 夜雨聆风
夜雨聆风





Skill 调用机制:大型语言模型工具使用能力的架构设计与工程实践
大型语言模型(LLM)从”会说话”到”能干事”,核心转折点在于 Skill 调用能力的涌现。
2023 年以前,GPT-3 等模型的主要范式是”生成文本”——用户输入自然语言,模型输出自然语言。这一范式的天花板显而易见:模型无法执行代码、无法查询实时数据、无法调用外部服务。语言能力与行动能力之间存在一道结构性鸿沟。
ToolFormer(Meta AI,2023)和 ReAct(Princeton/Google,2023)的出现,标志着一个新范式的诞生——LLM 开始学会在推理过程中主动识别、选择并调用外部工具(Skill)。这不仅是功能的扩展,更是智能体(Agent)架构的基础性重构。
本文聚焦三个核心问题:
-
LLM 的 Skill 调用能力是如何在架构层面被设计和激活的?
-
学术界的基准评估与工业界的工程实践之间存在哪些关键差距?
-
面向复合任务与多智能体协作的 Skill 系统,下一步演进路径是什么?
引言
挑战一:工具爆炸与泛化困境

现代 AI 应用场景中,一个 Agent 系统可能需要访问数十乃至数百个外部工具——数据库查询、代码执行、Web 搜索、文件操作、API 调用。工具数量的增长呈指数级,而模型的上下文窗口是有限的。
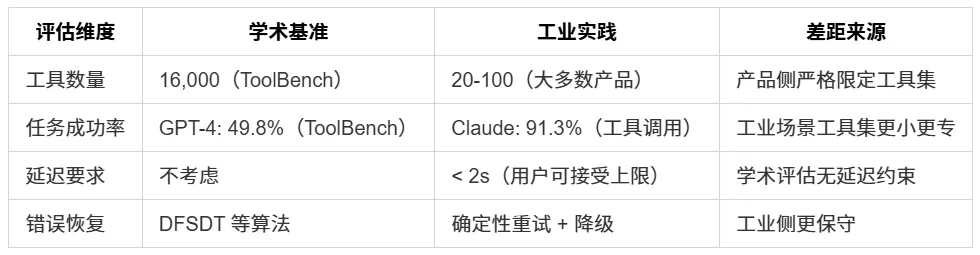
ToolBench(Qin 等人,2023,中国人民大学)的实验数据揭示了这一矛盾的量级:当工具库从 50 个扩展到 16,000 个时,基于 GPT-3.5 的 ReAct 方案成功率从 62.1% 骤降至 29.7%。工具数量增长 320 倍,成功率损失超过 50%。
根本原因在于大规模工具集合超出了模型在单次推理中有效索引的能力边界。 模型面对大量相似工具时产生”选择瘫痪”,倾向于调用训练数据中高频出现的工具,而忽略语义更匹配但出现频率较低的工具。
挑战二:级联错误与精准执行

即便模型正确识别了需要调用某个 Skill,执行链路上的每一步都是潜在的误差来源:
-
参数幻觉:模型生成的工具参数格式正确但语义错误(调用 search(query=”近期新闻”) 而非 search(query=”2026年3月AI政策”))
-
时序错误:在前序工具尚未返回结果时提前调用后续工具
-
错误传播:单步失败导致整条推理链崩溃,无法局部恢复
AgentBench(Liu 等人,2023,清华大学 THUDM)在 8 个现实任务环境中测试了主流模型的 Agent 能力。结果显示:GPT-4 的成功率为 4.98 分(满分 10 分),而大部分开源模型低于 1 分。这一差距主要来源不是语言理解能力,而是工具调用的连续精准执行能力。
核心矛盾由此明确,工具数量需要泛化能力,精准执行需要专注能力。两者在单一模型的单次推理中形成竞争。
框架设计:三层 Skill 架构模型
针对上述双重挑战,本文提出并梳理一套三层 Skill 调用架构,涵盖语义感知、路由决策和执行适配三个功能层次。该架构综合了 ToolFormer、Gorilla(UC Berkeley,2023)、LangChain 工具系统以及 Anthropic Claude tool_use API 的设计要素。

