 夜雨聆风
夜雨聆风





【实战】让 AI 帮你处理 PDF?一个技能搞定所有操作
【实战】让 AI 帮你处理 PDF?一个技能搞定所有操作
合同要提取文字、报表要转 Excel、扫描件要做 OCR……每次处理 PDF 都要查文档、装库、调代码,烦不烦?今天告诉你一个好消息:装一个技能,让 AI 编程助手直接帮你搞定!
开发者的 PDF 噩梦
说实话,PDF 处理绝对是开发者的”老大难”问题:
-
• 合同审核:几百页 PDF,手动复制粘贴提取关键信息? -
• 财务报表:领导要的 Excel 表格藏在 PDF 里,怎么提取? -
• 扫描件识别:历史资料全是图片 PDF,搜都搜不到 -
• 批量处理:1000 个 PDF 要合并、拆分、加水印,一个个来?
以前的解决方案要么贵(Adobe Acrobat),要么难(自己写代码调库),要么慢(在线工具一个个传)。
但现在,AI 编程助手 + 一个官方技能 = 直接用自然语言搞定。
什么是 Skills?为什么需要 PDF 技能?
Skills(技能)是一种让 AI 编程助手快速获得专业领域能力的机制。
简单理解:AI 助手很聪明,但不可能记住所有库的用法。通过”技能”,我们可以给它加载特定领域的最佳实践——就像给它装上一个”专业模块”。
Anthropic 官方开源的 PDF 技能,专门针对 PDF 处理场景,覆盖了:
-
• Python 主流库的用法(pypdf、pdfplumber、reportlab) -
• 命令行工具的调用方式(pdftotext、qpdf、pdftk) -
• 高级任务的完整流程(OCR、水印、加密)
装上这个技能后,你只需要告诉 AI:”帮我把这个 PDF 的表格提取成 Excel”,它就知道该用什么库、怎么写代码、怎么处理异常。
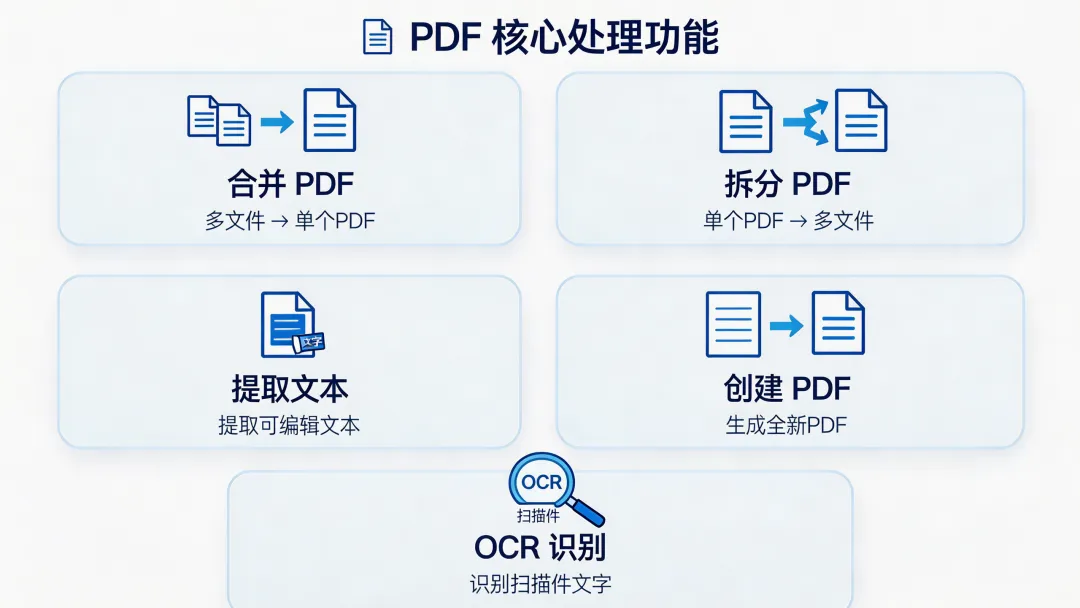
核心能力全解析
1. 基础操作:合并、拆分、旋转
这是最常见的需求,PDF 技能支持多种工具实现:
Python 方案(pypdf):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
from pypdf import PdfReader, PdfWriter
# 合并多个 PDF
merger = PdfWriter()
for pdf_file in ["file1.pdf", "file2.pdf", "file3.pdf"]:
merger.append(pdf_file)
merger.write("merged.pdf")
merger.close()
# 拆分 PDF(提取第 1-5 页)
reader = PdfReader("input.pdf")
writer = PdfWriter()
for page_num in range(5):
writer.add_page(reader.pages[page_num])
writer.write("split.pdf")
# 旋转页面(顺时针 90 度)
reader = PdfReader("input.pdf")
writer = PdfWriter()
for page in reader.pages:
page.rotate(90)
writer.add_page(page)
writer.write("rotated.pdf")
命令行方案(qpdf/pdftk):
1 2 3 4 5 6 7 8
# qpdf 合并
qpdf --empty --pages file1.pdf file2.pdf -- merged.pdf
# pdftk 拆分
pdftk input.pdf cat 1-5 output split.pdf
# qpdf 旋转所有页面
qpdf --rotate=+90 input.pdf rotated.pdf
2. 文本与表格提取(最实用!)
