 夜雨聆风
夜雨聆风





4B反杀9B前代!这个开源OCR模型把文档AI的「第一页」难题往前踹了一大步
所有做文档AI的人都懂这个痛:
你花大价钱搭了RAG pipeline,你精心调了agent的prompt,你选了最先进的embedding模型——但最后发现,整个系统在第一页就卡住了。
OCR那层把表格读裂了,把公式搞没了,把多栏版面彻底打乱。
文档AI不是败在「模型不够聪明」,而是常常先败在「第一页就没读对」。
2026年3月18日,Datalab创始人Vik Paruchuri在X上宣布开源Chandra OCR 2。

▲ Datalab创始人Vik Paruchuri宣布Chandra OCR 2开源,模型从9B降到4B,但benchmark反而冲到了SOTA。这条发布帖在短短几小时内获得近300次书签收藏。
这波发布最狠的,不是「又一个开源OCR模型来了」,而是它把一个很难看的trade-off做得漂亮:更小,但更强。
9B→4B,准确率还反超了
Chandra OCR 2的第一组核心数据,值得放大看:
- 参数量:4B
(前代9B,直接砍掉一半多) - olmOCR benchmark:85.9%
(SOTA,比前代83.1%还高) - 语言支持:90+
(比前代的40+翻了一倍不止)
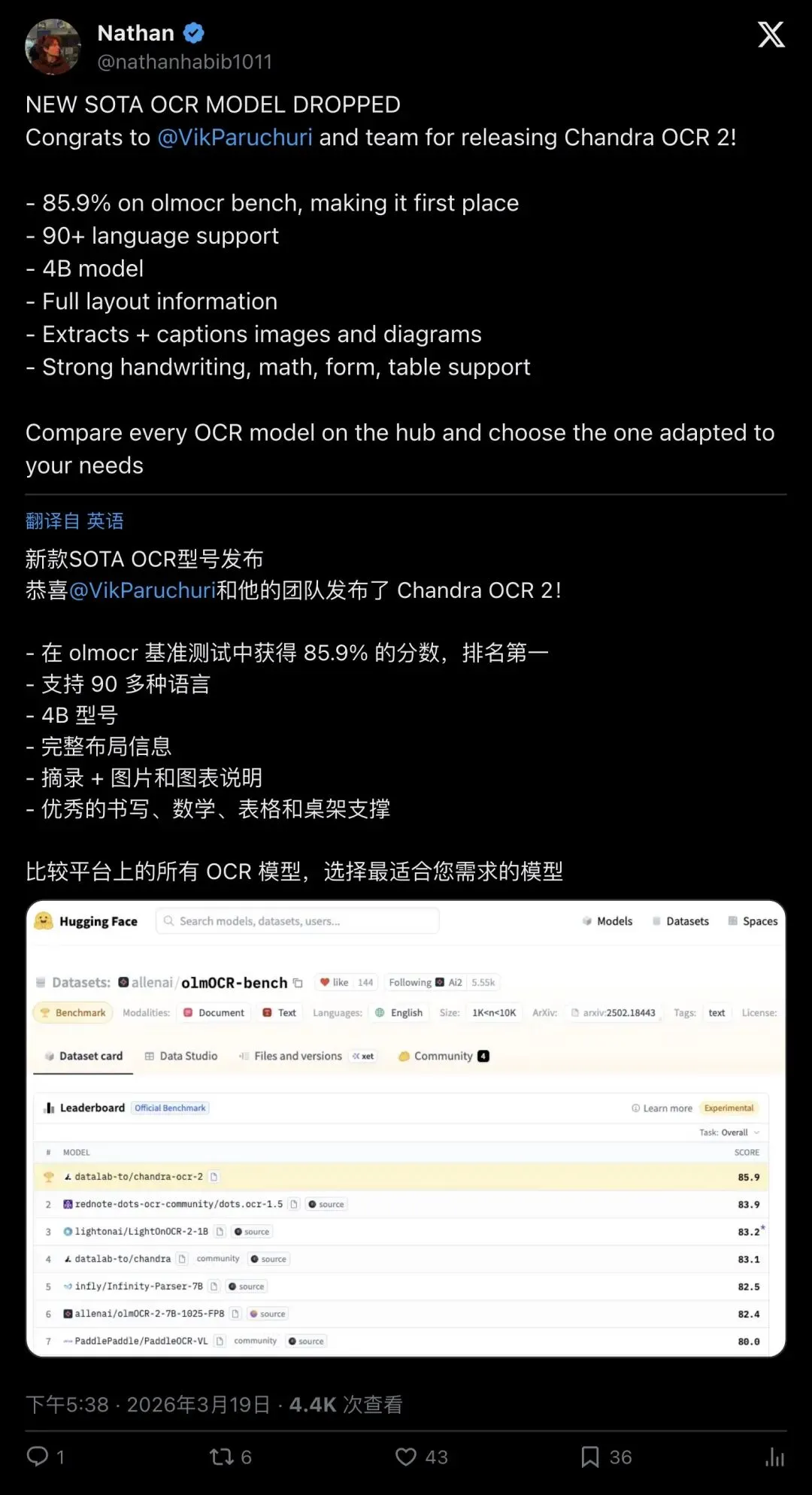
▲ Hugging Face评测团队的Nathan直接打出「NEW SOTA OCR MODEL DROPPED」,确认Chandra OCR 2在olmOCR榜单上拿下第一名。
这意味着什么?
