 夜雨聆风
夜雨聆风





装上这个插件,OpenClaw 学会了搜论文
OpenClaw开启了全民“养虾”时代
最近打开任何一个技术群,都在聊 OpenClaw。
甚至还有人推出了安装付费的服务,价格从100到1.6万不等!
如果你还没部署一只自己的龙虾,我个人建议可以试试腾讯云推出的轻量应用服务器海外版(会有惊喜),接入QQ、企业微信、飞书之后就可以使用了。
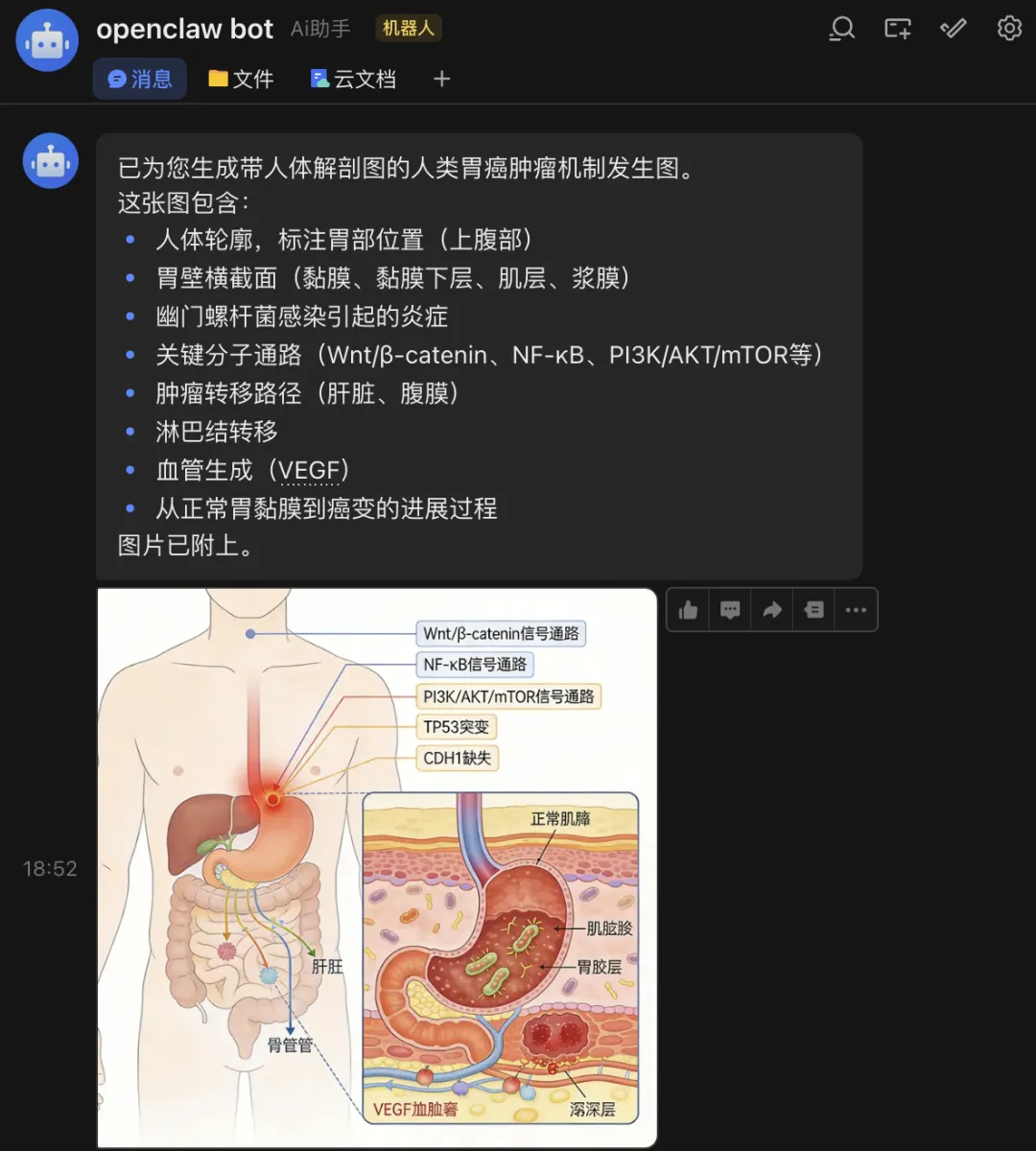
这是我自己的,还可以画图!
