夜雨聆风
夜雨聆风





具身智能相关论文开源代码推荐20260317
点击下方卡片,关注【具身智能小站】公众号
📅 2026年3月
👋 大家好!
来了!2026 年新开始的一个系列,主要是整理具身智能领域最近发表的提供开源代码或数据集的项目(论文),希望对相关领域的小伙伴有所帮助。获取这些论文的开源项目链接,可以直接在本文中查看。欢迎转发和关注!!👇
📊 今日数据统计
|
|
|
|---|---|
|
|
|
🤖 开源论文(重点板块)
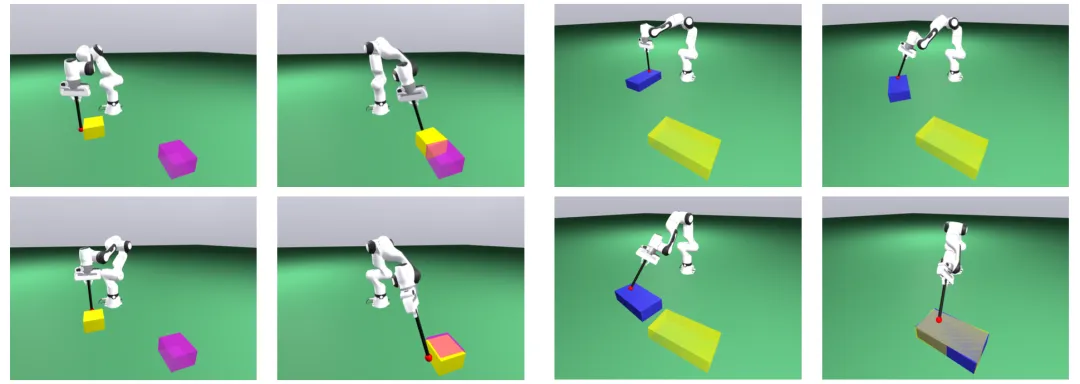
🔬 GrandTour:面向多模态感知与状态估计的野外足式机器人数据集
📌 Legged Robotics · SLAM · Multi-modal Perception · Dataset
✨ 发布了迄今为止规模最大、模态最丰富的足式机器人野外数据集,涵盖49个序列、超10公里路径,并配有毫米级精度的真值轨迹
📖 精确的状态估计和多模态感知是足式机器人在复杂大尺度环境中自主运行的前提。然而,至今缺乏一个公开的大型足式机器人数据集来捕捉开发此类算法所需的真实世界条件。本文介绍了GrandTour数据集,这是一个在充满挑战的室外和室内环境中收集的多模态足式机器人数据集,配备了先进的Boxi多模态传感器套件。数据涵盖高山、森林、废弃建筑和城市等多种环境,提供了来自旋转式LiDAR、多目RGB相机、深度相机和本体感受传感器的时延同步数据,并配有基于卫星RTK-GNSS和徕卡全站仪的高精度地面真实轨迹。该数据集支持SLAM、高精度状态估计和多模态学习的研究,并提供详尽的基准测试结果。
💡 让数据在多样性、规模和精度上都“狂野”起来,才能真正考验和推动足式机器人在真实世界中的感知与定位能力。
