 夜雨聆风
夜雨聆风





OmicClaw | 装了这个工具,以后单细胞和空间分析还愁啥,解决多组学分析碎片化痛点
⭐ 设为星标 · 第一时间获取生信前沿
💡 日常好的生信代码已放入免💰共享服务器中(人人皆可用):https://vip.r-py.com/


📦 代码获取
🔧 代码资源:
• https://github.com/Starlitnightly/omicverse
很大的亮点在于AI能自动分析这套完整的体系了,铁定了是款必火🔥的工具

🔥 核心突破
这项研究的核心突破在于提出了一套全新的可执行自然语言多组学分析框架OmicClaw,解决了当前AI辅助多组学分析中代码幻觉、方法选择错误两大核心问题,同时实现了全流程分析的可追溯、可重复。与以往纯大语言模型自由生成代码的AI分析工具不同,OmicClaw将自然语言分析锚定在统一的OmicVerse生态系统中,通过基于注册表的受限运行空间约束大语言模型的行为,避免了无效函数调用、参数误用等常见错误。该框架整合了上游处理、预处理、单细胞、空间、转录组和基础模型等超过100种分析方法,全部统一到以AnnData为核心的共享接口中,同时通过J.A.R.V.I.S.运行层暴露了超过200个注册函数和类,能够验证分析前提、保留分析溯源、支持迭代错误修复。
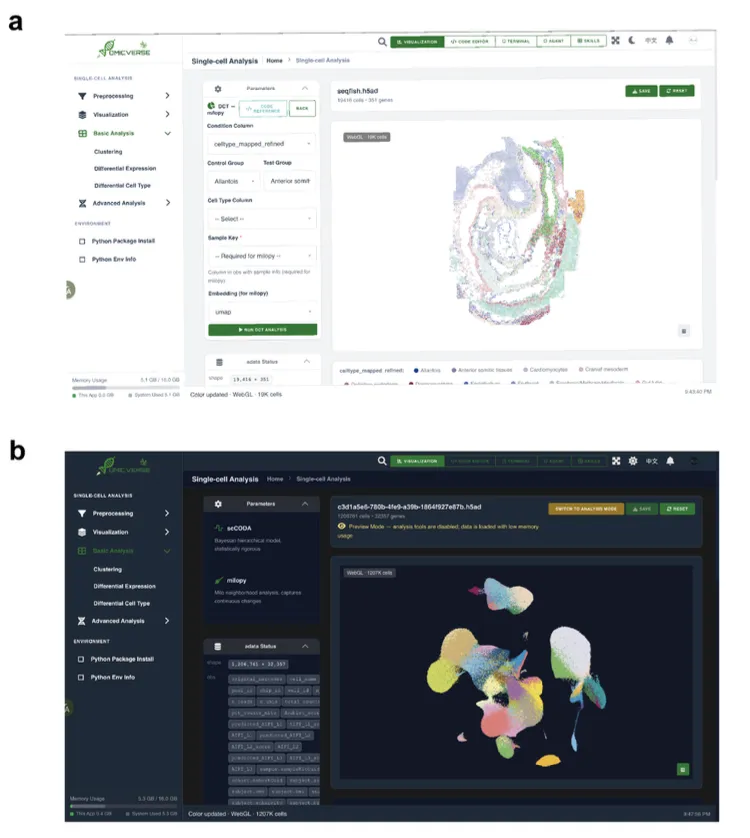
