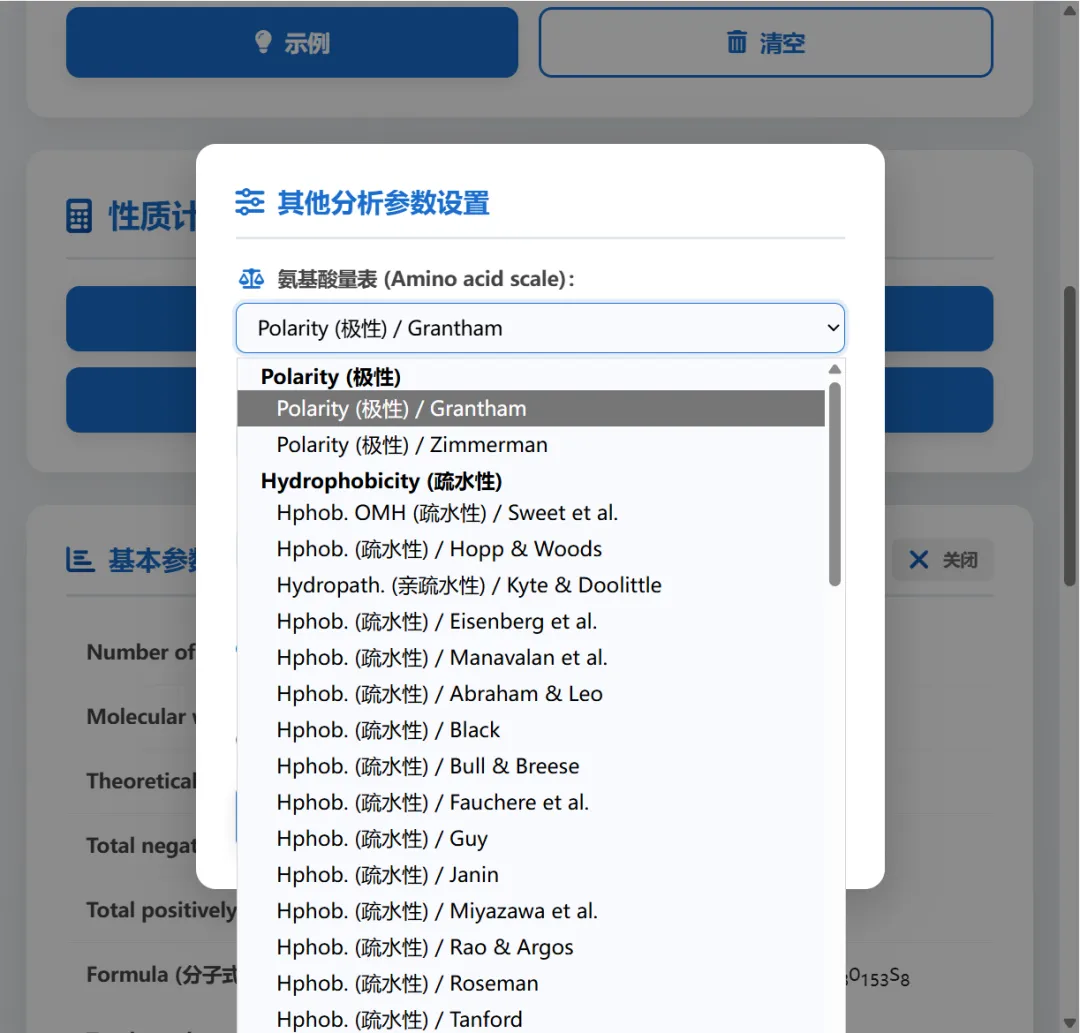
2,其他分析中涵盖了https://web.expasy.org/protscale/中的全部分析项,支持svg矢量图导出,具体计算数据可以导出txt文本或者直接插入word中。优点是速度非常快且可以批量计算。
好啦,今天的分享到此结束,水平有限,才疏学浅,如有问题,请多指教,青山不改,绿水长流,山高路远,顶峰相见。
往期推荐
 |
 |
 |
