 夜雨聆风
夜雨聆风





文档解析多模态最新进展:GLM-OCR及Agentar-Fin-OCR金融解析设计思路
今天是2026年3月13日,星期五,北京,天气阴
来看文档解析最新进展,两个模型技术报告,一个是GLM-OCR,一个是Agentar-Fin-OCR做金融文档解析,其中提到的表格合并,目录层级恢复的思路很有启发。
都有特点,可看看是设计思路。
多思考,着重看思路,会有收获。
一、GLM-OCR
GLM-OCRTechnical Report发布,https://arxiv.org/pdf/2603.10910,可以先回顾下文档解析多模态大模型都有哪些?
如下:
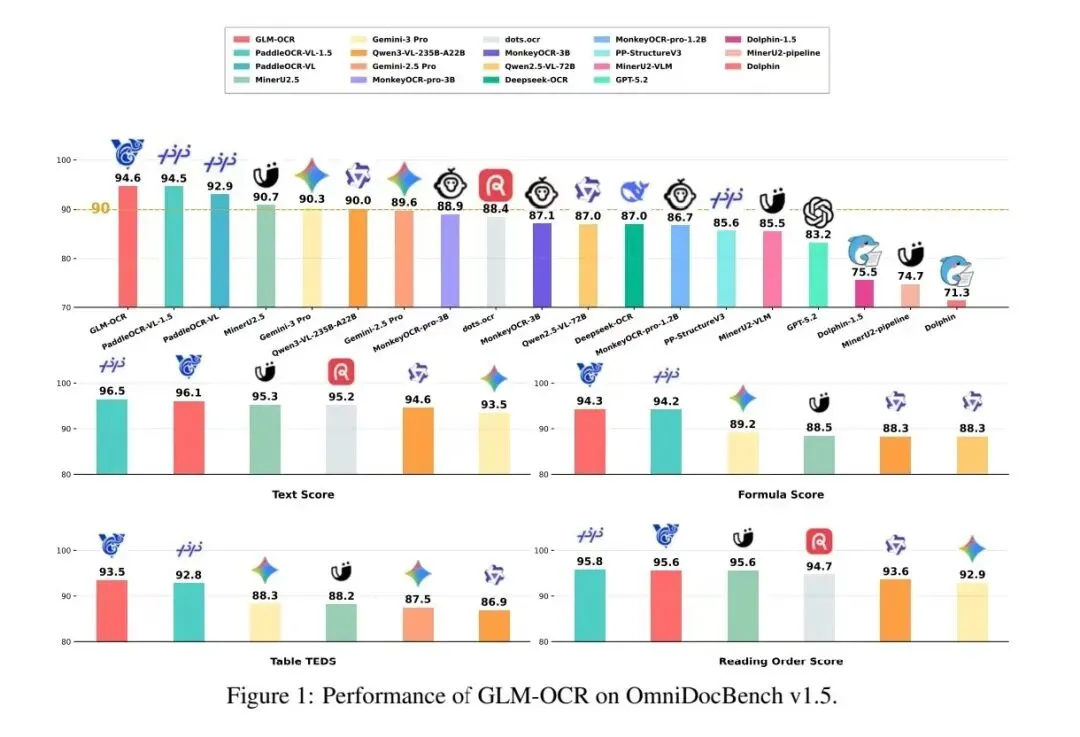
而对于GLM-OCR,重点看以下几点:
1、基础结构
由0.4B参数量CogViT视觉编码器+0.5B参数量GLM语言解码器组成,基于GLM-V编解码框架,整体参数量0.9B。
