 夜雨聆风
夜雨聆风





让 AI 测试助手“读懂你的业务”:RAG 知识库 + UI 截图多模态解析
让 AI 测试助手“读懂你的业务”:RAG 知识库接入 + UI 截图多模态解析
|
🔖「AI 测试用例设计助手|LangGraph 实战系列」第 5 篇前几篇我们解决了:并行提速、质量闭环、多模型协同、结构化输出。但要真正落地到企业项目,还差一个关键能力:业务知识与交互细节。这篇我分享两条“增强路线”:RAG 知识库 和 多模态 UI 解析。 |
前言:为什么“懂业务”比“会生成”更重要
LLM 很擅长把话说得“像样”,但它天然不知道:
- 你们的权限模型、角色规则是什么
- 某个页面字段有哪些校验/默认值/联动逻辑
- 历史上哪些模块经常出问题,回归要重点测什么
- 团队测试规范与命名规则是什么
所以只靠“需求文档一段文字”,AI 生成的用例往往会:
- 泛化:像模板,不像你们产品
- 漏规则:漏掉权限/风控/异常提示/边界逻辑
- 难执行:步骤缺关键 UI 字段与按钮名,落地时得靠人补
我的做法是:在生成阶段给模型两类“外部能力”——1)RAG:让它能查资料(产品知识/操作手册/历史用例)2)多模态:让它能读懂截图(字段、按钮、提示语、交互)
一、架构里这两条增强能力放在哪?
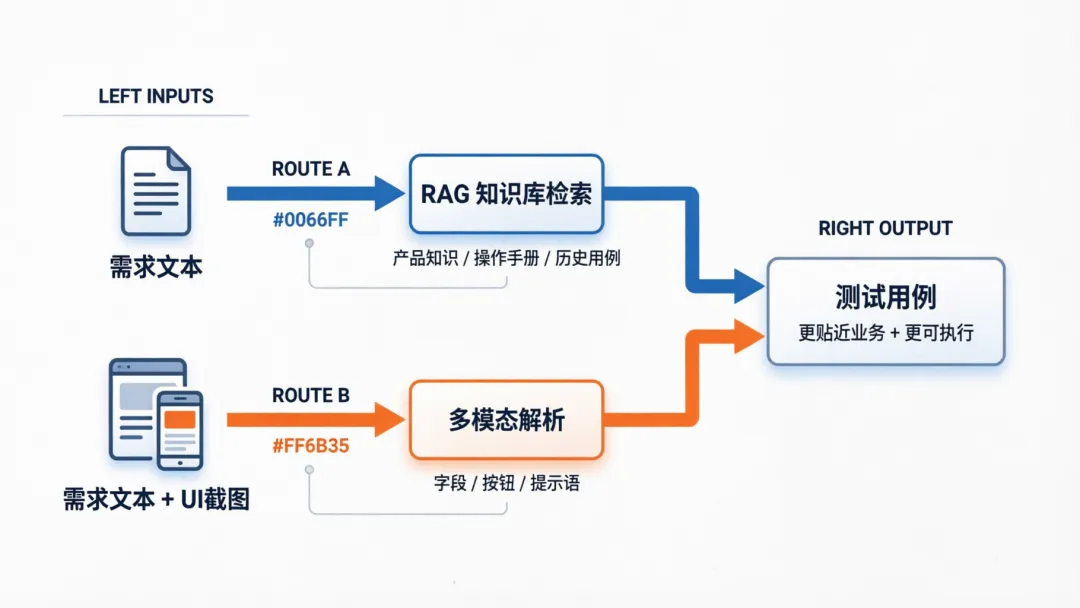
1.1 多模态的入口:条件路由“有图先解析”
init_state 会识别输入里是否有设计稿图片:
- 纯文本需求 → 走
parse_requirement - 文本 + 图片 → 先走
parse_images,再进入需求/生成流程 - 非需求 →
simple_chat
你可以理解为:截图解析是用例生成的前置“补全信息”步骤。
1.2 RAG 的入口:在 Worker 内按需调用 Tool
RAG 不放在固定节点里强制执行,而是:
- 把知识库查询封装为
@tool - 在
generate_casesWorker 中以 Agent 方式按需调用
原因很现实:并不是每个功能点都需要查库。强制检索会带来:
- 成本上升(每个功能点都要查)
- 噪声变大(不相关内容混进上下文)
- 输出更不稳定(上下文越长越容易漂)
我的目标是:能查、会查、该查才查。
二、RAG 知识库增强:3 类知识库怎么拆,怎么用
2.1 我为什么拆成 3 个知识库
| 知识库 | 主要内容 | 适合补什么 |
|---|---|---|
| 产品知识库(Product KB) | 业务背景、流程、角色权限、规则说明 | 权限差异用例、核心业务规则、影响范围 |
| 操作手册(Manual KB) | 页面入口、字段释义、操作步骤、交互说明 | 可执行步骤、字段校验、提示语、入口路径 |
| 历史用例库(History Case KB) | 历史覆盖模式、回归清单、常见缺陷点 | 回归重点、异常场景模板、经验复用 |
拆库的好处:
- 检索更精准(不同问题去不同库)
- 权限更清晰(历史用例可能更敏感)
- 可演进(后期还能加“接口文档库/埋点规范库”等)
2.2 用 Tool 封装知识库查询(伪代码示意)