前两天,这只开源龙虾在过去四个月里实现了一个成就:GitHub star 数从 0 飙到 23 万,超过了 React,超过了 Linux。
React 用了 12 年。Linux 用了 14 年。OpenClaw 用了 4 个月。
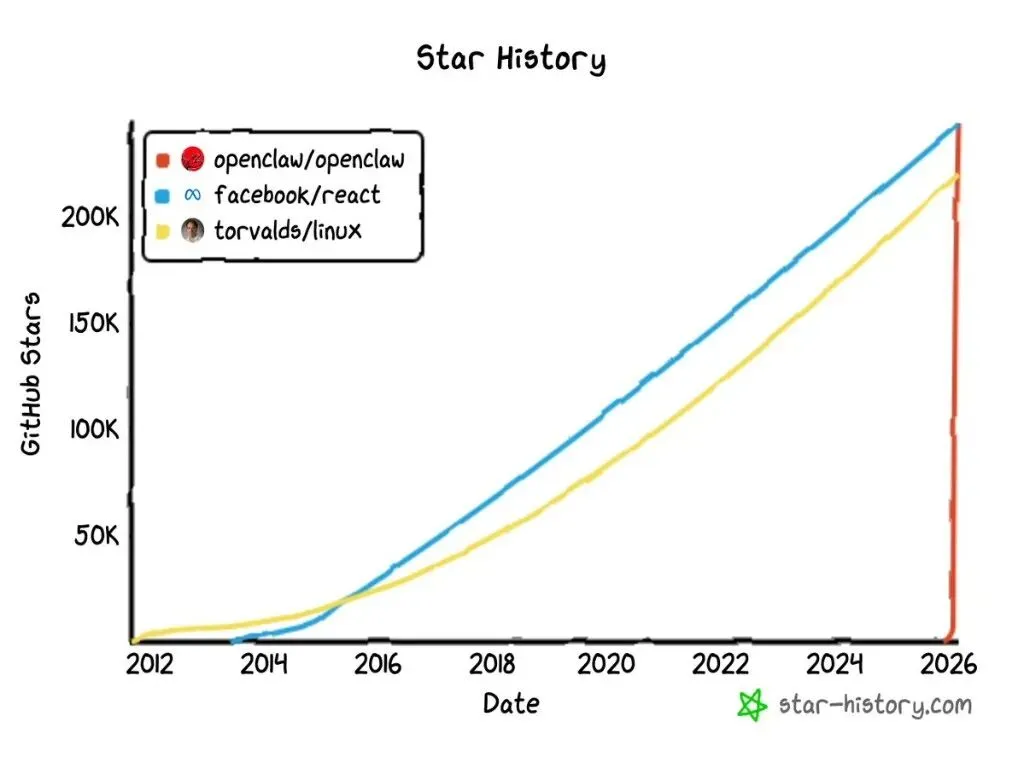
这条增长曲线本身就是一个信号——不是某个项目火了,而是一个时代的需求被引爆了。人们不只是想要一个更聪明的聊天机器人,他们想要一个能替自己干活的 AI。
有人用它管理日程,有人用它写代码,有人用它炒股,有人用它自动处理邮件和客户消息——什么都能干,什么都敢干。Discord 社区每天几千条消息,你的朋友圈里可能已经有人在晒他们的 OpenClaw 配置了。
但是。
当我第一次尝试用 OpenClaw 做科研的时候,它翻车了。
而且翻得很彻底。
01 一只不会搜论文的龙虾
事情是这样的。
我让它帮我搜一下 “CRISPR 基因编辑在肿瘤免疫治疗中的最新进展”。
它非常自信地给了我一份报告。条理清晰,语言流畅,列了 8 篇论文,每篇都有作者、期刊、年份、DOI。格式完美,看起来比我自己整理的还专业。
心想这玩意儿真行啊。
我点开第一个 DOI。
404。页面不存在。
第二个。404。
第三个。打开了!但那篇论文讲的是农业灌溉。
我开始不对劲了。把 8 个 DOI 全部验证了一遍。
8 篇论文,没有一篇是真的。
一篇都没有。作者是编的。期刊名是编的。DOI 是编的。它用完美的格式,写了一份完美的假报告。
这不是 OpenClaw 的问题。这是所有大语言模型的通病——它们会”编”论文。学术界管这个叫 hallucination(幻觉)。模型在训练数据中见过无数论文的格式,所以它知道一篇论文”长什么样”,但它不知道哪篇论文”真的存在”。
对于写营销文案来说,偶尔编个数据没什么大不了。
但对于科研来说,这是致命的。而且今年基金本子申请,基金委也专门出了提示,避免虚假文献!
所以,你写进论文的每一条引用,都必须是真实的、可溯源的。一条假引用被审稿人发现,整篇论文的可信度归零。你的学术声誉可能因此受损。
我身边就有朋友吃过这个亏——用 ChatGPT 帮忙整理参考文献,投稿之后审稿人发现了两条不存在的引用,直接 desk reject。
那一刻我意识到一件事:
OpenClaw 有大脑,但没有科研的手和眼。
它能思考、能规划、能写作。但它不能去 PubMed 上搜一篇真实的论文,不能去 arXiv 上下载一篇预印本,不能阅读一篇 PDF 的全文,不能判断一篇论文到底是顶会、顶刊,还是几乎没人会认真引用的期刊。
它是一个天才,但是一个没读过书的天才。
一个连图书馆门都进不去的天才。
02 我给龙虾装了一个学术大脑
我做了一件可能有点疯狂的事:我决定教会它。
不是教它”怎么搜论文”——那是 prompt engineering 的活儿,你调一百遍 prompt 也没用,因为模型本身没有访问学术数据库的能力。
我是要给它真正的学术搜索能力。让它能够调用真实的学术 API,拿到真实的数据。
