 夜雨聆风
夜雨聆风





不用后端转PDF!jit-viewer让浏览器直接"读懂"Office,3行代码搞定文件预览
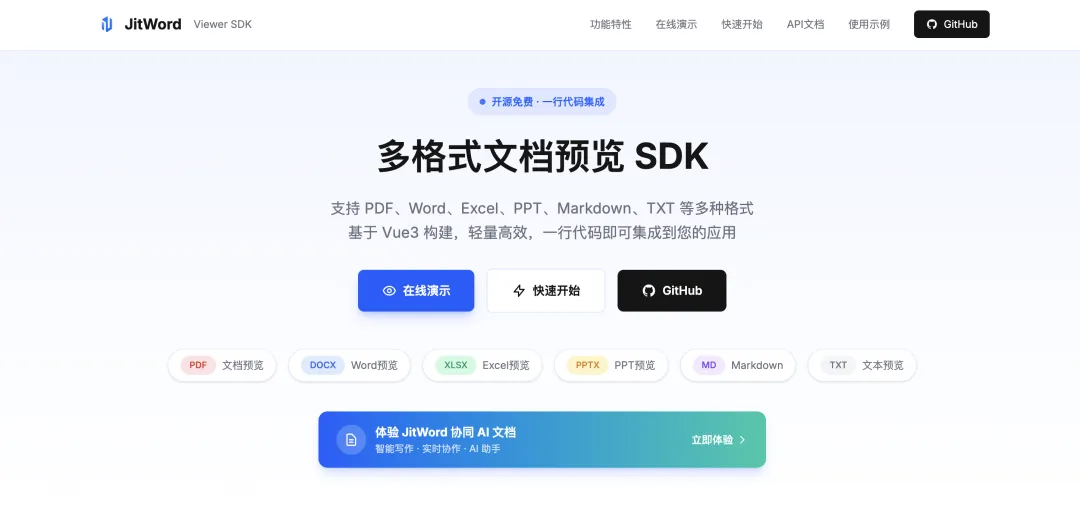
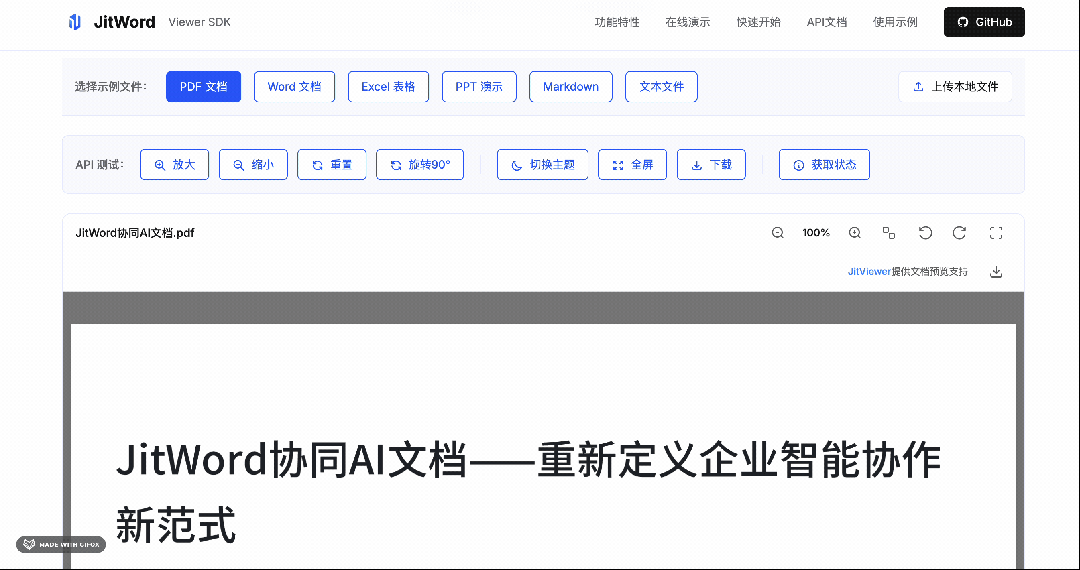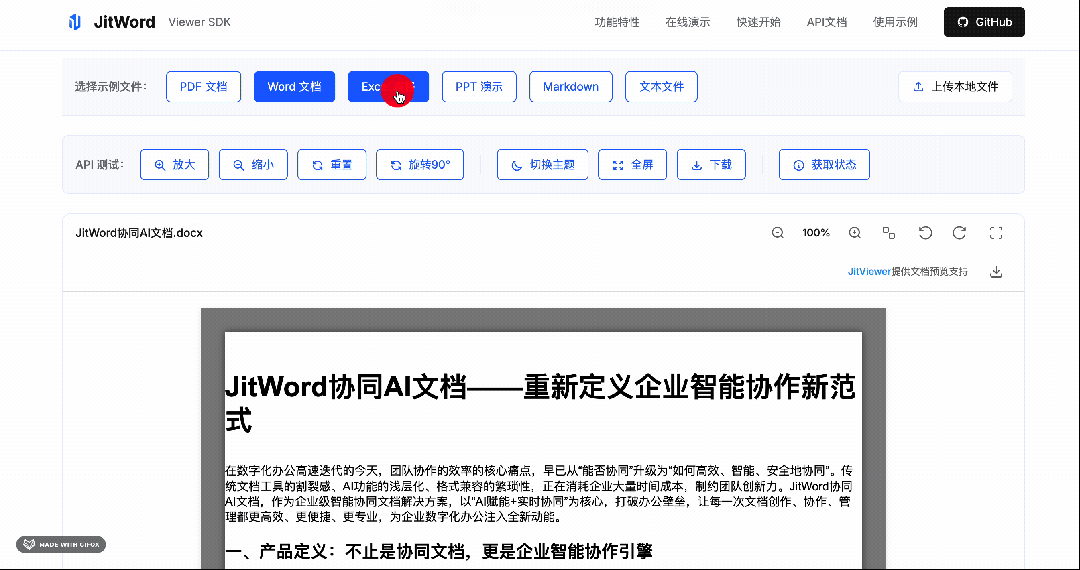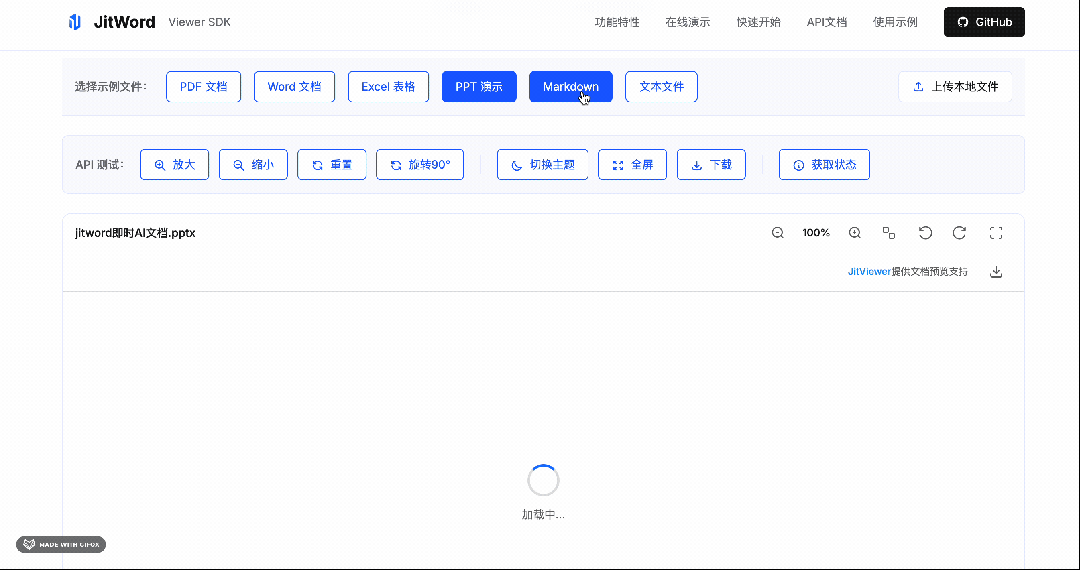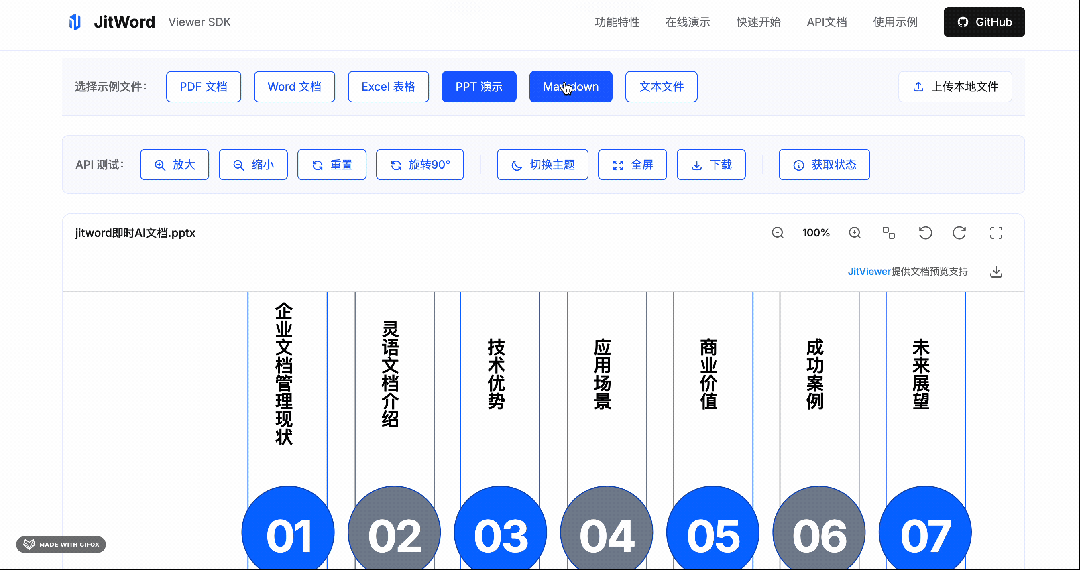
