 夜雨聆风
夜雨聆风





从0到1搭建可复用插件:SPI机制的落地实践与设计思路
❝
大家好,我是老丁,一个写了十年代码拥有“丁点技术“的“老”程序员。
作为技术架构师,在设计企业级应用时,我们最头疼的问题之一,就是「扩展性」—— 当业务需求迭代、第三方依赖升级,或者需要适配多场景时,核心代码被反复修改,耦合越来越重,维护成本呈指数级上升。
尤其是在存储场景中,几乎所有企业都会面临「多存储平台适配」的需求:开发环境用本地存储,测试环境用轻量对象存储,生产环境要对接阿里云 OSS、七牛云 Kodo、华为云 OBS 等主流平台,后续可能还要新增 MinIO、S3 等。
如果每接入一个存储平台,就去修改核心业务代码、重新打包部署,不仅效率低下,还容易引入 bug。这时候,「SPI + 插件化架构」就成了最优解 —— 它能实现功能的「热插拔」,让扩展无需改动核心,新增平台就像「插插件」一样简单。
今天,我们就以我自己的开源项目:Free FS 的存储插件模块为例,先厘清「插件思维」的核心内涵,再手把手拆解 SPI 机制的落地细节——要明确的是,SPI 只是插件思维的一种实现方式,而非全部。文中会讲解插件思维能解决什么问题、具体应用场景,以及如何从零搭建一套可复用、高扩展的插件体系,供各位参考。
一、 先搞懂:插件思维是什么?SPI 只是其实现方式之一
很多开发者会把「SPI」和「插件」画等号,其实这是一个常见的认知误区:插件思维是一种设计理念,而 SPI 是这种理念在 Java 中的一种具体实现方式。就像「面向对象」是一种编程思想,而 Java、C# 是实现这种思想的编程语言一样,二者是「理念」与「实现」的关系。
我们先明确两个核心概念,避免混淆:
1.1 什么是插件思维?
插件思维的核心是「核心稳定、扩展灵活」,本质是一种「解耦扩展」的设计思想——将系统拆分为「核心模块」和「扩展模块(插件)」,核心模块只定义统一的扩展标准(接口/规范),不依赖任何具体的扩展实现;扩展模块(插件)遵循核心模块的标准,独立实现具体功能,可按需加载、卸载,不影响核心模块的稳定性。
简单来说,插件思维就是给系统留好扩展接口,让新增功能像‘插U盘’一样简单,它的核心价值的是:
-
核心模块不被扩展逻辑污染,降低维护成本; -
扩展功能可独立开发、测试、部署,提升迭代效率; -
支持按需加载,减少系统冗余,提升性能; -
多场景、多需求可通过不同插件适配,无需修改核心代码。
插件思维的应用场景非常广泛,比如我们常用的 IDE(IDEA、VS Code)、浏览器(Chrome、Edge),都是插件思维的典型落地——核心程序只提供基础功能,通过插件扩展语法高亮、代码提示、广告拦截等个性化功能,用户可按需安装,开发者可独立开发插件,无需修改核心程序源码。
1.2 插件思维的多种实现方式
SPI 是 Java 内置的服务发现机制,是实现插件思维的一种简洁、高效的方式,但并非唯一方式。在不同语言、不同场景下,还有多种实现插件思维的方式,比如:
-
SPI(Java 专属):本文重点讲解的方式,通过 ServiceLoader 自动加载插件,无需手动配置,适合 Java 后端项目; -
配置文件驱动:核心模块读取配置文件(如 XML、YAML),根据配置反射创建插件实例,适合简单场景,灵活度高; -
注解驱动:通过自定义注解标记插件,核心模块扫描指定包下的注解,加载插件实例,适合 Spring 生态项目; -
动态加载 JAR:通过 ClassLoader 动态加载外部 JAR 包(插件),支持运行时加载、卸载,适合需要热更新的场景(如插件市场); -
其他语言实现:Python 的 entry_points、Go 的 plugin 包、前端的插件化(如 Vue 插件),本质都是插件思维的落地,只是实现方式不同。
回到本文的核心——Free FS 的存储插件模块,我们选择用 SPI 实现插件思维,原因很简单:SPI 是 Java 内置机制,无需引入额外依赖,且能完美适配「插件注册-加载-调用」的全流程,满足存储插件的扩展需求。但我们要明确:不是只有 SPI 才能实现插件化,而是 SPI 是 Java 项目中实现插件思维最便捷、最贴合原生生态的方式。
用一句话说清:插件思维是“道”(设计理念),SPI 是“术”(实现方法)。
我们可以用一张简单的图理解二者的关系:
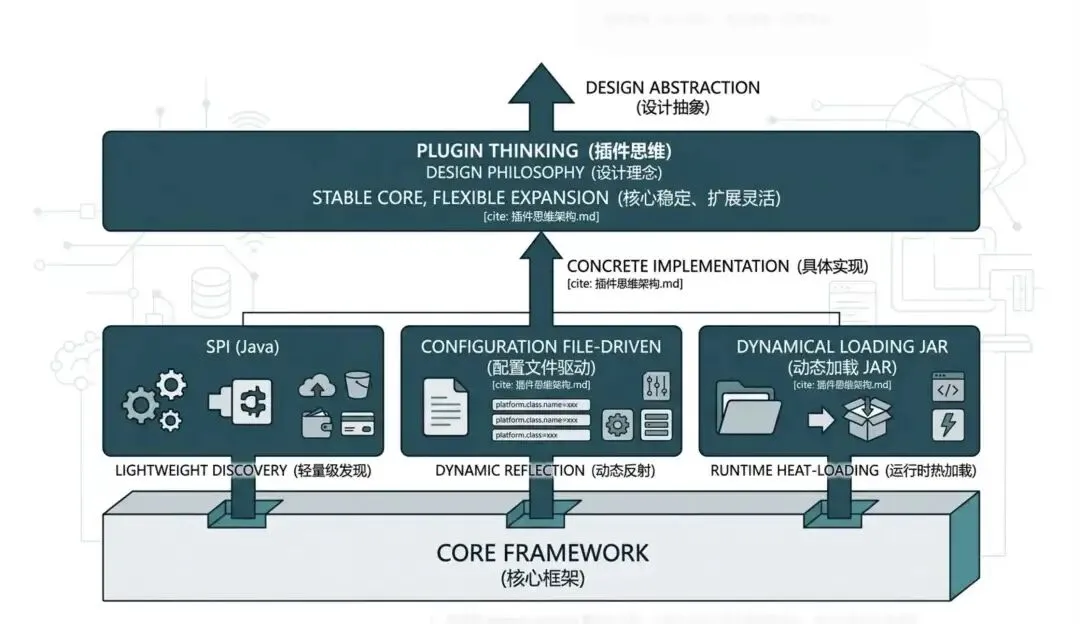
理解了这一点,我们再看 Free FS 的 SPI 实战,就能跳出「单纯讲解 SPI 用法」的局限,从插件思维的角度,理解每一步设计的意义——所有 SPI 相关的代码,本质都是为了落地「核心与扩展解耦」的插件理念。
二、SPI 为什么适合 Free FS 场景?
