 夜雨聆风
夜雨聆风





陈巍:“龙虾”们颠覆软件世界?(下)——OpenClaw(原Clawdbot)超深度分析
2026 年初发布的ClawdBot,其国外GitHub 星标迅速突破 180,000,并吸引数百万访问者。OpenClaw的崛起对现有的软件开发流程是很大的冲击。相对于传统软件动辄十到百倍的效率提升,会使得通用智能体在短时间代替大量的固定流程的软件。在这样的变革下,操作系统的形态都有可能被彻底颠覆。

主编作者:陈巍博士,大模型+AI芯片专家,高级职称。国际计算机学会(ACM)、中国计算机学会(CCF)专业会员,多个国际人工智能期刊审稿人。主要研究方向为大模型架构、稀疏压缩与部署加速,存算一体、AI芯片与3D Chiplet处理器。
全文目录
1 引言
2 背景与发展历史
2.1 项目起源
2.2 重命名历程
2.3 社区与流行度
2.4 生态定位
3 系统架构
3.1 整体框架与核心
3.2 组件分解
3.3 数据流分析
4 核心技术与功能
4.1 自主任务执行机制
4.2 持续记忆机制
4.3 模块化生态集成能力
4.4 AI增强模块
4.5 自托管部署
5 部署方案与应用案例
5.1 后端部署方案对比
5.2 应用案例研究
5.3 企业级部署分析
6 挑战、未来发展与结论
6.1 挑战与局限性
6.2 未来发展展望
6.3 对于OpenClaw的总结观点
自主任务智能体的分类
4.1 自主任务执行机制
OpenClaw的任务执行机制采用“行动导向”设计,将智能体定位为一个持续运行的自主任务系统,而非单纯的聊天工具。该机制的核心是智能体循环(agentic loop):持续进行提取(intake)、上下文解析(context assembly)、模型推理(model inference)、工具执行(tool execution)、流式回复(streaming replies)和持久化(persistence)。这一循环通过事件触发(如心跳heartbeat、cron定时器、聊天事件)实现主动性。典型的例子就是智能体自主查看邮箱并发送提醒,而无需用户干预。换而言之,OpenClaw开启了007数字牛马(指自主任务大模型)的新篇章。
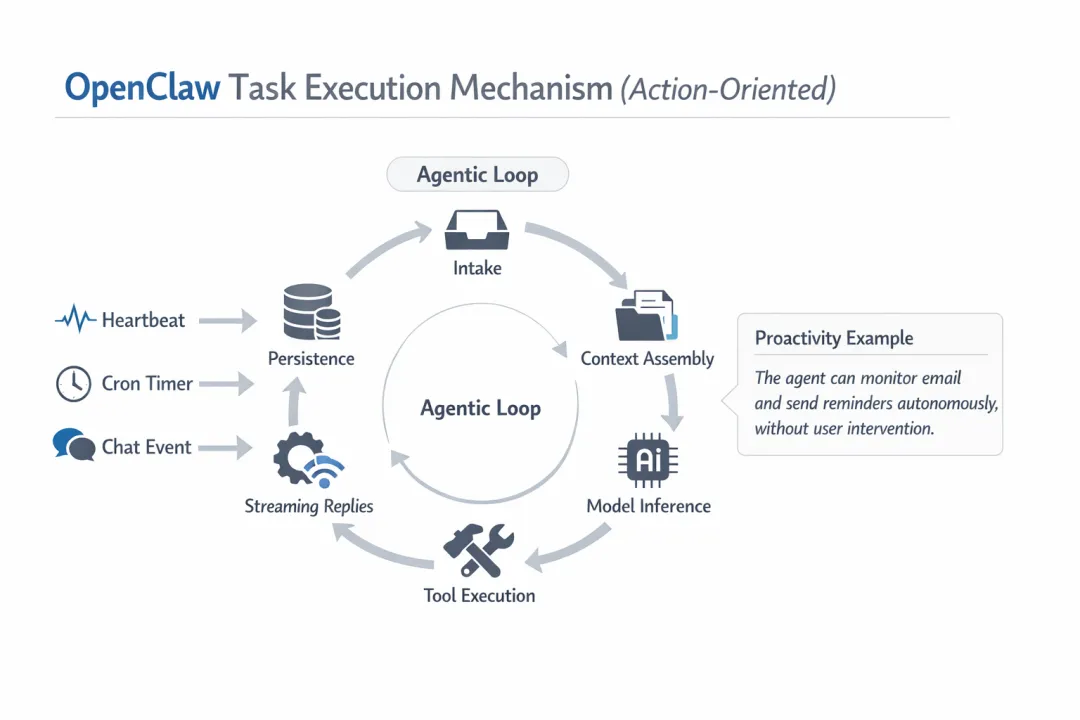
OpenClaw中的智能体循环
在OpenClaw中,工具调用(tool-calling)是执行的关键,即通过模型无关的接口(如RPC模式)调用内置工具,例如浏览器自动化(基于Chrome DevTools Protocol, CDP,实现网页抓取、表单填充和数据提取)、文件系统访问(read/write工具,用于文档处理)和shell脚本命令执行(system.run,用于运行本地脚本)。除了软件调用,OpenClaw的环境交互也可扩展到现实世界,如控制智能家居设备(如智能灯、空气净化器等)或动作控制(如设定机器狗的行进路径)。这些工具调用支持异步执行和流式处理,以确保OpenClaw与外界的高效交互。