如果只是「更准但更大」,开发者会说「那当然更贵」; 如果只是「更小但更菜」,开发者会说「那只是便宜点」;
但它讲的是:更小了,而且更准了。
开发者Twlvone的点评很犀利:
「9B → 4B with SOTA accuracy is the standout figure.」
这句话解释了为什么这次发布不只是技术圈的自嗨——因为上游OCR变便宜、变快、还维持高精度,会让整个文档AI流水线都受益。
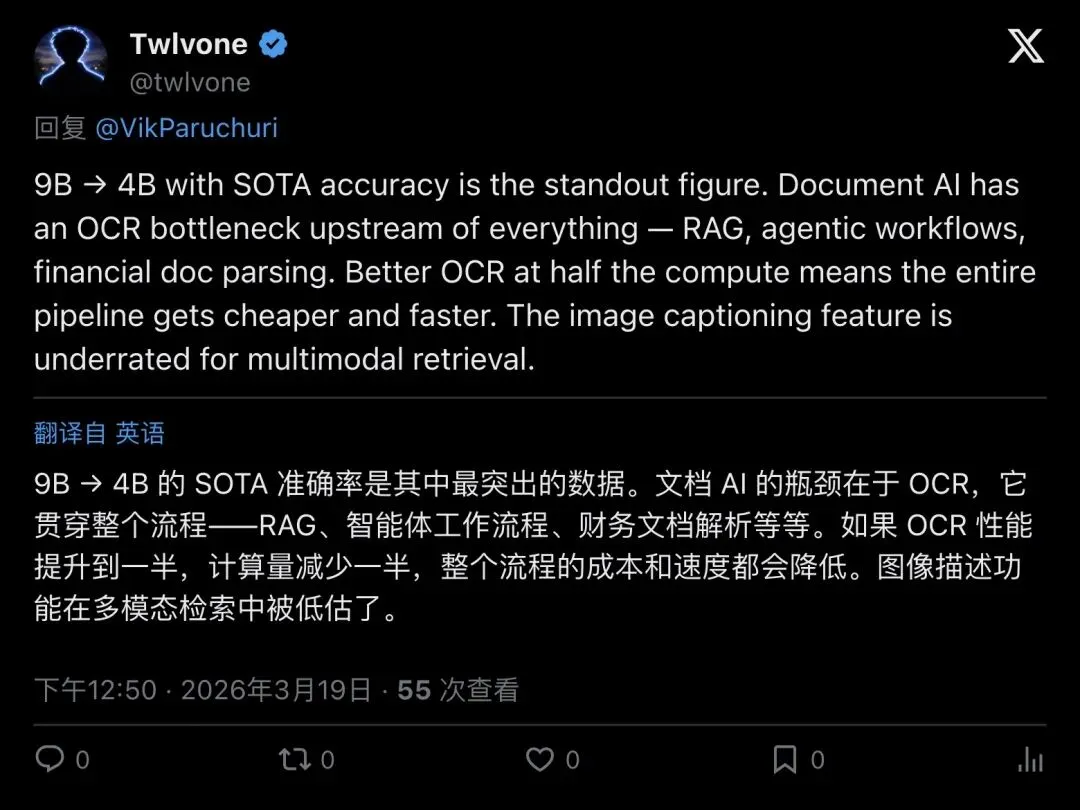
▲ Twlvone指出,OCR是文档AI的上游瓶颈,RAG、agentic workflows、财务文档解析都卡在这一层。更好的OCR意味着整条pipeline更便宜更快。
OCR为什么成了那个最烦的上游瓶颈?