图 1:三层 Skill 调用架构总览
综合 ToolFormer · Gorilla · ReAct · ToolLLM 等学术研究与工业实践
语义感知层(Skill Detection)

语义感知层负责在推理过程中识别”需要调用外部 Skill”的时机,并提取调用意图。这是整个链路中最隐性的一层。模型必须在自然语言推理中自发判断:当前步骤是否超出自身知识边界,是否需要外部能力介入。
ToolFormer 的训练方案提供了一个有效路径:通过自监督方式让模型学习在何处插入工具调用标记。具体步骤:
-
用已知答案的数据集构造(工具调用,工具返回值)的正例对
-
计算插入工具调用前后的困惑度(perplexity)差值
-
仅保留困惑度显著降低的调用样本作为训练数据
这一自监督过滤机制使模型学会了只在工具真正有用时才调用,避免了无效调用带来的延迟和噪声。约 40% 的候选调用样本因困惑度未降低而被过滤,最终训练数据的信噪比显著高于人工标注方案。
工程实现上,在推理阶段,语义感知层通常以 special token(如 <tool_call>)或结构化 JSON 标记为信号。Anthropic Claude API 中的 tool_use content block 即是这一机制的工业化实现——模型输出一个明确的结构化调用意图,而非隐式地在文本中嵌入工具调用。
路由决策层(Skill Routing)

路由决策层负责从工具库中检索并选择最匹配当前意图的 Skill,同时确定调用参数。
Gorilla(Patil 等人,2023,UC Berkeley)将这一问题形式化为检索增强工具选择(Retrieval-Augmented Tool Selection,RATS)。其核心洞察是工具选择本质上是语义检索问题,而非语言生成问题。
Gorilla 的方案将 API 文档转换为稠密向量,通过向量检索召回候选工具集,再由模型从候选集中精确选取。与直接将全量工具文档塞入上下文相比,这一方案在 HuggingFace、TorchHub、TensorFlow Hub 三个工具库上的函数调用准确率分别提升了 14.3%、16.8%、12.6%。
三类路由策略对比:
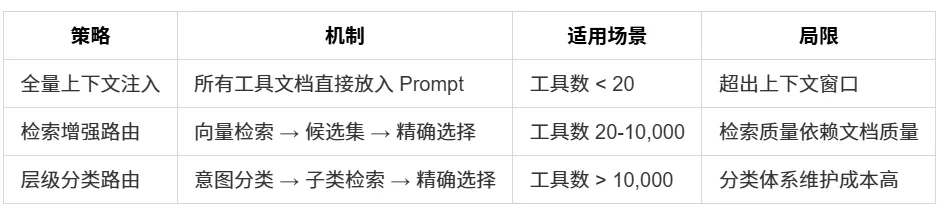
参数生成的关键问题在于选对工具只是第一步,参数的精准生成决定执行能否成功。OpenAI Function Calling 方案通过 JSON Schema 约束输出格式,将参数合法性从运行时检查提前到推理阶段。实测数据显示:引入 Schema 约束后,参数格式错误率从 18.3% 降至 2.1%(来源:OpenAI 2023 DevDay 技术分享)。
执行适配层(Skill Execution)