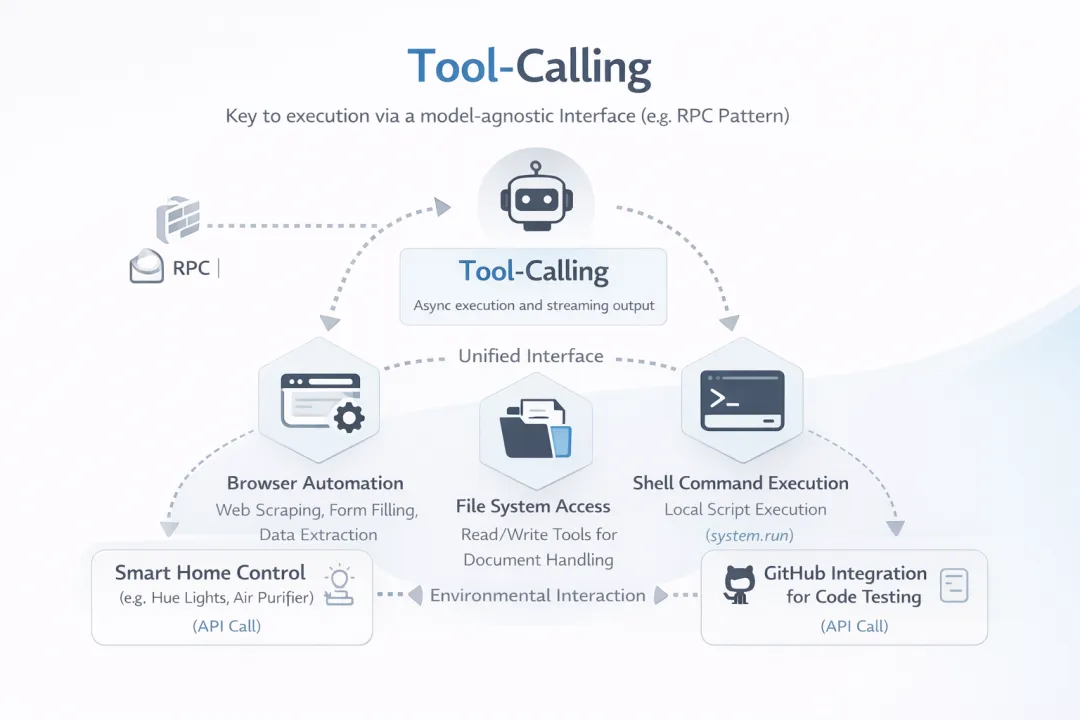
工具调用
为确保工具调用不被操作异常打断,OpenClaw内建了错误恢复策略。该策略包括重试机制(retry policies,用于处理API失败或网络中断)、模型故障转移(model failover,指切换到备用模型,如从Claude到GPT)和会话修剪(session pruning,自动清理无效上下文以避免token溢出)。此外,通过webhooks(如Sentry集成)捕获错误,并允许智能体自主修复(重新运行失败的任务或调整策略)。虽然这一恢复策略可能在复杂任务中引入延迟,但在高度不确定的软硬件环境中(如互联网访问操作中出现无法访问或浏览器崩溃)可以确保任务系统的稳定。
4.2 持续记忆机制
如果仅有自主任务能力,智能体还不足以像人类那样系统且有条理的完成工作。相对于其他智能体,OpenClaw最大的特点就是有了持续记忆机制和所谓的“灵魂”。
OpenClaw利用SOUL-TOOLS-USER-Session四层记忆体系来实现持续记忆机制。
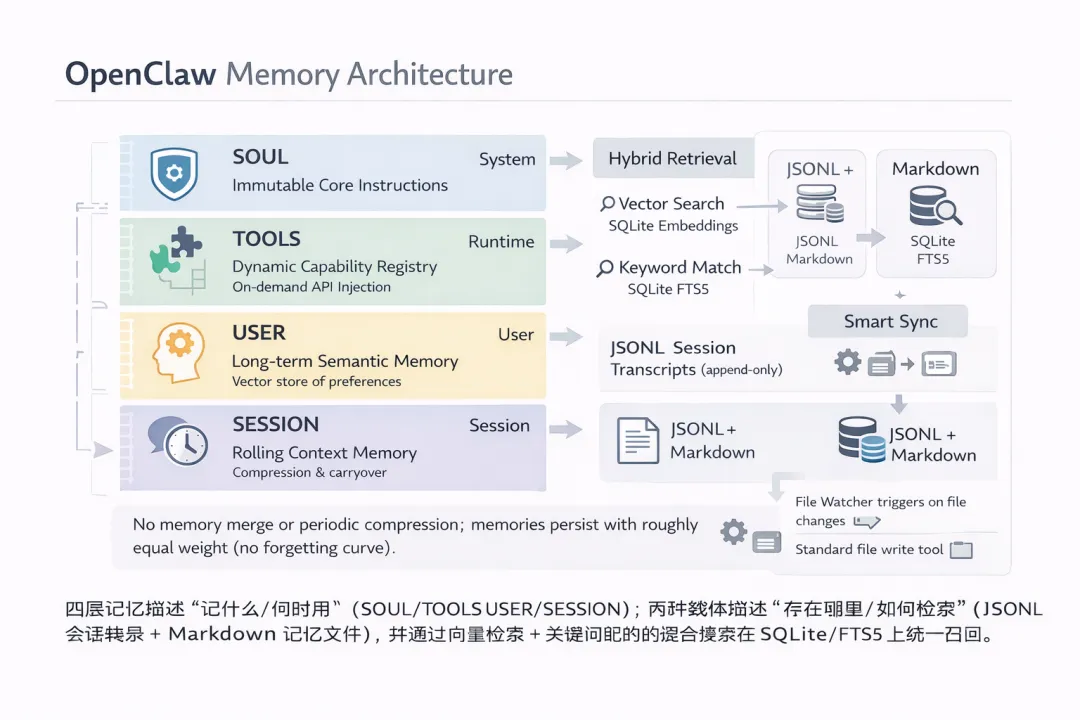
OpenClaw通过SOUL/TOOLS/USER/SESSION的Markdown记忆实现持续记忆机制
SOUL层:不可变的内核存储,涵盖智能体的底层系统指令,定义基本行为模式。SOUL层就像人的核心价值观和行为模式,在整个智能体的生命周期中保持稳定,确保行为可预测、可解释。
TOOLS层:动态能力注册表,根据当前任务按需注入可用的API。TOOLS层的按需加载大幅降低token消耗,提升响应速度和决策精准度。
USER层:语义向量记忆库,也是OpenClaw最”智能”的部分。USER层基于语义向量构建长期记忆,自动提取用户的偏好、习惯、工作方式、专业背景等关键信息。OpenClaw会像人类小助手那样,在交互中自动暗中观察用户,模仿行为习惯和代码风格,从而实现越用越贴心、越来越懂你。这也正是构建个性化智能体的关键。
Session层:实时情景记忆、智能化的上下文压缩与滚动机制,自动识别关键信息,压缩冗余内容但保留核心语义,滚动带入历史对话的高关联或有价值片段。
