 夜雨聆风
夜雨聆风





AI编程助手Skill技能系统深度拆解-Claude Code和OpenCode的技能到底怎么玩
AI 编程助手 Skill 技能系统深度拆解:Claude Code 和 OpenCode 的技能到底怎么玩?
上篇文章《AI 编程助手约束文件全解析:CLAUDE.md 和 AGENTS.md 到底怎么配?》发出来之后,后台好几个人问了同一个问题:「你提到的 Skill 技能系统,到底是什么?怎么用?和约束文件是什么关系?」
说实话这个问题我当时故意没展开——因为技能系统的水比约束文件深多了。约束文件解决的是「告诉 AI 你的项目规矩」,而技能系统解决的是「让 AI 学会新本事」。一个是员工手册,一个是技能培训。
今天就把这事彻底说清楚。Claude Code 和 OpenCode 的 Skill 系统,从设计理念到目录结构到加载机制,全拆一遍。
先理解一个问题:约束文件够用了,为什么还要技能?
上篇文章说过,CLAUDE.md / AGENTS.md 是给 AI 的「员工手册」——项目用什么技术栈、编码规范是什么、哪些红线不能碰。
但你有没有遇到过这种情况:
-
你想让 AI 帮你生成一张信息图,它不知道该调哪个 API、用什么参数 -
你想让 AI 把代码部署到测试环境,它不知道你的部署流程是 3 步还是 5 步 -
你想让 AI 分析一个 CSV 文件,它每次都要从头写一遍 pandas 代码,而且每次写的还不太一样
这些事靠约束文件是搞不定的。约束文件告诉 AI「怎么做是对的」,但不教它「怎么做一件具体的事」。
技能系统就是来补这个缺口的——把一整套可复用的工作流打包成一个「技能包」,AI 需要的时候加载进来,按步骤执行。
打个比方:约束文件是公司的《员工守则》,技能是《岗位操作手册》。守则告诉你「不能迟到」「代码要写注释」,操作手册教你「怎么一步步把容器部署到 K8s」。

Claude Code 的 Skill 系统
先说 Claude Code 的方案。Anthropic 在这块迭代得很快,最新版本已经把之前的 Custom Commands(自定义命令)和 Skills(技能)合并成了统一的技能体系。
核心概念:SKILL.md
每个技能就是一个文件夹,里面必须有一个 SKILL.md 文件,这是技能的入口。
SKILL.md 由两部分组成——YAML 头部元数据 + Markdown 正文指令:
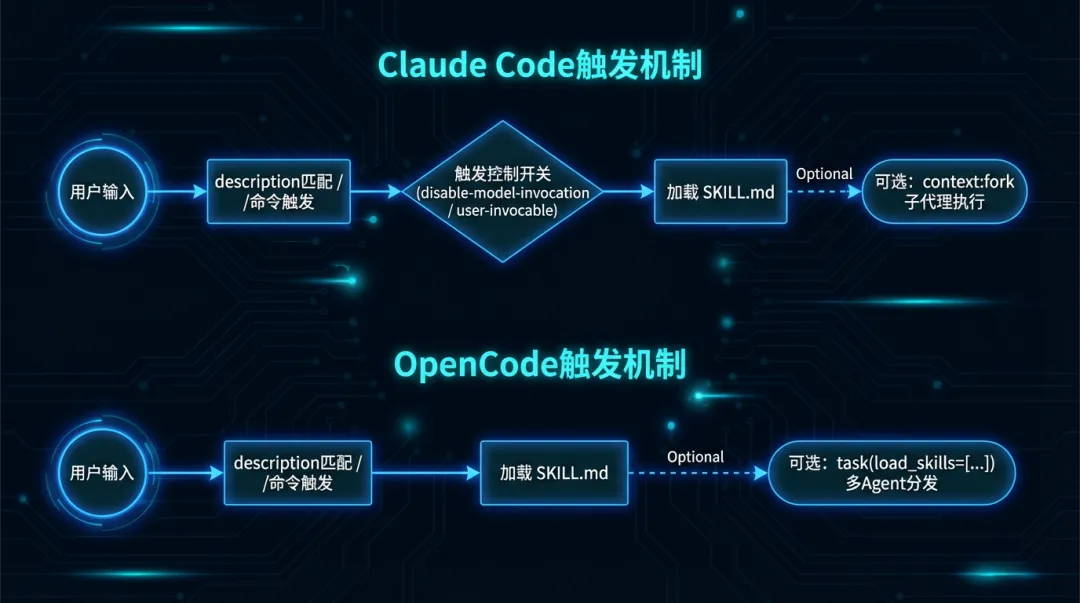
头部的 description 极其关键——Claude 根据这个描述来决定「要不要自动加载这个技能」。你问它「这段代码怎么工作的?」,它看到 description 里写了「当用户问怎么工作时触发」,就会自动把这个技能加载进来。
技能放哪?三个位置,各管各的
|
|
|
|
|
|---|---|---|---|
|
|
~/.claude/skills/<技能名>/SKILL.md |
|
|
|
|
.claude/skills/<技能名>/SKILL.md |
|
|
|
|
<插件>/skills/<技能名>/SKILL.md |
|
|
优先级:企业级 > 个人级 > 项目级。同名技能按优先级覆盖,插件级技能有独立命名空间(/插件名:技能名),不会冲突。
还有个实用特性——子目录自动发现。如果你在 packages/frontend/ 下工作,Claude Code 会自动去找 packages/frontend/.claude/skills/ 里的技能。Monorepo 的福音。
加载机制:三级渐进式
这是 Claude Code 技能系统最精巧的设计——不是所有技能内容都一次性塞进上下文。
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
启动时只把所有技能的名称和描述加载进去(占上下文窗口 2%,约 16000 字符),让 Claude 知道「我有哪些技能可用」。只有当某个技能被触发(用户手动 /技能名 或 Claude 根据对话自动判断),才把完整的 SKILL.md 内容加载进来。
脚本和参考文档?Claude 自己判断需不需要读。你在 SKILL.md 里写上「表单填写的详细指南见 forms.md」,Claude 碰到表单任务时自己去读,不碰就不读。
这个设计的好处是省 token。 你可以装 50 个技能,但日常对话中可能只触发 2-3 个,大部分技能只贡献了一行描述文字的开销。
