Python+AI手撕系统,彻底扔掉Excel,开发专属数据录入系统
干试验这十年,每次查历史数据都逃不开这套流程:翻遍层层文件夹、筛选对应试验项目、查找报告、手动录入Excel。重复又繁琐,耗时长还容易出错,没有体现出咱们工程师的水平😂。
建议公司买商用系统,一问报价30万,周期还特别长;试过Excel共享协作,两个人同时打开就崩溃,数据被覆盖是常事;某天领导指点可以开发一款自己的系统,思来想去有AI助攻,零基础也能试试。
从去年11月到今年2月,利用业余时间,我靠着Python+AI,搭建了一套专属试验数据管理系统。如今找数据、录数据、出报告,五分钟就能搞定,效率直接翻倍。
一、技术选型:为什么是这三样
Python
选Python不是因为它是最顶尖的编程语言,纯粹是因为我只会这个,但实战下来,完全够用,核心就靠三大库撑起所有需求:
pandas:专攻Excel导入导出,批量处理数据框,比起手动操作,速度快了不止一百倍,批量规整数据毫无压力;
plotly:绘制散点图、箱线图,支持交互式操作,鼠标悬停就能查看详细数据,还能框选放大,数据对比一目了然;
reportlab:精准生成PDF报告,页眉页码、表格位置、图片大小都能精细化控制,完美贴合试验报告规范。
Python最香的就是生态完善,试验数据处理需要的功能,都有现成的库可以调用,不用从零造轮子。
Streamlit
传统开发模式太复杂,前端要啃HTML/CSS/JS,后端要搭Python/Java框架,还要对接数据库,一个人根本顾不过来。
Streamlit彻底简化了流程,只需要写Python逻辑,界面就能自动生成。一行st.dataframe生成数据表格,一行st.plotly_chart出可视化图表,加个st.file_uploader就是文件上传组件,对只会Python的工程师来说,这就是实打实的效率神器。
MySQL
最开始我想用Excel当数据库,可多人同时保存就会数据冲突,好几次辛苦整理的数据直接被覆盖;后来换成SQLite,虽然轻量便携,但并发写入能力极差,三个人同时使用就卡顿闪退。