既然 SPI 是插件思维的一种实现方式,我们再具体拆解 SPI 的核心逻辑——它到底是什么,为什么 Free FS 选择用 SPI 实现存储插件?
SPI(Service Provider Interface)是 Java 6 内置的「服务发现机制」,核心思想就一句话:接口由框架定义,实现由第三方提供,框架自动加载所有实现,无需硬编码。
我们可以用一张简单的架构图,理解 SPI 的核心逻辑(结合 Free FS 存储场景):
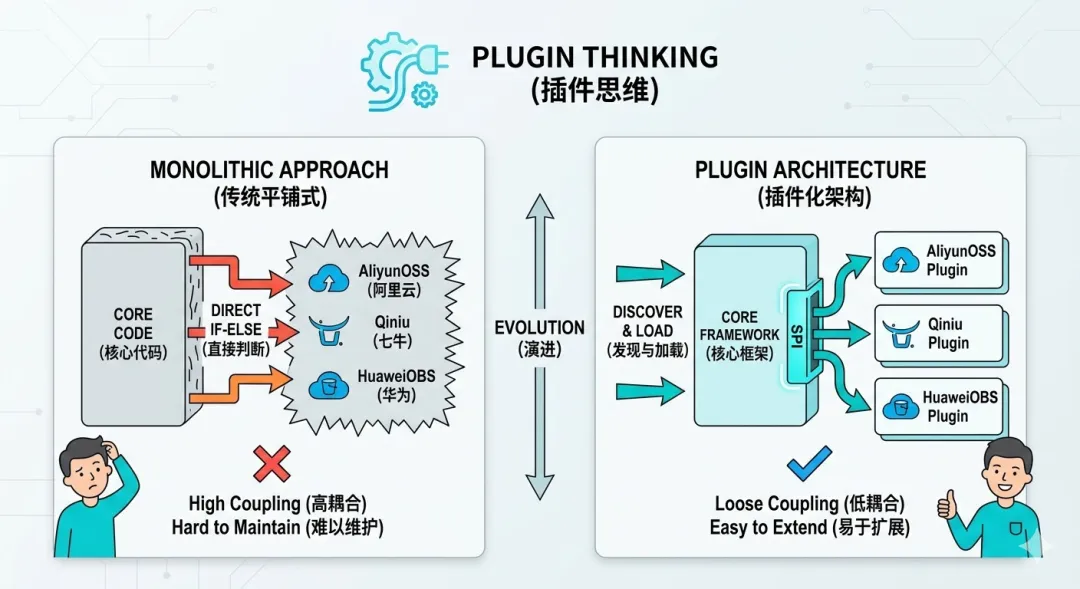
框架只负责定义「统一的能力标准」(比如上传、下载、删除文件),至于每个存储平台具体怎么实现这些能力,全由对应的插件负责。
而 SPI 的作用,就是让框架「自动找到」所有实现了该接口的插件 —— 每个插件只需在 META-INF/services/接口全限定名 文件中,声明自己的实现类,框架启动时通过 ServiceLoader.load(接口.class)就能一次性加载所有插件,无需我们手动 new 实例、写判断逻辑。
Free FS 选择 SPI 实现插件思维,核心原因有3点:
-
原生支持,无需额外依赖:SPI 是 Java 内置机制,不用引入第三方框架,降低项目依赖复杂度;
-
自动加载,简化开发:插件只需按规范注册,框架自动加载,无需手动编写加载逻辑;
-
契合存储场景:存储插件需遵循统一接口(上传、下载等),SPI 能完美适配「接口定义-实现分离」的需求,实现多存储平台的无缝切换。
这就解决了「硬编码耦合」的核心问题:核心框架不用关心有多少个存储平台,也不用关心每个平台的实现细节,新增平台时,只需要新增一个插件,完全不碰核心代码——这正是插件思维的核心诉求。
三、Free FS 存储插件模块:整体结构设计
理解了插件思维和 SPI 的关系后,我们来看 Free FS 中存储插件模块的具体结构 —— 整个模块采用「分层设计」,严格遵循「高内聚、低耦合」原则,确保插件的独立性和可扩展性,本质是插件思维的落地实践。
模块目录结构如下(简化版):
fs-storage-plugin/ ├── storage-plugin-core # 核心层:定义接口、抽象类、配置模型(SPI 接口所在) ├── storage-plugin-boot # 插件管理层:负责插件加载、实例创建、缓存管理 ├── storage-plugin-local # 本地存储插件(基础插件) ├── storage-plugin-aliyunoss # 阿里云 OSS 插件 ├── storage-plugin-obs # 华为云 OBS 插件 ├── storage-plugin-kodo # 七牛云 Kodo 插件 └── storage-plugin-rustfs # RustFS 插件每个模块的职责清晰,互不依赖,核心规则如下:
-
core 层:所有插件的「依赖中心」,只定义 SPI 接口、抽象基类和通用配置模型,不包含任何具体实现。各插件只需依赖 core 层,彼此之间完全独立,避免插件间的耦合——这是插件思维「核心稳定」的体现。
-
boot 层:插件的「管理中心」,负责加载所有插件、创建业务实例、缓存实例,是核心框架与插件之间的桥梁——承接核心层的标准,管理扩展层的插件,实现「核心与扩展解耦」。
-
插件层:每个插件对应一个存储平台,实现 core 层定义的 SPI 接口,完成该平台的具体操作逻辑(如 OSS 的上传下载、本地存储的文件读写)——这是插件思维「扩展灵活」的体现,每个插件可独立开发、按需加载。
最关键的是「按需引入」—— 我们可以在 boot 模块的 pom.xml 中,按需声明需要的插件依赖,不需要的插件直接注释或删除即可,实现真正的「按需加载」,减少项目打包体积。
示例(storage-plugin-boot/pom.xml):
<!-- storage-plugin-boot/pom.xml --><dependencies> <dependency> <groupId>com.xddcodec.fs</groupId> <artifactId>storage-plugin-local</artifactId> </dependency> <dependency> <groupId>com.xddcodec.fs</groupId> <artifactId>storage-plugin-aliyunoss</artifactId> </dependency> <!-- 不需要的插件,注释或删除即可,不影响核心功能 --> <!-- <dependency> <groupId>com.xddcodec.fs</groupId> <artifactId>storage-plugin-obs</artifactId> </dependency> --></dependencies>四、核心设计:SPI 接口 + 抽象基类
插件架构的核心,是「统一接口 + 标准化实现」—— 只有接口定义清晰、基类封装到位,才能保证所有插件的一致性,让框架能无缝加载和调用。下面我们拆解 Free FS 中的核心设计,这也是 SPI 实现插件思维的关键步骤。
4.1 SPI 接口定义:统一能力标准
SPI 接口的作用,是定义所有存储插件必须实现的「能力」—— 比如上传文件、下载文件、删除文件等。在 Free FS 中,我们定义了 IStorageOperationService 接口,同时加入了一个关键的「工厂方法」,解决 SPI 加载的痛点。
为什么需要工厂方法?因为 SPI 加载得到的是「原型实例」(无参构造创建),这个实例不能直接执行业务逻辑(没有配置信息),必须通过工厂方法,根据具体配置创建「业务实例」。
接口代码如下:
// storage-plugin-core/.../IStorageOperationService.javapublic interface IStorageOperationService extends Closeable { /** * 工厂方法:根据配置创建业务实例 * SPI 加载的是原型实例(无参构造),通过此方法创建真正可用于业务的实例 */ IStorageOperationService createConfiguredInstance(StorageConfig config); // 核心业务方法:所有存储插件必须实现 void uploadFile(InputStream inputStream, String objectKey); InputStream downloadFile(String objectKey); void deleteFile(String objectKey); String getFileUrl(String objectKey, Integer expireSeconds); boolean isFileExist(String objectKey); // 扩展方法:分片上传、Range 下载等(按需扩展) void uploadFileByChunk(InputStream inputStream, String objectKey, long chunkSize); InputStream downloadFileByRange(String objectKey, long start, long end);}4.2 抽象基类:封装通用逻辑,规范插件实现
为了减少插件的重复代码,我们定义了抽象基类 AbstractStorageOperationService,封装了所有插件的通用逻辑,同时强制规范插件的实现方式 —— 每个插件必须提供两种构造方式,避免误用。
抽象基类的核心作用:
-
封装「原型实例」和「业务实例」的双构造逻辑; -
提供配置校验、初始化的统一入口; -
防止在原型实例上执行业务方法(避免报错); -
实现工厂方法的通用逻辑,减少插件重复编码。
代码如下:
// storage-plugin-core/.../AbstractStorageOperationService.javapublic abstract class AbstractStorageOperationService implements IStorageOperationService { // 业务实例的配置信息(原型实例为 null) protected final StorageConfig config; /** 配置化构造函数(用于创建业务实例) */ protected AbstractStorageOperationService(StorageConfig config) { this.config = Objects.requireNonNull(config, "StorageConfig cannot be null"); validateConfig(config); // 配置校验(子类实现) initialize(config); // 初始化(子类实现,如创建 OSS 客户端) } /** 原型构造函数(供 SPI 加载用,无参) */ protected AbstractStorageOperationService() { this.config = null; } /** 子类必须实现:配置校验(避免非法配置) */ protected abstract void validateConfig(StorageConfig config); /** 子类必须实现:初始化(如创建第三方客户端、初始化连接) */ protected abstract void initialize(StorageConfig config); /** 工厂方法:通用实现,子类无需重写 */ @Override public IStorageOperationService createConfiguredInstance(StorageConfig config) { try { // 通过反射,调用子类的有参构造,创建业务实例 Constructor<? extends IStorageOperationService> constructor = this.getClass().getConstructor(StorageConfig.class);return constructor.newInstance(config); } catch (Exception e) { throw new StorageOperationException("Failed to create instance for platform: " + getIdentifierFromAnnotation(), e); } } /** 关键校验:防止在原型实例上执行业务方法 */ protected void ensureNotPrototype() {if (config == null) { throw new StorageOperationException("Cannot invoke business methods on prototype instance"); } }}这样一来,所有插件只需继承这个抽象基类,实现 validateConfig(配置校验)和 initialize(初始化)两个抽象方法,就能满足 SPI 加载和业务调用的要求,极大减少了重复代码——这也是插件思维「标准化实现」的体现。
五. 插件注册:SPI 配置 + 元数据注解
一个插件要被框架加载,需要满足两个条件:一是在 SPI 配置文件中注册,二是标注元数据注解 —— 前者让框架能找到插件,后者让框架能识别插件的信息(如平台名称、配置规则)。这是 SPI 实现插件加载的具体操作,也是插件思维「扩展灵活」的落地细节。
5.1 SPI 配置文件:插件的「身份证」
每个插件都需要在src/main/resources/META-INF/services/ 目录下,创建一个「以 SPI 接口全限定名为文件名」的文件,文件内容是插件实现类的全限定名。 以阿里云 OSS 插件为例:
-
创建文件:storage-plugin-aliyunoss/src/main/resources/META-INF/services/com.xddcodec.fs.storage.plugin.core.IStorageOperationService
-
文件内容(插件实现类全限定名):com.xddcodec.fs.storage.plugin.aliyunoss.AliyunOssStorageServiceImpl
本地存储插件同理,只需修改文件中的实现类全限定名即可。