而且,我们对SDK的设计做到了极致,只需要3行代码,就能轻松集成到任何系统。
为什么我们需要它?
传统方案的三大痛点
我们做企业级应用时,文件预览往往是”看起来简单,做起来很要命“, 一般有如下几个方案:
1. 后端转换方案(如LibreOffice + PDF.js)
-
服务器压力大:并发一上来,CPU直接飙满
-
格式失真:复杂排版、公式、表格经常”面目全非”
-
延迟感人:大文件等个5-10秒是常态
2. 第三方云服务(如某钉、某微文档接口)
-
数据外泄风险:敏感文件传到第三方服务器
-
定制受限:UI风格、交互逻辑无法自主控制
-
成本不可控:按调用量收费,业务量上来就是无底洞
3. 纯前端方案(如mammoth.js + SheetJS)
-
各自为战:Word一个库、Excel一个库,API风格不统一
-
兼容性差:PPT预览基本空白,复杂格式支持弱
-
集成成本高:每个库都要单独学习、配置、踩坑
jit-viewer 的实现思路
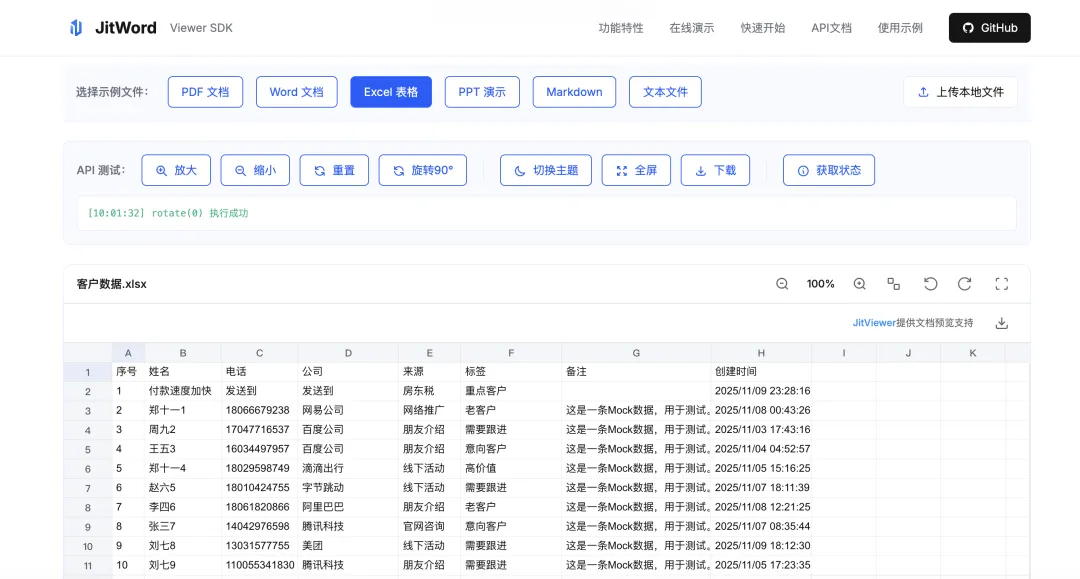
“浏览器原生能力 + 统一抽象层”
我们不依赖后端转换,而是直接在浏览器端解析 Office Open XML 格式(.docx/.xlsx/.pptx 的底层结构),最后通过 jit-viewer 封装的渲染器渲染成可视化组件。