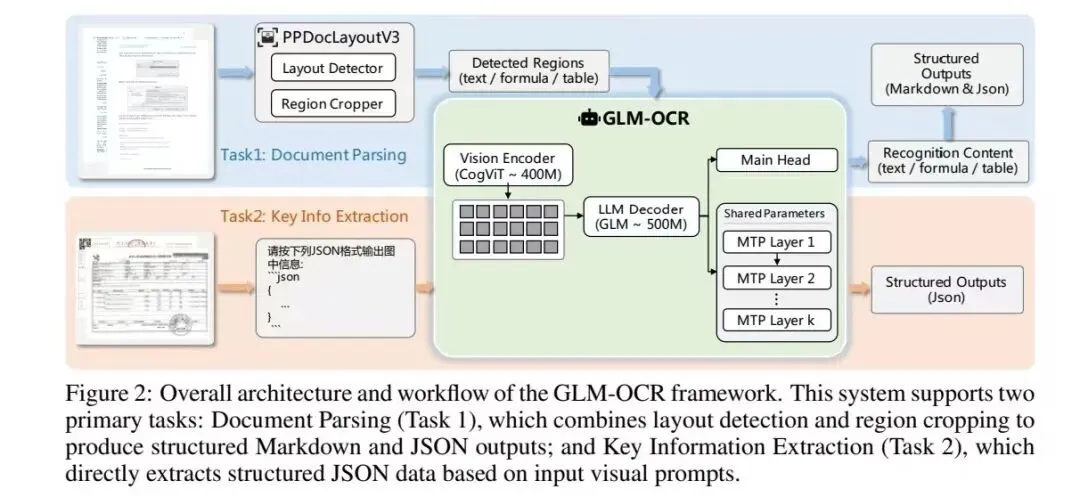
2、多token预测(MTP)
主要用于解决自回归解码效率低问题,单步可预测多个token,推理时平均每步生成5.2个token,吞吐提升约50%,通过参数共享控制内存开销。
3、两阶段处理流水线
先由PP-DocLayout-V3完成文档布局分析,再对各区域并行识别。
4、支持任务
一个是支持文档解析:布局分析→区域裁剪→GLM-OCR识别→结果聚合,输出Markdown/JSON结构化格式。
一个是支持关键信息提取(KIE):直接输入整图+任务提示词,模型隐式关注关键区域,输出JSON结构化结果。
如下示意图∶
二、Agentar-Fin-OCR金融文档解析设计思路
继续看Agentar-Fin-OCR金融文档解析,点在于通过跨页内容整合、文档级标题层级重构(DHR)模块来应对金融文档布局复杂、跨页结构不连续等问题,工