这里的核心优势是:新增插件时,只需添加这个配置文件,无需修改框架的任何代码 —— 框架启动时,会自动通过 ServiceLoader 加载所有配置文件中的插件,完全符合插件思维「不改动核心、按需扩展」的要求。
5.2 @StoragePlugin 注解:元数据驱动
仅仅加载插件还不够,框架还需要知道插件的「元信息」—— 比如这个插件对应哪个存储平台、显示名称是什么、配置规则是什么,这些信息用于前端展示(如配置表单)和配置校验。
因此,我们定义了 @StoragePlugin 注解,要求所有插件类必须标注该注解,声明元数据。
注解定义如下:
// storage-plugin-core/.../annotation/StoragePlugin.java@Target(ElementType.TYPE)@Retention(RetentionPolicy.RUNTIME)@Documentedpublic @interface StoragePlugin { String identifier(); // 平台唯一标识(如 AliyunOSS、Local),不可重复 String name(); // 平台显示名称(如 阿里云OSS、本地存储) String description() default ""; // 平台描述(用于前端说明) String iconSvg() default ""; // 前端图标(SVG 格式,适配界面) String link() default ""; // 平台官方文档链接 boolean isDefault() default false; // 是否为默认插件 String configSchema() default ""; // 配置校验规则(JSON 格式) String schemaResource() default ""; // 配置 Schema 文件路径(如 classpath:schema/aliyun-oss-schema.json)}这个注解的核心价值,是实现「元数据驱动」—— 框架通过注解获取插件信息,无需硬编码配置,同时支持前端根据 Schema 自动生成配置表单,实现「配置可视化」。这也是插件思维「标准化、可扩展」的补充,让插件不仅能被加载,还能被便捷地管理和使用。
六、插件加载与实例管理:从加载到调用的完整流程
插件注册完成后,框架如何加载插件、创建实例、供业务层调用?这部分由 boot 层的三个核心类负责:StoragePluginRegistry(插件注册器)、StorageInstanceFactory(实例工厂)、StorageInstanceCache(实例缓存)。这一流程是 SPI 实现插件思维的完整链路,将「核心标准」与「扩展实现」完美衔接。
6.1 插件加载:StoragePluginRegistry
应用启动时,StoragePluginRegistry 会通过 ServiceLoader 加载所有实现了 IStorageOperationService 的插件,同时校验插件是否标注了 @StoragePlugin 注解,最后缓存插件的「原型实例」和「元数据」。
核心代码如下:
// storage-plugin-boot/.../StoragePluginRegistry.java@Slf4j@Componentpublic class StoragePluginRegistry { // 缓存插件原型实例(key:平台标识,value:原型实例) private final Map<String, IStorageOperationService> prototypes = new ConcurrentHashMap<>(); // 缓存插件元数据(key:平台标识,value:元数据) private final Map<String, StoragePluginMetadata> metadataMap = new ConcurrentHashMap<>(); @PostConstruct public void loadPlugins() { log.info("开始加载存储插件..."); // 加载所有实现了 IStorageOperationService 的插件 ServiceLoader<IStorageOperationService> loader = ServiceLoader.load(IStorageOperationService.class);for (IStorageOperationService prototype : loader) { Class<?> pluginClass = prototype.getClass(); // 校验插件是否标注了 @StoragePlugin 注解 StoragePlugin annotation = pluginClass.getAnnotation(StoragePlugin.class);if (annotation == null) { log.warn("跳过未标注 @StoragePlugin 注解的插件: {}", pluginClass.getName());continue; } String identifier = annotation.identifier(); // 提取插件元数据 StoragePluginMetadata metadata = StoragePluginMetadata.fromPluginClass(pluginClass); // 缓存原型实例和元数据 prototypes.put(identifier, prototype); metadataMap.put(identifier, metadata); log.info("注册存储插件: {} ({})", annotation.name(), identifier); } log.info("存储插件加载完成,可用平台: {}", prototypes.keySet()); } // 根据平台标识获取原型实例 public IStorageOperationService getPrototype(String platformIdentifier) { IStorageOperationService prototype = prototypes.get(platformIdentifier);if (prototype == null) { throw new StorageOperationException( String.format("不支持的存储平台: %s,可用平台: %s", platformIdentifier, prototypes.keySet())); }return prototype; }}这里有个关键细节:我们缓存的是「原型实例」,而不是业务实例 —— 因为业务实例需要根据具体的配置创建(不同的配置对应不同的实例,比如不同的 OSS 存储桶),原型实例只是用于创建业务实例的「模板」。这一设计既保证了核心层的稳定,又兼顾了插件扩展的灵活性,是插件思维的具体体现。