而这件事,正好用到了我构建的文献搜索项目: ai4scholar(ai4scholar.net)。这是一个统一的学术搜索代理。它把 Semantic Scholar、PubMed、Google Scholar、arXiv、bioRxiv、medRxiv 这些学术平台的接口打通了,提供一个统一的 API。
做这个的初衷很简单:我自己做科研的时候,受够了在六七个平台之间来回切换。PubMed 搜一遍,arXiv 搜一遍,Semantic Scholar 再搜一遍,Google Scholar 又搜一遍。同样的关键词输四遍,结果还得手动去重。
现在我要做的是下一步——把 ai4scholar 的能力变成 OpenClaw 能用的”工具”。
用 OpenClaw 的话说,就是做一个插件。
这个过程比我想象的要顺利。OpenClaw 的插件体系设计得很好,本质上就是:你告诉 Agent “你有哪些工具可以用”,以及”每个工具怎么调用”。剩下的,Agent 自己决定什么时候用什么工具。
两周时间,我写了 35 个工具:
搜索类——跨平台论文搜索(一句话搜遍六大数据库)、关键词搜索、语义搜索、标题精确匹配、代码片段搜索
详情类——论文详情获取(标题、摘要、引用量、作者、DOI,全是真的)、引用网络查询(谁引了这篇,这篇引了谁)、作者信息查询(h-index、发表记录、合作者网络)
全文类——PDF 全文下载和阅读(包括通过 DOI 直接下载,支持校园网机构访问)、arXiv 全文获取、bioRxiv/medRxiv 全文获取
分析类——论文质量评估(基于 CCF 分级、引用量、发表年份、作者 h-index 自动打分排序)、论文推荐、批量查询
写作类——自动引用标注(粘贴一段学术文字,自动在需要引用的位置加上真实的参考文献)
35 个工具,覆盖 6 个学术数据库平台。
装上这个插件之后,OpenClaw 变了。
我再让它搜 “CRISPR 基因编辑在肿瘤免疫治疗中的最新进展”。
这一次,它没有”编”。它调用了 PubMed 和 Semantic Scholar 的搜索接口,拿到了真实的论文列表。它读了摘要,按引用量和发表时间排了序,筛掉了不相关的,给我生成了一份报告。
每篇论文的 DOI 都能点开。每个数据都可以验证。它甚至给高引论文做了标注,告诉我哪几篇是领域内被引最多的。具体案例可见我之前写的文章。
同一只龙虾,装上工具之前和之后,是两个物种。
这个对比让我深刻理解了一件事:Agent 的能力不取决于它的”大脑”有多聪明,而取决于它”手里有多少趁手的工具”。给一个普通人一台显微镜,他能看到细菌。给同一个人一把锤子,他只能砸核桃。
工具定义了能力的边界。
03 凌晨四点半,龙虾自己交了作业
装完插件后的一段时间里,我一直在测试各种用法。搜论文、查引用、找作者——这些都是基本操作,没什么惊喜。
直到有一天,发生了一件让我重新认识 Agent 的事。
凌晨四点半,我失眠刷小红书,看到有人做了一个”自动引用标注”工具——你粘贴一段论文文字,它自动帮你在合适的位置加上引用。