最终换成MySQL,临时采用小团队使用的MySQL8.0,配置好连接池后,现在支持20人同时在线操作毫无压力,彻底解决了团队协作的痛点。
|
方案
|
优点
|
缺点
|
适用场景
|
|
Excel
|
上手简单,全员都会用
|
多人协作崩溃、数据量大卡顿、易丢失
|
单人操作、临时数据整理
|
|
SQLite
|
轻量便携、单文件存储
|
并发写入能力差
|
单人使用、嵌入式场景
|
|
MySQL
|
性能稳定、并发协作能力强
|
需要部署配置
|
团队多人协作
|
二、系统功能:工程师能干什么
测试数据录入
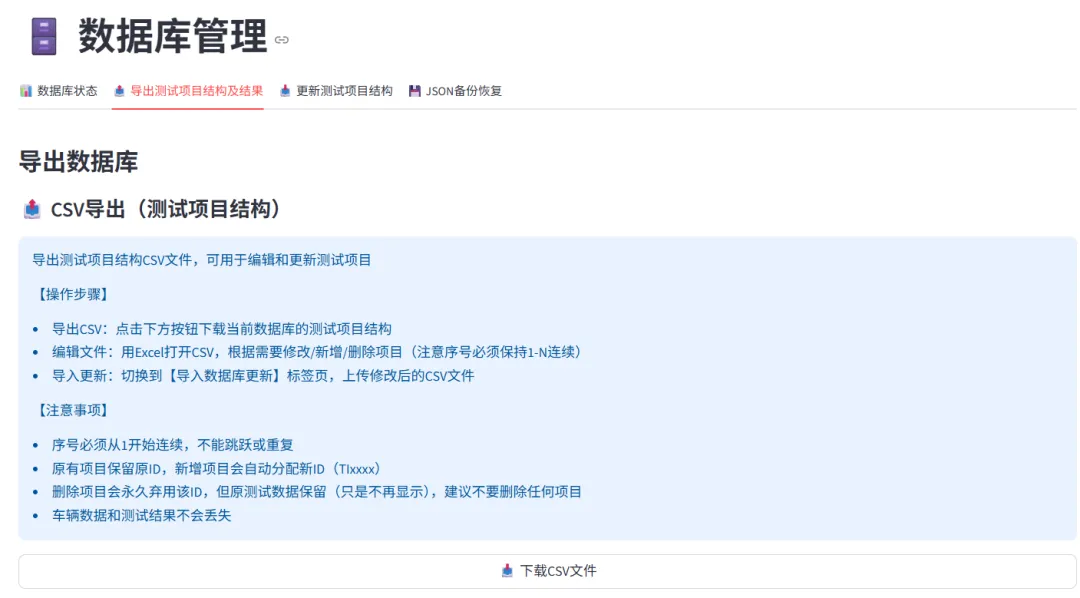
操作流程极简,选中目标车辆,点击下载模板,就能拿到标准化Excel模板,格式如下:
|
项目ID
|
序号
|
一级目录
|
二级目录
|
测试项目
|
单位
|
测试值
|
|
TI0001
|
1
|
基本参数测量
|
主要尺寸测量
|
长
|
mm
|
5890
|
前六列内容固定,工程师只需在最后一列填写测试值,保存后上传,程序会自动覆盖原有数据。
之所以选择“覆盖”而非“追加”,是因为试验数据每辆车仅测一次,无需保留历史版本,覆盖逻辑简单清晰,能最大程度避免数据混乱。
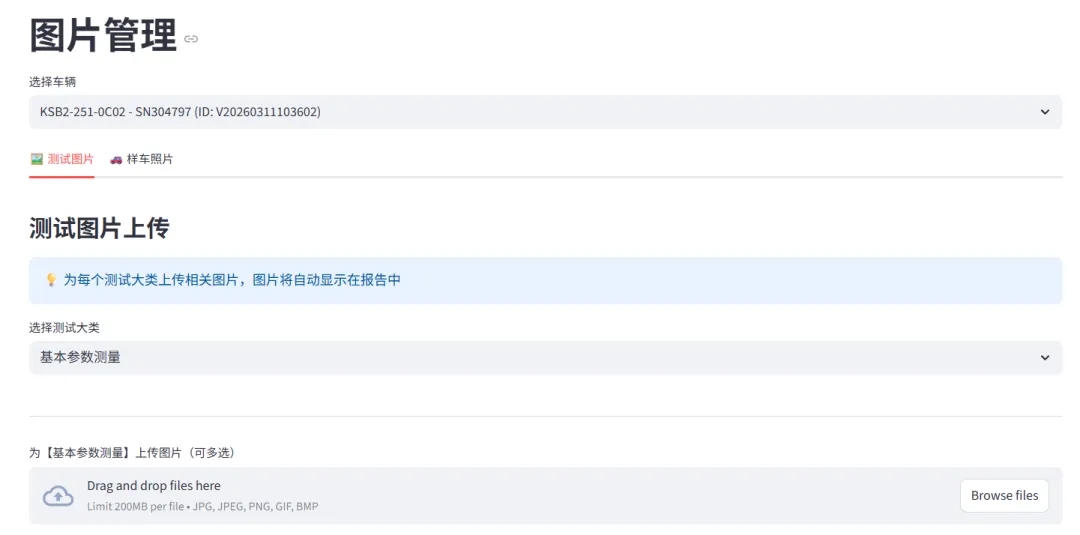
图片管理
支持按测试大类单独上传图片,比如“制动性能”分类,可上传制动盘实拍图、测试现场图等,图片会自动嵌入PDF报告,一行最多放置两张,固定高度5cm,宽高比自动适配,无需手动调整排版。
报告生成
只需点击一键生成按钮,30秒就能输出完整PDF报告,内容包含:
试验一览:写明试验目的、所用设备、测试项目、核心结论;
以往手动做一份报告至少要一小时,现在短短几十秒就能完成,彻底解放双手。
三、数据看板:让数据活起来
数据看板是系统的核心亮点,按照边界筛选,选中多款车型、单个测试项目(比如车辆长度),系统会自动生成两张可视化图表,数据分析效率拉满:
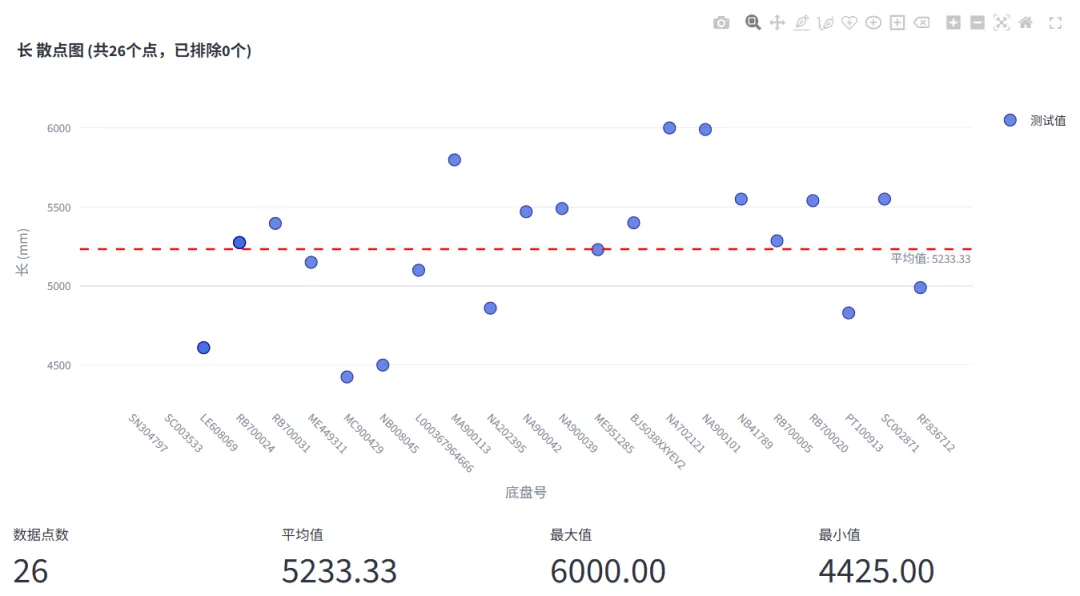
散点图
横坐标为车型或底盘号,纵坐标为测试数值,鼠标悬停可查看每辆车的精准数据,还标注了平均值红线,车辆数据偏高、偏低的情况,一眼就能看清。