谁来触发?可以控制
技能触发有两种方式:
- 用户手动调用:输入
/技能名
,就像用斜杠命令 - Claude 自动触发:Claude 根据对话内容匹配 description,觉得相关就自动加载
但有些技能你不想让 Claude 自作主张——比如部署到生产环境的技能。Claude 觉得「代码看着差不多了」就自动部署?想想就刺激。
两个控制开关:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
disable-model-invocation: true |
|
|
|
user-invocable: false |
|
|
|
参数传递:$ARGUMENTS
技能支持接收参数,用 $ARGUMENTS 占位符:
用户输入 /fix-issue 123,Claude 收到的就是「修复 GitHub issue 123」。还支持按位置取参数:$ARGUMENTS[0]、$ARGUMENTS[1] 或简写 $0、$1。
动态注入:Shell 命令预处理
这个功能有点意思—— ` !command` 语法可以在技能内容发送给 Claude 之前,先执行一段 Shell 命令,把结果注入进去:
技能被触发时,三个 gh 命令先执行,输出替换掉原始占位符,Claude 收到的是包含真实 PR 数据的完整提示词。这是预处理,不是 Claude 在执行。
子代理执行:context: fork
加上 context: fork,技能会在一个独立的子代理里运行,和主会话隔离:
agent 字段指定用哪种子代理执行(Explore、Plan 或自定义的),执行完把结果汇总返回给主会话。适合那种需要大量读取文件但不应该污染主对话上下文的任务。
内置技能:开箱即用
Claude Code 自带了几个官方技能:
|
|
|
|---|---|
/simplify |
|
/batch |
|
/debug |
|
/loop |
|
/claude-api |
|
/batch 比较值得一提——它会把一个大任务拆成 5-30 个独立子任务,每个子任务在独立的 git worktree 里并行执行,各自跑测试、各自提 PR。适合「把项目从 React 迁移到 Vue」这种大规模改造。
和 Custom Commands 的关系
如果你之前用过 Claude Code 的 .claude/commands/ 目录,不用急着迁移——旧的命令文件继续生效。技能系统是 commands 的超集,.claude/commands/deploy.md 和 .claude/skills/deploy/SKILL.md 效果一样。同名情况下技能优先。
官方建议新的都用 skills,因为 skills 支持附带脚本和参考文件,commands 只是单个 Markdown 文件。
OpenCode 的 Skill 系统
OpenCode 的技能系统和 Claude Code 思路类似,但实现上走了不同的路。
核心概念:也是 SKILL.md
每个技能也是一个文件夹 + SKILL.md 入口,结构几乎一样:
SKILL.md 的格式也是 YAML 头部 + Markdown 正文:
到这里为止,看着和 Claude Code 很像。但接下来就不一样了。
技能放哪?只有一个默认位置
OpenCode 的技能只有一个自动发现路径:
放在这个目录下的技能,OpenCode 启动时自动扫描、自动注入上下文,不需要任何额外注册。
跟 Claude Code 的区别在这:
|
|
|
|
|---|---|---|
|
|
~/.claude/skills/ |
~/.config/opencode/skills/ |
|
|
.claude/skills/
|
|
|
|
|
|
|
|
|
|
OpenCode 没有项目级技能目录。我之前专门做了个实验——在项目根目录下建了 skills/test-skill/SKILL.md,重启之后 AI 完全识别不到。只有全局目录 ~/.config/opencode/skills/ 才是自动发现路径。
这意味着 OpenCode 的所有技能都是「全局共享」的,没法给某个项目单独配一套技能。
变通方案:用 AGENTS.md 实现「项目级技能」
虽然 OpenCode 官方不支持项目级 skills 目录,但有个实用的变通方案——在项目的 AGENTS.md 里手动注册技能清单,指定任意路径的技能。