作在:《Agentar-Fin-OCR》,https://arxiv.org/pdf/2603.11044,可以看看核心几个点:
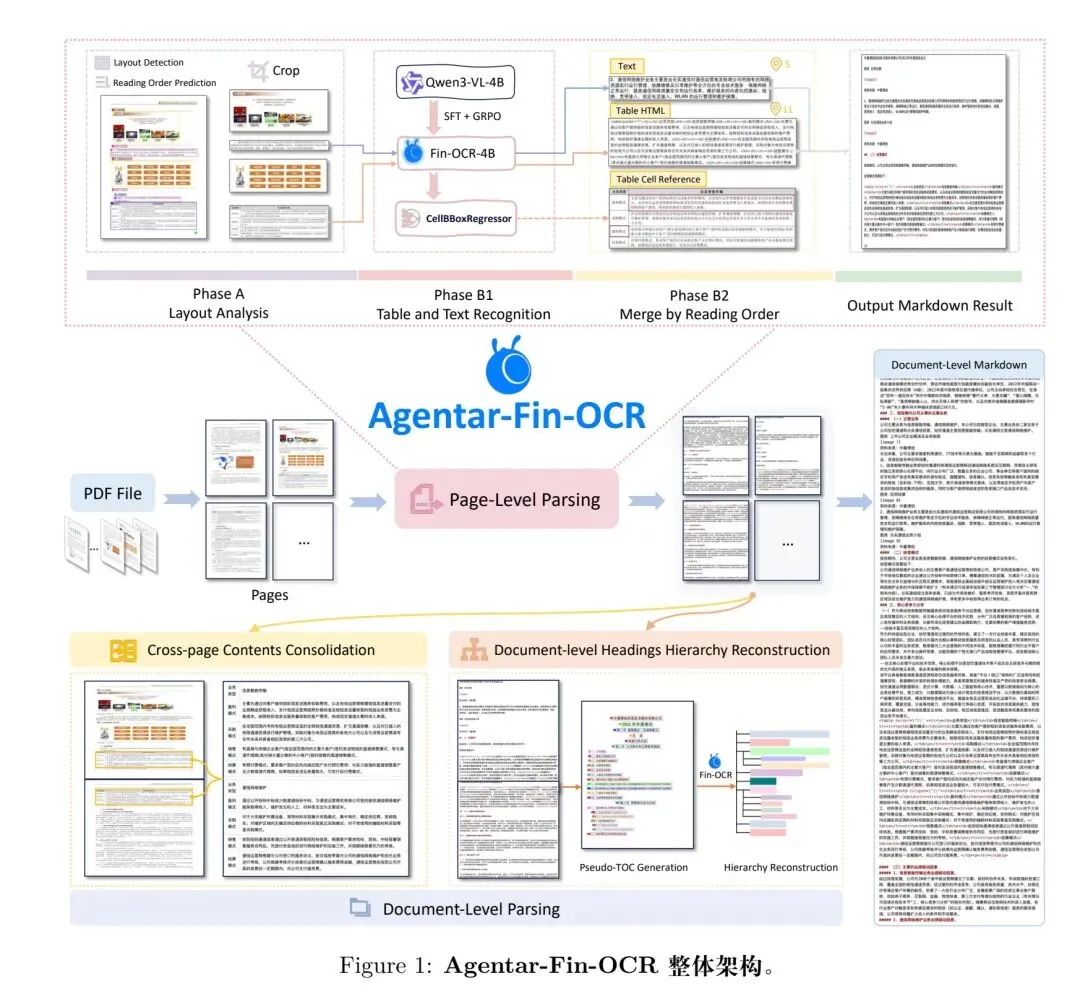
1、跨页内容整合
一个是跨页文本合并,识别页边界的文本片段,剔除页眉页脚等非内容元素,拼接保持句法与上下文完整性;
一个是跨页表格拼接,这个也是一个常考任务点,不少内网多模态模型也补齐了这个任务。

思路为∶ 先过滤,①结构对齐:前后表格列维度严格一致;②上下文邻近:表格片段间无非内容外的语义元素,然后,③自适应标题拼接:满足前两条后,分2种方式拼接:同质拼接(后表格无标题/标题与前一致,剔除冗余标题仅追加<tbody>)、异质拼接(后表格标题不同,全量合并保留子标题信息);

2、文档级标题层级重构(DHR)
这个层级结构,也是个刚需,这里的思路是借助 Fin-OCR 的多模态推理能力,恢复整个文档的标题层级结构。首先从原始文档中提取标题,形成一组类似于伪目录(pseudo-TOC)的图像。