🔗 项目链接:https://grand-tour.leggedrobotics.com
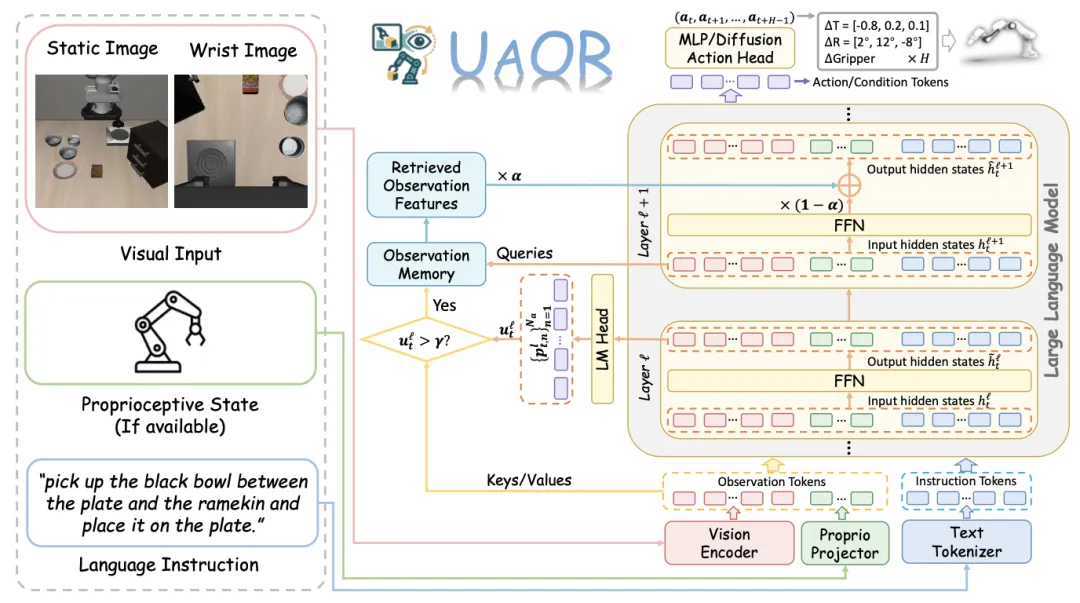
🔬 UAOR:面向视觉-语言-动作模型的不确定性感知观测信息重注入
📌 Vision-Language-Action Model · Uncertainty Estimation · Model Editing · Robotics
✨ 首次揭示VLA模型在推理过程中存在“观测信息遗忘”现象,并提出无需训练、即插即用的UAOR模块,通过不确定性触发将观测特征重新注入FFN层,提升模型性能
📖 VLA模型利用预训练的VLM作为主干来将图像和指令映射到动作。受前馈网络可作为“键值记忆”的启发,本文提出UAOR,一个有效的、无需训练且即插即用的VLA模块。当当前语言模型层表现出高不确定性(通过动作熵衡量)时,UAOR通过注意力检索将关键的观测信息重新注入下一层的FFN中。这种机制帮助VLA在推理过程中更好地关注观测,从而生成更自信和忠实的动作。综合实验表明,该方法能以最小的开销,在不同VLA模型上持续提升其在仿真和真实世界任务中的表现。
💡 大型模型在深度推理中会逐渐“遗忘”输入信息,一个简单的“提词器”就能有效地唤醒它的记忆,提升输出质量。
🔗 项目链接:https://uaor.jiabingyang.cn
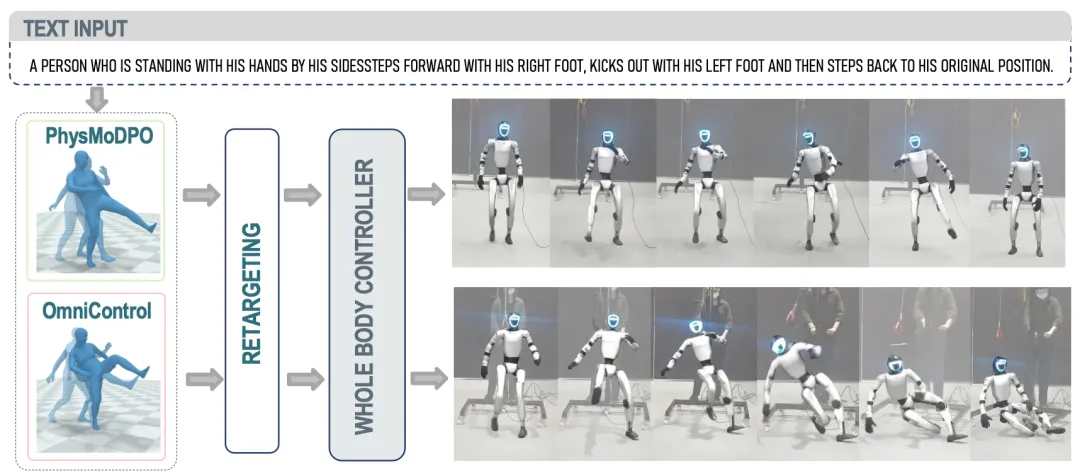
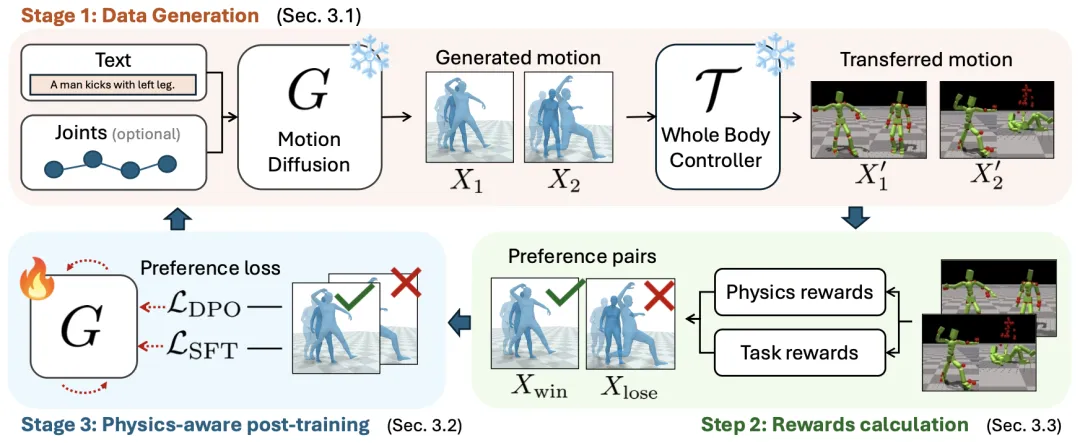
🔬 PhysMoDPO:基于偏好优化的物理合理人形运动生成