我心想:这不就是 ai4scholar 插件的用武之地吗?我的 Agent 手里有真实的学术搜索工具,完全可以做同样的事,而且引用的论文是从真实数据库搜出来的,不是编的。
于是我给我的 OpenClaw Agent 发了条消息:
“我需要你实现一个功能:用户粘贴一段学术文本,你自动分析哪里需要引用,去数据库搜真实论文,匹配后插入引用标记,在末尾生成参考文献列表。你自己想想怎么实现。我先睡了,早上看结果。”
注意,我没有告诉它具体步骤。没有说”先做 A 再做 B 再做 C”。我只是描述了目标。
然后我去睡了。
早上醒来,它给我交了作业。
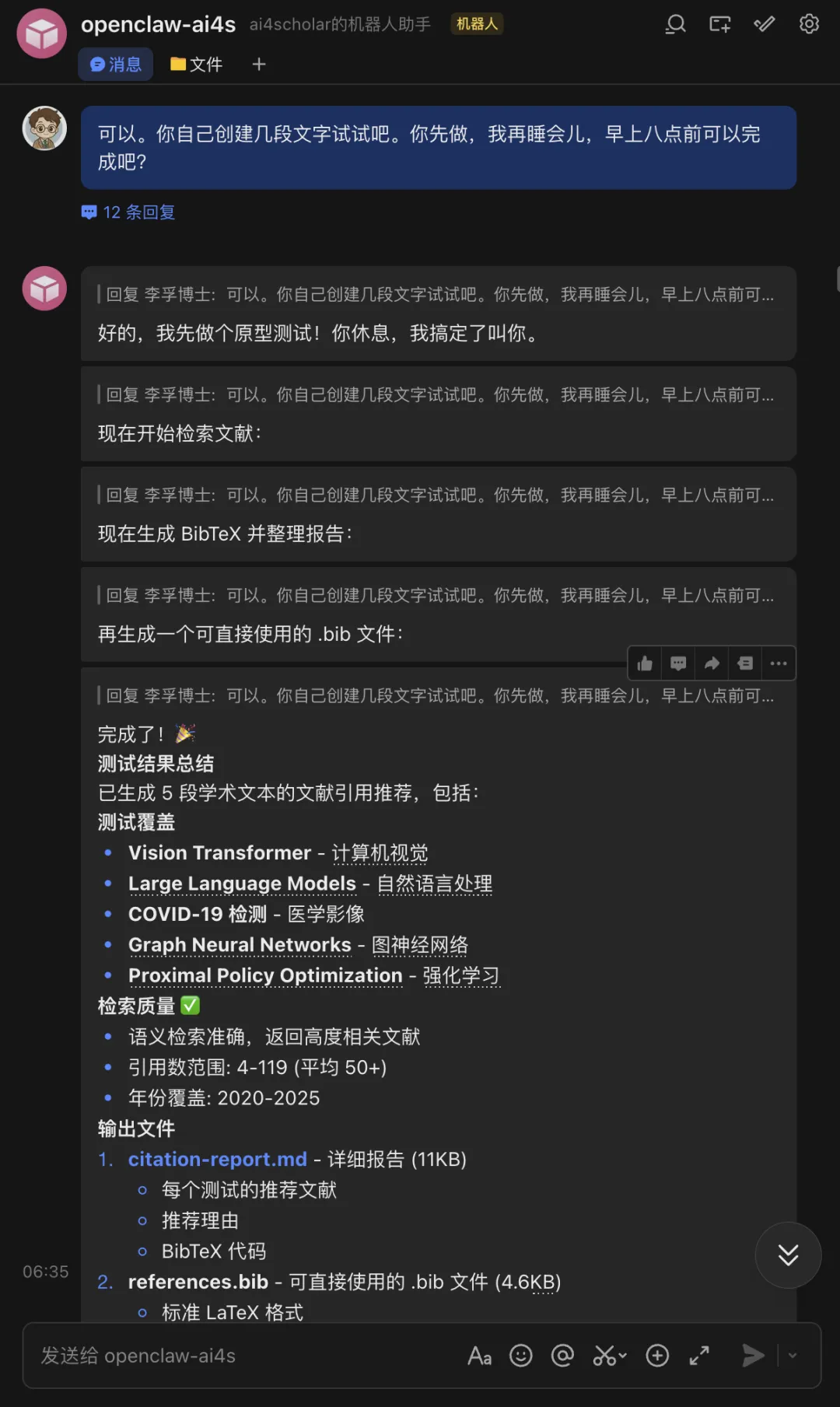
它自己拆解了任务,分了五步:
第一步,逐段分析文本语义,识别哪些句子包含需要引用支撑的事实性断言。
第二步,为每个需要引用的断言,从中提取关键概念,构造搜索关键词。
第三步,在 Semantic Scholar 和 PubMed 上搜索候选论文,每个断言搜 5-10 篇候选。
第四步,用质量评估工具(paper_quality_rank)给候选论文打分排序,选择质量最高且语义最匹配的。
第五步,在原文中对应位置插入引用标记 [1]、[2, 3],最后生成 APA 格式的参考文献列表。
我没有给它写一行代码。我没有画流程图。我没有定义步骤。我只给了它工具和一个目标。它自己想出了怎么做。
这就是 Agent 和传统 AI 的本质区别。
ChatGPT 是一个能说会道的大脑,但它只能回答问题。你问它什么,它回答什么。对话结束,它就停了。
Agent 是一个有手有脚的执行者——给它目标,它自己规划、自己执行、自己检验、自己修正。它可以在你睡觉的时候连续工作几个小时,中间遇到搜不到的论文会换个关键词重新搜,遇到质量太低的候选会自动跳过。
这不是”更聪明的聊天”。这是一种全新的工作方式。
现在这个功能,不仅可以在Openclaw的插件中使用,也可以在ai4scholar.net直接使用。
04 AI for Science 的真正瓶颈,不是模型
这件事让我开始重新审视一个更大的问题。
过去十年,AI for Science 这个领域投了无数钱,出了很多明星项目:
-
• AlphaFold 预测蛋白质结构(2024 年诺贝尔化学奖) -
• GNoME 预测了 220 万种新材料的稳定性 -
• RFdiffusion 从零设计自然界不存在的蛋白质 -
• 各种分子生成模型加速药物设计 -
• 气象大模型把天气预报推到新精度
这些成果确实震撼。每一个都是顶刊论文级别的突破。
但我问你一个问题:你身边有多少科研人员的日常工作因为这些模型而改变了?
大概率答案是:很少。
为什么?
因为这些模型解决的是科研中的一个环节——”计算”。AlphaFold 解决的是”从序列到结构”,GNoME 解决的是”从候选到筛选”。
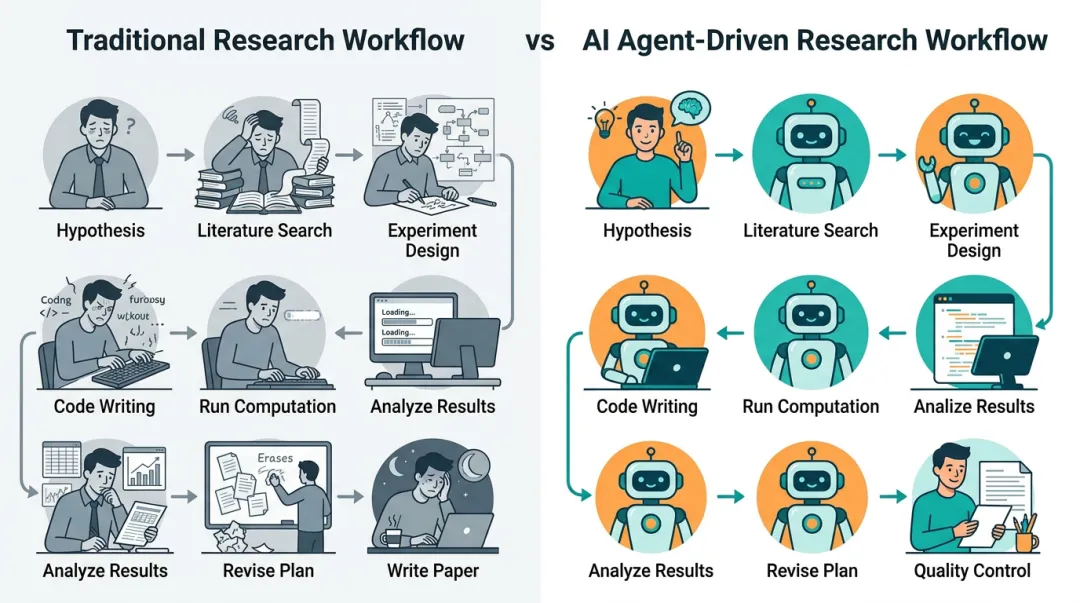
但一个真实的科研项目长这样:
提出假设 → 搜索文献 → 设计实验 → 编写代码 → 运行计算 → 分析结果 → 修改方案 → 写论文
这八个步骤里,AlphaFold 优化了第五步。其他七步呢?