在涵盖scRNA-seq、空间转录组、RNA速度、scATAC-seq、CITE-seq和多组学分析的15个任务基准测试中,基于OmicClaw的ov.Agent比纯一次性大语言模型基线在 rubric评分中表现更优,尤其对于长周期多步工作流的提升更加明显。此外,OmicClaw还支持通过MCP兼容服务器进行外部代理访问,同时提供了对新手友好的网页交互平台,支持交互式分析、代码执行和百万级数据可视化,为现代多组学研究中的可重复人机协作提供了实用基础。

文章摘要:OmicClaw是基于统一OmicVerse生态的可执行自然语言多组学分析框架,解决了多组学分析工具碎片化和AI分析代码幻觉的问题,支持全流程可重复分析
📚 研究背景
在实际分析中,研究者必须手动桥接原本不兼容的工具,为不同方法的API编写自定义包装,手动整理跨工作流的中间输出。这种碎片化不仅大幅提升了技术门槛,尤其对入门不深的研究生不友好,还削弱了分析结果的可重复性,很难构建覆盖多分析任务、多组学模态的稳健多步分析流程。近年来大语言模型的发展为自然语言驱动的组学分析提供了可能,但无约束的代码生成始终存在代码幻觉、方法错选等问题,实际可用性很低,因此亟需一个将统一生态与受限执行层结合的全新框架解决这些痛点。
🔬 技术创新
- 统一AnnData中心生态
:OmicVerse将上游处理、预处理、单细胞、空间、bulk转录组等不同类型的超过100种分析方法,整合为以AnnData为核心的共享接口,解决了不同工具对象规范不统一、接口不兼容的问题,同时支持CUDA、Apple Metal/MPS等不同加速环境,还将很多原本仅在R中存在的方法重新用Python实现,降低了Python环境用户的使用门槛。