6.2 实例创建:StorageInstanceFactory
业务层需要调用插件时,不能直接使用原型实例,必须通过 StorageInstanceFactory,根据配置创建「业务实例」—— 本质上就是调用原型实例的 createConfiguredInstance 工厂方法。
核心代码如下:
// storage-plugin-boot/.../StorageInstanceFactory.java@Slf4j@Component@RequiredArgsConstructorpublic class StorageInstanceFactory { private final StoragePluginRegistry pluginRegistry; public IStorageOperationService createInstance(StorageConfig config) { config.validate(); // 校验配置合法性 // 根据配置中的平台标识,获取插件原型实例 IStorageOperationService prototype = pluginRegistry.getPrototype( config.getPlatformIdentifier()); // 调用工厂方法,创建业务实例return prototype.createConfiguredInstance(config); }}6.3 实例缓存:StorageInstanceCache
如果每次业务调用都创建一个新的业务实例,会造成资源浪费(比如频繁创建 OSS 客户端),因此我们需要对业务实例进行缓存 —— 同一个配置对应同一个实例,避免重复创建。
Free FS 中使用 Striped 锁保证并发安全,核心逻辑如下:
// storage-plugin-boot/.../StorageInstanceCache.java(核心逻辑)public class StorageInstanceCache { // 缓存业务实例(key:缓存键,由配置信息生成;value:业务实例) private final Map<String, IStorageOperationService> cache = new ConcurrentHashMap<>(); // 并发锁:每个缓存键对应一个锁,避免并发创建实例 private final Striped<Lock> locks = Striped.lock(16); public IStorageOperationService getOrCreate(String cacheKey, Supplier<IStorageOperationService> creator) { // 先从缓存中获取实例 IStorageOperationService instance = cache.get(cacheKey);if (instance != null) return instance; // 缓存未命中,获取对应锁,双重检查 Lock lock = locks.get(cacheKey); lock.lock(); try { instance = cache.get(cacheKey);if (instance != null) return instance; // 调用 creator 创建实例(由 StorageInstanceFactory 提供) instance = creator.get(); // 放入缓存 put(cacheKey, instance);return instance; } finally { lock.unlock(); } }}6.4 统一入口:StoragePluginManager
为了简化业务层的调用,我们封装了 StoragePluginManager 作为统一入口 —— 业务层只需调用这个类的方法,就能获取到对应的业务实例,无需关心插件加载、实例创建、缓存的细节。这一设计让业务层与插件层完全解耦,符合插件思维「核心与扩展分离」的原则。
核心逻辑如下:
// storage-plugin-boot/.../StoragePluginManager.java@Component@RequiredArgsConstructorpublic class StoragePluginManager { private final StorageInstanceFactory instanceFactory; private final StorageInstanceCache instanceCache; private final LocalStorageManager localStorageManager; /** * 统一入口:获取或创建业务实例 * @param configId 配置ID * @param configLoader 配置加载器(从数据库/配置中心加载配置) */ public IStorageOperationService getOrCreateInstance(String configId, Supplier<StorageConfig> configLoader) { // 本地存储特殊处理:单例模式,无需缓存(本地存储无多配置场景)if (StorageUtils.isLocalConfig(configId)) {return localStorageManager.getLocalInstance(); } // 其他存储平台:从缓存获取,未命中则创建 StorageConfig config = configLoader.get(); String cacheKey = config.getCacheKey(); // 由配置信息生成唯一缓存键return instanceCache.getOrCreate(cacheKey, () -> instanceFactory.createInstance(config)); }}至此,从插件加载到业务调用的完整流程就打通了 —— 业务层只需传入配置ID和配置加载器,就能轻松调用任何存储平台的功能,实现「一键切换存储平台」。这正是插件思维的核心目标:让扩展变得简单,让核心保持稳定。
