 夜雨聆风
夜雨聆风





拍照类文档解析及计数任务下MLLM能力如何?Real5-OmniDocBench及UNICBench评估基准
今天是2026年3月9日,星期一,北京,天气晴
来看多模态大模型评估进展,还是看数据方面的动静,看看有啥新鲜事儿。
一个是多模态大模型计数能力评估UNICBench实现思路。
另一个是多模态大模型非规整类文档场景评估基准Real5-OmniDocBench。
多看,多思考,沉下心来看技术,尤其学习这种数据角度的评测及构建设计思路,会有收获。
一、多模态大模型拍照类文档场景解析基准Real5-OmniDocBench
先看文档多模态进展,讲的还是测试数据集的问题。现有数字文档基准(如OmniDocBench,榜单已经刷爆)无法反映真实物理场景性能,真实文档存在几何畸变、光学伪影等复杂物理扰动。
例如,OmniDocBench v1.5(https://arxiv.org/pdf/2412.07626,https://github.com/opendatalab/OmniDocB,包含九种文档类型(学术论文、书籍、笔记、财务报告、杂志等)测试集,都是比较规整的。

所以,就做个增强,在这个数据集上,在扫描、扭曲、屏幕翻拍、光照、倾斜五大真实场景,对全部1355页进行了全面的一对一物理重构,对每张数字源图像,使用专业级打印和异构移动采集设备生成五种物理变体,同时保留原始数据的完整真实标注。

工作在:《Real5-OmniDocBench: A Full-Scale Physical Reconstruction Benchmark for Robust Document Parsing in the Wild》,https://arxiv.org/pdf/2603.04205,覆盖并生成 6775个测试样本,数据地址在:https://huggingface.co/datasets/PaddlePaddle/Real5-OmniDocBench
说到数据范畴,那就看看细节【这个比较重要】:
具体的,1200dpi专业打印,A3/A4等比缩放,扫描场景用专业设备,手持采集场景(扭曲/屏幕翻拍/光照/倾斜)使用苹果、小米、OPPO主流移动设备,覆盖不同ISP、传感器噪声和镜头畸变。
组合5大主场景+各5个子条件:
扫描(Scanning,标准、低质量、倾斜、装订、书册式)

扭曲(Warping,折叠、卷曲、揉皱、边角翘曲、书脊弧形)

屏幕翻拍(Screen-Photography,办公显示器、专业显示屏、笔记本、平板、手机)