- 注册表约束的运行层
:J.A.R.V.I.S.运行层将超过200个函数和类注册到中心化工具注册表中,在执行前即可检查可调用操作、参数schema和预期输出,将大语言模型的行为约束在可检查的分析动作空间内,从根源上解决了AI分析常见的代码幻觉和方法错选问题。
- 状态感知可恢复运行时
:OmicClaw维护了链接用户需求和当前分析状态的执行上下文,支持多轮交互迭代分析,还具备前提验证、错误检测和多阶段错误恢复能力,将自然语言需求转化为可追溯、可中断、可恢复的流程执行。
📊 实验结果
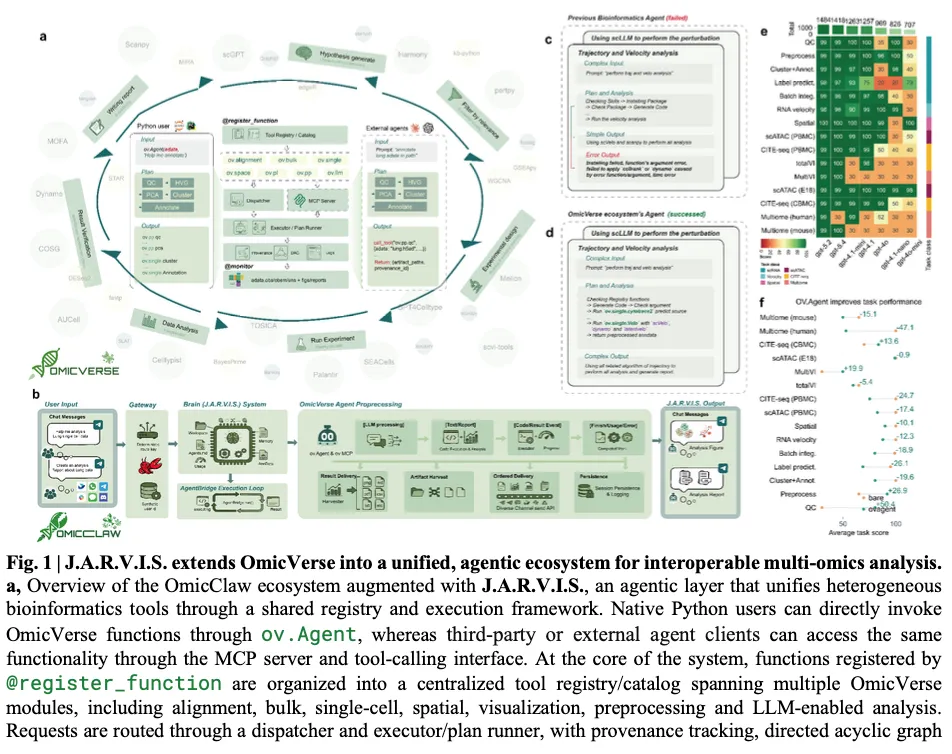
Figure 1:OmicClaw的整体设计框架与基准测试优势,展示了注册表约束设计解决多步分析失败问题的核心逻辑
Figure 2展示了OmicVerse生态的整体模块结构与接口统一性。OmicVerse将多组学分析按流程阶段拆分为多个互操作的分析模块,包括ov.alignment模块负责将测序读数转换为不同测序流程的计数矩阵,ov.preprocess模块负责多组学数据的质量控制与标准化预处理,ov.cluster模块负责降维聚类分析,ov.annotate模块负责细胞类型注释,ov.trajectory模块负责轨迹与RNA速度分析,ov.spatial模块负责空间转录组分析,ov.cellcommunication模块负责细胞通讯分析等。