这绝对是 PDF 技能的杀手级功能。
提取文本(保留布局):
1 2 3 4 5 6
import pdfplumber
with pdfplumber.open("report.pdf") as pdf:
for page in pdf.pages:
text = page.extract_text()
print(text)
提取表格并导出到 Excel:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
import pdfplumber
import pandas as pd
with pdfplumber.open("financial_report.pdf") as pdf:
all_tables = []
for page in pdf.pages:
tables = page.extract_tables()
for table in tables:
df = pd.DataFrame(table[1:], columns=table[0])
all_tables.append(df)
# 合并所有表格并导出
final_df = pd.concat(all_tables, ignore_index=True)
final_df.to_excel("output.xlsx", index=False)
高级表格处理(复杂布局):
1 2 3 4 5 6 7 8 9 10
import pdfplumber
with pdfplumber.open("complex_table.pdf") as pdf:
page = pdf.pages[0]
# 自定义表格检测参数
table = page.extract_table(table_settings={
"vertical_strategy": "text",
"horizontal_strategy": "lines",
"snap_tolerance": 3,
})
3. 创建 PDF(报告生成)
需要自动生成 PDF 报告?reportlab 是最佳选择:
1 2 3 4 5 6 7 8
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
# 创建基础 PDF
c = canvas.Canvas("report.pdf", pagesize=letter)
c.drawString(100, 750, "月度销售报告")
c.drawString(100, 700, "2024年3月 - 总销售额:¥1,234,567")
c.save()
多页 PDF + 自动换页:
1 2 3 4 5 6 7 8 9 10 11 12 13
from reportlab.lib.pagesizes import letter
from reportlab.platypus import SimpleDocTemplate, Paragraph, Spacer
from reportlab.lib.styles import getSampleStyleSheet
doc = SimpleDocTemplate("multi_page.pdf", pagesize=letter)
styles = getSampleStyleSheet()
content = []
for i in range(50):
content.append(Paragraph(f"第 {i+1} 段内容...", styles['Normal']))
content.append(Spacer(1, 12))
doc.build(content)
4. 高级功能
OCR 扫描件识别:
1 2 3 4 5 6 7 8 9 10 11
from pdf2image import convert_from_path
import pytesseract
# 将 PDF 转为图片
images = convert_from_path("scanned_document.pdf")
# 对每一页进行 OCR
for i, image in enumerate(images):
text = pytesseract.image_to_string(image, lang='chi_sim') # 中文识别
print(f"--- 第 {i+1} 页 ---")
print(text)
添加水印:
1 2 3 4 5 6 7 8 9 10 11
from pypdf import PdfReader, PdfWriter
reader = PdfReader("original.pdf")
watermark = PdfReader("watermark.pdf")
writer = PdfWriter()
for page in reader.pages:
page.merge_page(watermark.pages[0])
writer.add_page(page)
writer.write("watermarked.pdf")
密码保护:
1 2 3 4 5 6 7 8 9 10 11
from pypdf import PdfReader, PdfWriter
reader = PdfReader("sensitive.pdf")
writer = PdfWriter()
for page in reader.pages:
writer.add_page(page)
# 设置密码(用户密码 + 所有者密码)
writer.encrypt(user_password="read123", owner_password="admin456")
writer.write("protected.pdf")
一行命令,即装即用
在你的 AI 编程助手中集成 PDF 技能:
1
npx skills add https://github.com/anthropics/skills --skill pdf
安装完成后,你可以直接用自然语言下达指令:
-
• “帮我把这 10 个 PDF 文件合并成一个” -
• “提取这份财报中所有的表格,导出到 Excel” -
• “这是一份扫描件,帮我 OCR 识别成文字” -
• “给这份合同加上公司水印”
AI 助手会自动选择最合适的工具和方案。
典型使用场景
|
|
|
|
|---|---|---|
| 合同审核 |
|
|
| 财务报表处理 |
|
|
| 档案数字化 |
|
|
| 报告自动生成 |
|
|
| 文档安全 |
|
|
| 批量整理 |
|
|
数据说话:这个技能有多火?