很多人喜欢讨论RAG召回好不好、agent会不会用工具、模型能不能做任务规划。
但现实是,如果你喂进去的文档本身OCR就是烂的:
-
表格裂了 → 后面的结构化提取全废 -
公式没了 → 数学文档直接变乱码 -
多栏乱序 → 上下文语义彻底打乱 -
手写识别错误 → 填表单、签合同这种场景直接GG -
bounding box不可靠 → 你想做版面分析、要做高亮,基础都没了
那后面再强的模型也只能在脏输入上做高阶推理。
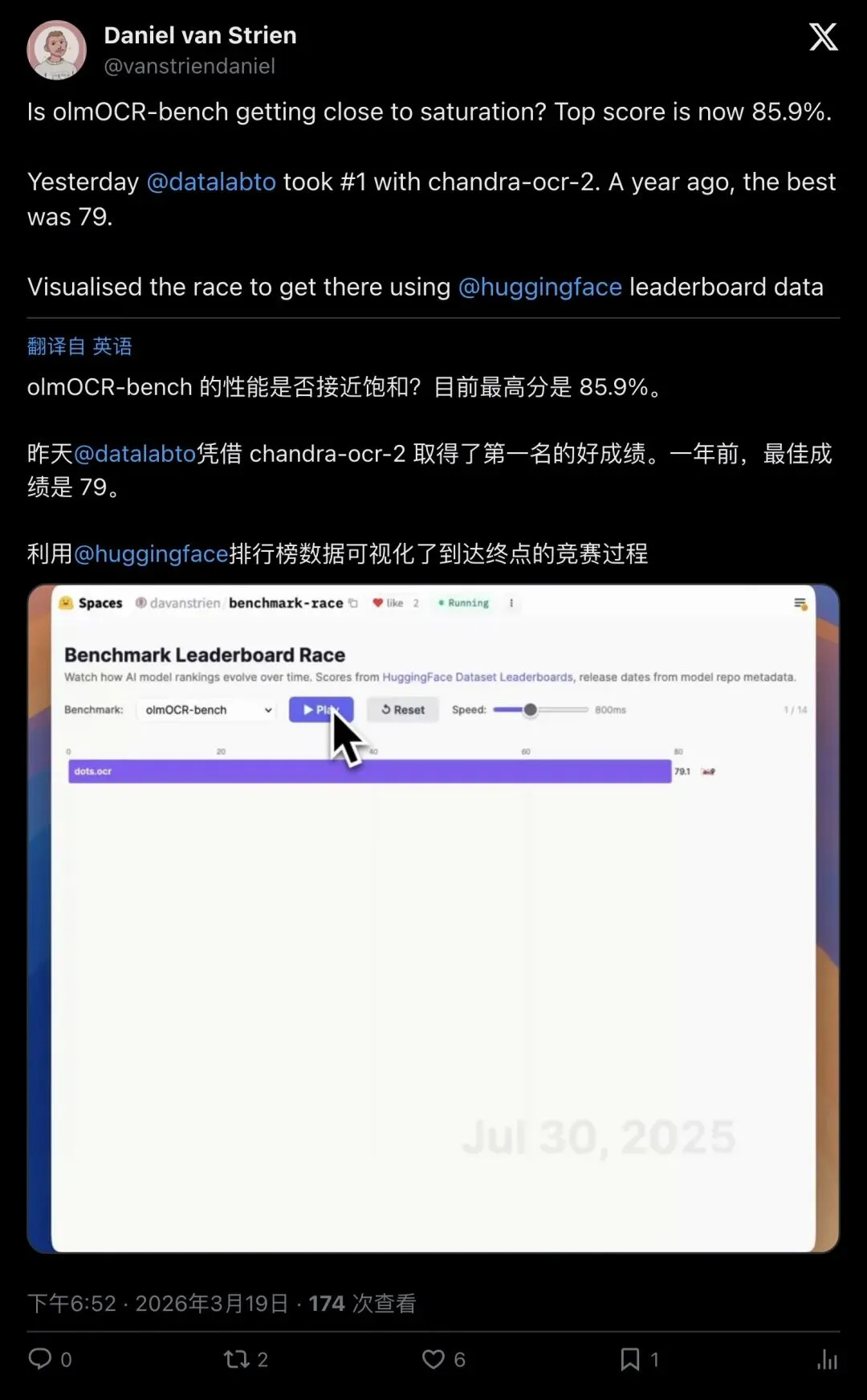
▲ Hugging Face的ML Librarian Daniel van Strien用数据可视化展示了olmOCR榜单的进展:一年前最佳得分才79,现在已经被Chandra OCR 2推到了85.9%。