📌 Human Motion Generation · Diffusion Models · Direct Preference Optimization · Physics-Based Control
✨ 将物理仿真控制器引入扩散模型的微调环路,通过直接偏好优化,使生成的运动在遵循指令的同时,经得起物理引擎的推敲
📖 文本条件的人体运动生成主要依靠在大型数据集上训练的扩散模型。为将其应用于角色动画和机器人控制,通常需要添加一个全身控制器将生成的运动转换为可执行的轨迹。然而,这种转换可能导致运动与原始意图产生偏差。本文提出PhysMoDPO,一个直接偏好优化框架。它将全身控制器集成到训练流程中,并使用基于物理和任务特定奖励来构建偏好对,优化扩散模型,使其输出在经过控制器后既能符合物理定律,又能忠实于原始文本指令。实验证明,PhysMoDPO在文本到运动生成和空间控制任务中,持续提升了物理真实性和任务相关指标,并能零样本迁移到真实的G1人形机器人上。
💡 “所见非所得”是仿真到现实迁移的核心问题,直接优化“所得”而非“所见”,才能让生成的运动真正落地。
🔗 项目链接:https://mael-zys.github.io/PhysMoDPO/
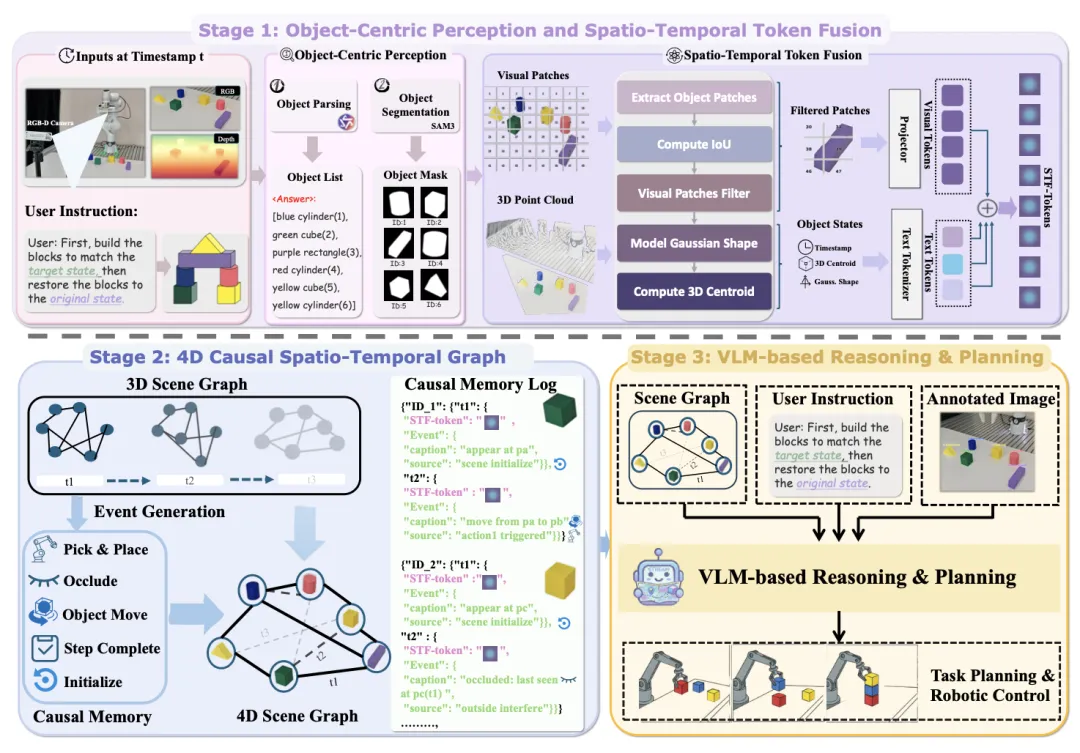
🔬 RoboStream:通过时空融合令牌与因果图实现长视野操作
📌 Vision-Language Model · Long-Horizon Planning · Causal Reasoning · Spatial Reasoning
✨ 针对VLM规划器在长时程任务中“空间幻觉”与“因果失忆”的缺陷,提出无训练框架RoboStream,通过时空融合令牌与因果图实现持久化的空间锚定与状态追踪