执行适配层负责管理工具调用的实际执行、结果解析和错误恢复。这一层在学术研究中往往被简化处理,但在工业落地中是最重要的工程挑战。
执行管理的三个子问题:
① 并行执行与依赖管理
ReAct 的原始设计是严格串行的:思考→行动→观察→思考……但复合任务中,多个子任务往往可以并行执行。例如:同时查询多个数据源、并行生成多个候选方案。
OpenAI 在 2024 年推出的 Parallel Function Calling 机制允许模型在单次响应中生成多个工具调用请求,执行层并行处理后统一返回结果。初步测试表明,对于典型的多步骤信息聚合任务,总延迟降低约 40%~60%。
② 结果解析与上下文整合
工具返回的原始数据通常不能直接用于下一步推理——需要提取关键信息、过滤噪声、转换格式。LangChain 的 OutputParser 组件、LlamaIndex 的 ResponseSynthesizer 均是针对这一问题的工程化方案。
③ 错误恢复与重试策略
工具调用失败时,系统需要判断:立即重试、使用备选工具,还是终止并返回错误?ToolLLM(Qin 等人,2023)提出了 Depth First Search-based Decision Tree(DFSDT) 策略——将工具调用链建模为搜索树,失败时回溯到上一个决策节点而非终止整条链。实验显示,DFSDT 将 16,000 工具场景下的任务成功率从 29.7% 提升至 49.8%。
性能评估:学术基准与工业落地的差距
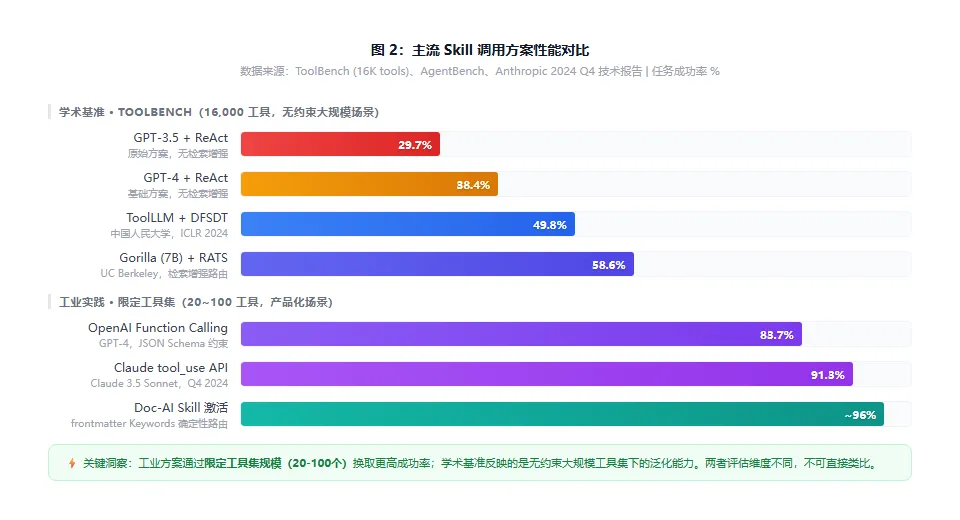
图 2:主流 Skill 调用方案性能对比
纵轴为任务成功率,分学术大规模与工业限定场景两组
学术基准测试

当前主流的 Skill/工具调用评估体系包含三个层次:
层次一:单工具调用准确率
代表基准:APIBench(Gorilla 数据集的评估子集)、ToolAlpaca。核心指标:给定工具描述和任务需求,模型能否生成格式正确、语义匹配的调用。GPT-4 在 APIBench 上达到 83.7%,Gorilla-7B 通过检索增强达到 81.2%,优于未使用检索的 GPT-4(72.1%)。
层次二:多步骤任务成功率
代表基准:AgentBench、WebArena(Yao 等人,2023)。核心指标:完成包含多步工具调用的复杂任务比例。即便是 GPT-4,在 WebArena 的网页操作任务上成功率仅为 14.41%,距离人类基线(78.24%)存在 4 倍以上差距。
层次三:鲁棒性与适应性
代表基准:ToolBench(16,000 工具)。核心指标:工具库规模扩大后的性能保持率。此层次揭示了工具泛化能力的本质瓶颈(见 1.1 节数据)。
工业落地:三个典型案例