这里考虑的特征有文本,视觉,位置等。其中∶
文本特征。标题 的文本内容在整篇文档中具有上下文意义。
视觉特征,在财务报告中,标题层级通常通过一致的排版来表示(例如,所有一级标题共享相同的字体大小和权重,而范围更大的标题通常采用更显著的排版格式)。
位置特征,布局分析得到的边界框坐标编码了标题的缩进模式,为深层嵌套的标题层级提供了额外线索。
问题来了,怎么组合特征?做法也蛮有趣,如下图所示∶
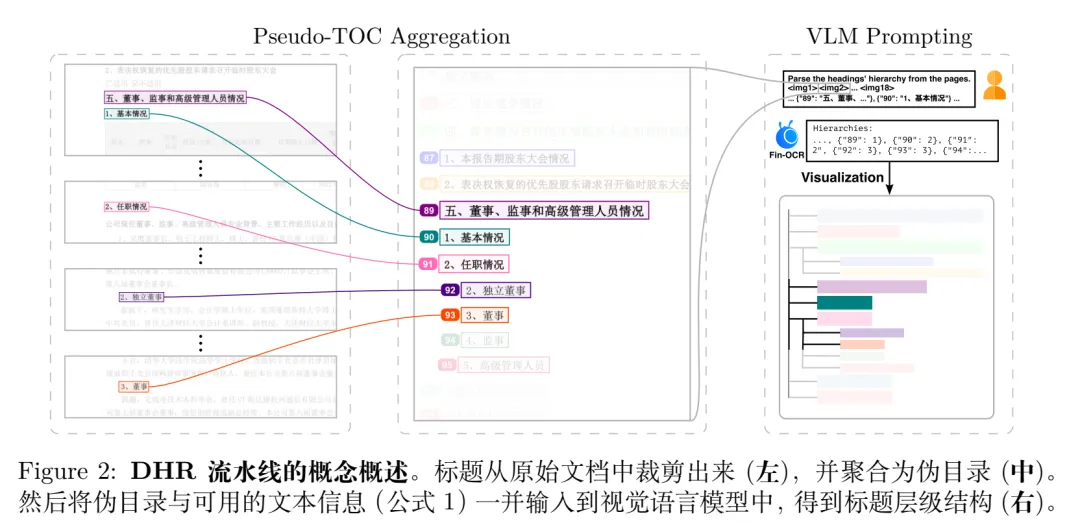
为了有效保留这些线索,直接使用前一版面分析阶段获得的每个标题的边界框坐标,就是图2的左边所示,裁剪文档页面,为每个标题 ℎ 生成一个图像裁剪 C。随后,将这些图像裁剪
粘贴到一个空白的页面大小图像上,保持其相对于原始文档的水平偏移。通过将所有标题垂直排列,从而可以得到一组页面大小的图像,形成一个 伪目录(图 2 中间)。