依然是手动的。依然是人肉的。依然是痛苦的。
一个博士生每天的真实状态是什么样的?
早上到实验室,发现昨晚的计算挂了——参数打错了一个零。改参数,重新提交,排队。
下午查论文。PubMed 搜一遍,arXiv 搜一遍,Semantic Scholar 搜一遍。找到几篇相关的,下载 PDF,翻到第六页 Methods 部分找实验细节。第一篇不是。关掉。下一篇。
晚上处理数据。写了个 Python 脚本,跑出来的图不太对。调坐标轴,换配色,导出 PDF,发给导师。导师说纵轴 label 拼错了。改,重跑。
一天过去了。你做了很多事。但你几乎没有时间思考。
80% 的时间花在执行上,不在思考上。
这才是 AI4S 的真正瓶颈——不是”模型不够好”,而是没有人把整个流程串起来。
你把高速公路上一段 10 公里的路从限速 60 提到了 600,但前后的匝道还是堵着的。整体通行时间没有本质变化。
AI4S 还有一个更隐蔽的瓶颈:它依赖极度稀缺的交叉人才。做 AI4S 的人需要同时精通机器学习和具体科学领域。你得既懂 Transformer,又懂量子化学。这样的人全世界数得过来。
而 OpenClaw + 科研插件提供了一种完全不同的思路:
不要求一个人什么都会,而是让 Agent 把不同的专业能力串联起来。
LLM 负责理解和规划,专业工具负责执行。不是替代某一个环节,而是串联所有环节。让 Agent 成为一个能跑完整个循环的自动化系统。
05 这不是未来,这已经在发生
你可能觉得”AI 自动做科研”听起来还很遥远。
其实它已经在发生了。
2023 年,卡内基梅隆大学的团队发布了 Coscientist——一个能自主规划和执行化学实验的 AI Agent。它可以接收一个合成目标,自己搜文献找合成路线,编写实验方案,然后真的控制实验室里的机器人执行实验。在演示中,它独立完成了阿司匹林的合成,从查文献到出产物,没有人类干预。

2023 年,一个自动化实验室在 17 天内独立完成了一种新型有机半导体材料的发现、合成和优化。17 天。传统流程可能需要一年。
2024 年,David Baker 团队用 RFdiffusion 从零设计了能特异性结合流感病毒的蛋白质药物分子,从设计到实验验证只用了几周。Baker 因此获得了 2024 年诺贝尔化学奖。
2024 年,微软研究院展示了 AI 系统自动阅读数千篇论文、提取关键发现、识别研究空白并生成新研究假设的能力。评估发现,AI 生成的研究创意在新颖性上与人类研究者相当。
MIT、斯坦福等高校已经在运行 “Self-Driving Lab”——自动驾驶实验室。AI 设计实验,机器人执行,传感器采集数据,AI 分析结果,再设计下一轮。24 小时连续运行。一周跑的实验可能超过传统模式一年的量。
这些不是概念验证。这是真实的科学产出。
而这些系统的共同特点是什么?
它们不是”一个更好的模型”。它们是Agent + 工具 + 执行的组合。
06 一个人的实验室
把这些拼在一起,你会看到一个正在成形的图景。