Chandra OCR 2这次试图解决的,就是这个问题。
它不是那种传统「把页面扫成纯文本」的OCR——它更像一个layout-aware的文档理解模型:
-
不是只识别字 -
而是同时理解整页布局 -
把文本、表格、公式、表单、图片、图表一起纳入处理 -
输出结构化内容,比如Markdown/HTML/JSON/bounding boxes
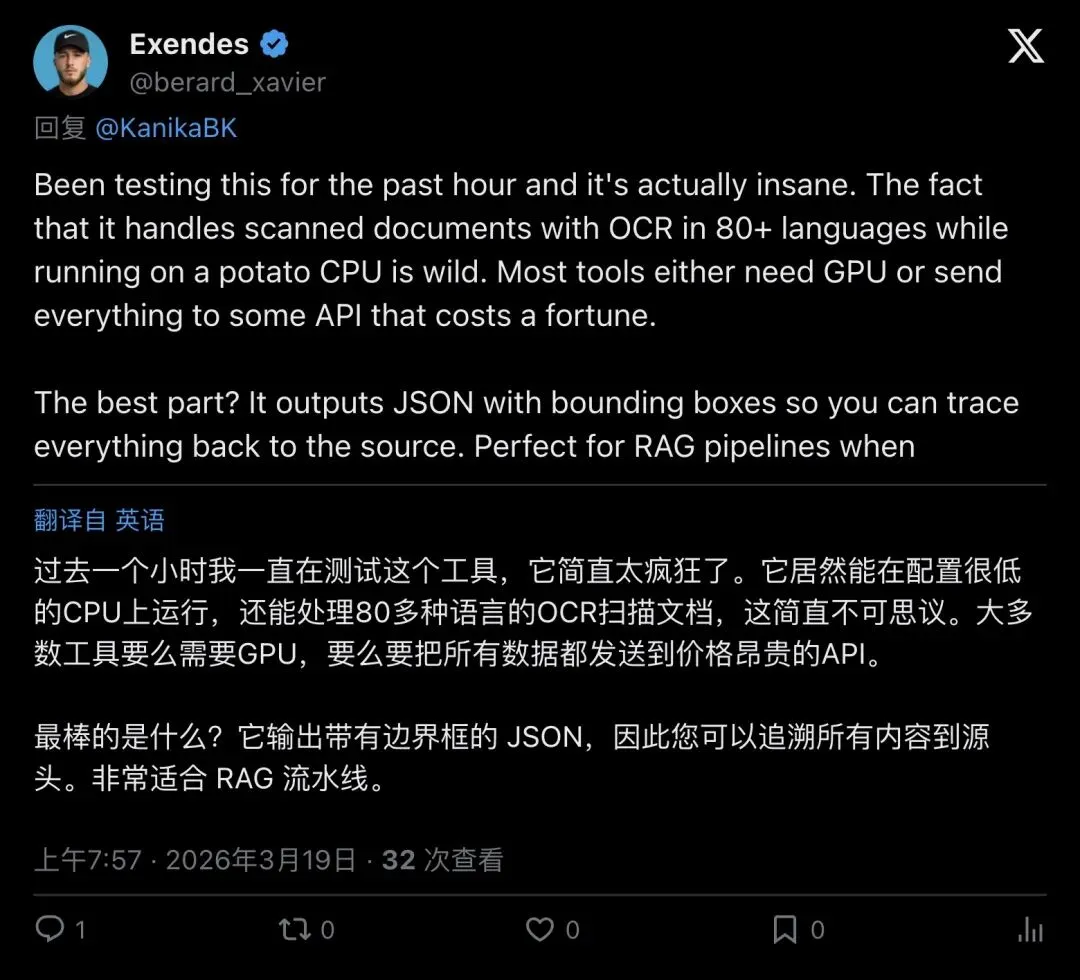
▲ 开发者Exendes实测反馈:扫描文档、80+语言、低配CPU可跑、输出JSON带bounding boxes。这说明它不是只会在benchmark上刷分的「实验室模型」。
这种结构化输出对工程团队非常关键。
因为它不只是「识别完给你一段字」,而是把结果保留成机器可继续消费、可追溯的结构。你可以直接喂给RAG pipeline,可以接agent workflow,可以用来做版面分析。