python from langchain.tools import tool@tooldef search_product_kb(query: str) -> str:"""查询产品知识库:业务规则、流程、角色权限等。"""return bailian_client.search(index=KB_INDEX_PRODUCT, query=query)@tooldef search_manual_kb(query: str) -> str:"""查询操作手册:页面入口、字段、按钮、提示语、交互步骤。"""return bailian_client.search(index=KB_INDEX_MANUAL, query=query)@tooldef search_history_case_kb(query: str) -> str:"""查询历史用例库:类似模块的用例覆盖模式、常见缺陷点。"""return bailian_client.search(index=KB_INDEX_HISTORY_CASE, query=query)这里我更倾向于返回“可读文本 + 结构化片段”的混合结果(例如带小标题/要点列表),方便模型引用。
═════════ 2.3 Worker 里怎么“按需检索”?
在
generate_casesWorker 的 Prompt/策略里,我会加两个约束:约束 A:只有在信息不足时才检索例如出现以下信号就建议检索:
- 需求提到“权限/角色/审批/风控”等规则,但没写清楚
- 需求写了“按产品规范校验”,但规范在文档里
- 需求没有明确字段/提示语,但 UI/手册有
约束 B:检索结果必须落到用例里比如检索到“手机号校验规则”,那就应该体现在:
- 前置条件:账号/手机号格式
- 步骤:输入非法手机号
- 预期:提示语/禁用态/错误码(如果有)
这样 RAG 才是“提升可执行性”,而不是“堆上下文”。
2.4 一个很实用的落地建议:RAG 结果做“摘要再注入”
很多知识库返回会很长。我的习惯是:
- 先检索
- 再让模型/规则把检索结果压缩成“与当前功能点相关的 5-10 条要点”
- 最后用这些要点指导用例生成
好处:
- 降低上下文长度
- 减少无关信息干扰
- 输出更稳定
三、UI 截图多模态解析:让用例真正��执行
很多需求文档写的是“支持编辑/删除/筛选”,但截图里才有关键细节:
- 字段名、必填标识、placeholder
- 按钮文案、禁用态、loading 态
- 弹窗标题、提示语、二次确认
- 表格列、筛选项、分页规则
- 错误提示、空状态文案
这些内容直接决定用例是否“能照着一步步执行”。
3.1 parse_images 节点输出什么?
parse_images 的目标不是“描述图片”,而是抽取测试要用的信息结构,比如:
- 页面/模块名称
- 关键控件清单:输入框、下拉、按钮、tab、表格列
- 字段规则:必填、长度、格式、范围、联动
- 交互流程:点击后跳转/弹窗/调用接口(如果能推断)
- 文案:错误提示、空状态、成功提示
- 多端差异(如果截图显示)
最后把这些信息放入全局状态的 image_analysis,给后续节点使用。
3.2 为什么我把 image_analysis 注入到 Worker?