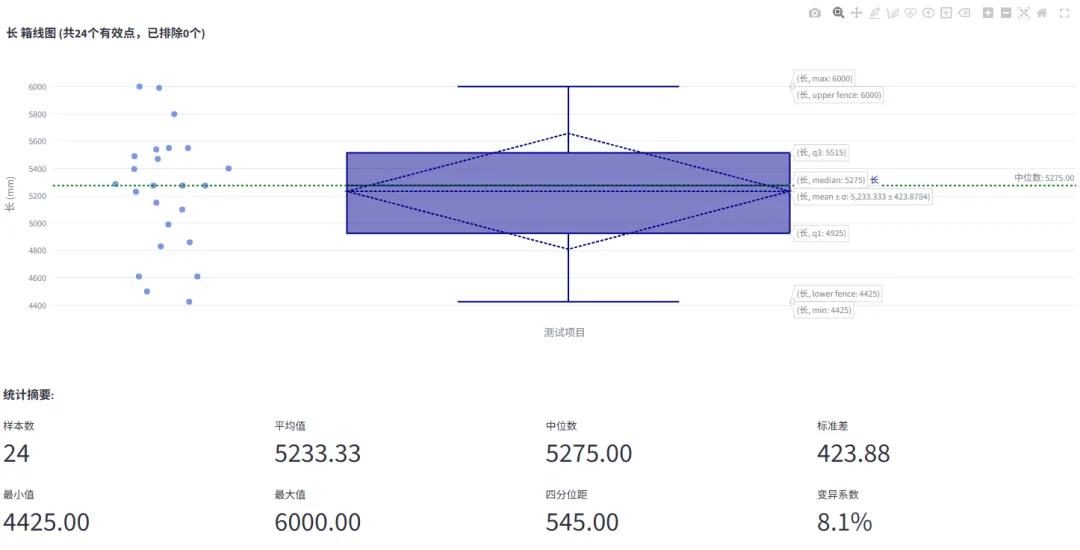
箱线图
直观展示数据分布情况,中位数、四分位距、异常值清晰呈现,哪辆车的数据存在异常、偏离正常区间,一目了然,省去手动排查的麻烦。
异常点剔除
这个功能是后期迭代新增的,试验过程中难免出现传感器接触不良、读数失误、录入错误等问题,在表格中勾选异常数据,点击删除,图表就能实时更新,清洗后的数据更精准,分析结果更可靠。
数据导出
清洗完成后的有效数据,可直接导出CSV格式,复制粘贴就能用到工作汇报、试验复盘材料里,省去二次整理的步骤。
以前做这类多车数据对比分析,要从多份报告里摘抄数据,再用Excel绘图,至少耗时半天,现在轻点鼠标,5分钟就能搞定。
四、最大的坑:测试项目动态调整
系统开发过程中,踩过无数坑,其中最致命、最耗时间的,就是测试项目的动态调整设计。
第一版设计思路极其简单,就建一张数据表,每行对应一个测试项目,字段只包含名称、单位、所属大类,想着快速落地就行。
A项目提出:前轮轮荷要分左右测量,需拆成“左前轮”“右前轮”两个项目;
B项目要求:制动距离需测三次,要支持录入三组数值;
C项目需求:新车型新增续航测试,需添加全新测试大类。
每一次需求变动,都要手动修改数据库,调整表结构、改写代码、更新导入导出模板、优化PDF生成逻辑,每次修改都要折腾大半天,还极易引发bug,返工成本极高。
这时候我才彻底醒悟:我要做的不是一个固定不变的系统,而是一个能跟着需求“长大”的灵活系统。
随即启动第二版重构,改成三级分类结构,所有关联靠ID绑定,摒弃死数据:
main_categories:一级目录,存储测试大类,支持用户增删;
sub_categories:二级目录,关联一级目录ID,支持用户增删;
test_items:测试项目,关联二级目录ID,存储名称、单位、序号,支持用户增删。
优化后,新增测试项目无需改动表结构,只需在test_items里插入一行数据即可,拆分项目、新增指标都变得简单。
可新的问题随之而来:用户随意修改导致序号混乱怎么办?删除项目后,历史数据该如何留存?