在OpenClaw中,是通过两个载体实现持续记忆机制。一是 JSONL 格式会话转录文件,二是存放在 MEMORY.md 或 memory/ 文件夹下的 Markdown 记忆文件。这些 Markdown 文件由智能体使用标准的写入操作生成(向 memory/*.md 写入内容)。无需专用的“记忆写入 API”。当新对话开始时,一个Hook会抓取之前的对话内容,并写下一份 Markdown 格式的摘要。
为了确保记忆匹配的高效,OpenClaw采用了向量检索(Vector Search)与关键词匹配(Keyword Match)的混合检索模式。这一混合检索模式也是提升效率的关键,录入当检索“身份验证漏洞(authentication bug)”时,既能依据语义相关找到提到“登录问题(auth issues)”的文档,也能按照关键词匹配找到包含精确词组的内容。在技术实现上,向量检索直接使用 SQLite,关键词搜索通过 FTS5(SQLite 扩展),嵌入模型(Embedding,用于将对话转为计算前大模型可读的内通)可按照应用场景配置。
需要注意的是,OpenClaw 的记忆机制中没有记忆合并或月度/周度的记忆压缩。在这种简洁的存储机制下,智能体的记忆会永久保存,新记忆与旧记忆的权重基本相等。可以说,OpenClaw是不存在“遗忘曲线”的,当然这种方式也增加了存储系统的负担。
4.3 模块化生态集成能力
为了拓展能力,OpenClaw通过模块化技能系统和通道连接实现生态集成,支持广泛的内置技能(SKILL)和社区应用扩展。OpenClaw内置多项常用操作技能,例如邮箱管理(Gmail/Outlook集成,用于清理收件箱、发送邮件)、日历调度(Google Calendar,用于会议安排和提醒)、航班check-in(通过API查询和自动化处理)、音乐控制(Spotify集成)和健康追踪(WHOOP数据分析)。这些技能都以Markdown文件形式存储在工作区(workspace),允许智能体直接访问和修改本地数据,实现无缝衔接的自动化。
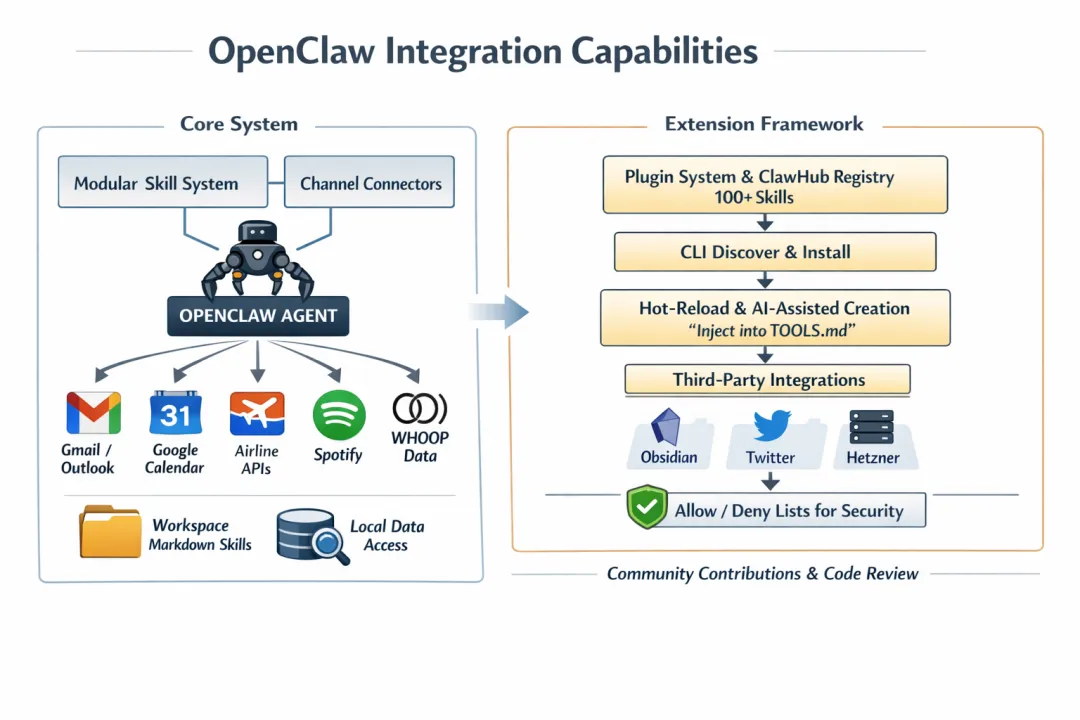
OpenClaw的模块化集成
扩展框架基于插件系统和技能注册表(ClawHub),包含超过100个预构建技能,用户可通过CLI命令查找和安装,也可自定义新技能。生态集成强调可热重载(hot-reload)和AI辅助创建:智能体可从聊天或视频中生成自定义的技能(如短视频网站的视频处理),并注入到TOOLS.md文件中。扩展框架支持第三方集成,如Obsidian笔记和Hetzner服务器管理,通过允许/拒绝列表(allow/deny lists)控制访问权限,保障安全性。
4.4 AI增强模块
OpenClaw的AI增强模块聚焦于多智能体协作和自适应学习,并构建了一个分布式智能体生态。