📖 基于VLM的规划器将每一步视为孤立的观察到动作的映射,缺乏对先前动作如何改变环境的感知,导致长视野任务中感知误差累积和前提条件违例。受人类持续心理模型的启发,本文提出RoboStream,一个无需训练的框架。它通过时空融合令牌将视觉证据与3D几何属性绑定,实现持久化的物体锚定;并通过因果时空图记录由动作触发的状态转换,维护因果连续性。这种设计使规划器能够追踪因果链并在遮挡下保持物体存在感。RoboStream在长视野RLBench和真实世界积木搭建任务中分别取得90.5%和44.4%的成功率,远超现有方法。
💡 让机器人拥有一个会“记事”和“记路”的内部模型,而不是每次都“失忆”重来,是迈向可靠长时程操作的关键。
🔗 项目链接:https://robostream123.github.io/
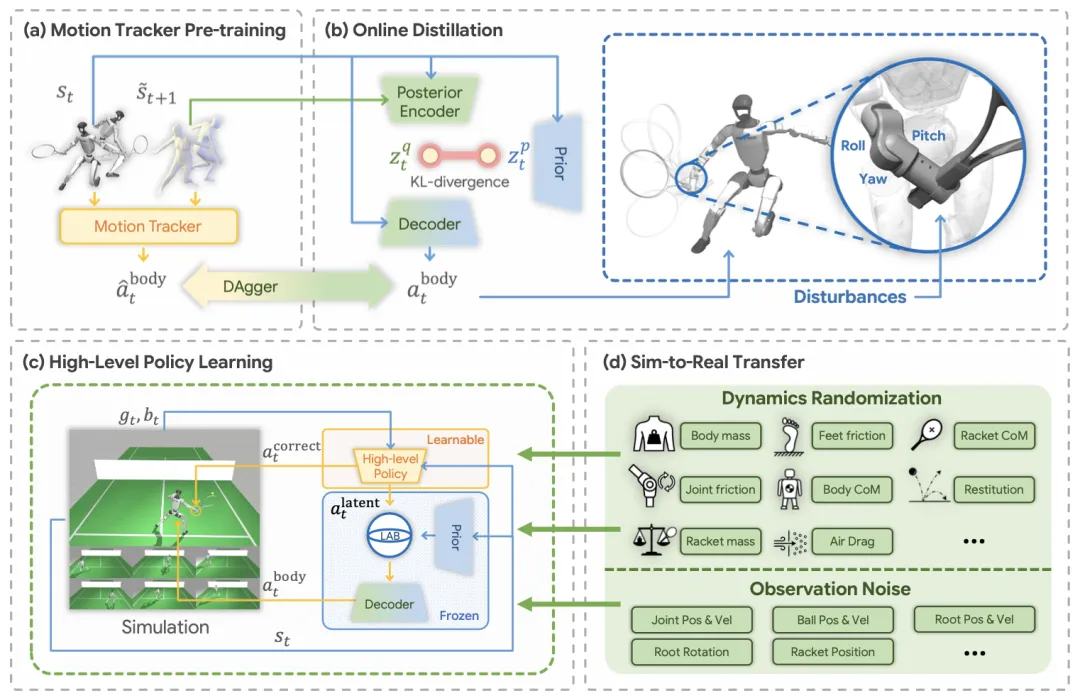
🔬 LATENT:从不完美人体运动数据中学习运动型人形机器人网球技能
📌 Humanoid Robotics · Reinforcement Learning · Motion Imitation · Tennis
✨ 首次提出利用不完美、碎片化的业余玩家运动数据,结合可修正的潜空间和潜动作屏障,让人形机器人在真实世界学会与人类进行多回合对打
📖 在高速、高动态的网球运动中,采集完美的人形机器人动作数据或人体运动数据极为困难。本文提出LATENT系统,通过从不完美的(不精确、不完整)人体运动数据中学习运动型人形机器人网球技能。核心洞察是,尽管数据不完美,但这些碎片化的基元技能(如正手、反手)仍然提供了有价值的先验知识。通过设计一个兼容动作修正的潜动作空间,并引入潜动作屏障来约束强化学习探索,高层策略能够校正和组合这些基元技能以完成任务。通过精心的仿真到现实迁移设计,该方法成功部署在Unitree G1人形机器人上,实现了与人类玩家的稳定多回合对打。
