 夜雨聆风
夜雨聆风





文档解析实战,轻松接入Dify、Coze和LangChain,还有1000页额度免费领!
最近看到TextIn文档解析出了一本实战手册,TextIn也是我之前推荐过的工具。虽然大家作为开发者会更习惯性用开源方案,但如果你的业务涉及大量非标、复杂的文档处理,且对准确率和SLA有高要求,选择成熟的商业化方案确实可以帮忙团队剔除隐形成本。闭源厂商投入了大量资源做数据标注、质量筛选、RLHF对齐,这些积累不是开源社区短时间能追上的。
一、项目介绍
TextIn 文档解析是一款大模型友好的解析工具,能够精准还原pdf、word、excel、ppt、图片等十余种格式的非结构化文件,将其快速转换为Markdown或JSON格式返回,同时包含精确的页面元素和坐标信息。
支持识别文本、图像、表格、公式、手写体、表单字段、页眉页脚等各种元素,并支持印章、二维码、条形码等子类型,为LLM推理、训练输入高质量数据,帮助完成数据清洗和文档问答任务,适用于各类AI应用程序,如知识库、RAG、Agent或其他自定义工作流程。
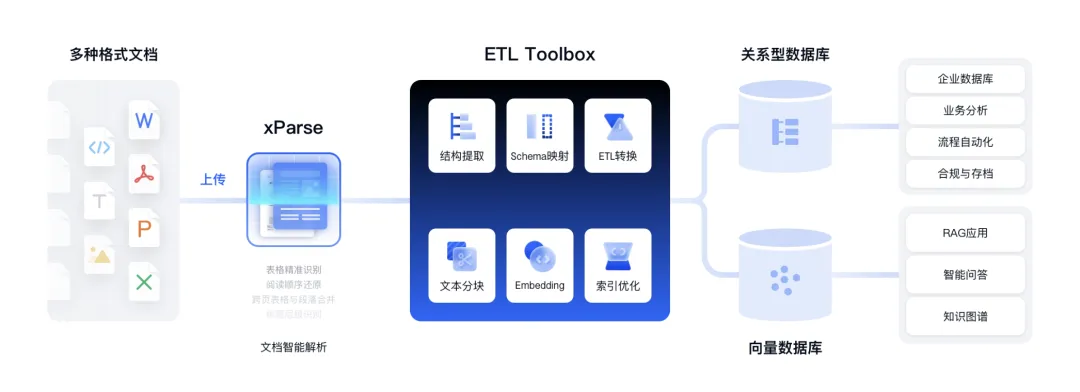
1. 从散乱资料到知识库:基于Coze与TextIn的实战
2. 文档问答Bot:基于Dify与TextIn的实战
3. 批量文档处理并上传至云端S3:基于Dify与TextIn的实战
4. 文章精读与在线检索:基于Coze与TextIn的实战
5. 合同智能审阅:基于Coze与TextIn的实战
6. TextIn MCP Server 接入与使用
7. 信息提取Agent:基于TextIn和LangChain实现结构化数据提取与整理
扫码👇

文档(PDF/Word/Excel/图片) ↓[xParse Pipeline - Parse] └─ 解析文档,提取结构化元素(elements) ↓聚合元素文本(elements[].text) ↓[LangChain Agent] ├─ Tool 1: extract_invoice_info(提取发票信息) ├─ Tool 2: extract_medical_bill_info(提取医疗票据信息) ├─ Tool 3: extract_contract_info(提取合同信息) ├─ Tool 4: extract_resume_info(提取简历信息) ├─ Tool 5: extract_product_specs(提取产品规格) ├─ Tool 6: extract_api_info(提取API信息) └─ Tool 7: format_data(数据格式化) ↓结构化数据(JSON/CSV)核心流程:
-
使用xParse解析文档,获得elements列表 -
聚合所有elements的text字段,形成完整文档文本 -
将完整文本直接输入大模型,通过精心设计的prompt提取结构化信息


4. 自研文档树引擎:基于语义提取段落embedding值,预测标题层级关系,通过构造文档树提高检索召回效果。
5. 支持多种扫描内容:能良好处理各类图片与扫描文档,包括手机照片、截屏等内容。
6. 支持多种语言:支持简体中文/繁体中文/英文/数字/西欧主流语言/东欧主流语言等共50+种语言。
7. 集成强大的图像处理能力:文件带水印、图片有弯曲,都能一键解决,排除图像质量干扰。

8. 开发者友好:提供清晰的API文档和灵活的集成方式,包括MCP Server、Coze、Dify插件,支持FastGPT、CherryStudio、Cursor等主流平台。
大家可以先获取TextIn的API Key。
TextIn官网注册:https://cc.co/16YScl
教程和弹药都备齐了。挑一篇最复杂的 PDF,试试看吧。