因为用例生成发生在 Worker(按功能点并行)里。最自然的做法是把 image_analysis 作为上下文传递给每个 Worker:
- 功能点 A:引用截图里的字段规则与按钮文案
- 功能点 B:引用表格列与筛选项
- 功能点 C:引用弹窗与提示语
这样每个功能点生成的用例都更贴近 UI,步骤会更具体。
3.3 多种图片来源格式兼容(工程上的“细节坑”)
在真实场景里,设计稿/截图可能来自:
file://...本地路径(LangGraph Studio 常见)http:///https://在线链接(协作最常见)base64(前端上传或接口传输常见)
我的做法是:
- 在
init_state统一归一化图片输入 parse_images只关心“我拿到的是一组可解析的图像引用”- 失败时要能降级:图片解析失败不影响纯文本需求继续跑(只是不那么细)
四、RAG + 多模态如何协同?(一个很关键的组合策略)
实际效果最好的方式是:
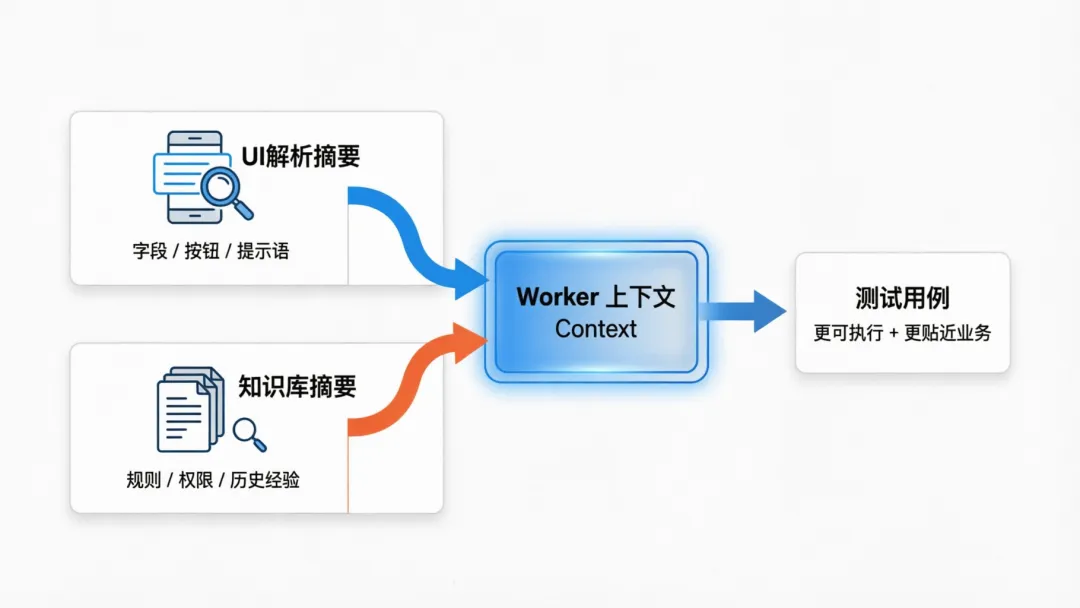
- 先用多模态补“界面事实”比如:字段名、按钮文案、提示语、必填标识、布局信息这类信息来自截图,可信度高、非常具体。
- 再用 RAG 补“业务规则与历史经验”比如:权限矩阵、风控规则、审批流、常见缺陷点、团队规范这类信息来自知识库,更偏规则与经验。
最终用例生成时,Worker 的上下文大概是:
- 功能点结构化描述(feature)
- UI 解析摘要(image_analysis)
- 业务知识检索摘要(rag_summary,可选)
- 质量评审回流建议(suggestions,可选)
- 既有用例参考(existing_cases,可选)
这就是“可落地”的 AI 测试用例生成:有界面细节、有业务规则、有质量约束。
五、风险与 Trade-off:我为什么把这两条能力都做成“可选”
5.1 RAG 的风险
- 知识库脏数据会“带坏模型”
- 检索结果过长会让输出漂
- 成本不可控(尤其是功能点多时)
所以我做了开关:
ENABLE_KNOWLEDGE_BASE=false时完全关闭- 开启后也尽量按需检索,而不是强制检索
5.2 多模态的风险
- 截图不清晰/遮挡/多语言,会影响解析质量
- 解析耗时与成本高于纯文本
- 解析结果可能需要“摘要化”,否则上下文过长
所以我同样把它设计为:
- 有图才走
parse_images - 解析失败可降级(纯文本路径继续跑)
六、总结:让 AI “更像你的测试同事”,关键是给它“你们的资料”和“你们的界面”
在我看来,RAG 与多模态不是“锦上添花”,而是把 AI 从“泛化生成器”变成“项目内可交付助手”的关键一步:
- RAG:让它知道“你们怎么做业务”
- 多模态:让它知道“你们页面长什么样、怎么操作”
当两者结合,再配合前几篇的:
- 并行 Worker 提速
- 质量评审闭环
- 多模型协同降本
- Pydantic 结构化输出保稳定
整个系统才真正具备“工程化可落地”的形态。
下一篇预告(第 6 篇)
《复盘:做这个 AI 测试助手,我踩过的坑和 8 个关键决策》会把 LangGraph 选型、reducer、阈值策略、导出格式、配置体系等 trade-off 做一次完整复盘。