多智能体系统(multi-agent systems)通过sessions工具实现智能体间通信,支持智能体层次化(主管智能体和委托专家智能体)和并行任务(例如一个智能体监控邮箱,另一个处理日历)。这一设计允许实例复制或跨会话内存迁移,实现复杂工作流,如跨设备协调。
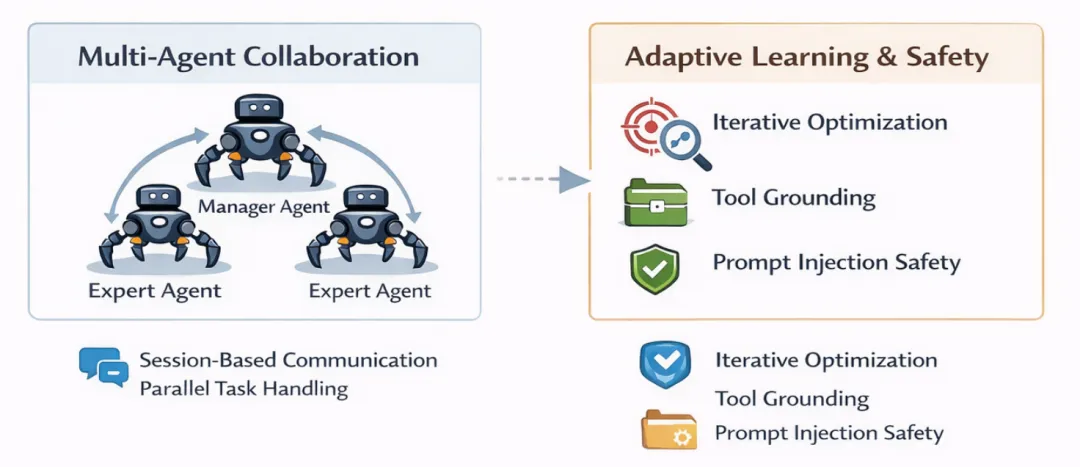
通过会话式通信实现分布式多智能体协作
自适应学习是OpenClaw相对其他智能体的显著进步。OpenClaw可通过任务结果迭代优化(基于历史反馈调整),并支持自修改(如重写自身代码、编辑提示文件SOUL.md/AGENTS.md)。自适应学习的能力通过持久化的记忆机制(Markdown文件存储上下文、偏好和历史)长期保留,无需每次会话从零开始。这种模式意味着智能体自身的不断学习和优化,不断适应用户的喜好和需求。
针对大模型容易出现的幻觉和偏见,OpenClaw通过工具 grounding(将响应锚定在实际数据/动作上)、沙箱隔离(限制非主会话的工具访问)和提示注入防护(审核不受信任输入,使用长上下文模型增强抵抗力)来进行纠正,减小幻觉和偏见造成的损失。
4.5 自托管部署
与云原生的各类智能体不同,OpenClaw的从诞生起就自托管部署强调本地优先(local-first)的自托管部署,天然支持本地文件操作,支持本地LLM(如Ollama)以减少延迟和Token消耗。
为确保安全性,OpenClaw采用安全沙箱(包括per-agent/session沙箱)、allow/deny lists控制工具(如对非主会话禁用浏览器)和workspace访问权限控制模式进行自托管的权限控制,防止权限滥用。
5 部署方案与应用案例
对于OpenClaw来说,部署方案对其性能和安全性有显著的影响。
下面将对OpenClaw不同部署方案和应用案例进行对比。对比主要聚焦响应延迟、任务成功率和资源消耗,特别是不同大模型后端如Claude Opus vs.本地Ollama的差异。对比表明,OpenClaw在轻量任务中表现出色,但在高复杂场景下需进一步优化部署方案以避免瓶颈。
OpenClaw的云部署与本地部署对比
5.1 后端部署方案对比
基于互联网数据参考,我们对比分析了在OpenClaw基准测试框架下,同类任务的响应时间和资源使用率。核心指标包括响应延迟(从用户输入到结果反馈的时间,以毫秒计)、任务成功率(完成率百分比)和资源消耗(CPU/GPU利用率、内存占用)。
不通部署方案对比(国内模型匿名对比)
|
对比维度 |
Claude (云端) |
GPT-5 (云端) |
KXXX(云API) |
QXXX-3-14B (本地) |
|
首token延迟 |
~800ms |
~600ms |
~450ms |
~150ms (低负载) |
|
端到端任务延迟 |
较高 (推理较深) |