💡 完美数据难求,但大量不完美数据中蕴含的“运动基元”是解锁机器人复杂运动技能的钥匙。
🔗 项目链接:https://zzk273.github.io/LATENT/
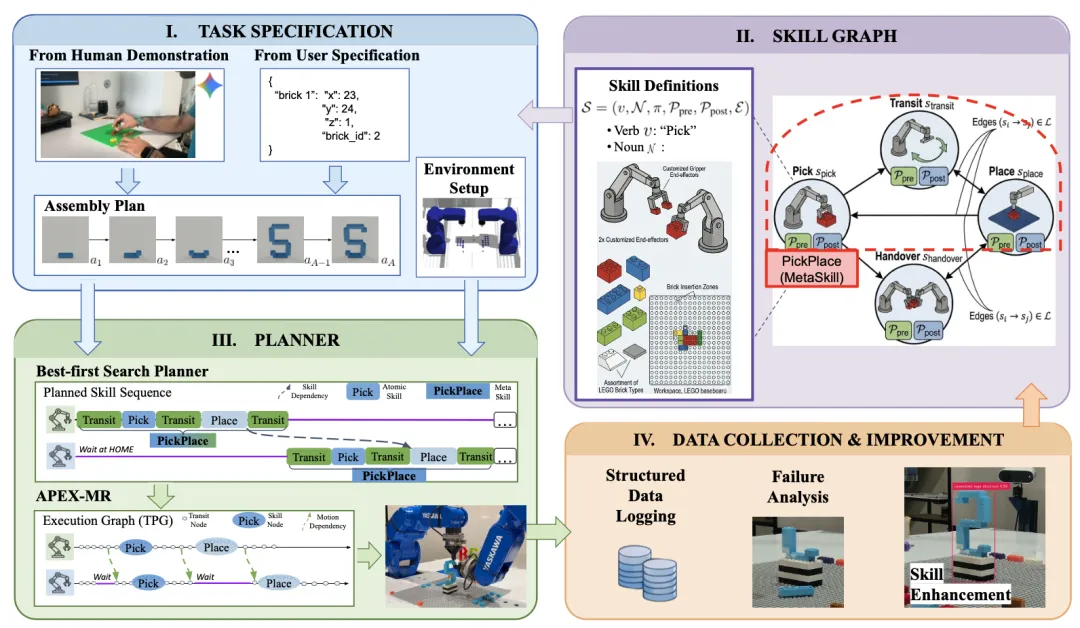
🔬 基于技能图表示的机器人装配自主集成与优化
📌 Robotic Assembly · Skill Graph · Task Planning · Autonomous Improvement
✨ 提出技能图这一统一抽象表示,将装配任务的语义描述、可执行策略、条件验证和性能评估融为一体,实现系统的快速集成与闭环优化
📖 传统的机器人装配系统需要大量的人工工程来集成新任务、适应新环境和随时间推移改进性能。本文提出了一个基于技能图表示的框架,用于自主集成和持续改进机器人装配系统。技能图将机器人的能力组织为基于动词的技能,并将语义描述与可执行策略、前置条件、后置条件和评估器显式连接起来。这种表示支持在语义层面进行规划,同时通过定义良好的接口与机器人控制器和感知模块连接,实现快速系统集成。部署后,相同的技能图结构支持系统性地收集数据并驱动闭环性能改进,使技能及其组合得以迭代优化。
💡 将机器人的能力构建成一张可查询、可组合、可学习的“技能图谱”,是实现自适应和可重用制造系统的基石。
🔗 项目链接:https://github.com/intelligent-control-lab/AIDF
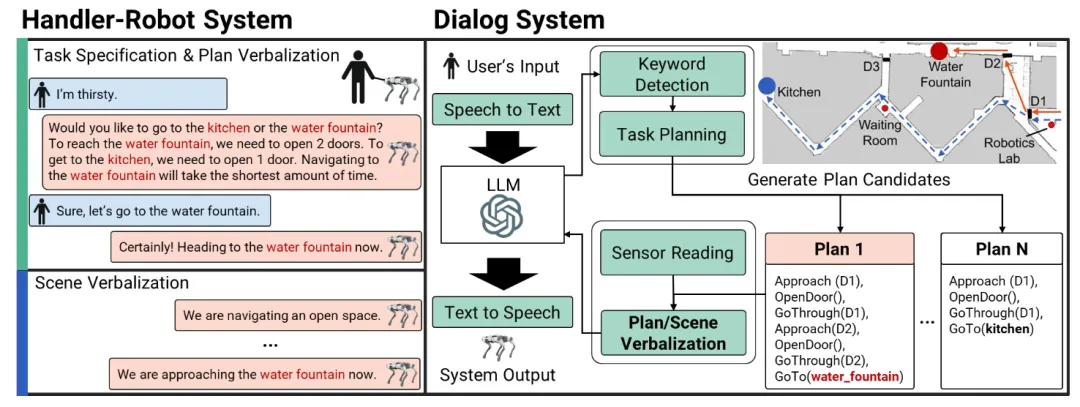
🔬 从犬吠到人言:迈向具备语言沟通能力的智能机器人导盲犬