PDF 则基于 Mozilla 的 PDF.js 做深度优化。
结果:
-
✅ 零后端依赖,纯前端部署
-
✅ 秒级渲染,大文件不卡顿
-
✅ 格式还原度 95%+(包括表格、图片、基础样式)
-
✅ 三行代码集成,API 统一
应用场景

jit-viewer 可以应用在如下场景:
|
|
|
|
|---|---|---|
| 企业OA系统 |
|
|
| 在线教育 |
|
|
| SaaS文档管理 |
|
|
| 移动端H5 |
|
|
| 低代码平台 |
|
|
优点客观分析
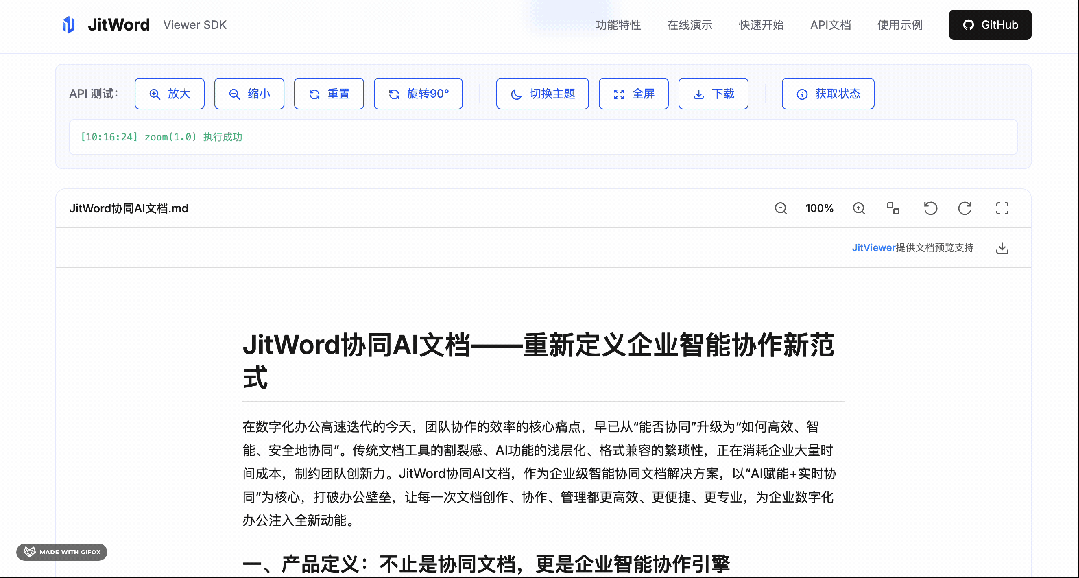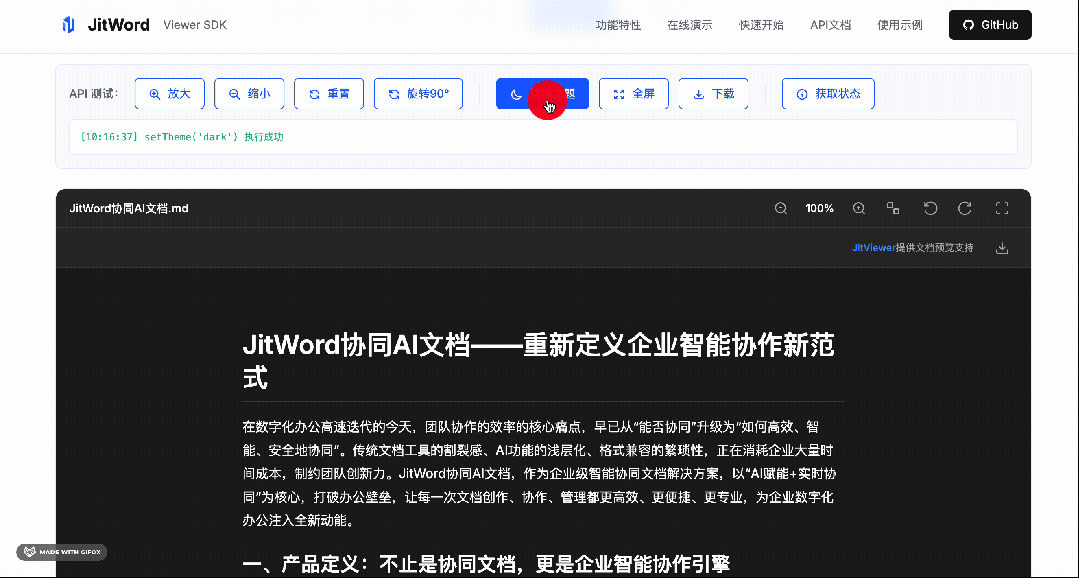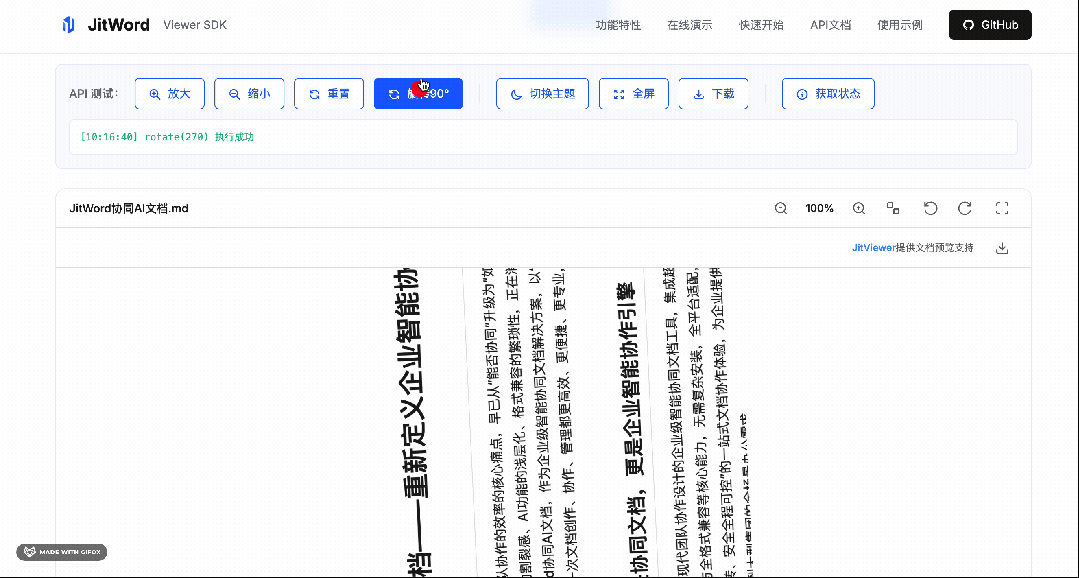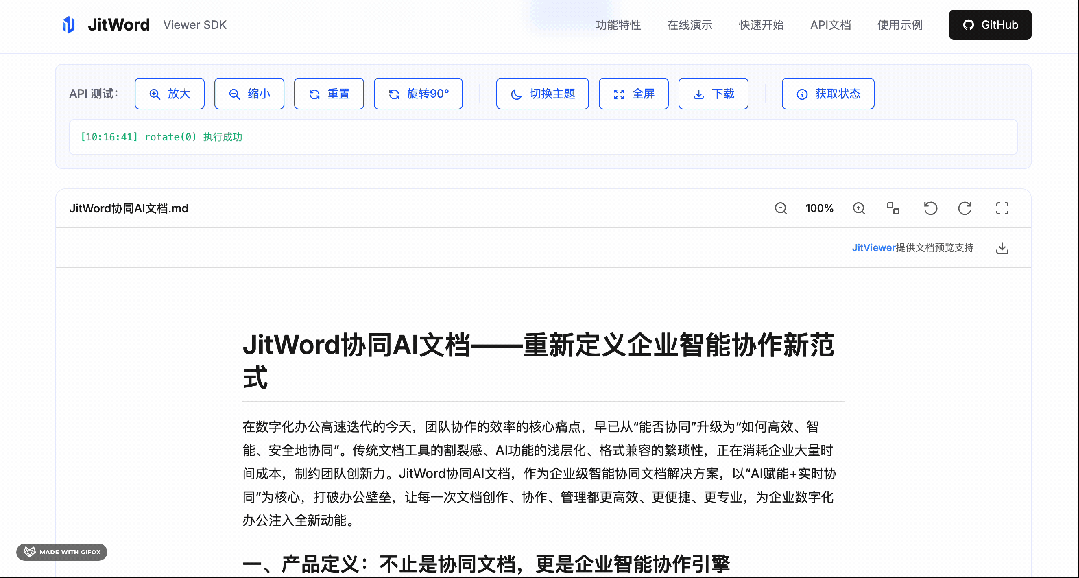
基于我们研究的一些真实场景和痛点,这里我总结一下它的亮点:
-
真正的纯前端:无需配置任何后端服务,静态站点也能用
-
框架无绑定:一个SDK同时支持Vue/React/Angular,团队技术栈切换无成本
-