光照(Illumination,低光、阴影、偏色、闪光灯过曝、透明介质折射)
倾斜(Skew,俯仰、侧滚、偏航、复合旋转、极端倾斜)。

最后,看下测试效果:
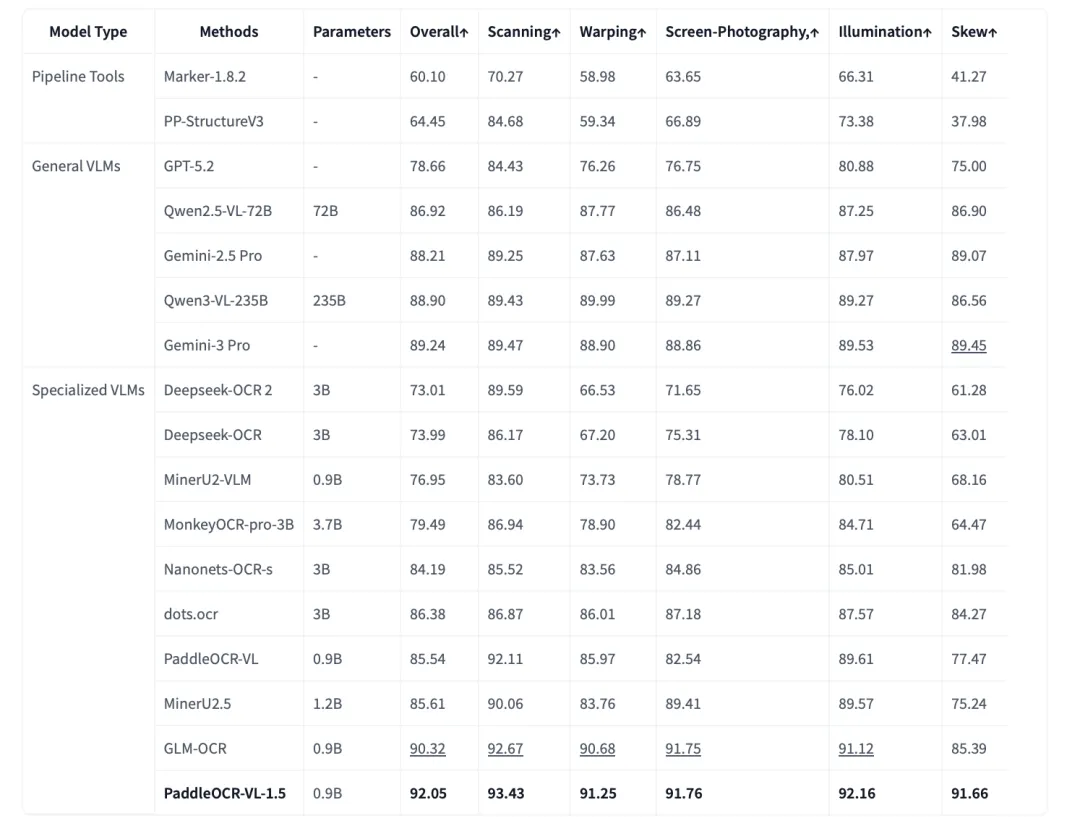
二、多模态大模型计数能力评估UNICBench思路
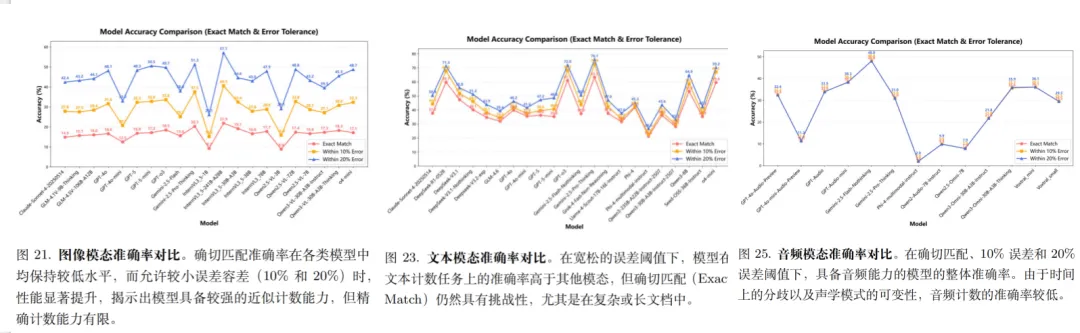
接着看第二个基准UNICBench,覆盖图像、文本、音频三模态的MLLM计评估,考察计数能力。工作在《UNICBench: UNIfied Counting Benchmark for MLLM》,https://arxiv.org/pdf/2603.00595,先说结论,推荐采用“检测器+VLLM”混合流水线、证据优先输出(附带坐标/时间戳)、难度分层报告【其实就是小模型加大模型结合思路】。
看核心几个点:
1、看数据
