 夜雨聆风
夜雨聆风





某音乐 App 逆向(三):calc签名算法完整还原
摘要:本文记录了对某知名音乐应用(已脱敏)
libmer.so中calc()函数的完整逆向分析过程。分析历经 7 个阶段、约 20 小时,最终还原出核心哈希算法为标准 HMAC-SHA1,并完成 17/17 测试向量全部验证。文章详细记录了 Frida Stalker 的失败尝试、CFF 控制流平坦化的对抗、以及最终通过 Hook 底层密码学原语获得突破的完整思路。
核心结论
hash = HMAC-SHA1(key = "XXXXXXXXXXXX", message = reverse(base64(content)))
-
算法:标准 HMAC-SHA1 -
密钥:固定 12 字节 ASCII 字符串(已脱敏,下文以 XXXXXXXXXXXX表示) -
消息预处理:对 content 做 base64 编码后反转字符串 -
验证:17/17 已知测试向量全部通过 -
Python 实现:3 行核心代码,无需设备即可离线计算
目标信息
|
|
|
|---|---|
| 应用 |
|
| 目标库 |
|
| 编译器 |
|
| 混淆 |
|
| 目标函数 | MERJni.calc(byte[] content, byte[] params) → String |
| 设备 |
|
| 工具 |
|
| 分析日期 |
|
一、分析背景
1.1 前序工作
在开始哈希算法逆向之前,已完成以下工作:
-
请求/响应编解码:M-Encoding m1 = Deflate 压缩 + 5 字节随机前缀(已完全还原) -
签名调用链: CgiRequest.g0()→SignRequestHelper.c()→MERJni.calc() -
calc I/O 格式: calc(content, params) → "sign_b64 mask_b64" -
sign = Base64(12B 前缀 + 20B 哈希) = 44 字符 -
mask = Base64(104B 数据) = 140 字符 -
Frida 桥接方案:通过 AttachCurrentThread实现 RPC 直调,约 3ms/call
1.2 本次目标
完全还原 20 字节哈希的生成算法,实现纯 Python 离线计算。