📌 Assistive Robotics · Human-Robot Interaction · LLM · Visual Navigation
✨ 首次将大语言模型与任务规划器结合,为机器人导盲犬赋予了规划与场景的双重语言化能力,实现与视障人士的协同决策
📖 机器人导盲犬是一种辅助型四足机器人,旨在帮助视障人士避障和导航。为其赋予语言能力不仅仅是简单地在移动机器人上添加一个对话系统,其新挑战在于将语言与动态变化的环境进行结合,并提高人类使用者的空间意识。本文开发了一种新颖的机器人导盲犬对话系统,该系统使用LLM将导航计划和场景都语言化。通过“计划语言化”(在导航前提供多种路径方案)和“场景语言化”(在导航中描述周围环境),实现了人-狗团队内的协同决策。真实视障人士研究和仿真实验验证了该方法在用户满意度、任务效率和准确性上的优越性。
💡 对于辅助机器人,语言不仅是命令的载体,更是建立信任和共享空间认知的桥梁。
🔗 项目链接:https://sites.google.com/view/woofs-words
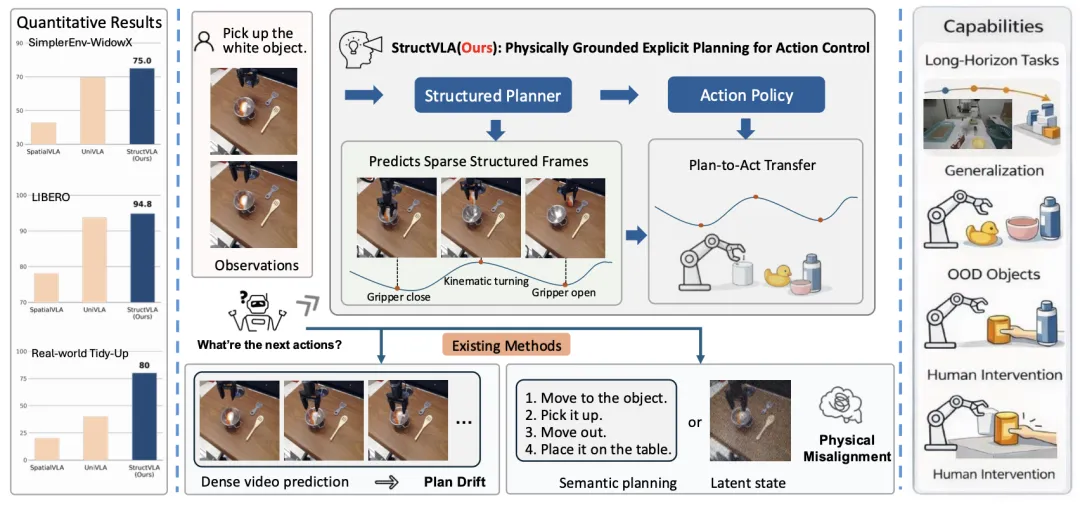
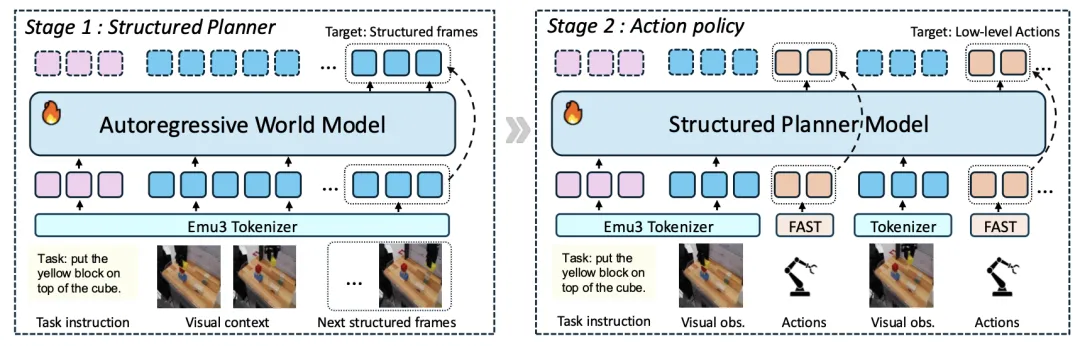
🔬 StructVLA:通过结构化世界模型实现稳健的长视野操作
📌 Vision-Language-Action Model · World Model · Long-Horizon Manipulation · Structured Planning
✨ 将生成式世界模型重构为显式的结构化规划器,通过预测物理基元的关键帧,弥合了高层视觉规划与低层运动控制之间的差距