比如你的项目有些专属脚本和工作流,不想污染全局 skills 目录,可以这么搞:
第一步,在项目里建一个 skills 目录:
第二步,在项目的 AGENTS.md 里注册这些技能:
原理很简单:AGENTS.md 本身就是 AI 的「指令文件」,你在里面写清楚「这个项目有这些技能,文件在这个路径,什么时候用」,AI 就会按描述去读取对应的 SKILL.md 并执行。
本质上是用 AGENTS.md 当了一个「手动索引」,把技能发现的工作从系统自动扫描降级为约束文件声明。虽然没有自动发现那么优雅,但胜在灵活——你可以把技能放在任何路径,甚至引用项目外的共享目录。
这个方案还有个隐藏好处:项目级技能跟着 Git 走,团队成员 clone 下来就能用,不需要每个人都往全局 skills 目录里装一遍。
加载机制:也是渐进式,但方式不同
OpenCode 的技能加载分两步:
- 启动时:扫描
~/.config/opencode/skills/
下所有技能,读取每个 SKILL.md 的 name和description,注入到系统提示词 - 触发时:用户调用
/技能名
或 AI 通过 skill()函数主动加载,此时才读取完整的 SKILL.md 内容
和 Claude Code 的三级渐进式类似。但 OpenCode 有个额外的机制——内置技能。
除了用户安装的技能,OpenCode 还内置了 4 个技能:
|
|
|
|---|---|
playwright |
|
frontend-ui-ux |
|
git-master |
|
dev-browser |
|
最终可用的技能列表 = 内置技能 + 全局目录自动扫描。是并集关系。
之前的坑:手动注册
这里得说一段历史。早期版本的 OpenCode,技能安装到 ~/.config/opencode/skills/ 之后,还需要在 AGENTS.md 里手动注册,写上触发词和调用方式。不注册的技能 AI 看不到,等于白装。
后来 OpenCode 升级了技能发现机制,从「手动声明」变成了「自动扫描+注入」。现在 AGENTS.md 里的技能清单变成了可选的补充说明——写上也不会冲突,但不写也能正常发现和使用。
别问我怎么知道这个坑的。
调用方式:斜杠命令 + 技能函数
OpenCode 的技能有两种调用方式:
1. 用户手动调用: 输入 /技能名,和 Claude Code 一样
2. AI 自动触发: OpenCode 给 AI 提供了一个 skill() 工具函数,AI 在对话过程中可以自己决定加载某个技能:
触发逻辑和 Claude Code 类似——根据 description 里的关键词匹配。你说「帮我生成一张图」,AI 看到 image-service 的描述里写了「图像处理」,就自动加载。
技能里的脚本
OpenCode 的技能大量使用了脚本机制。拿 image-service 技能来说,它不是靠 AI「自由发挥」来生成图片,而是调用预写好的 Python 脚本:
这个思路和 Claude Code 的 scripts/ 目录一样——把需要确定性执行的操作封装成脚本,AI 负责编排调用,不负责重写逻辑。每次执行结果一致,不会出现「今天生成的代码和昨天不一样」的玄学问题。
OpenCode 特有:Agent 分发 + 技能加载
OpenCode 有个 Claude Code 没有的特性——多 Agent 分发时携带技能。
OpenCode 支持把任务分发给不同的子代理执行,分发时可以指定「这个子代理需要加载哪些技能」:
子代理是无状态的——它不知道全局有哪些技能。你不通过 load_skills 传给它,它就是个「什么都不会」的白板。这个设计和 Claude Code 的 context: fork + agent 类似,但更显式——你必须明确告诉子代理该装什么技能。
正面对比:两套系统的核心差异
目录结构对比
|
|
|
|
|---|---|---|
|
|
SKILL.md
|
SKILL.md
|
|
|
~/.claude/skills/ |
~/.config/opencode/skills/ |
|
|
.claude/skills/
|
|
|
|
|
|
|
|
|
|
|
|
|
|
技能配置对比
|
|
|
|
|---|---|---|
|
|
disable-model-invocation
user-invocable |
|
|
|