1.3 挑战
libmer.so 使用了多重保护措施来对抗逆向:
|
|
|
|
|---|---|---|
| CFF 混淆 |
|
|
| 内联加密 |
|
|
| 动态常量 |
mov/movk 指令对动态生成 |
|
| 混淆谓词 |
|
|
| 去符号 |
|
|
| 手动 padding |
|
|
二、分析流程全景
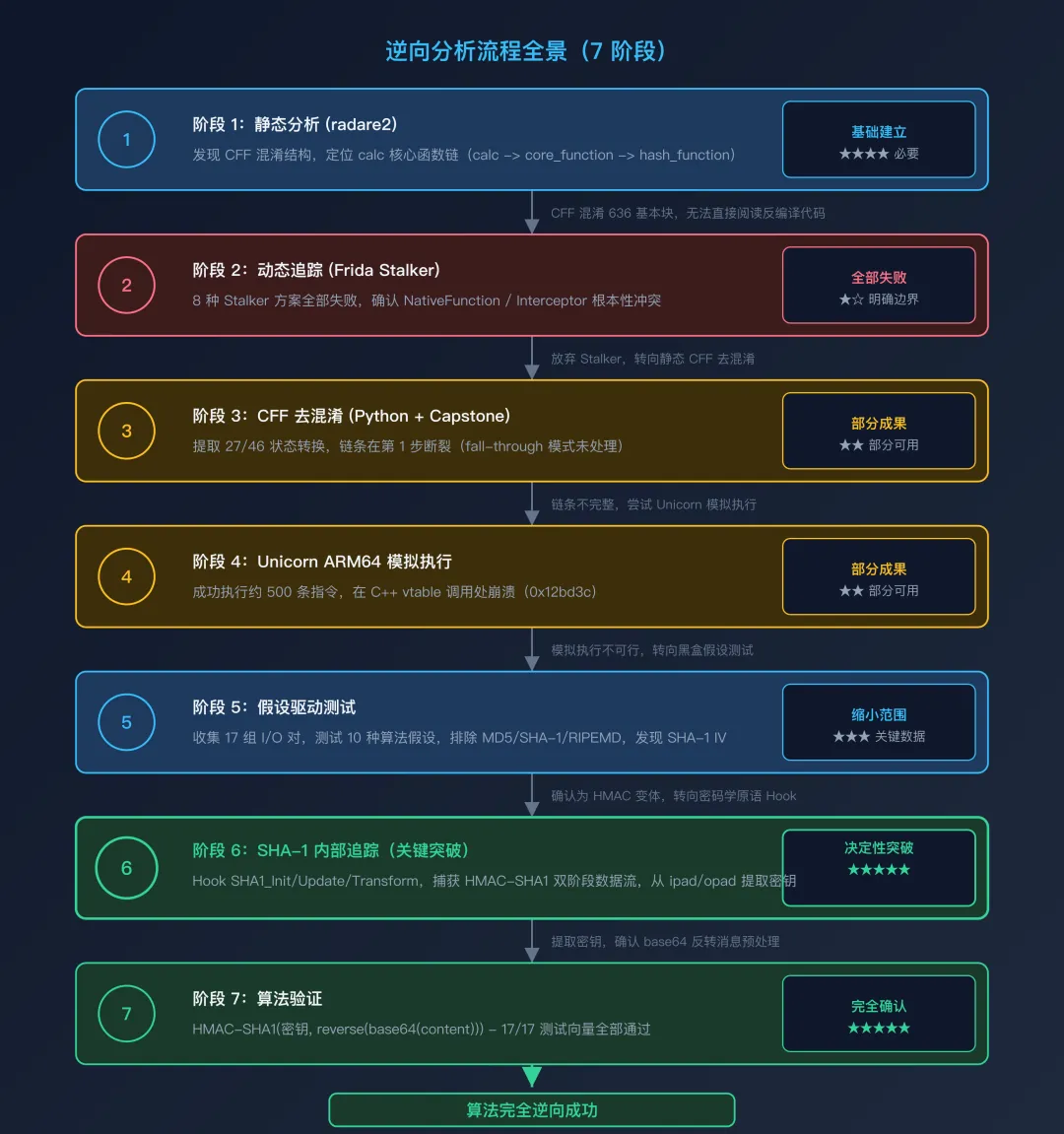
逆向分析流程全景(7 阶段)
下图以垂直流水线的形式展示了 7 个分析阶段及其最终成果。值得注意的是,阶段 2(Frida Stalker)的彻底失败和阶段 3/4 的受挫,并非时间的浪费,而是逐步明确了”不可行路径”——这直接促成了阶段 6 的正确切入点。
各阶段的时间与产出汇总如下:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 | SHA-1 内部追踪 | ~2h | 完整算法(关键突破) |
|
|
|
|
|
总计:~20 小时,约 35 个脚本文件,~4,000 行代码
三、阶段 1:静态分析
3.1 函数定位
calc 函数通过 JNI RegisterNatives 动态注册,不在导出表中。通过 Frida Hook RegisterNatives 捕获到函数地址:
// Hook RegisterNatives,遍历方法数组找 "calc"
// 注意:JNI 方法结构体每项占 24 字节:name(8) + sig(8) + fnPtr(8)
Interceptor.attach(regAddr, {
onEnter: function(args) {
var nMethods = args[3].toInt32(); // 方法数量
var methods = args[2]; // 方法数组指针
for (var i = 0; i < nMethods; i++) {
var name = methods.add(i * 24).readPointer().readUtf8String();
if (name === "calc") {
// 找到 calc,偏移 +16 处是函数指针