中等 |
低 (响应快) |
极低 |
|
任务成功率 |
~98% |
~95% |
~88% |
~65% |
|
长上下文保持力 |
极强 |
极强 |
强 |
较弱(128k性能下降) |
响应延迟在本地部署中平均为1-5秒,取决于模型复杂度;使用云LLM如Claude时,延迟可增至10-15秒。任务成功率在简单任务(如文件组织)中达85-95%,但在复杂多步任务中降至60-70%,主要问题来自模型幻觉或工具运行失败。在资源消耗方面,Mac Mini的CPU利用率峰值可达70-90%,内存占用2-8GB。
不同LLM后端的对比显示,如采用Claude Opus作为“大脑”模型,可提供更高成功率(80%)但同时延迟和Token成本也更高;本地Ollama降低延迟20-30%或更多,但成功率降10-15%,Token成本却比云调用会便宜很多,更有利于长程任务的高性价比部署。具体使用哪种部署方案,应结合实际需求选择。
5.2 应用案例研究
通过对OpenClaw的一些具体应用案例进行研究,可以发现OpenClaw在一些常规任务上的效率优势是巨大的。考虑到通用智能体的快速发展,很多行业软件都可能面临生存问题。
5.2.1 自动化财务报告生成
在传统的财务人员工作中,完成财务报告需要收集数据、手动操作分析和格式化,通常耗时30-60分钟。OpenClaw则通过工具调用(如浏览器自动操作和文件管理)的自动化流程,进行意图解析、API调用(如Google Sheets集成)和报告生成,平均耗时15-30秒(调用云API),实现效率提升60-120x。
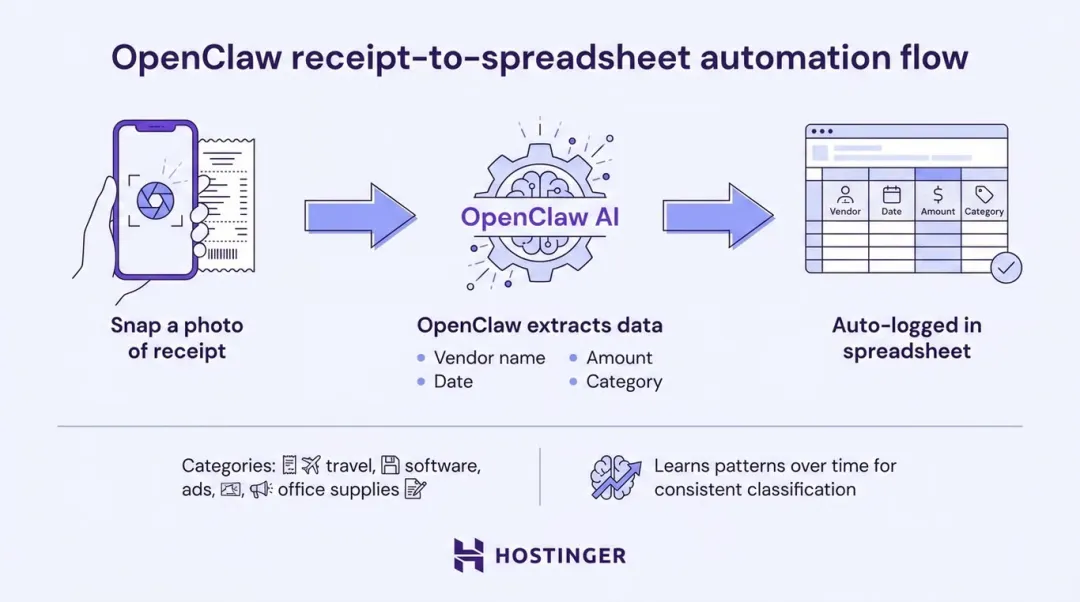
OpenClaw处理报表
具体流程如下:
1)用户输入“生成上月财务报告”触发意图解析。
2)智能体调用工具检索数据(如邮箱附件或API)。
3)执行计算(Python技能)。
4)输出Markdown报告。
这一流程成功率达75-85%(相对基准),失败主要原因是数据不完整需重试。
相比人工手动操作软件的流程,自动化的OpenClaw可以节省人力90%以上。类似的办公操作,如邮箱管理(手动15min vs. AI 15s,提升60x)或市场研究(手动10min vs. AI 15s,提升40x),均显示出智能体的效率显著提升。
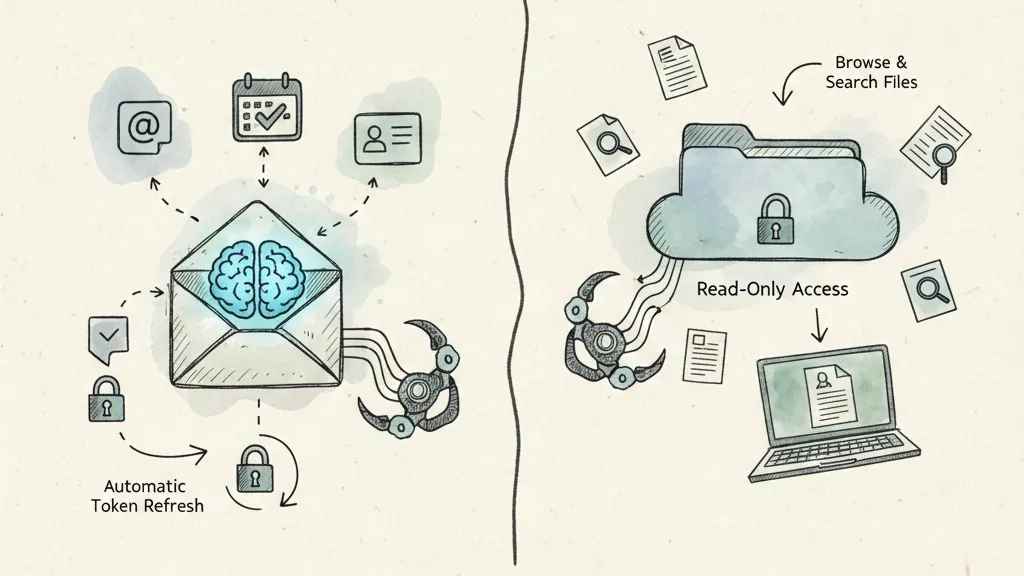
OpenClaw调取与整理文件
5.2.2 学术文献综述自动化生成
在传统学术研究中,一般需要定期进行领域文献调研,撰写综述报告,跟进技术进展。针对科研人员在特定领域XX技术的快速调研需求,用户在OpenClaw中输入“总结过去三年关XX某技术的最新进展”后,对话触发自主任务,OpenClaw通过搜索引擎和ArXivSKILL检索论文,下载相关文献的PDF,并通过长上下文进行交叉对比和信息浓缩。