特别的,还用彩色边界框和单调递增的数字标签对粘贴的标题裁剪进行标注,以进一步提升视觉语言模型的定位能力。
然后将获得的文本结果与伪目录一同输入 Fin-OCR,以重建文档的标题层级结构。
具体就是文本-图像提示怎么写,具体如下,内容包括∶一个简短、以任务为导向的文本指令。例如,“将目录页解析为以下 JSONL 格式:…”;从版面分析结果中提取的每个标题的文本内容 T以及对应标题的数字标签;按顺序的伪 TOC 页面。
然后按照指定格式恢复每个标题的级别,由此格式可以解码并可视化整个文档的标题层级结构(图 2 右下角)。
3、表格解析的优化
表格解析方面,借助课程学习:先基于难度评分划分样本,从简单到复杂进行SFT;再采用GRPO强化优化,引入网格一致性信号与TEDS加权作为奖励,解决复杂表格的行列对齐问题。
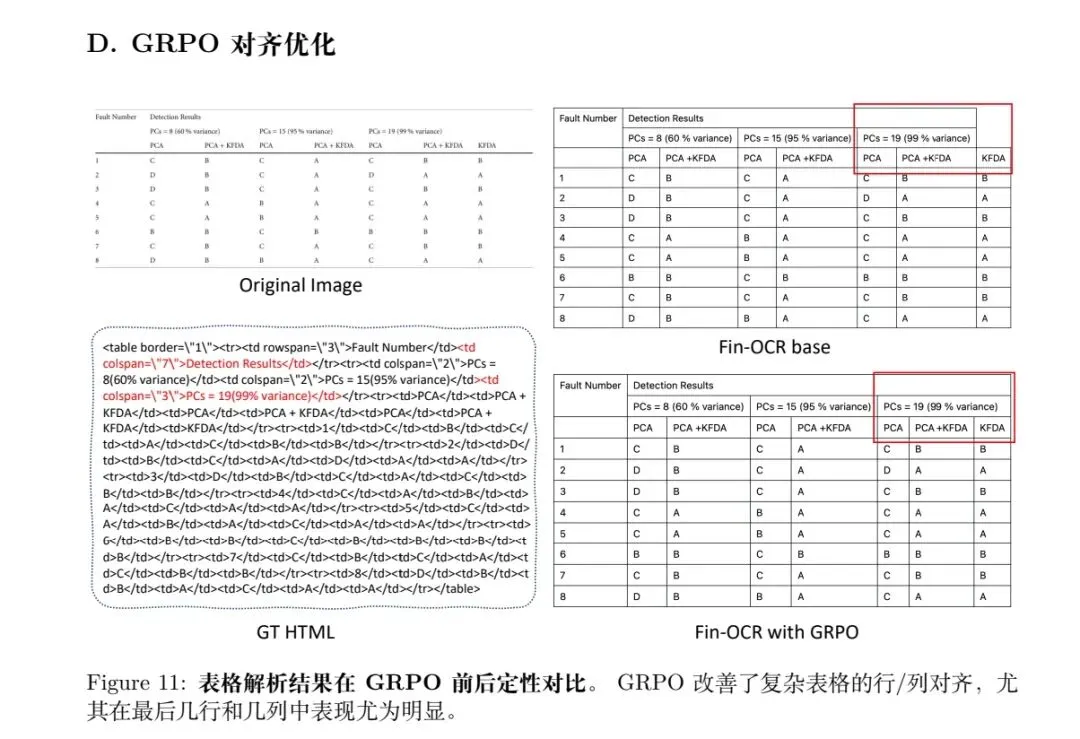
