open-plm 的插件化设计:底座和能力是怎么被“组装”起来的
前几篇文章,我们把 open-plm 的内核(Kernel)机制彻底拆解了一遍。
从事件分发、Hook 扩展,再到上下文传递和并发模型,内核的骨架已经搭好了。但对一线开发来说,光有一套机制是不够的。最现实的问题是:这套机制写完之后,上层应用到底该怎么接入?
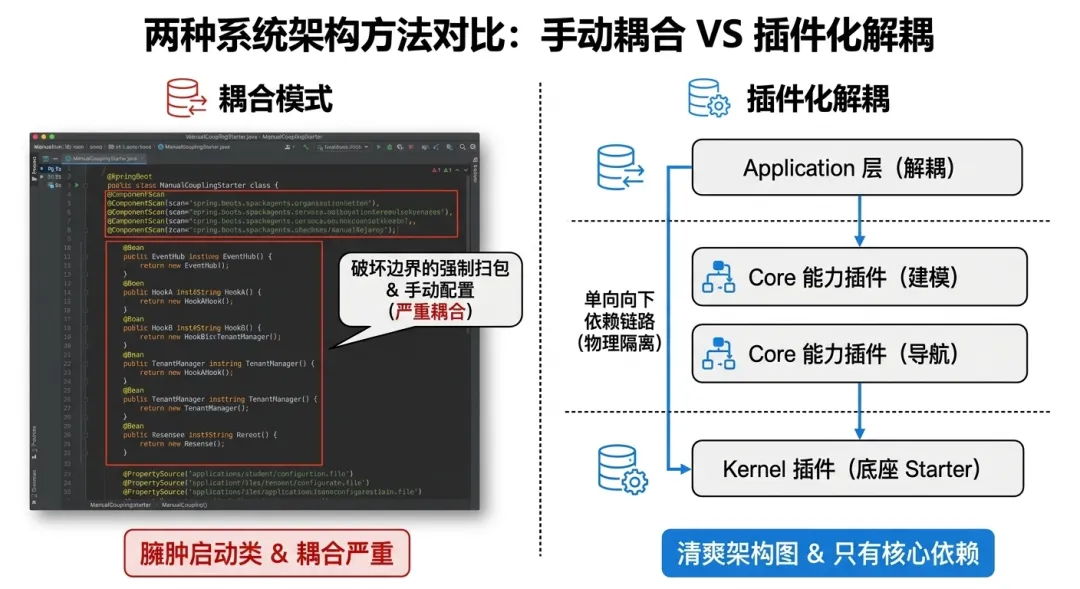
总不能每次起一个新的业务服务,都要手动去 new 一个 EventHub,手动把上百个 Hook 塞进注册表,再去各种配置类里写上一堆 @ComponentScan 扫描底层的包。
这就涉及到了 open-plm 架构设计里的另一项核心思路:插件化与模块装配。
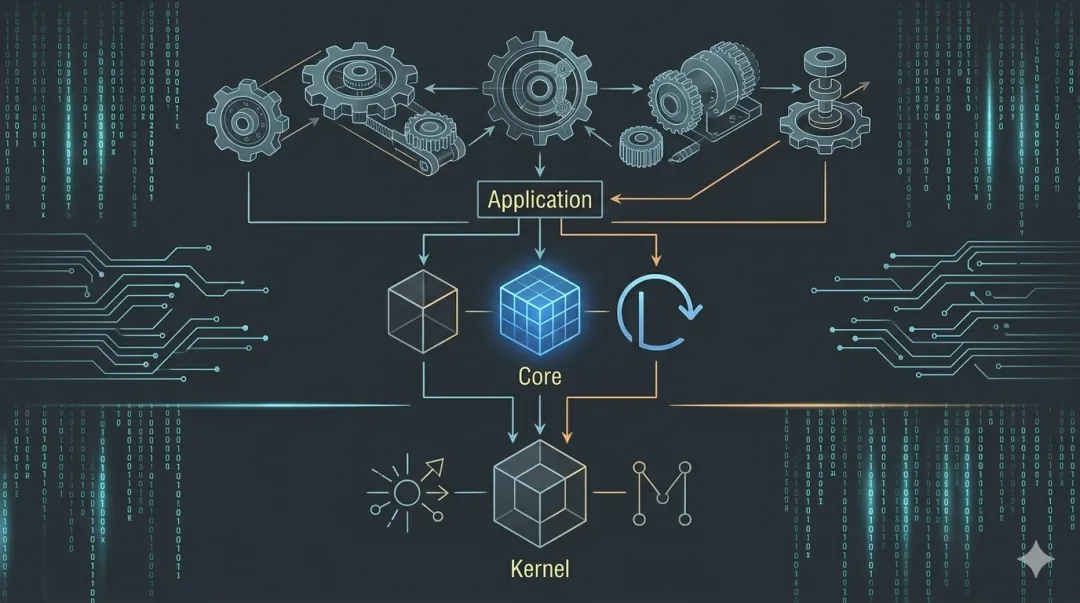
在 open-plm 里,插件化不是某个业务模块的专利,而是贯穿 Kernel(技术内核)、Core(业务能力)到 Application(业务应用)的全局集成方式。
一、最常见的跨模块调用,往往是破坏边界的开始
系统分层最怕一种情况:架构图上分了十几层,但到了启动的时候,应用层(Application)为了把底下模块的类注入进来,直接在启动类上加了一句扫描全包的注解。
这句代码看起来很省事,但它实际上把模块之间的边界彻底打穿了。
更严重的是,底层模块如果需要初始化数据库连接、需要注册拦截器、需要装配特定的事务管理器,如果全都指望应用层来手动配置,那底座就根本谈不上“独立运作”。
为了解决这个问题,open-plm 从底向上,全面拥抱了自动装配机制,把所有的能力都做成了“插件”。
二、Kernel 也是插件:插上就能用的技术内核
很多人在设计底座时,会把基础组件做成一堆普通的依赖包。但在 open-plm 里,Kernel 本身就是一个插件。