📖 现有的基于世界模型的视觉-语言-动作(VLA)架构通过预测性的视觉前瞻改善了机器人操作。然而,密集的未来预测引入了视觉冗余并累积误差,导致长视野规划漂移。本文提出StructVLA,该框架将生成式世界模型重构为一个显式的结构化规划器,用于可靠控制。StructVLA不是预测密集的未来图像,而是预测稀疏的、物理上有意义的结构化帧,这些帧源自内在的运动学线索(如夹爪状态转换和运动转向点)。通过两阶段训练(先预测结构化帧,再生成低层动作),StructVLA在SimplerEnv和LIBERO基准测试中分别取得了75.0%和94.8%的平均成功率,并在真实世界的长视野任务中表现出强大的泛化性和鲁棒性。
💡 让机器人像人类一样,只记住任务进程中的关键“路标”,而不是每一步的像素,是实现长时程稳定的关键。
🔗 项目链接:https://wm-planner.github.io/structvla/
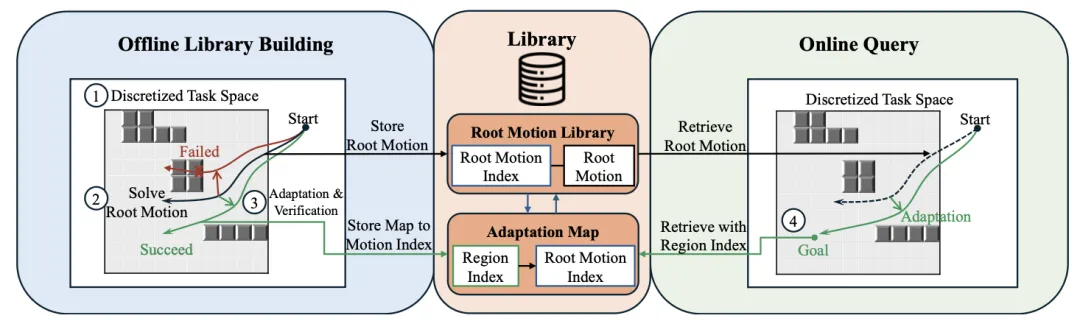
🔬 CoAD:基于压缩库和在线适应的连续目标操作的恒定时间规划
📌 Motion Planning · Experience-Based Planning · Task Space Regions · Goal-Conditioned Planning
✨ 通过将连续的目标空间离散为有限覆盖区域并压缩存储根轨迹,首次实现了对连续目标参数化任务空间的恒定时间规划
📖 在许多机器人操作任务中,机器人需要重复解决运动规划问题,这些问题的差异主要在于目标物体的位姿,而周围的工作空间保持不变。本文提出了CoAD框架,该框架在一个连续的目标参数化任务空间上提供恒定时间规划。CoAD将连续的任务空间离散为有限的任务覆盖区域,并通过仅为代表性根问题规划路径来构建一个压缩库。其他问题则通过从这些根解中进行快速在线适应(如线性插值、动态运动基元或简单轨迹优化)来处理。实验表明,CoAD在保持高成功率的同时,实现了亚毫秒级的查询时间,并将运动库压缩了高达97%,在效率和路径质量上均优于基线方法。