具体流程如下:
1)意图解析(1s)。
2)多源文献并行检索(10s)。
3)内容浓缩。
4)Markdown综述生成。
这一流程的成功率约 80%,失败主要原因在于某些付费文献的访问受限。
相比传统的手工阅读,OpenClaw能通过并行检索提高效率,并基于持久记忆记住调用过的论文,避免重复提取,节省人力95%以上。
5.2.3 智能家居与跨设备调度
OpenClaw可在智能家居场景执行更智能的任务。
例如根据天气预报自动调节办公环境,用户可设定触发“如果明天下午北京房山有大雨,请提醒我带伞并提前关闭卧室窗户”。如果按照常规流程,用户手动操作查询天气预报、手动设置定时提醒、手动操作App关窗,人类用户就会耗时5-10分钟。OpenClaw则会持续监测天气API,静默监控并在触发瞬间执行,用户感知耗时接近0秒。
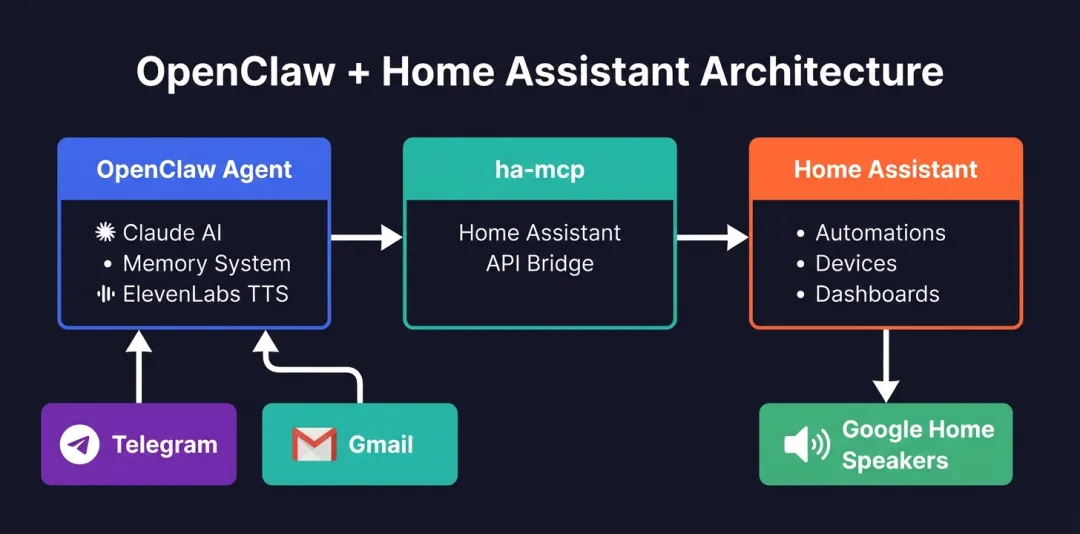
OpenClaw的家居部署
具体流程如下:
1)定时巡检(后台运行)。
2)条件匹配后调用Home Assistant技能。
3)通过聊天APP发送客户确认。
4)确认后发送执行关窗操作。
这一任务确定性相对较高,成功率高达95%。特别是与普通智能家居不同,OpenClaw可以理解非结构化指令(如“根据明天的天气决定是否需要浇花”),具备一定逻辑判断能力和常识,而非简单的IF-THEN逻辑。
5.3 企业级部署分析
OpenClaw运行包括高负载和高并发场景。高负载场景下,OpenClaw的瓶颈主要包括并发任务处理(序列化执行导致延迟堆积)和上下文管理(长会话溢出Token限制)。而在多智能体协作中,事件驱动架构需支持并行,高并发(>10任务/分钟)下CPU负载可瞬时增加到90%,网络延迟增30-50%。
为了实现高负载和高并发支持,通常会采取分布式部署方案,通过Docker容器化和云集成(如Cloudflare Workers或Virtual Private Server)实现扩展,支持多节点(如Mac Mini集群)处理并发负载。分布式部署的优势在于自动缩放以降低瓶颈,挑战在于通信开销和安全风险增加,一般采用用auto-scaling和监控工具缓解性能瓶颈,以支持企业级扩展。
目前典型OpenClaw分布式部署案例主要包括混合云集群和边缘沙箱两类架构。
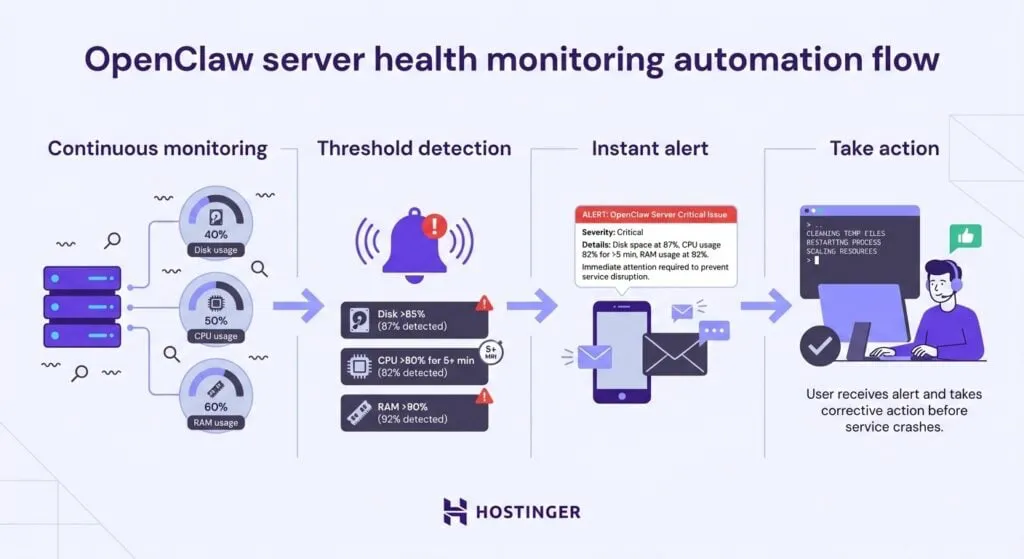
OpenClaw服务器管理
5.3.1 混合云集群架构 (Mac Mini + VPS/Docker)
混合云集群的目标是平衡本地文件安全与远程高可用性。