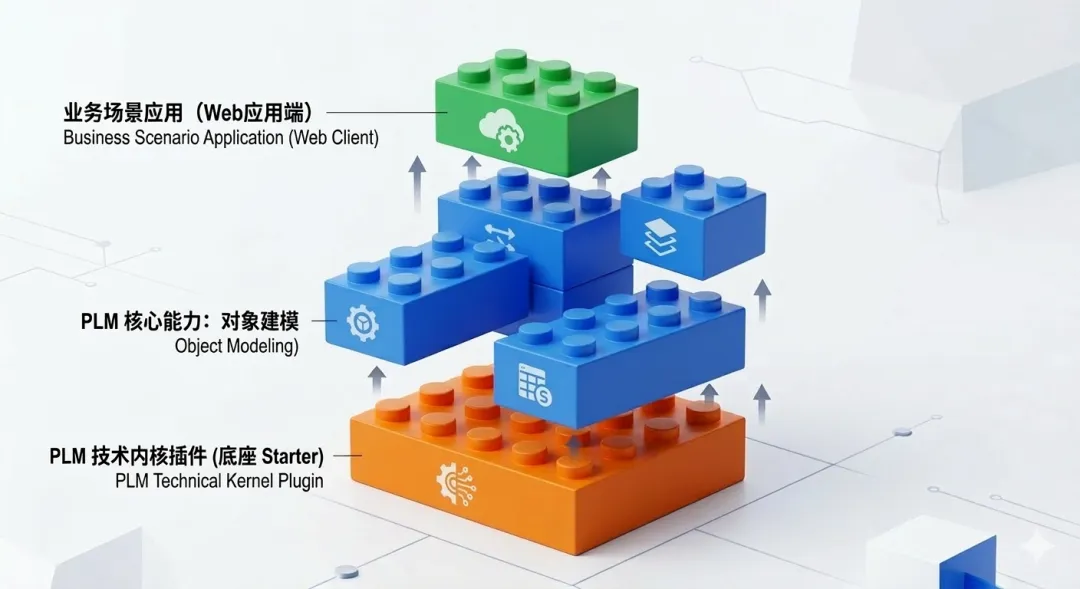
从架构设计的交付形态来看,Kernel 层不能只是一堆散落的接口和实现类。为了让上层无缝接入,open-plm 把底层 API 和核心引擎做了一层统一的封装,专门对外提供了一个标准的 Spring Boot Starter。
当一个业务应用引入了这个内核插件,它不需要写任何配置代码,内核就会在后台自动完成一整套复杂的初始化动作:
自动扫描当前环境里所有打上 @RegisterHook 的类,并按优先级注册到内存字典中。
甚至包括持久化层的底层抽象和针对特定数据库的方言适配,也会一并就绪。
应用层对此一无所知,也不需要知道。它只要引入了这个插件,系统瞬间就具备了事件驱动和 Hook 扩展的技术底座能力。
三、Core 也是插件:按需点单的业务能力
前面提过,Core 层沉淀的是 PLM 领域里可复用的业务能力。比如对象建模、运行时数据访问、结构导航。这些能力在 open-plm 的设计里,同样被打包成了独立的插件形态。
PLM 系统是非常庞大的,并不是所有业务线都需要全量能力。
如果一个轻量级的外部接口服务只需要简单的对象访问,它完全可以只引入“运行时数据访问插件”。
如果另一个复杂的 BOM 应用需要深度的图遍历能力,它再把“结构导航插件”也引入进来。
每个 Core 插件在被引入时,会自动将其依赖的数据库表结构、领域服务接口、以及默认的内置 Hook(比如对象保存前自带的规则校验 Hook)组装到当前环境里。这就是真正的“能力插拔”。
四、Application:成为一条纯粹的“组装流水线”
当 Kernel 和 Core 都完成了插件化封装之后,最顶层的 Application 层(业务应用)的形态也就彻底变了。
传统的应用层很重,里面全是各种框架整合代码和技术配置。但在 open-plm 的应用层设计里,你会发现它的依赖清单极其干净,基本只剩下了对底座各个插件的引入。