💡 与其为每个可能的目标都存储一条路径,不如存储能覆盖一片区域的“种子”路径,并在需要时快速“生长”出目标解。
🔗 项目链接:https://github.com/elpis-lab/CoAD
🔬 MACRO:基于简化模型的模式感知平面接触操作
📌 Non-prehensile Manipulation · Contact Mechanics · Reduced-Order Models · Bimanual Manipulation
✨ 将复杂的平面接触力学抽象为五种直观的简化运动模型,实现单臂与双臂操作的统一规划与优化-free执行
📖 非抓取式平面操作对于机器人在家庭、仓库和工厂中的应用至关重要,但由于其混合接触动力学、欠驱动特性和非对称摩擦限制,传统上需要计算昂贵的迭代控制。本文提出了一个基于接触拓扑选择和简化运动学建模的模式感知框架,用于单臂或双臂的平面操作。核心思想是将复杂的力-螺旋极限曲面力学抽象为一个由物理直观模型组成的离散库。通过将轨迹生成锚定到这些简化模型(如将按压-滑动运动建模为独轮车),该框架可以计算所需的物体力旋量,并通过直接的代数分配器将可行的、受摩擦约束的接触力分配给一个或两个手臂。实验在多种单臂和双臂操作任务中验证了这种快速、免优化的方法的有效性。
💡 将复杂的物理交互简化为经典的、可解释的运动模型,是实现实时、鲁棒的非抓取式操作的关键。
🔗 项目链接:https://sites.google.com/view/pushpressslide