1)控制节点(Master Node):通常部署在始终在线的VPS(Virtual Private Server,虚拟专用服务器)或Cloudflare Worker上,负责接收来自通信APP(如飞书、钉钉)的用户请求,并进行初步的意图解析(Intent Parsing)。
2)执行节点 (Worker Nodes)通常分为以下几部分:
a)本地节点: 使用MacMini 运行Docker容器。负责处理本地文件访问、执行Shell脚本或操作本地智能家居的SKILL。
b)远程节点: 部署在虚拟服务器镜像中,专门处理高并发的Web爬虫、API调用和数据计算任务。
c)通信层: 通过加密的虚拟私有网络(Overlay Network)建立连接,即使节点跨越地理位置,也能像在局域网内一样通过 gateway 互相调用。
d)状态同步: 使用Redis等存储服务保存Session状态,以避免单机Node.js内存溢出问题。
5.3.2 边缘沙箱架构
边缘沙箱(Edge Sandbox)架构针对追求“极低延迟”和“自动缩放”的企业级场景。
沙箱整合大数据平台计算资源,支持大规模数据并行计算,整个企业或集团能够集中在分布式平台中进行数据分析挖掘。除了企业/集团数据,也可接入外部数据,多平台各层互通,保证数据可获得性、一致性、提高效率。
●持久化层(Persistence):使用分布式存储系统保存OpenClaw的MEMORY.md和配置文件,使智能体在重启或迁移节点时能保持“长效记忆”。
●安全沙箱: 所有的Tool调用(如Browser渲染)都在沙箱的浏览器API中运行,确保即使模型产生幻觉执行了恶意操作,也不会波及主服务器。
●监控集成: 实时捕捉Token超限制等异常(例如Token Limit Exceeded或Loop Limit Reached),并在并发负载超过 10 任务/分钟时自动触发降级逻辑(如从Claude 4.5切换到较低模型以节约成本和降低延迟)。
6 挑战、未来发展与结论
OpenClaw的崛起充分展示了自主任务AI智能体领域的动态张力:一方面,其爆炸式增长展示了社区驱动创新和技术需求的潜力;另一方面,安全漏洞和快速迭代暴露了成熟度安全度不足的风险。OpenClaw虽在短期内取得显著成就,但仍面临技术瓶颈、监管压力和其他智能体的竞争风险。按照目前的发展趋势,OpenClaw可能推动AI智能体向分布式、更高效率和安全性的方向转型,并在一定程度上瓦解现有软件行业的产品和商业模式,甚至对主流操作系统产生巨大的冲击。
OpenClaw的崛起
6.1 挑战与局限性
OpenClaw的当前版本虽功能强大,但存在面临一定技术挑战。包括:
1)碎片化的模型耦合。例如仍依赖云上的大模型如Claude或GPT,对模型指令跟随要求高,导致成本和延迟波动。