所有模块都统一使用AnnData对象作为输入输出,不同模块之间的结果可以无缝对接,不需要用户手动转换对象格式,所有方法都遵循统一的调用规范,大幅降低了用户的学习成本。图中也展示了OmicVerse支持的不同组学模态,从bulk转录组到单细胞多组学再到空间转录组都覆盖全面,满足绝大多数常见多组学分析需求。
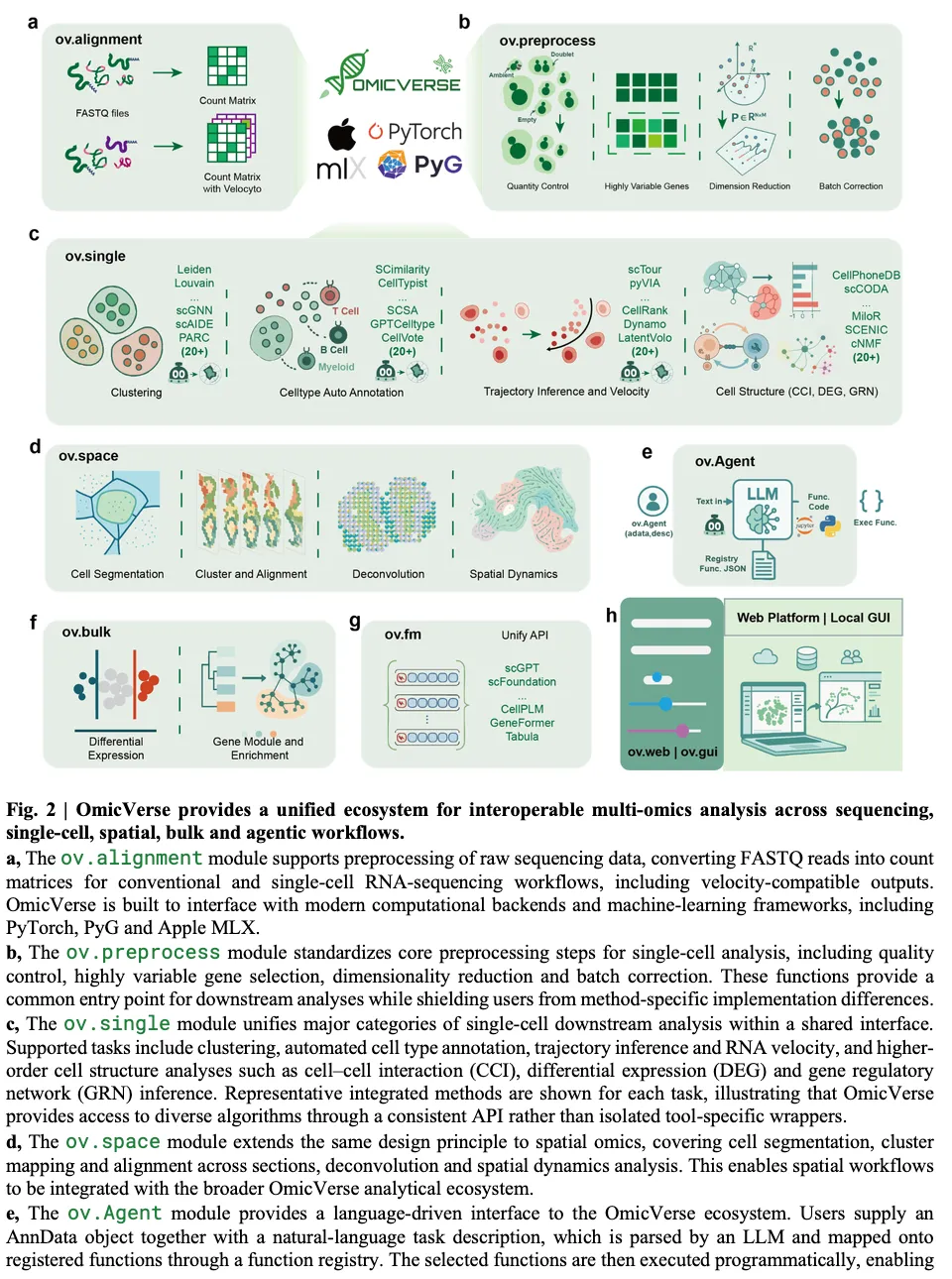
Figure 2:OmicVerse生态的模块结构展示,所有模块统一AnnData接口,覆盖全流程多组学分析需求
💡 应用前景和未来展望
未来OmicClaw可以进一步扩展支持更多组学模态,比如空间蛋白质组、代谢组等,同时可以整合更多领域特异性的高级分析方法,比如疾病生物标志物筛选、药物靶点预测等。基于自然语言交互的特性,后续也可以开发面向临床医生的多组学数据解读功能,让没有生信基础的临床研究者也能自己分析多组学数据,推动多组学技术的临床转化。对于生信工具开发者来说,OmicClaw的统一注册表框架也提供了工具分发的新渠道,降低了新方法的推广成本。
🔍 生信视角解读
当前很多AI生信工具都追求端到端的大语言模型生成,完全依赖LLM的知识和代码能力,但实际上LLM的代码幻觉在生信领域尤其严重,不同包的API一直在更新,不同工具的对象规范不一样,LLM很难实时掌握所有信息,生成的代码大多跑不通,用户体验很差。而OmicClaw的设计思路非常务实,它先把所有常用的多组学方法统一整理到AnnData为中心的生态里,解决了工具碎片化的问题,再通过注册表把LLM的动作约束在可验证的范围内,从根源上减少了错误,这个设计思路其实比单纯堆大模型能力更适合生信领域的实际需求。