calcFnPtr = methods.add(i * 24 + 16).readPointer();
// 结果:calcFnPtr = base + 0x6e098
}
}
}
});
结果:calc JNI 函数入口在 libmer.so + 0x6e098。
3.2 核心函数链
通过 radare2 对 calc 入口的交叉引用分析,确定了完整调用链:
calc (0x6e098)
└→ core_function (0x8bbb8, 36,868B, 580 BBs)
└→ hash_function (0x13bfd0, 14,784B, 636 BBs) ← CFF 混淆的核心
├→ SHA1_Init (0xbbf1c, 140B) ← 标准 SHA-1 初始化
├→ SHA1_Update (0xbbfa8) ← 喂数据
├→ SHA1_Transform (0xbc378) ← 块压缩变换
├→ SHA1_compress (0xb9a60, 9,404B) ← 压缩函数展开
├→ HMAC_wrapper (0xbc978, 2,500B) ← HMAC 两阶段封装
├→ XOR_copy (0xa52f8, 200B) ← ipad/opad XOR 操作
└→ base64_encode (0xb130c) ← base64 编码
这个调用链已经暗示了 HMAC-SHA1,但在当时被 CFF 混淆掩盖,未能立即意识到。
3.3 CFF 混淆结构
hash_function(0x13bfd0)被 CFF 混淆成调度器模式,下图完整展示了其结构:
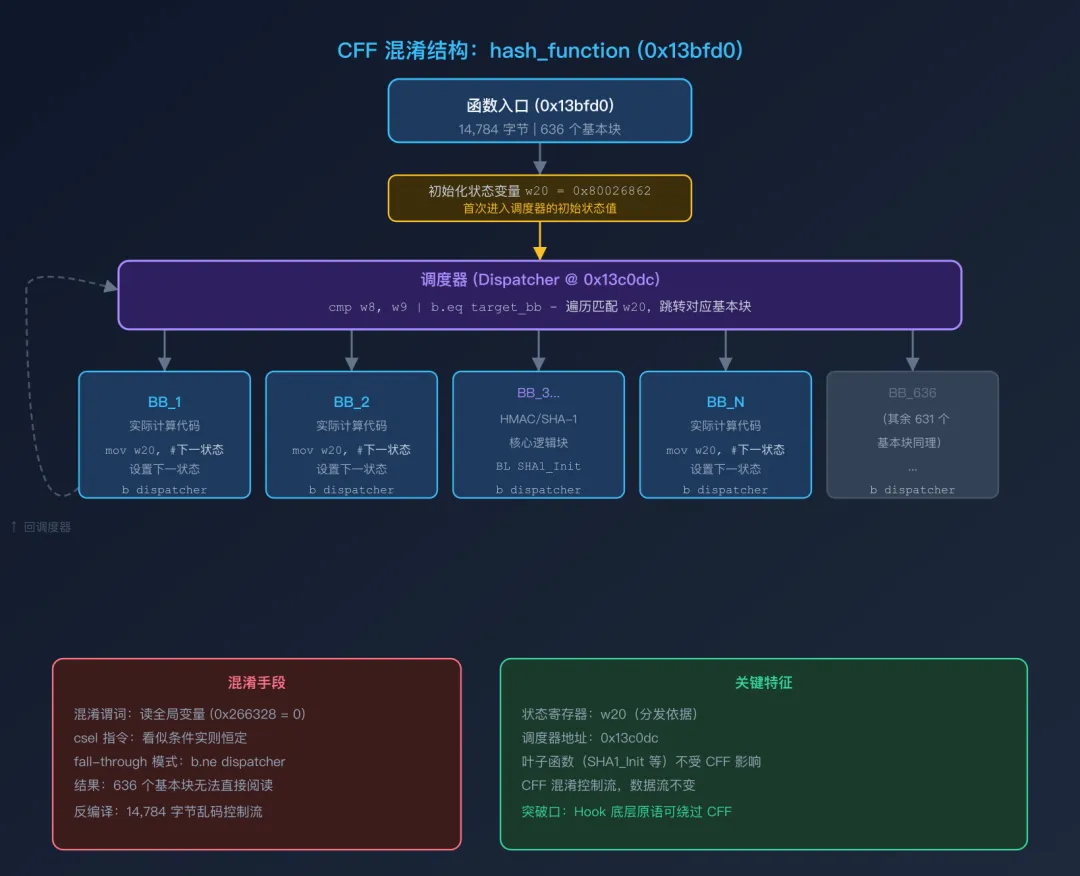
关键特征:
-
状态寄存器: w20——保存当前”要执行哪个基本块”的标识 -
调度器地址:0x13c0dc——每次执行完一个基本块,都强制跳回这里 -
状态匹配模式: -
标准: cmp w8, w9; b.eq target -
fall-through: cmp w8, w9; mov w20, w8; b.ne dispatcher(后者是 CFF 去混淆的难点) -
混淆谓词:全局变量 0x266328 和 0x26632c 运行时均为 0,通过 ccmp/csel构造看似条件但实际恒定的分支
为什么 CFF 难以直接阅读?