2)集成不稳定性。例如浏览器工具或API调用在高负载下易失败。
3)作为开源框架,OpenClaw的维护挑战尤为突出。githubrepo的快速迭代(每日数百次提交)容易导致兼容性问题,特别是SKILL插件更新后容易破坏现有工作流,社区报告显示GitHub issues中兼容性bug占比约25-30%。
4)OpenClaw的自修改能力虽然可以提高性能,但也有可能放大幻觉导致的“错误演进”风险。
5)商用自主任务智能体的竞争。例如 Anthropic Claude 提供的垂直集成智能体或许在安全性和可控性上有更商业友好的解决方案。
6)智能体监管风险。目前智能体有大量的自主甚至威胁网络安全的任务能力,对于智能体的监管条例还处于空白。各国政府可能要求对自主智能体进行监管,限制隐私信息操作和高危网络操作,以避免具备造假能力的SKILL窃取或假冒人类身份实时非法活动。
6.2 未来发展展望
目前可以预期的OpenClaw技术发展方向主要包括以下几点。
1)将引入语音和图像能力。例如通过接入语音处理、结合视觉模型实现图像甚至视频理解。
2)优化边缘计算集成,提升在边缘设备计算效率,以减少对云端大模型的依赖。
3)安全性增强(例如Docker沙箱升级)。
4)扩展企业级功能(审计日志、SSO)。
5)多智能体协作框架持续发展,并成为行业标准。
OpenClaw与编程框架的结合
从市场发展趋势看,OpenClaw 具备与 Web3 和 AIoT融合的空间。例如,通过引入 相关交易协议,使智能体能够自主参与经济活动,包括自主购买数据、租用算力或获取收益。在 AIoT 场景下,智能体可用于控制智能设备,逐步形成分布式的智能体网络。在向企业级演进的路径上,团队管理和权限控制将成为关键,使其能够从“影子 IT”工具转型为正式系统。一旦OpenClaw的安全性问题得到妥善解决,极有可能快速引爆这一潜在市场。
OpenClaw+Web3
6.3 对于OpenClaw的总结观点
OpenClaw的崛起,充分证明在极少数技术人员的引导下,社区驱动的自主任务智能体可以快速爆发,对现有的软件开发流程是很大的冲击。相对于传统软件动辄十到百倍的效率提升,会使得通用智能体在短时间代替大量的固定流程的软件。
在这样的变革下,操作系统的形态也有可能被颠覆,很有可能未来主流的操作系统是给智能体用的而不是人类操作。对于计算行业来说,智能体所需的海量Token会大大加速计算产业的扩张,是不亚于deepseek的算力强心剂。在未来,OPC(一人公司)可能越来越流行,算力有可能替代能源成为产业的基础设施。
推荐阅读
陈巍:“龙虾”们颠覆软件世界?(上)——OpenClaw(原Clawdbot)超深度分析