难点在于数据样本构造,数据是多模型打分,预过滤:融合PaddleOCR-VL、Mineru2.5、HunyuanOCR实现样本预过滤。
4、单元格级视觉溯源
单元格级溯源是很刚需的一个用法,之前用传统检测模型可以做,但多模态少见。
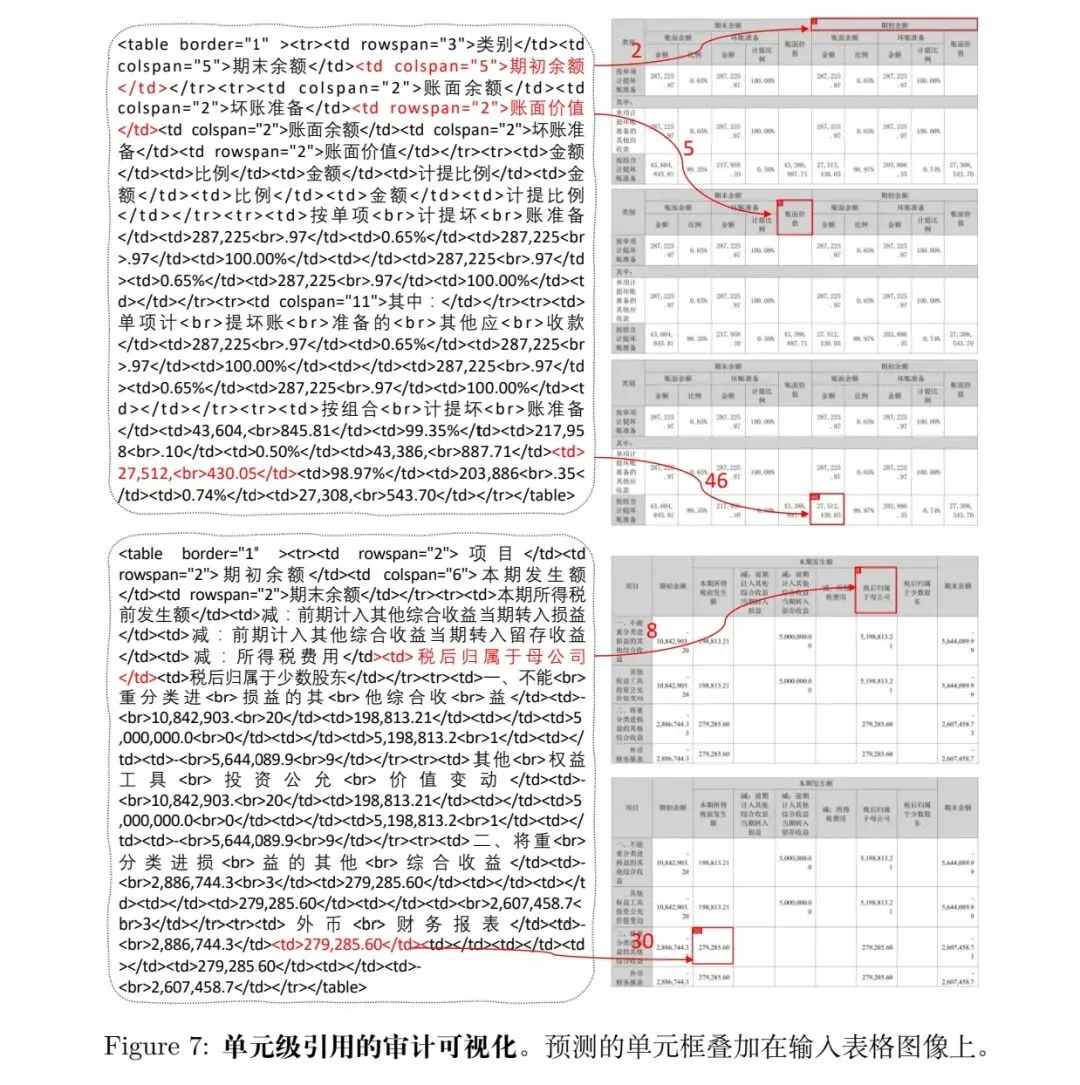
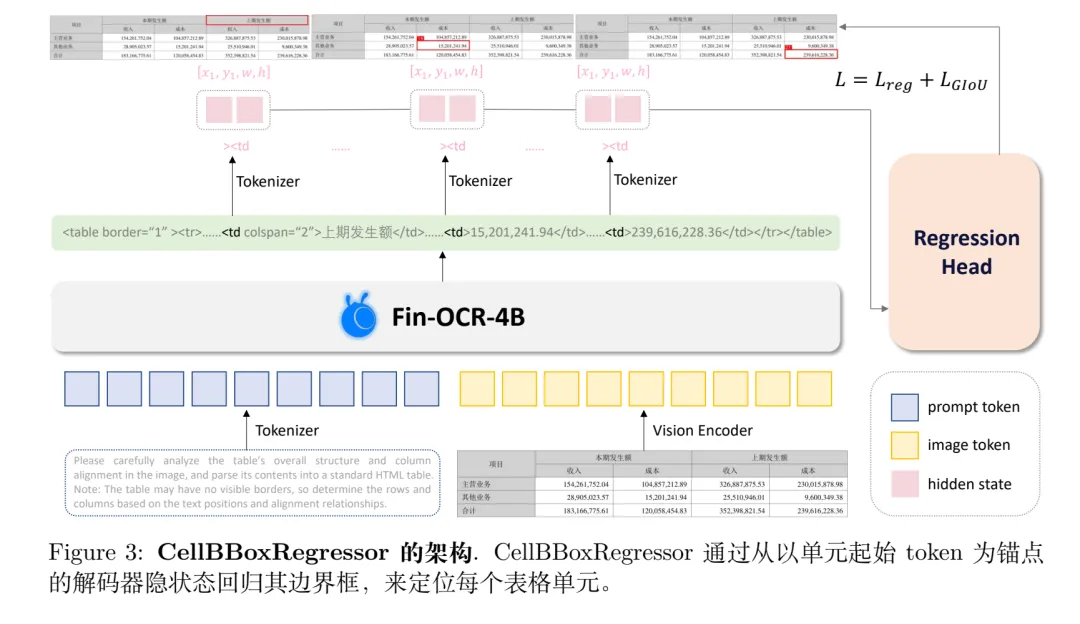
这里引入Cell BBox Regressor模块,金融审计的溯源需求,直接从生成的HTML中定位单元格边界框,所以,这个是个差异性。
5、金融领域专属评测集FinDocBench
最后,模型做了,顺便搞个数据集,6类金融文档涵盖年报、研报、审计报告、发债公告、招股书、保险文档6类,分为表格识别、布局与阅读顺序、标题层级重构3大任务。
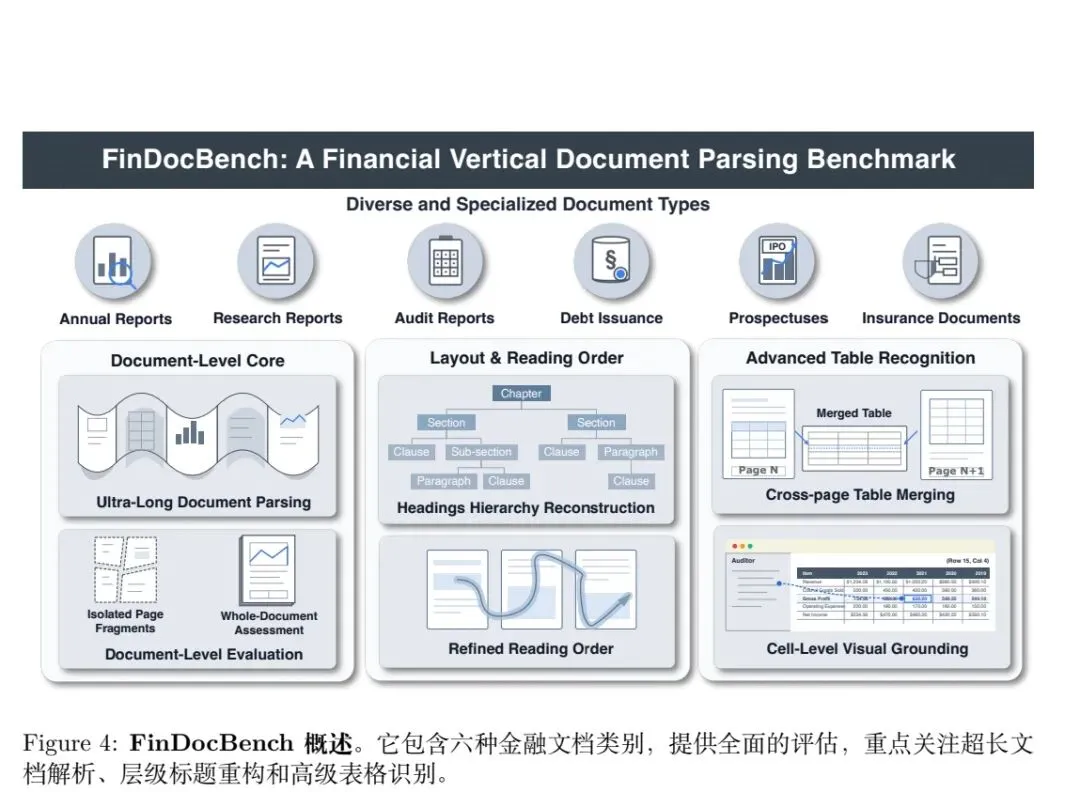
评估指标方面。专属评估指标包括TocEDS:基于编辑距离的目录相似度,衡量标题内容与层级的识别精度;跨页拼接TEDS:将跨页表格拼接后计算树编辑距离相似度,评估跨页表格解析的端到端精度;C-IoU(Table Cell Intersection over Union):计算单元格预测与真实边界框的交并比,衡量单元格级视觉溯源精度。
这些也都是要关注到的评估细节。
参考文献
1、https://arxiv.org/pdf/2603.10910
2、https://arxiv.org/pdf/2603.11044
老刘,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
对大模型&知识图谱&RAG&文档理解感兴趣,并对每日早报、老刘说NLP历史线上分享、心得交流等感兴趣的,欢迎加入社区,社区持续纳新。
加入社区方式:关注公众号,在后台菜单栏中点击会员社区加入。