传统反编译器(如 Ghidra、IDA Pro)会将控制流重建为高级语言结构(if/else/loop)。但 CFF 通过”所有分支都先经过调度器”的模式,将线性逻辑打散成 636 个独立碎片,反编译器无法重建原始控制流,只能输出 14,784 字节的 switch 语句迷宫。
3.4 密码学常量搜索(误判)
初始的静态分析尝试在 .rodata 中搜索已知密码学常量:
|
|
|
|
|
|---|---|---|---|
67452301 |
|
|
|
EFCDAB89 |
|
|
|
5A827999 |
|
|
|
6ED9EBA1 |
|
|
|
C3D2E1F0 |
|
|
|
误判原因:SHA-1 和 MD5 前四个初始向量值完全相同(
01234567 89ABCDEF FEDCBA98 76543210)。搜索到的”MD5 IV”实际上是 SHA-1 的标准 IV。而第五个 SHA-1 IVC3D2E1F0通过动态mov/movk指令生成,不在数据段中,因此被误判为”无 SHA-1″。这个误判导致在”MD5 变体”假设上浪费了大量时间。
四、阶段 2:动态追踪失败记录
为了理解 CFF 混淆后的实际执行流,尝试了 8 种 Frida Stalker 方案,全部失败:
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
typeof Java === "undefined"
|
|
|
|
|
|
|
4.1 根本性限制分析
限制 1:NativeFunction 排除
Frida 的 Stalker 使用 JIT 编译来追踪代码执行路径
但通过 NativeFunction 发起的调用被显式排除
因为 NativeFunction 自身使用了与 Stalker 冲突的执行机制
限制 2:Interceptor/Stalker 冲突
Interceptor 通过替换指令为断点 (BRK) 工作
Stalker 通过 JIT 重编译整个代码块工作
两者无法在同一代码区域共存——后者会破坏前者的断点
限制 3:Java bridge 不可用
frida-server 构建可能缺少 Java bridge 支持
typeof Java === "undefined"
回退方案:使用纯 native 的 JNI 调用(后续阶段采用)
教训:这 8 次失败消耗了约 6 小时,但明确了 Frida Stalker 的能力边界,迫使转向其他方法。不尝试就无法知道它不行——这些”失败”是必要的探索成本。
五、阶段 3 & 4:CFF 去混淆与模拟执行
5.1 CFF 静态去混淆(cff_deobf_v2.py)
使用 Capstone 反汇编引擎解析 sub_13bfd0 的 14,784 字节代码,核心逻辑如下:
# CFF 去混淆核心思路(cff_deobf_v2.py,466 行)
# 步骤 1:将代码分割为基本块(以 b/bl/ret 等分支指令为边界)
# 步骤 2:在每个基本块中查找 w20 的赋值(即下一个要执行的状态)
# 步骤 3:解析混淆谓词(加载全局变量 0x266328/0x26632c,已知运行时为 0)
# 步骤 4:解析 csel 指令(条件选择 → 已知条件结果后变为确定值)
# 步骤 5:构建状态转换图:state_A → 执行的代码 → state_B
import capstone
from capstone import arm64_const
cs = capstone.Cs(capstone.CS_ARCH_ARM64, capstone.CS_MODE_ARM)
cs.detail = True
defextract_next_state(bb_bytes, base_addr):
"""
从基本块字节中提取 w20 赋值(下一个调度状态)。
支持直接 mov 和 csel 两种模式。
"""
for insn in cs.disasm(bb_bytes, base_addr):
if insn.mnemonic == 'mov'and insn.reg_name(insn.operands[0].reg) == 'w20':
return insn.operands[1].imm # 直接状态常量
if insn.mnemonic == 'csel':