但它不是万能的
Vik这次主动讲了已知限制,这点对开发者很重要——因为真正做生产的人最怕的是:官方只吹benchmark,不讲失败边界。
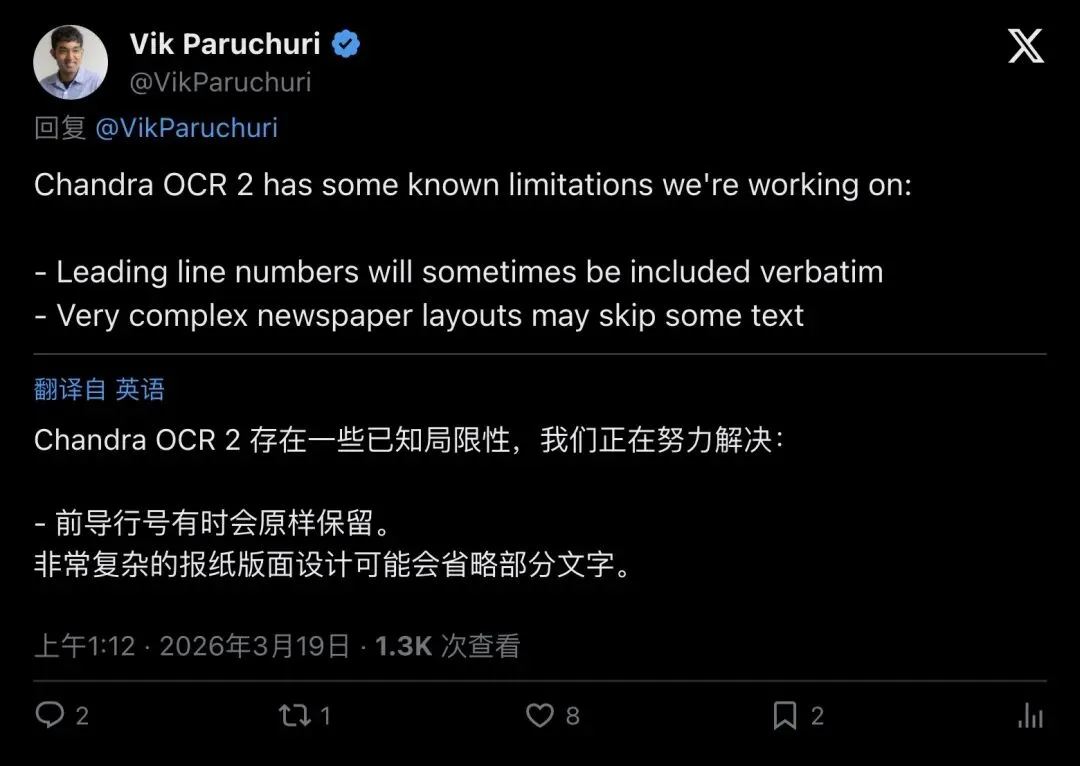
▲ Vik公开承认Chandra OCR 2的已知限制:行号有时会被带入、非常复杂的报纸版式可能会漏掉一些文本。这种透明度对开发者选型很关键。
复杂报纸版式、极难layout仍然是它明说的短板。
但整体来看,这波开源OCR的升级,让那些想把文档处理从昂贵API迁回本地的人,终于有了一个更像样的选择。
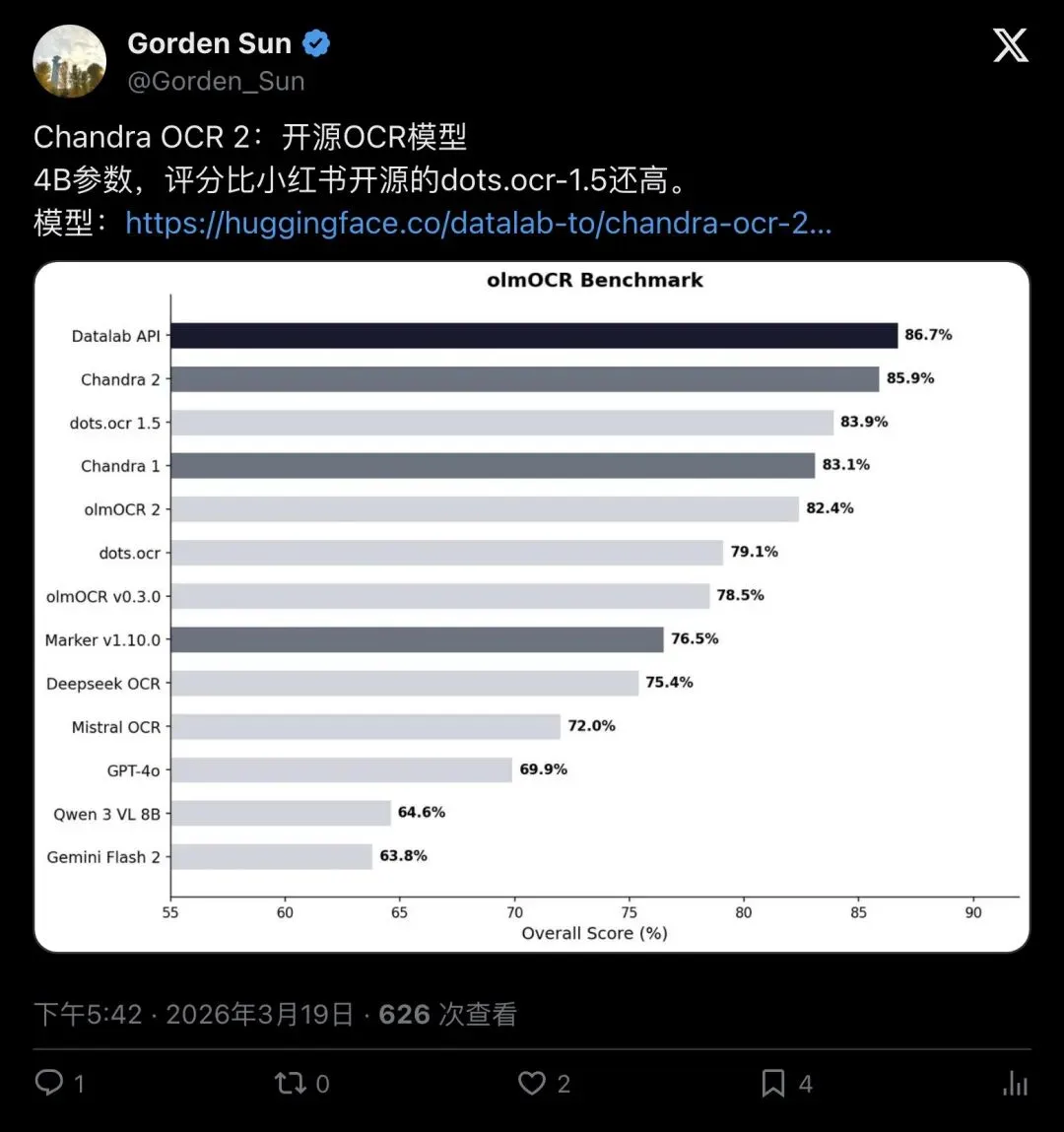
▲ 中文技术圈Gorden Sun的转述直接点出:4B参数,评分比dots.ocr-1.5还高。模型链接直接挂在Hugging Face上,开发者可以拿来就试。
文档AI的「第一页」终于没那么容易读错了
这波发布最值得记住的,不是几个benchmark数字。
而是:
文档AI上游最烦人的OCR关卡,又被开源社区往前踹了一大步。
从Surya(布局检测)到Marker(PDF转Markdown),再到Chandra(全页文档理解),Datalab这个团队一直在用开源的方式,把文档处理的基础设施一点点往前推。
这次Chandra OCR 2给出的答案很简单:更小、更便宜、更适合本地部署,但准确率还更高。
对那些正在搭建RAG系统、做agent workflow、处理财务法律文档、扫描多语言档案的工程师来说——
你终于可以在「把所有文档扔给昂贵API」和「忍受烂OCR」之间,找到第三个选项了。
— END —