Application 的职责变得非常纯粹:聚焦业务场景。
它不需要关心 EventHub 怎么跑,不需要关心虚拟线程怎么起,也不用管底层数据存取的方言怎么转换。它只需要引入相应的底座插件,然后调用 Core 层暴露出来的对象 API,发布 Kernel 层定义好的业务事件,最后写自己这个业务独有的前端接口和业务编排。
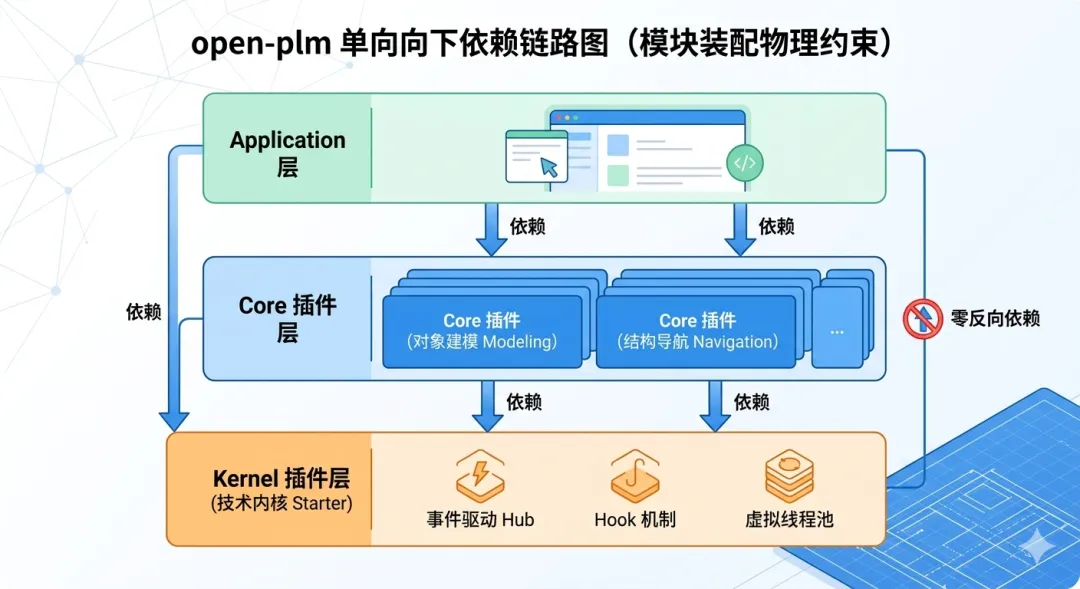
五、用物理隔离管住架构边界
这种全局插件化的设计,最后在工程上带来了一个非常硬核的收益:架构规范变成了物理约束。
Core 依赖 Kernel,但不依赖 Application。
Application 依赖 Kernel 和 Core。
如果只是口头约定,写代码的人早晚会为了图方便反向依赖。但通过划分出清晰的插件模块,依赖图谱会强行守住这个边界。如果在 Core 层试图去引用一个 Application 层的具体业务实体,底层编译直接就会被阻断。
这也是架构设计里很实在的一条经验:能靠物理隔离管住的边界,就不要靠开发规范去防守。
六、下一篇:能力有了,业务到底长什么样?
通过这五篇文章,我们从概念到工程,彻底把 open-plm 的“底座”部分交代清楚了:
拆出了 Kernel、Core、Application 三层架构。
最后用插件机制,把内核和所有能力变成了可组装的模块。
但是,对于一个真正的 PLM 来说,光有基础设施是跑不了业务的。PLM 的核心永远是数据模型:怎么定义一个对象?怎么描述一个关系?怎么在代码里优雅地把这两者存取出来?
下一篇,我们将跨过技术内核,正式进入 Core 层,聊聊 PLM 最硬核的第一块业务能力:
从技术内核到业务能力:为什么建模(modeling)是平台落地的第一步。
 夜雨聆风
夜雨聆风