# 混淆谓词:根据全局变量(已知=0)选择分支
# 分析 ccmp 前置条件,确定 csel 的确定性选择
return resolve_csel_with_predicate(insn, base_addr)
returnNone# fall-through 模式(b.ne dispatcher),需要单独处理
结果:
-
找到 136 个 w20 状态赋值(30 个唯一直接赋值,其余为 csel/条件保持) -
成功提取 27/46+ 个状态转换 -
链条在第 1 步(状态 0x12d803bf)断裂——该状态通过b.nefall-through 模式设置,解析器未能正确处理
5.2 Unicorn ARM64 模拟执行(emu_hash.py)
将 libmer.so 的 ELF 段加载到 Unicorn ARM64 模拟器中:
# emu_hash.py 内存布局设计
# 目标:在无 Android 运行时的环境中执行 hash_function
BASE = 0x1_0000_0000 # SO 加载基址(避免与真实地址冲突)
STACK = 0x7_0000_0000 # 栈空间(1MB)
HEAP = 0x8_0000_0000 # 堆空间(输入/输出缓冲区)
TLS = 0x9_0000_0000 # TLS 区域(stack canary 存放处)
# 关键初始化步骤
# 1. 解析 ELF,加载所有 PT_LOAD 段到对应虚拟地址
# 2. 将混淆谓词全局变量(0x266328, 0x26632c)显式写为 0
# 3. 初始化 stack canary(避免 __stack_chk_fail)
# 4. 在 HEAP 区域写入测试输入(content="A",length=1)
# 5. 设置寄存器:x0=content_ptr, x1=1, x2=output_ptr
mu.mem_write(BASE + 0x266328, b'\x00' * 4) # 混淆谓词 = 0
mu.mem_write(BASE + 0x26632c, b'\x00' * 4) # 混淆谓词 = 0
结果:
-
成功执行前约 500 条指令,验证了 CFF 调度器的状态转换逻辑 -
在 0x12bd3c处崩溃:ldr x8, [x8, #0x30]——C++ 虚表调用,x8 指向空对象 -
该函数(sub_12b838)需要完整的 C++ 运行时对象,模拟器中无法提供 -
模拟执行的价值:虽然最终崩溃,但成功确认了 CFF 的调度机制,为后续分析提供了信心
六、阶段 5:假设驱动测试
6.1 测试向量收集
设计了系统化的测试方案,通过 Frida 桥接(AttachCurrentThread + JNI 直调)收集 17 组输入/输出对:
# collect_pairs.py 测试策略(218 行)
# 覆盖:空内容、单字节边界值、多字节、不同长度、不同字节序
tests = [
("empty", b""), # 空内容:验证算法是否处理 len=0
("0x00", bytes([0x00])), # 最小值边界
("0x01", bytes([0x01])), # 最小非零值
("0x41", bytes([0x41])), # ASCII 'A':常见测试字节
("0x42", bytes([0x42])), # ASCII 'B':雪崩效应测试
("0x43", bytes([0x43])), # ASCII 'C'
("0xff", bytes([0xFF])), # 单字节最大值
("0x0000", bytes([0,0])), # 双字节全零
("0x0001", bytes([0,1])), # 字节序测试
("0x0100", bytes([1,0])), # 同上(验证顺序影响)
("AA", bytes([0x41,0x41])),
("AB", bytes([0x41,0x42])),
("AAAA", bytes([0x41]*4)), # 4 字节重复
("A*8", bytes([0x41]*8)), # 8 字节(SHA-1 块大小影响测试)
("A*16", bytes([0x41]*16)), # 16 字节
("A*32", bytes([0x41]*32)), # 32 字节