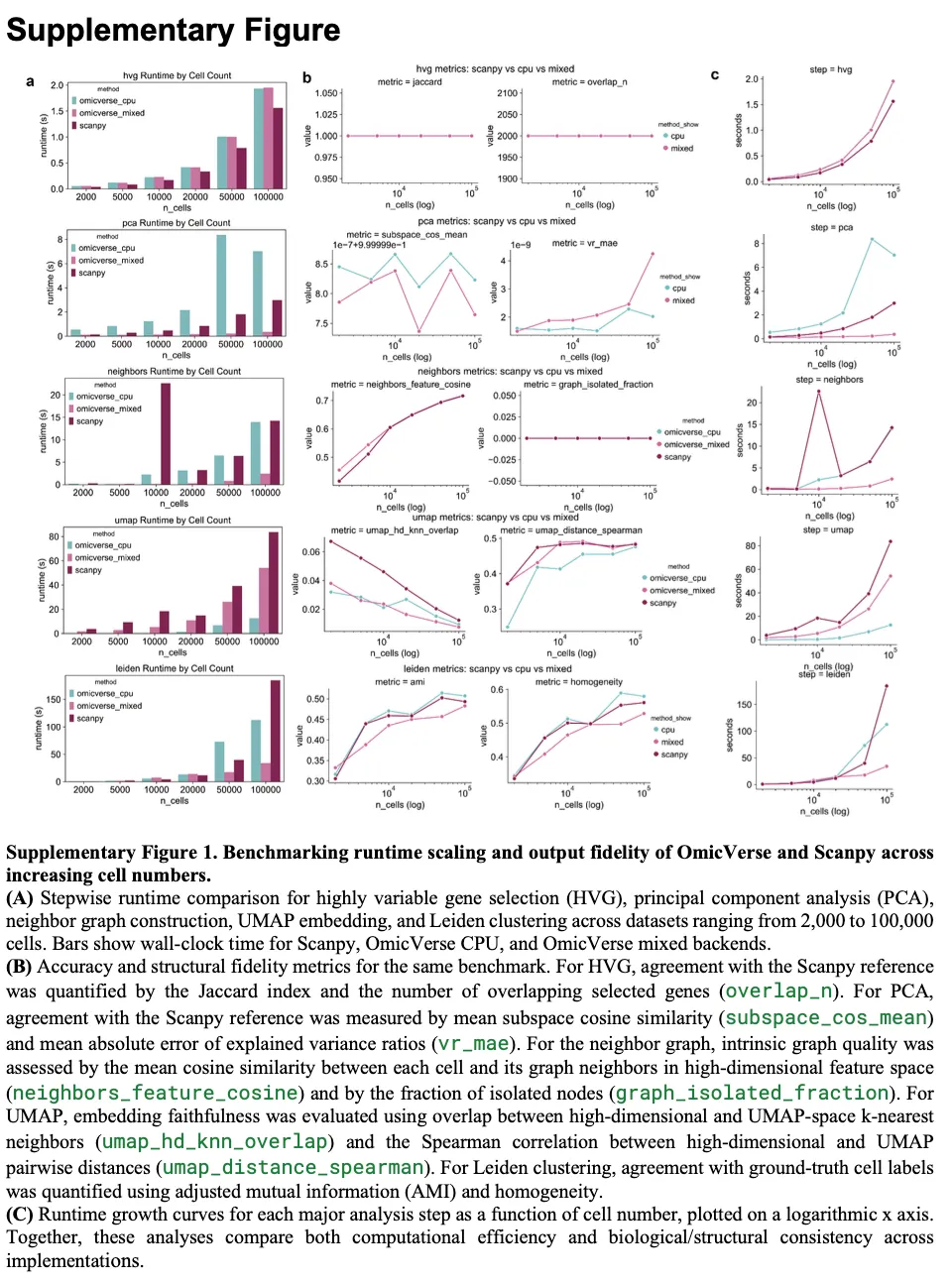
当然这个工作也存在一定可以改进的地方:目前注册的200多个函数虽然覆盖了常规分析需求,但很多高级的定制化分析方法还没有纳入,对于特殊的分析场景可能还需要用户自己扩展;另外,当前的错误恢复主要针对常见的前置缺失问题,对于数据本身的错误还没办法识别,后续可以增加数据质量层面的验证。对于我们自己的生信研究来说,这个工作的启发很大:如果我们要做工具开发,不要为了追热点而做纯LLM的工作,反而可以从生态整合、工程优化的角度出发,解决现有工具的真痛点,这样的工作反而更有实际价值,更容易被领域接受。另外,对于做AI辅助生信分析的研究来说,这个工作证明了“约束+生态”的思路比无约束生成更靠谱,后续我们开发相关工具的时候,可以借鉴这种设计思路,提升工具的实际可用性。
你会用OmicClaw分析自己的多组学数据吗?你做分析时遇到最头疼的依赖冲突问题是什么?欢迎在评论区留言讨论!
📌 Figure补充
👇 关注「公众号」,每日获取前沿生信研究解读
📚 文献引用:OmicClaw: executable and reproducible natural-language multi-omics analysis over the unified OmicVerse ecosystem, 2026.