$ARGUMENTS
$0~$N |
|
|
|
allowed-tools
|
|
|
|
context: fork
agent |
task()
load_skills |
|
|
!command |
|
|
|
|
|
|
|
model
|
category 间接指定 |
加载机制对比
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
适用场景对比
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
load_skills
|
|
|
|
|
|
|
|
disable-model-invocation
|
实战:从零创建一个技能
光说不练假把式。下面用一个「部署到测试环境」的技能,分别演示两边怎么创建。
Claude Code 版本
写 .claude/skills/deploy-test/SKILL.md:
使用:/deploy-test v1.2.3
OpenCode 版本
写 ~/.config/opencode/skills/deploy-test/SKILL.md:
使用:/deploy-test 或直接说「部署到测试环境」
区别在哪?
|
|
|
|
|---|---|---|
|
|
|
|
|
|
disable-model-invocation
|
|
|
|
allowed-tools
|
|
|
|
$ARGUMENTS
|
|
写好 SKILL.md 的几条经验
不管用哪个工具,SKILL.md 的质量直接决定技能好不好用。踩了一些坑之后,总结几条:
1. description 是灵魂,写不好等于白写
AI 根据 description 判断要不要加载你的技能。写得太笼统——每次对话都乱触发;写得太窄——该用的时候不触发。
2. SKILL.md 控制在 500 行以内
每次技能触发,整个 SKILL.md 都会被塞进上下文。太长了不仅费 token,AI 的注意力也会被稀释。
详细的 API 文档、使用示例、配置说明——拆到 references/ 目录下的独立文件里,在 SKILL.md 中用链接引用:
Claude 需要的时候自己去读,不需要的时候不占空间。
3. 能用脚本的别让 AI 自由发挥
AI 每次「自由发挥」写出来的代码可能不一样。涉及到文件操作、API 调用、部署流程这种需要确定性的事,封装成脚本:
脚本的好处:确定性高、可以独立测试、token 消耗低(执行但不需要读进上下文)。
4. 同一技能里区分「参考内容」和「任务内容」
有些技能是给 AI 补充背景知识的(coding conventions、API 规范),有些是教 AI 执行具体任务的(部署、生成报告)。别混在一起:
- 参考型技能:主要是约束和规范,AI 在执行其他任务时参考。适合自动触发。
- 任务型技能:有明确的执行步骤,用户主动调用。适合
disable-model-invocation: true
。
总结
Skill 技能系统是约束文件的自然延伸——约束文件管「什么是对的」,技能管「怎么把事做对」。
两边的设计哲学差异很明显:
- Claude Code:走的是精细化路线。项目级/个人级/企业级分层、触发控制开关、工具白名单、Hooks 生命周期、动态注入——功能全但学习曲线陡
- OpenCode:走的是简洁路线。全局目录自动扫描、自动注入、多 Agent 分发时显式装载——上手快但缺乏精细控制
选哪个?老话——看场景:
-
团队协作、需要把技能提交到 Git → Claude Code -
个人使用、快速搭建工作流 → OpenCode 更省心 -
两个都用 → 技能的核心逻辑(脚本、参考文档)抽成独立文件,SKILL.md 各写一份包装
不过有一点是共通的:技能的价值不在于数量,在于每个技能的 description 写得好不好、SKILL.md 的指令清不清晰、脚本够不够稳定。 装了 50 个技能但触发逻辑乱七八糟,还不如 5 个精心打磨的技能好使。
工具是死的,手艺是活的。
*接上篇约束文件全解析,这篇把技能系统也讲完了。下回有人问「Skill 是什么」,甩这篇文章就行。*
#AI编程 #ClaudeCode #OpenCode #Skill技能 #AI编程助手 #编程工具 #效率工具 #AIAgent #开发者工具 #技能系统
觉得有用?扫码关注「昕悦技术栈」持续输出实战干货

长按识别二维码,关注我!