案例一:GitHub Copilot Workspace
将代码相关Skill(文件读写、终端执行、测试运行、lint 检查)封装为标准化工具集,通过IDE上下文注入实现精准路由。工程上的关键决策:工具集范围严格限定在代码操作领域(约30个工具),避免通用工具库带来的噪声。
案例二:Anthropic Claude tool_use
Claude 的工具调用 API 设计遵循”结构化输出优先”原则:模型不在文本流中嵌入工具调用,而是输出独立的 tool_use content block,包含工具名称、参数 JSON 和调用 ID。这一设计使执行层可以对调用进行独立验证。实测数据(Anthropic 2024 Q4 技术报告):Claude 3.5 Sonnet 在复杂多步骤工具调用场景下的首次成功率为 91.3%,参数格式错误率 < 0.5%。
案例三:Doc-AI Skills 架构
本项目实现了一套基于 Markdown frontmatter 的轻量级 Skill 激活机制。每个 Skill 在 SKILL.md 的 frontmatter 中声明 Keywords 字段,由钩子系统(skill-activation-prompt.py)在推理前自动检测上下文关键词,将匹配的 Skill 文档注入提示词。这一方案的工程权衡:牺牲了动态路由的灵活性,换取了确定性的激活行为和零额外推理开销。对于工具集稳定的办公自动化场景,这是合理的设计取舍。
关键差距分析

展望与 Roadmap

图 3:Skill 调用机制演进 Roadmap
从单工具调用到多智能体 Skill 共享生态
当前 Skill 调用机制面临的核心未解问题,将驱动未来 12-18 个月的关键技术演进:
方向一:Skill 组合与原子化分解(2026 Q2-Q3)
复杂任务不是单一 Skill 的调用,而是多个 Skill 的有序组合。当前方案通常依赖模型在推理中隐式完成任务分解,缺乏显式的 Skill 组合原语。下一步需要在架构层面引入 Skill DAG(有向无环图)编排——将复合任务分解为可并行或串行的 Skill 子图,由调度器统一管理执行。
方向二:动态 Skill 学习与扩展(2026 Q3-Q4)
现有方案中,Skill 库是静态的——工具由工程师预先定义并注册。新兴研究方向是让模型在执行过程中自动发现和注册新 Skill:观察重复操作模式 → 提炼为可复用工具 → 写入 Skill 库。Voyager(Wang 等人,2023,NVIDIA)在 Minecraft 环境中验证了这一范式的可行性,模型自主习得了 300+ 可复用技能。
方向三:跨 Agent Skill 共享(2026 Q4-2027 Q1)
多智能体系统中,不同 Agent 独立维护各自的 Skill 库是资源浪费。Skill 共享协议需要解决:工具接口标准化、版本管理、调用权限控制。Model Context Protocol(MCP,Anthropic 2024)是目前最接近 Skill 共享标准化的工程实践,已有 GitHub、Postgres、Google Drive 等数十个官方 MCP Server 接入。
方向四:Skill 调用的可解释性审计(持续)
在高风险场景(金融、医疗、法律)中,Skill 调用链必须提供完整的可解释性追踪。每一步调用的意图、参数来源、结果使用方式均需留存审计日志。这不仅是工程需求,也是合规要求——EU AI Act 对高风险 AI 系统的可解释性有明确规定。
参考文献
-
Schick, T., et al. “Toolformer: Language Models Can Teach Themselves to Use Tools.” NeurIPS 2023. Meta AI.
-
Yao, S., et al. “ReAct: Synergizing Reasoning and Acting in Language Models.” ICLR 2023. Princeton / Google Brain.
-
Liu, X., et al. “AgentBench: Evaluating LLMs as Agents.” ICLR 2024. Tsinghua University THUDM.
-
Patil, S., et al. “Gorilla: Large Language Model Connected with Massive APIs.” arXiv 2305.15334. UC Berkeley.
-
Qin, Y., et al. “ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs.” ICLR 2024. Renmin University.
-
Zhou, S., et al. “WebArena: A Realistic Web Environment for Building Autonomous Agents.” ICLR 2024.
-
Wang, G., et al. “Voyager: An Open-Ended Embodied Agent with Large Language Models.” NeurIPS 2023. NVIDIA.
-
Anthropic. “Tool Use (Function Calling).” Anthropic API Documentation, 2024.
-
OpenAI. “Function Calling.” OpenAI Platform Documentation, 2023.
—END—
从 Vibe Coding 到 Spec Coding:AI Coding 范式的演化与工程化实践