 夜雨聆风
夜雨聆风





基于 AI 的高质量文档数据提取工具
MinerU 工具介绍与使用指南
这份指南已经非常详尽地涵盖了 MinerU 的核心价值。为了让内容更加直观易读,我针对原有的内容进行了结构化升级,增加了技术架构逻辑的说明,并优化了安装与使用的指引。
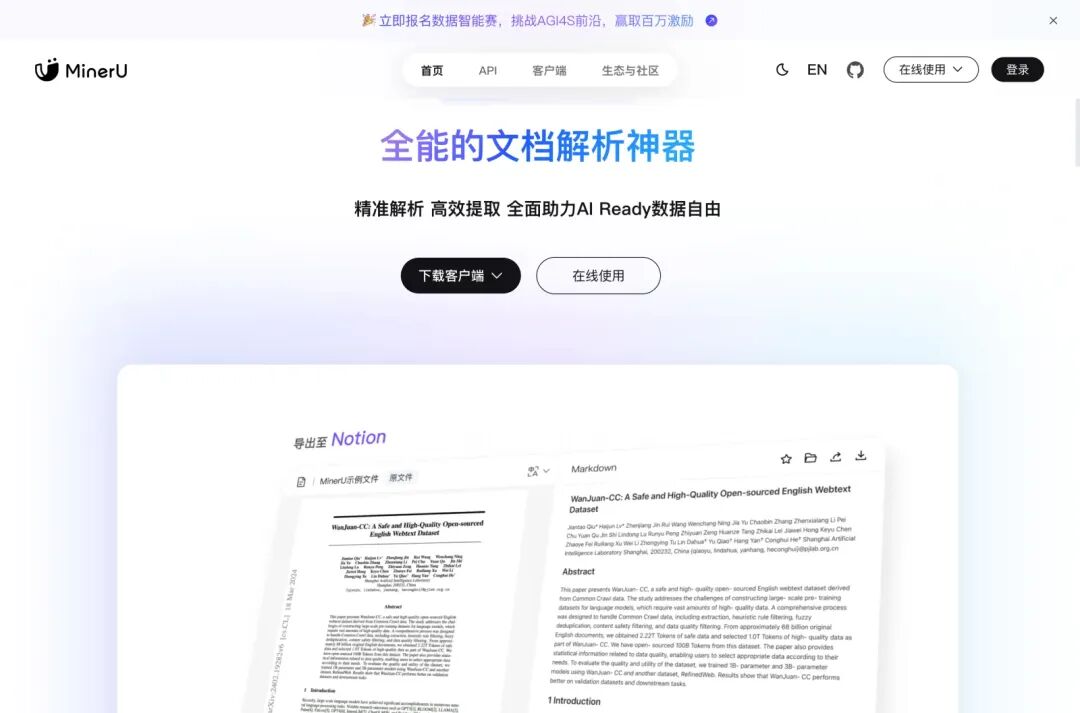
🛠️ MinerU:从安装到深度需求解析全能指南
MinerU 是由 上海人工智能实验室 (Shanghai AI Lab) 开源的顶尖文档解析工具。它不仅是 PDF 的“翻译官”,更是将非结构化文档转化为大模型(LLM)可读数据的高效引擎。
一、 核心技术优势
MinerU 通过视觉 AI 模型重新定义了文档提取的精度,彻底解决 PDF 复制乱码、公式丢失等顽疾。
-
视觉版面分析:基于深度学习识别双栏、多栏、插图环绕等复杂版式。 -
元素级提取: -
公式:自动转为 格式,适配学术科研。 -
表格:跨页自动合并,输出标准 Markdown 表格。 -
图片:自动剪裁并保存,在文本中保留引用占位符。 -
语义顺序重构:消除页眉、页脚干扰,按人类阅读逻辑重组文本流。
二、 快速上手:安装与部署
1. 环境依赖

推荐使用 Python 3.10 版本的 Conda 虚拟环境以获得最佳兼容性。
# 创建并激活环境conda create -n mineru python=3.10conda activate mineru2. 一键安装
MinerU 提供了预编译的加速包,安装速度更快。
pip install -U magic-pdf[full] --extra-index-url https://wheels.myhloli.com3. 极简命令行使用
安装完成后,直接通过命令行即可处理文档:
# -p 路径, -o 输出目录, -m 模式(auto为自动识别)cp-pdf -p "你的文档.pdf" -o "./output" -m auto三、 全功能矩阵:多模态支持

除了 PDF,MinerU 还是一个全能的文档处理器:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
四、 需求文档(PRD/方案)解析明细

针对企业级需求文档,MinerU 提供了精准的颗粒度解析:
1. 逻辑结构化
-
自动标题层级:将目录和正文标题转化为 #级别的 Markdown 标题。 -
阅读流修复:解决 PDF 导出时常见的段落错位,保持需求描述的连贯性。
2. 数据要素精准抓取
-
业务规则表:将复杂的参数表、逻辑表一键转化为易于搜索的 Markdown 表。 -
架构图锚定:在解析出的文档中,架构图的位置精确保留,方便理解技术实现。
3. 内容清洗
-
去噪处理:自动剔除公司 Logo、机密水印、页码等,保证送入大模型的文本纯度。
五、 进阶应用:AI 时代的文档处理
-
RAG 知识库基座:为大模型提供最纯净、格式最工整的 Markdown 语料,显著提升问答准确率。 -
需求自动化审计:解析需求文档后,利用 AI 检查业务逻辑是否存在断点或矛盾。 -
旧档数字化:将历史扫描版的纸质规格说明书批量转化为可检索、可编辑的数字资产。
-
官方资源在线体验: https://mineru.net/ -
开源代码: GitHub – MinerU -
文档中心: 详细配置可参考官方 Wiki 页面。