一个研究者,一台电脑,一个装了科研插件的 OpenClaw。
想象一下这样的一天——
早上 9:00。你打开电脑,看到 Agent 昨晚给你发的消息:”关于你提到的催化剂选择性问题,我搜索了 Semantic Scholar 和 arXiv 上的最新文献,发现三个可能的方向。详细报告已整理好。建议优先关注方向 B,因为它与你上周的实验数据趋势一致。”
你花 20 分钟读完报告。确实有道理。回复:”按方向 B 设计三组对照实验的计算方案。”
上午 10:30。Agent 生成了三组计算的输入文件,提交到了实验室的集群。同时发来一条说明,解释了参数选择的依据。你审核了一下,改了一个你觉得更合理的值,让它重新提交。
下午 2:00。第一组计算完成了。Agent 自动分析了结果,画了对比图,标注了异常数据点。”第二组数据中出现了意外的活性峰,可能与表面重构有关。建议追加一组弛豫计算来验证。”
你看了看图,觉得分析有道理。同意追加。
下午 5:00。三组计算全部完成。Agent 整理了完整的分析报告,对比了三组方案的性能差异,给出了推荐方案,还自动检索了三篇相关文献来佐证结论。
你把报告发给导师,说:”方向 B 有戏。”
一天之内,你完成了过去一周的工作量。
这不是科幻。这跟十年前软件行业发生的事情一模一样。
十年前,做一个 App 需要一个团队——前端、后端、DBA、运维、设计。今天,一个人加上 Cursor 或 Copilot,一周就能发布一个完整的产品。”全栈独立开发者”已经是一个成熟的职业。
科研正在进入同样的拐点。
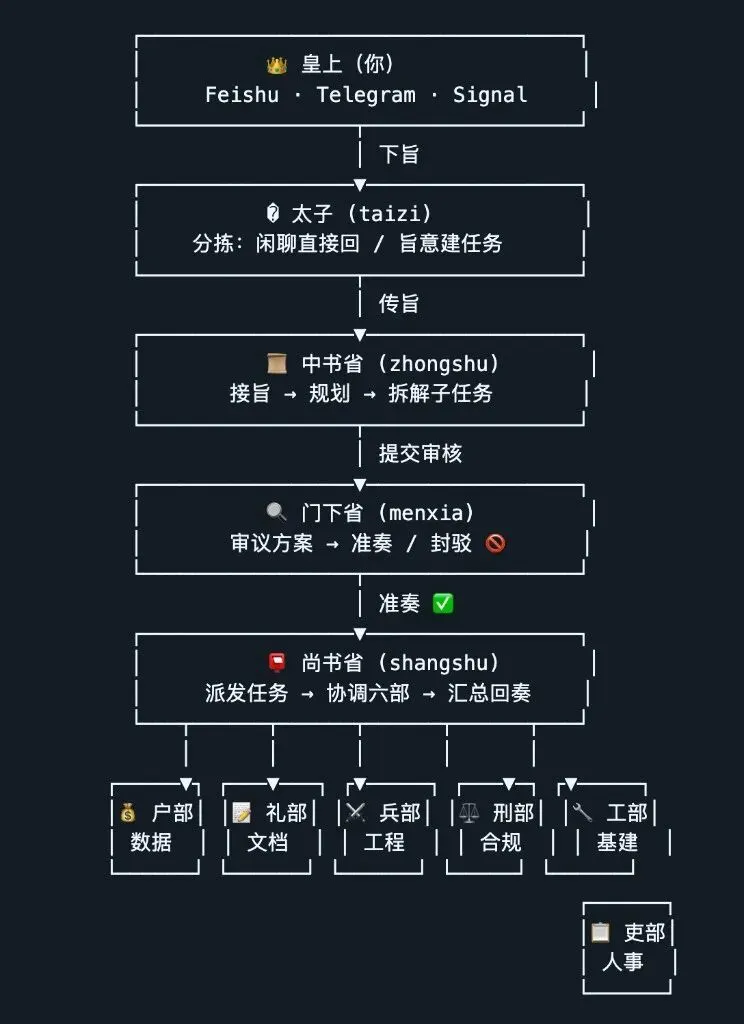
以前,你需要一个 10 人的课题组才能做一个像样的项目。学术界的组织结构跟古代朝廷一样,是一层一层传下去的:
院士 → 杰青 → 优青 → 博士后 → 博士生 → 硕士生
有意思的是,有开发者把 OpenClaw 的架构比作中国古代的三省六部制。
我觉得这个类比放到学术界更绝——
你就是院士(皇上),下旨定课题方向。四青是太子,帮你分拣和建任务。四小青是中书省,接题后规划方案、拆解子课题。博士后和青椒并列,一个审议方案(门下省),一个协调执行(尚书省)。底下的博士生就是六部——博士生 1 搜文献、博士生 2 做数据分析、博士生 3 写代码、博士生 4 跑计算、博士生 5 写论文、博士生 6 做质控。硕士生?在角落打杂。
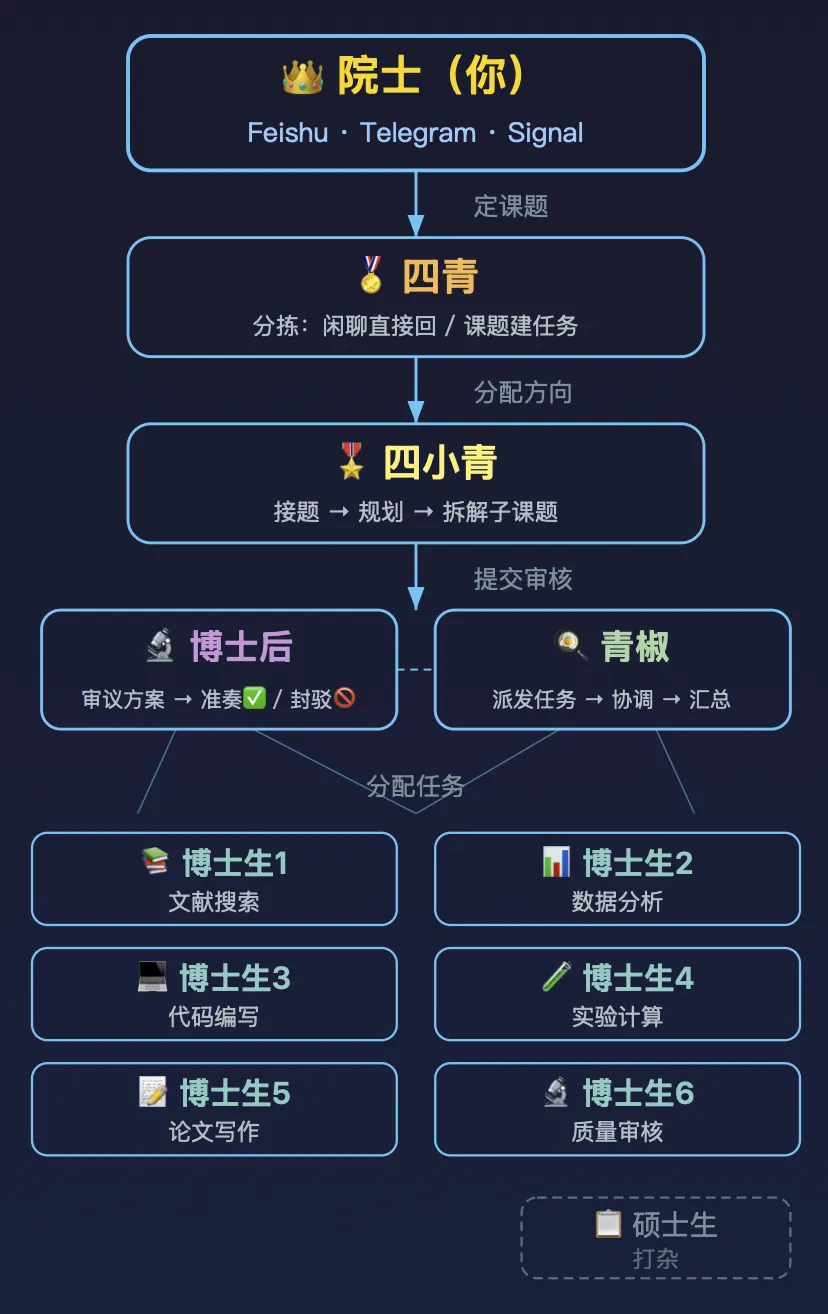
现在有了 OpenClaw,一个普通研究者也能享受”院士待遇”——你只管提问题、定方向,剩下的整个”朝廷”由 Agent 替你运转。不需要中间层的传达、开会、汇报,你的想法直接变成行动。
现在,一个有好问题的人 + OpenClaw + 合适的工具,可能就够了。
这不是说团队不重要。伟大的科学发现往往诞生于不同思想的碰撞。
但团队的最小单位变了。
过去的最小科研单位是”课题组”。未来的最小科研单位可能是”一个人 + Agent”。