总计8241个样本、14301个QA:5300张图像(5508个QA)、872份文档(5888个QA)、2069段音频(2905个QA),图像含49类场景(日常物品、密集人群、遥感影像等),文本覆盖代码、古籍等12类格式,音频包含环境音与会议语音。
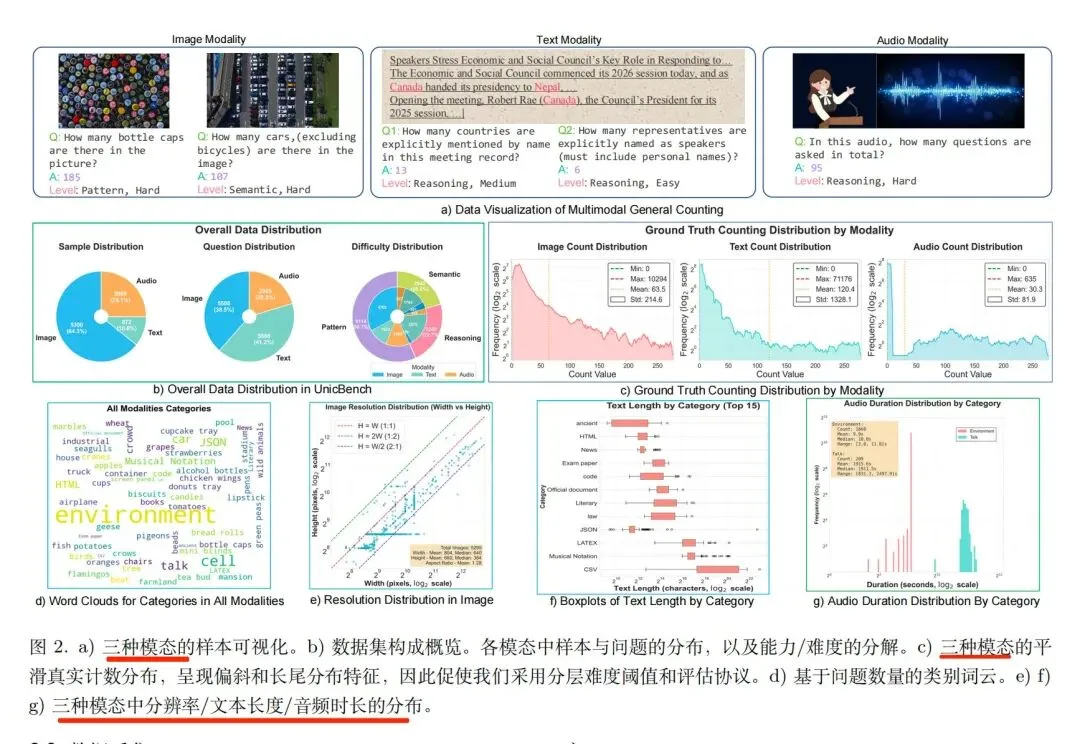
这个核心还是可以看看数据上的细节:
图像模态数据构建上,从FSC147提取30+类日常物体,每类100个样本,保证计数范围多样;NWPU‑MOC提供遥感影像(飞机、船只、农田等),含尺度变化与遮挡;人群计数:整合JHU‑CROWD++、UCF‑QNRF、ShanghaiTechPartA、NWPU‑Crowd共150个样本,并人工补充极端密集场景(平均355.58人,最大10,294人);医学:血细胞图像400张,平均每图50.06个细胞;屏幕面板:50个样本、55个问题,团队定制标注;笔、书本、杯子等17类在FSC147基础上人工增强标注;汽车:融合CARPK与NWPU‑MOC各100个样本。