七、实战示例:阿里云 OSS 插件完整实现
前面讲了很多理论和框架设计,下面我们以阿里云 OSS 插件为例,看一个完整的插件实现 —— 只需4步,就能完成一个存储插件的开发。这一过程是 SPI 实现插件思维的具体实践,每一步都遵循「核心标准、扩展独立」的原则。
7.1 第一步:定义插件实现类,继承抽象基类
插件类需要标注 @StoragePlugin 注解,提供无参(原型构造)和有参(配置化构造)两种构造方法,实现抽象基类的两个抽象方法。
// storage-plugin-aliyunoss/.../AliyunOssStorageServiceImpl.java@Slf4j@StoragePlugin( identifier = "AliyunOSS", // 平台唯一标识 name = "阿里云OSS", // 显示名称 description = "阿里云对象存储 OSS(Object Storage Service)是一款海量、安全、低成本、高可靠的云存储服务", iconSvg = "icon-aliyun1", // 前端图标 link = "https://www.aliyun.com/product/oss", // 官方文档 schemaResource = "classpath:schema/aliyun-oss-schema.json" // 配置Schema路径)public class AliyunOssStorageServiceImpl extends AbstractStorageOperationService { // OSS 客户端(业务实例专属) private OSS ossClient; // OSS 存储桶名称 private String bucketName; /** 原型构造函数(SPI 加载用) */ public AliyunOssStorageServiceImpl() { super(); } /** 配置化构造函数(创建业务实例用) */ public AliyunOssStorageServiceImpl(StorageConfig config) { super(config); } /** 配置校验:校验 OSS 必要配置 */ @Override protected void validateConfig(StorageConfig config) { // 将通用配置转为 OSS 专属配置 AliyunOssConfig cfg = config.toObject(AliyunOssConfig.class); // 校验必要配置(endpoint、accessKey、secretKey、bucket 不能为空)if (cfg.getEndpoint() == null || cfg.getEndpoint().trim().isEmpty()) { throw new StorageConfigException("阿里云OSS endpoint 不能为空"); }if (cfg.getAccessKey() == null || cfg.getAccessKey().trim().isEmpty()) { throw new StorageConfigException("阿里云OSS accessKey 不能为空"); }if (cfg.getSecretKey() == null || cfg.getSecretKey().trim().isEmpty()) { throw new StorageConfigException("阿里云OSS secretKey 不能为空"); }if (cfg.getBucket() == null || cfg.getBucket().trim().isEmpty()) { throw new StorageConfigException("阿里云OSS bucket 不能为空"); } } /** 初始化:创建 OSS 客户端 */ @Override protected void initialize(StorageConfig config) { AliyunOssConfig cfg = config.toObject(AliyunOssConfig.class); // 创建 OSS 客户端(单例,随业务实例生命周期) this.ossClient = OSSClientBuilder.create() .credentialsProvider(new DefaultCredentialProvider(cfg.getAccessKey(), cfg.getSecretKey())) .endpoint(cfg.getEndpoint()) .build(); this.bucketName = cfg.getBucket(); } /** 上传文件:实现 SPI 接口方法 */ @Override public void uploadFile(InputStream inputStream, String objectKey) { ensureNotPrototype(); // 校验:避免在原型实例上调用 try { PutObjectRequest request = new PutObjectRequest(bucketName, objectKey, inputStream); ossClient.putObject(request); log.info("阿里云OSS上传文件成功,objectKey: {}", objectKey); } catch (OSSException | ClientException e) { log.error("阿里云OSS上传文件失败,objectKey: {}", objectKey, e); throw new StorageOperationException("阿里云OSS上传文件失败", e); } } /** 下载文件:实现 SPI 接口方法 */ @Override public InputStream downloadFile(String objectKey) { ensureNotPrototype(); try { OSSObject ossObject = ossClient.getObject(bucketName, objectKey);return ossObject.getObjectContent(); } catch (OSSException | ClientException e) { log.error("阿里云OSS下载文件失败,objectKey: {}", objectKey, e); throw new StorageOperationException("阿里云OSS下载文件失败", e); } } // 其他方法(deleteFile、getFileUrl 等)类似,此处省略... /** 关闭客户端:释放资源 */ @Override public void close() throws IOException {if (ossClient != null) { ossClient.shutdown(); log.info("阿里云OSS客户端已关闭"); } }}7.2 第二步:定义插件专属配置模型
不同存储平台的配置不同(比如 OSS 有 endpoint、accessKey,本地存储有存储路径),因此我们用 StorageConfig作为通用配置模型,通过 toObject 方法将通用配置转为插件专属配置。这一设计让核心层无需关心具体插件的配置细节,只需提供统一的配置模型,符合插件思维「解耦」的要求。
通用配置模型(core 层):
// storage-plugin-core/.../config/StorageConfig.java@Data@Builderpublic class StorageConfig { private String configId; // 配置唯一ID private String platformIdentifier;// 平台标识(如 AliyunOSS) private String userId; // 关联用户ID(多租户场景) private Map<String, Object> properties; // 插件专属配置(键值对) private Boolean enabled; // 配置是否启用 /** 将 properties 转为插件专属配置类 */ public <T> T toObject(Class<T> targetClass) { ObjectMapper mapper = JsonMapper.builder() .configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false) .build();return mapper.convertValue(properties, targetClass); } /** 生成缓存键(由配置ID + 平台标识组成,确保唯一) */ public String getCacheKey() {return configId + "_" + platformIdentifier; } /** 配置校验 */ public void validate() {if (platformIdentifier == null || platformIdentifier.trim().isEmpty()) { throw new StorageConfigException("平台标识不能为空"); }if (properties == null || properties.isEmpty()) { throw new StorageConfigException("插件配置不能为空"); } }}阿里云 OSS 专属配置模型(插件层):
// storage-plugin-aliyunoss/.../config/AliyunOssConfig.java@Datapublic class AliyunOssConfig { private String endpoint; // OSS 端点(如 oss-cn-beijing.aliyuncs.com) private String accessKey; // 访问密钥 private String secretKey; // 密钥 private String bucket; // 存储桶名称 private String region; // 区域(如 cn-beijing) private Boolean https; // 是否启用 HTTPS}7.3 第三步:创建配置 Schema 文件
Schema 文件用于定义配置项的规则(如标签、数据类型、是否必填),前端可以根据这个文件自动生成配置表单,无需手动编写表单代码。这一设计让插件的配置更标准化,也让核心层无需关心插件的具体配置项,符合插件思维的「扩展独立」原则。
文件路径:storage-plugin-aliyunoss/src/main/resources/schema/aliyun-oss-schema.json