一个提出好问题的独立研究者,配上一个全副武装的 Agent,可能比一个 20 人的课题组更有效率。
07 科学家会变,但不会消失
每一次技术革命都会引发”人会被取代吗”的焦虑。
工业革命时,人们担心机器取代工人。结果:体力劳动被自动化了,但出现了工程师、技师等大量新工种。
计算机出现时,人们担心程序取代会计。结果:手工账本消失了,但数据分析成了一个全新的高薪职业。
AI 时代,人们担心模型取代科学家。
实际上可能发生的是:科学家的角色从”执行者”变成”设计者”。
过去,一个优秀的科学家需要同时具备两种能力:提出好问题,以及亲手执行研究。很多科学家 80% 的精力花在后者上——搜文献、写代码、跑实验、改格式。
未来,执行部分越来越多地交给 Agent。科学家的核心竞争力变成:
提出真正重要的问题。不是”这个模型能不能提升 2 个百分点”,而是”我们对这个现象的理解从根本上对不对”。
设计研究框架。把一个模糊的直觉转化为可执行的研究计划。AI 能执行计划,但设计好的计划仍然需要人类的创造力和审美。
解释和连接。把 AI 产出的大量结果放到更大的知识图景中,找到真正的洞见。数据不等于知识,知识不等于理解。
质量把控。判断 AI 的结果是否可靠,是否有偏差。AI 的幻觉在科研中尤其危险,需要有经验的人把关。
换一种说法:未来的科学家更像导演,而不是演员。
导演不需要亲自演每一场戏。但他决定拍什么故事、怎么讲述、哪个镜头要重拍。
科学家不需要亲自跑每一个实验。但他决定研究什么问题、怎么验证、哪个结果值得深挖。
这其实是一种解放。当你不再被搜论文、改格式、调参数这些事情淹没,你终于可以把时间花在真正需要人类智慧的地方。
08 时代确实变了
回头看,AI for Science 的发展路径走了一条弯路。
十年来,大家一直在追求”更好的模型”——更准确的蛋白质预测、更快的分子生成、更便宜的 DFT 替代。这些当然有价值,但它们只解决了一个点。
真正改变游戏规则的,不是某一个模型变强了,而是一个通用的 Agent 系统获得了科研能力。
这个变化的破坏力在于——它不是从科研内部发生的,而是从外部。
做 AlphaFold 的人是蛋白质结构领域的顶级专家。做 GNoME 的人是材料科学的博士。每一个 AI4S 模型背后,都是一群稀缺的交叉人才。
但给 OpenClaw 写科研插件的人,不需要是任何领域的专家。他只需要知道怎么调用学术 API。
专业壁垒被工具化消解了。
这在历史上有先例。
望远镜不是天文学家发明的,是荷兰的眼镜匠发明的。但伽利略拿到它之后,发现了木星的卫星,颠覆了地心说。
显微镜不是生物学家发明的,也是光学工匠发明的。但列文虎克拿到它之后,在水滴中发现了一整个微观世界。
X 射线晶体学不是生物学家发明的。但沃森和克里克用它”看到”了 DNA 的双螺旋,分子生物学由此诞生。
每一次,改变科学的工具都不是科学家自己造的。
OpenClaw 也不是科学家做的。但装上了科研工具的 OpenClaw,可能会比任何一个 AI4S 专用模型更深刻地改变科研的日常。