文本模态构建上,共872个文本样本,生成5,888个问题,覆盖12个类别,均为自采集。代码:100个Java/Python文件,500个问题,统计函数、类、循环等;JSON:200个样本,1,800个问题,统计嵌套结构与键值对;LaTeX:66个样本,593个问题,嵌套与公式密度高(最大计数71,176);HTML:168个文件,1,176个问题,关注标签层级,已去冗余;乐谱(MusicXML):143个文件,715个问题,统计音符、小节、休止符;古籍(20样本)、文学作品(60样本):保留原文语言与风格,统计其中的用词等。

音频模态构建上。共2,069个音频样本,来自两个专业数据集:DESED:1,860个环境音(门声、警报、狗叫、键盘等),事件稀疏(平均1.56个/样本),时长3–300s;AliMeeting:209段会议录音,1,045个问题,语音密集(平均81.51个/样本),时长10–2497.9s,中位数10s。标注:帧级精度(0.01s),标签区分说话人、事件类别、语义单元【用于统计】。

2、看任务设置
能力层级上设计三级:Pattern(L1):直接感知计数(如“可见人数”“鼓点次数”);Semantic(L2):属性过滤+去重(如“穿红衬衫的人”“非重复引用”);Reasoning(L3):规则驱动推理(如“2022年修改的文件夹数”“音频中总提问数”)。
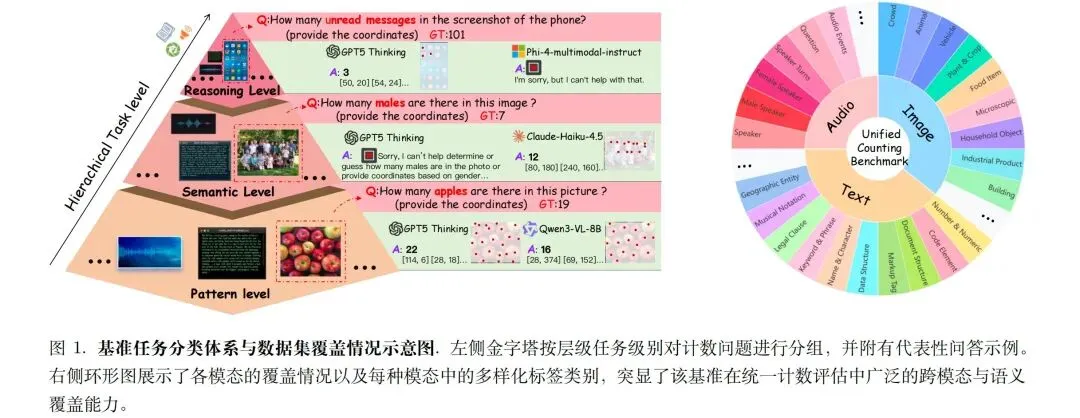 难度标签上, 设计三级:Easy(1-10)、Medium(11-100)、Hard(>100),按密度、遮挡、重复度等客观指标划分。
难度标签上, 设计三级:Easy(1-10)、Medium(11-100)、Hard(>100),按密度、遮挡、重复度等客观指标划分。

评测方式上,采用固定提示词(要求仅输出数字)、解码参数(max_tokens=4096、temperature=0.0)、答案解析规则(优先提取思考标签内数字,再取结尾/首个有效数字,这个就是具体的计算逻辑了)。

3、看评估指标及评测结果
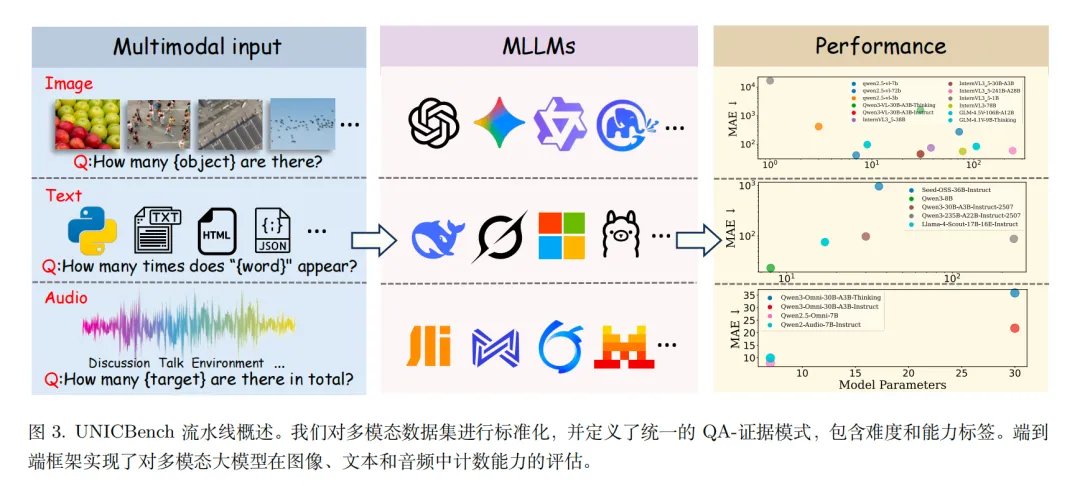
核心指标方面,采用成功率(有效数字输出占比)、MAE/MSE(误差)、命中率(@100%/@90%/@80%,允许一定误差tolerance)。
评估结果方面,如结果是:闭源模型(如GPT-5系列、Gemini-2.5-Pro-Thinking)在鲁棒性上更优,开源模型(如InternVL3_5-241B、Qwen2.5-VL)在特定场景(密集图像)效果好些【这个其实是废话。。。】
参考文献
1、https://arxiv.org/pdf/2412.07626
2、https://arxiv.org/pdf/2603.00595
关于我们
老刘,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
对大模型&知识图谱&RAG&文档理解感兴趣,并对每日早报、老刘说NLP历史线上分享、心得交流等感兴趣的,欢迎加入社区,社区持续纳新。
加入社区方式:关注公众号,在后台菜单栏中点击会员社区加入。