[ {"label": "Access-Key", "dataType": "string", "identifier": "accessKey", "validation": {"required": true, "description": "阿里云OSS访问密钥"}}, {"label": "Secret-key", "dataType": "string", "identifier": "secretKey", "validation": {"required": true, "description": "阿里云OSS密钥"}}, {"label": "服务器端点", "dataType": "string", "identifier": "endpoint", "validation": {"required": true, "description": "如 oss-cn-beijing.aliyuncs.com"}}, {"label": "存储桶名", "dataType": "string", "identifier": "bucket", "validation": {"required": true, "description": "OSS存储桶名称"}}, {"label": "区域", "dataType": "string", "identifier": "region", "validation": {"required": true, "description": "如 cn-beijing"}}, {"label": "启用HTTPS", "dataType": "boolean", "identifier": "https", "validation": {"required": false}, "defaultValue": true}]7.4 第四步:添加 SPI 配置文件
创建 SPI 配置文件,声明插件实现类的全限定名,让框架能加载该插件。这是 SPI 实现插件加载的关键步骤,也是插件思维「按需扩展」的具体操作——新增插件只需添加此配置,无需修改核心代码。
文件路径:storage-plugin-aliyunoss/src/main/resources/META-INF/services/com.xddcodec.fs.storage.plugin.core.IStorageOperationService
文件内容:com.xddcodec.fs.storage.plugin.aliyunoss.AliyunOssStorageServiceImpl
至此,阿里云 OSS 插件就开发完成了 —— 只需在 boot 模块的 pom.xml 中引入该插件依赖,启动应用后,插件会自动被加载,业务层就能直接调用 OSS 的所有功能。这一过程完美体现了插件思维的价值:核心稳定,扩展灵活。
八、整体流程概览:一张图看懂插件架构的工作原理
为了让大家更清晰地理解整个流程,我们用两张图,总结「应用启动时的插件加载流程」和「业务请求时的插件调用流程」—— 这两个流程完整呈现了「插件思维」通过「SPI 实现」的全链路。
8.1 应用启动:插件加载流程
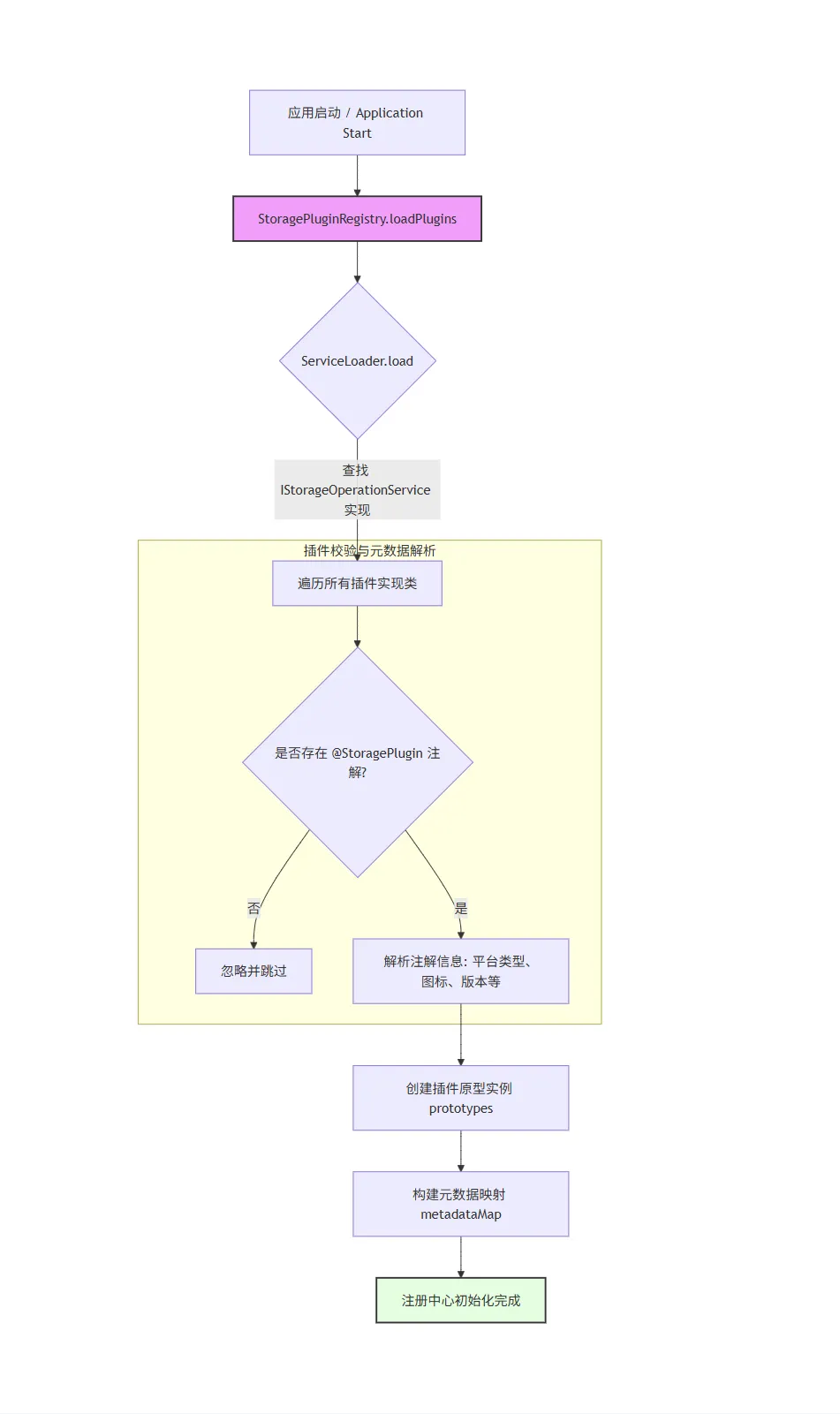
8.2 业务请求:插件调用流程(以上传文件为例)
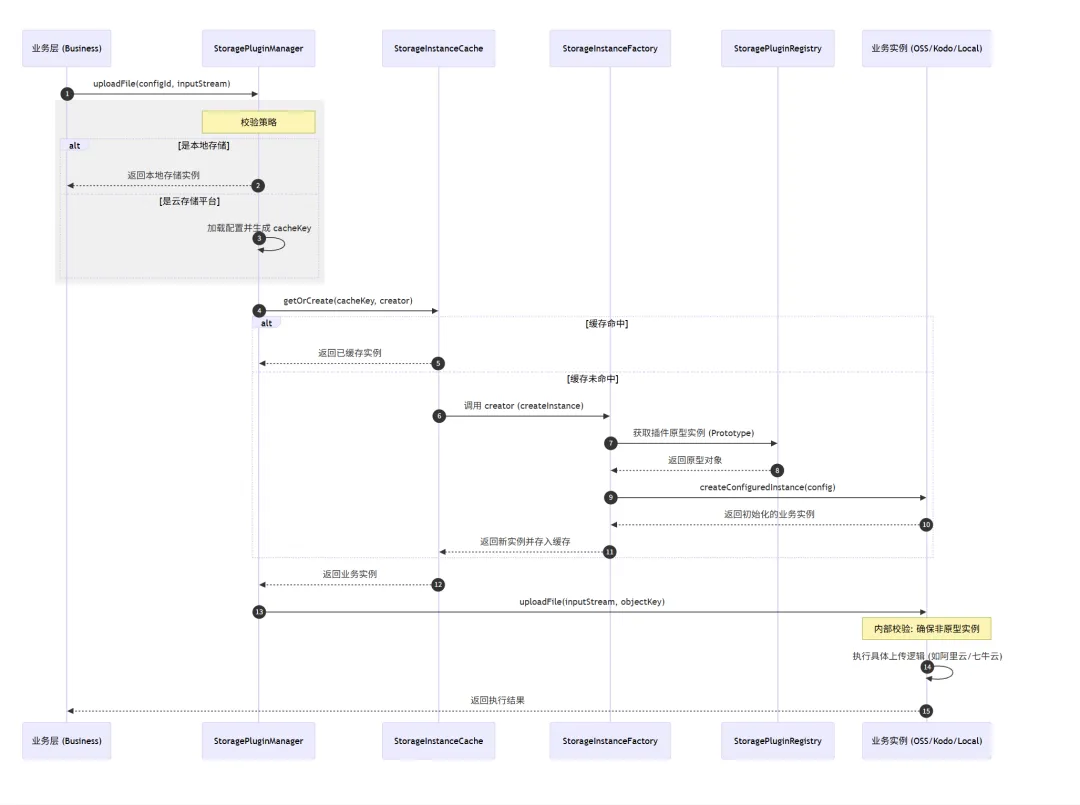
这两个流程清晰地展现了「插件思维」如何通过「SPI」落地:应用启动时,SPI 负责自动加载所有插件,核心层只做「管理和校验」;业务请求时,核心层通过统一入口调用插件,无需关心插件具体实现,完全实现了「核心与扩展解耦」。
九、插件架构的优势与避坑指南
基于 SPI 实现的插件架构,在 Free FS 项目中经过了生产环境的验证,既能解决多存储平台适配的核心痛点,也能带来显著的开发和维护优势,但同时也有一些需要避坑的细节——这些都是插件思维落地过程中,我们总结的实战经验。
9.1 核心优势(插件思维的价值体现)
-
解耦彻底:核心层与插件层完全分离,核心代码不包含任何扩展逻辑,后续新增、修改插件,无需改动核心代码,降低维护成本; -
扩展便捷:新增存储平台,只需按规范开发插件(实现接口、添加SPI配置),引入依赖即可,无需重新打包部署核心服务; -
可复用性高:插件可独立打包,供其他项目复用(如阿里云OSS插件,可直接复用至其他需要对接OSS的Java项目); -
易于维护:每个插件独立开发、测试,问题定位更精准,不会因单个插件故障影响整个核心系统; -
按需加载:通过pom.xml依赖管理,按需引入插件,减少项目打包体积,提升系统性能。
9.2 避坑指南(实战踩过的坑,建议收藏)
-
避免插件间耦合:严禁插件之间互相依赖,所有插件只能依赖 core 层,否则会导致插件加载异常,破坏「扩展独立」的原则;
-
原型实例与业务实例区分清楚:SPI 加载的是原型实例,不可直接执行业务方法,必须通过工厂方法创建业务实例,否则会因缺少配置报错;
-
配置校验不可少:每个插件必须实现 validateConfig 方法,校验必要配置(如OSS的accessKey、bucket),避免因配置缺失导致运行时异常;
-
资源释放要及时:插件实现 Closeable 接口,在业务实例销毁时关闭第三方客户端(如OSS客户端),避免资源泄露;
-
并发安全要保证:业务实例缓存需使用并发安全的容器(如ConcurrentHashMap),结合 Striped 锁避免并发创建实例,防止线程安全问题;
-
SPI 配置文件不可写错:配置文件的路径、接口全限定名、插件实现类全限定名,必须完全正确,否则 SPI 无法加载插件(常见报错:NoSuchElementException)。
十、总结:插件思维才是核心,SPI 只是落地手段
本文通过 Free FS 存储插件模块的实战案例,详细拆解了「SPI + 插件架构」的落地细节,但我们始终要明确:插件思维是设计核心,SPI 只是 Java 项目中实现插件思维的一种便捷方式。
插件思维的本质是「核心稳定、扩展灵活」,它能解决企业级应用中「扩展性差、耦合度高」的核心痛点,尤其是在多场景、多依赖适配的场景(如存储、消息队列、支付等),插件化架构能大幅提升开发效率、降低维护成本。
而 SPI 作为 Java 原生的服务发现机制,无需引入额外依赖,能完美适配「接口定义-实现分离」的需求,成为 Java 项目实现插件思维的首选方式——但它不是唯一方式,配置文件驱动、注解驱动、动态加载 JAR 等方式,可根据具体场景灵活选择。
最后,希望本文的实战经验,能帮助各位真正理解插件思维的价值,掌握 SPI 的落地技巧,在实际项目中搭建出高扩展、低耦合的插件体系,让系统在业务迭代中始终保持灵活与稳定。
结合你的项目场景,你在实现插件化架构时,是否用过 SPI 机制?遇到过哪些坑(比如插件加载失败、实例管理异常等)?或者你有其他实现插件思维的好方法,欢迎在评论区留言分享!