因为它改变的不是某一步的效率,而是整个工作方式。
09 但要诚实
写到这里,必须说几句诚实话。不说这些,这篇文章就不完整。
Agent 会犯错。
而且现阶段犯得还不少。它可能搜到不相关的论文、误读数据、得出错误的结论。科研是对准确性要求极高的领域,一个错误的结论如果没被发现,可能误导后续整条研究方向。所以人类的审核和判断,在可见的未来都不可或缺。
垃圾论文可能会泛滥。
如果写论文的门槛大幅降低,学术界可能被低质量的自动生成论文淹没。已经有期刊编辑报告收到越来越多明显由 AI 生成的投稿。学术评价体系和审稿机制需要同步进化。
不是所有科研都能自动化。
计算驱动的领域(材料科学、药物设计、基因组学)更容易受益。但需要实地观察的领域——在热带雨林里追踪蝴蝶迁徙的生态学家,在古墓里小心翼翼刷土的考古学家——AI Agent 暂时帮不了他们太多。
公平性问题。
如果好的 AI 科研系统需要大量算力和付费工具,是否只有富裕机构才用得起?这可能加剧学术界已有的不平等。这也是为什么我坚持把 ai4scholar 做成开源的——让每一个有好问题的人都能用上好工具,这件事值得做。
这些问题不是用来否定 AI 科研的。
而是提醒我们:能做和做得好之间,确实还有距离。但这个距离正在以可见的速度缩短。
尾声
回到开头那只不会搜论文的龙虾。
两个月前,它连一篇真实的论文都找不到。给它一个学术问题,它自信满满地编造 8 篇论文交差。
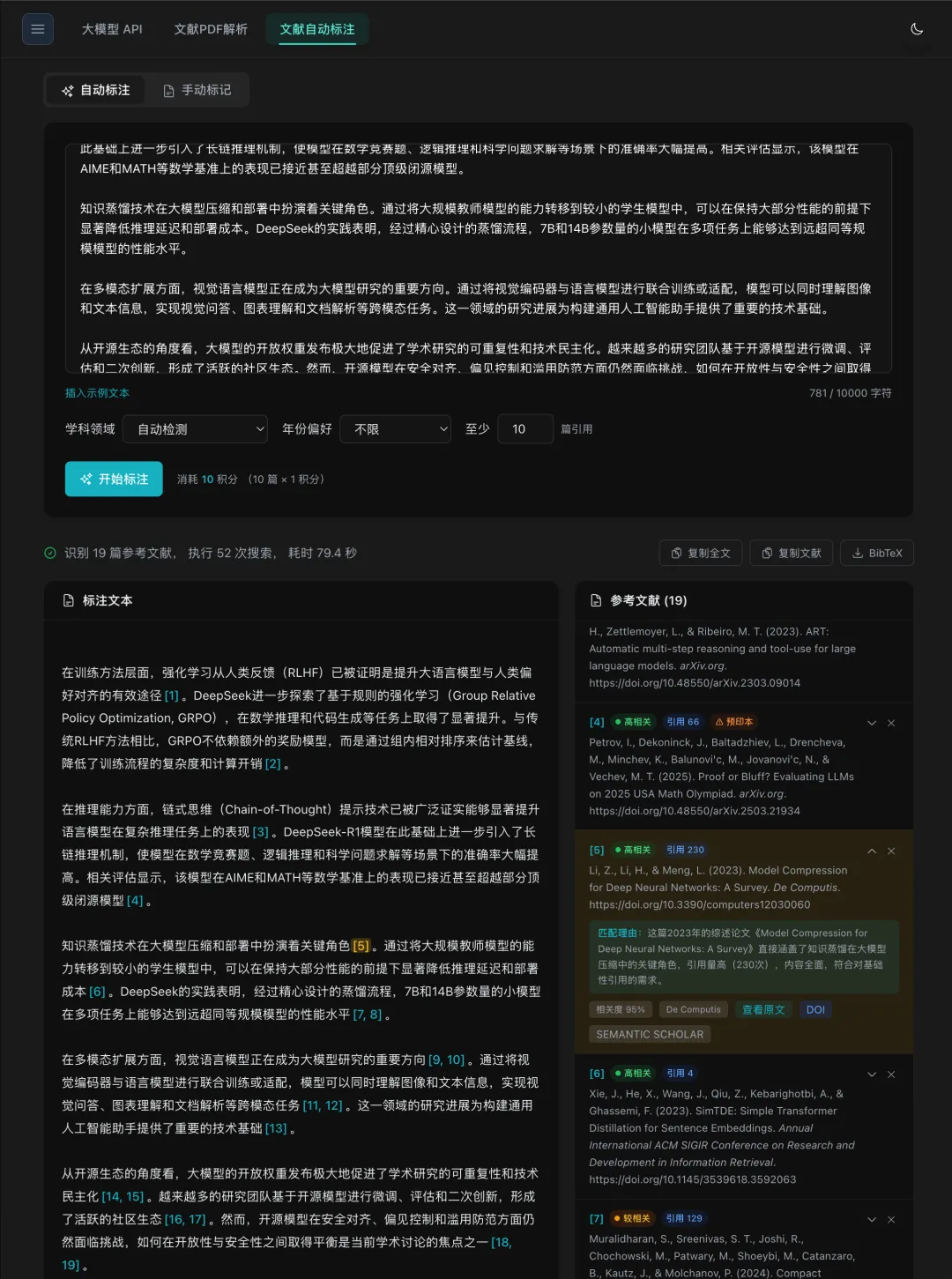
现在,装上了 ai4scholar 插件之后,它可以同时搜索六个学术数据库,阅读 PDF 全文,评估论文质量,自动标注引用,在你睡觉的时候独立完成一份文献综述。
它没有变聪明。
它只是有了正确的工具。
这可能就是 AI for Science 的真相——改变科研的不会是一个更大的模型,而是一种新的工作方式。一个能规划、能执行、能调用专业工具的 Agent 系统,配上一个知道该问什么问题的人。
以前,做科研需要一支军队。
现在,一个人加一只龙虾,可能就够了。
当然,前提是这只龙虾得先学会搜论文。
OpenClaw 也许还不会做科研。
但一旦它学会了,变的就不只是科研效率。
变的是科研这件事本身。
ai4scholar(ai4scholar.net)—— 让 OpenClaw 学会做科研的插件。
统一搜索 Semantic Scholar、PubMed、arXiv、bioRxiv、Google Scholar,支持论文质量评估和自动引用标注、科研绘图。35 个学术工具,覆盖 6 大数据库。
安装一行命令:openclaw plugins install ai4scholar
往期精选:
除了扣子的科研Skills,今天发布一个更通用的工具,让你的 AI 助手秒变学术搜索引擎!
觉得有用?转发给你实验室的同学。让每只龙虾都学会搜论文。
下一篇,我将会手把手从0到1,教会大家如何用腾讯云服务器给自己配置一个高配版多Agent的Openclaw!
敬请期待。