隐私安全:文件解析在浏览器本地完成,不上传服务器
-
性能优异:虚拟滚动 + Web Worker,大文件不卡主线程
-
扩展性强:插件化架构,可自定义渲染器、添加水印、集成审批流
下面聊聊大家比较关注的如何集成使用的问题。
从零集成jit-viewer
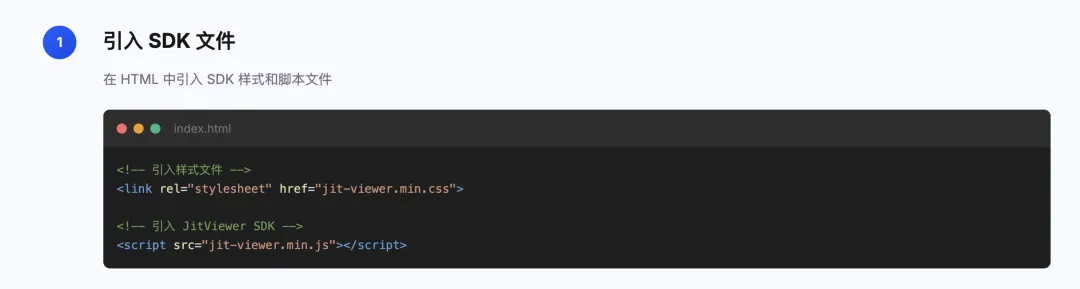
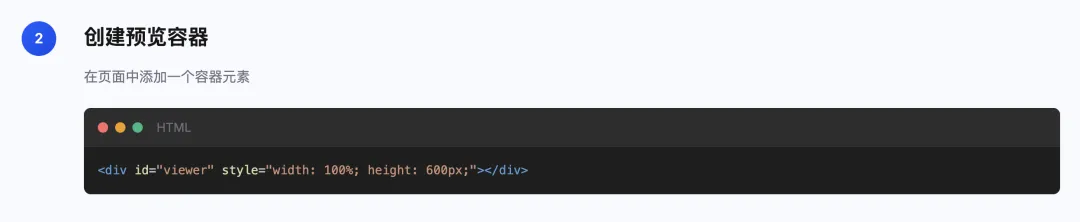
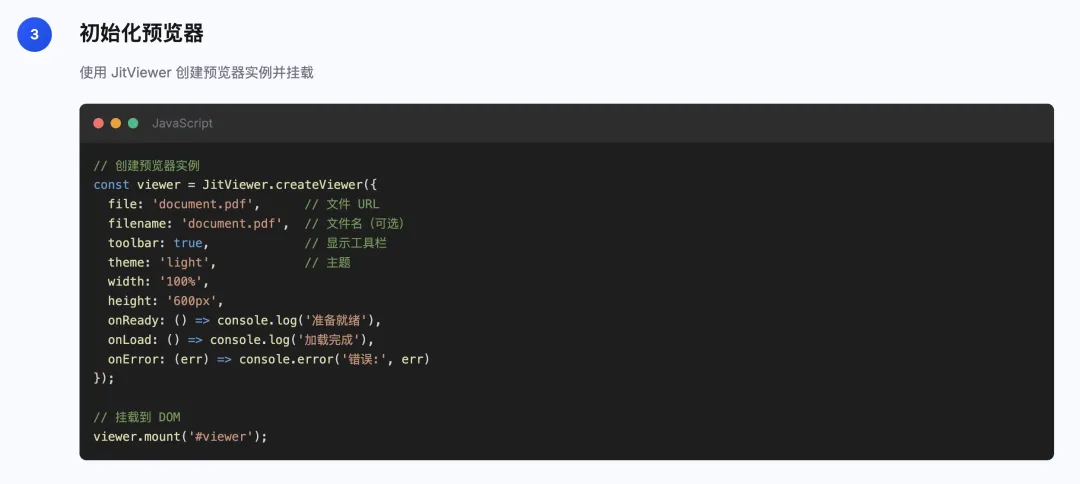
https://jitword.com/jit-viewer.html