序号必须连续:从1到N依次排序,严禁跳号,导入CSV时系统自动校验,缺号、重复直接报错拦截;
项目ID永久保留:每个项目对应唯一ID(格式TI0001~TI9999),删除的项目ID不再复用,历史数据依旧留存,仅前端不显示,兼顾数据完整性与ID利用率;
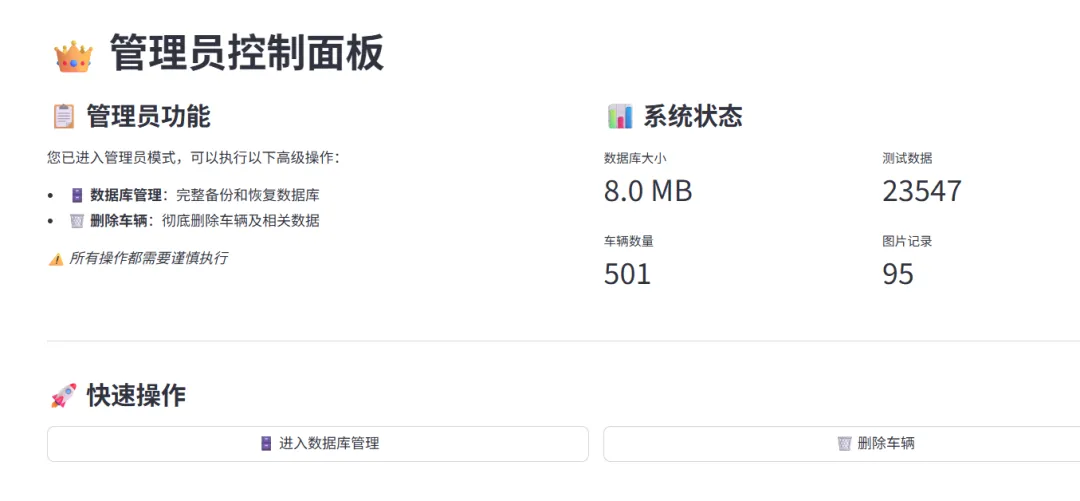
管理员专属权限:普通工程师仅能录入数据,无权增删测试项目,权限分离,杜绝误操作打乱数据结构。
这套逻辑前后写了三版,重构两次才跑通,现在回想,若是第一版就能理清思路,至少能少走两个月的弯路。
五、落地效果
上个月科室开展新项目,我用这套系统录入了第一辆试验车的数据,生成了首份正式报告。
把系统生成的报告和以往手动制作的报告放在一起对比:页眉位置、页码排序、签名区域、表格格式完全一致,规整度甚至优于手动版。
如今系统内已录入试验车的数据,零散数据不再散落于个人电脑,想要查询任何数据,轻点鼠标就能快速调取,工作模式彻底蜕变。
下篇预告
《数据是怎么“活”起来的?——导入导出、权限控制、动态调整的底层逻辑》
数据存进数据库只是第一步,怎么让工程师愿意用、用得好,才是关键。下篇详细讲:
模板设计:为什么Excel长那样?为什么导入必须是“覆盖”不是“追加”?
权限切割:工程师能干什么、管理员能干什么,这条线怎么划?
全是踩过的坑和最终的解决方案,干货满满,敬请期待。
互动话题:你在工作中被Excel、数据整理困扰过吗?评论区聊聊你的痛点,咱们一起找解法。
 夜雨聆风
夜雨聆风