看看 Anthropic PDF 技能的真实数据:
-
• 周安装量:41.8K(每周超过 4 万次安装) -
• GitHub Stars:96K(接近 10 万星标)
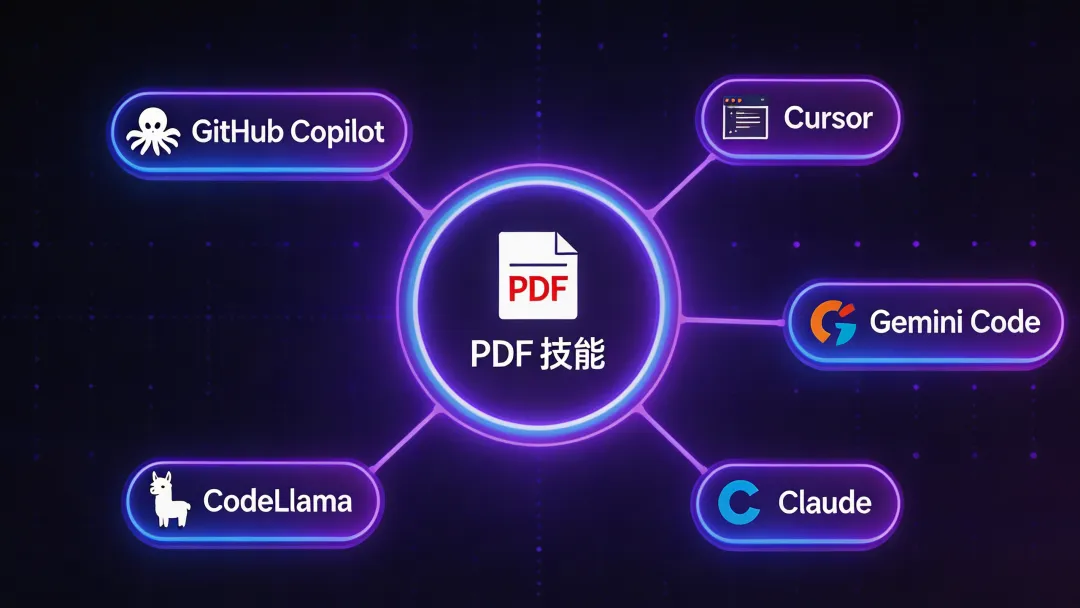
已集成到主流 AI 编程平台:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
几乎所有主流的 AI 编程助手都在用这套技能,说明它确实好用、稳定、覆盖面广。
写在最后
PDF 处理曾经是开发者的痛点,但有了 AI 编程助手 + 官方 PDF 技能,这一切变得前所未有的简单。
记住这几点:
-
• 不需要记住每个库的 API,AI 帮你选择最佳方案 -
• 复杂任务(OCR、表格提取)也能用自然语言完成 -
• 一个技能覆盖 Python 库 + 命令行工具,灵活切换
下次再遇到 PDF 处理任务,别再手动查文档了——让 AI 帮你干活。
你平时处理 PDF 最头疼的是什么场景?欢迎在评论区聊聊!
如果觉得有用,别忘了点赞、在看、转发三连支持一下~
参考资料:Anthropic Skills – pdf
GitHub: https://github.com/anthropics/skills
技能地址: https://skills.sh/anthropics/skills/pdf