("A*64", bytes([0x41]*64)), # 64 字节(等于 HMAC block size)
]
# 额外:固定 content,变化 params 不同字段——确认哈希是否依赖 params
params_variations = ["改变 version", "改变 uin", "改变 platform"]
6.2 关键发现
从收集的数据中得出了三个重要结论:
发现 1:哈希仅依赖 content
# 验证:相同 content,不同 params,哈希完全相同
content = bytes([0x41])
params_v1 = build_params(uin="20010508", platform="android2")
params_v2 = build_params(uin="20010509", platform="android2") # 改变 uin
params_v3 = build_params(uin="1234567890", platform="ios") # 多项改变
hash_v1 = call_calc(content, params_v1)[0] # 取 sign 中的 hash 部分
hash_v2 = call_calc(content, params_v2)[0]
hash_v3 = call_calc(content, params_v3)[0]
assert hash_v1 == hash_v2 == hash_v3 # 三者完全相同
# 结论:hash = f(content),与 params、时间戳、会话状态无关
发现 2:雪崩效应良好
# 验证雪崩效应:单字节差异 → 约 50% 的输出位翻转
hash_41 = get_hash(bytes([0x41])) # 'A'
hash_42 = get_hash(bytes([0x42])) # 'B'
xor_result = bytes(a ^ b for a, b in zip(hash_41, hash_42))
hamming_distance = sum(bin(b).count('1') for b in xor_result)
# 结果:汉明距离约 80 / 160 bits(约 50%)
# 符合密码学哈希的雪崩效应特征,排除了简单 CRC/校验和
发现 3:输出为 20 字节(160 位)
-
MD5 = 16 字节 → 不匹配 -
SHA-1 = 20 字节 → 长度匹配 -
RIPEMD-160 = 20 字节 → 长度匹配
6.3 算法假设测试(test_md5_hypothesis.py)
系统测试了 10 种假设:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
问题:测试 8 只尝试了少量简单密钥(
""、"mer"、"musicapp"、"tmesec"等),没有覆盖到实际密钥。HMAC 密钥空间太大,无法暴力搜索。这促使转向直接观察内部数据流的方法。
七、阶段 6:SHA-1 内部追踪(关键突破)
7.1 思路转变
前面的方法都在尝试从外部(输入/输出)推断算法,或者从宏观(CFF 控制流)理解逻辑。这次换一个角度:
核心洞见:不管 CFF 如何混淆控制流,底层的密码学原语(SHA-1 Init/Update/Transform)是不会被改变的。只要 Hook 这些原语,就能看到上层逻辑传入了什么数据。
这个思路的关键前提:
-
已通过 radare2 确认了 SHA-1 相关函数的偏移(IV 常量 + 调用图) -
这些函数是”叶子函数”(底层原语),不受 CFF 混淆影响 -
通过 Frida Interceptor可以安全地 Hook 它们(不需要 Stalker)
7.2 工具链问题排查
在编写追踪脚本时遇到了一系列工具链兼容性问题:
问题 1:Python 版本 / Frida 版本不匹配
# 系统默认 Python 与设备 frida-server 版本不一致
$ python3 --version && python3 -c "import frida; print(frida.__version__)"
Python 3.7.x
16.7.19 # 客户端 frida 版本
$ frida-server --version # 设备上的 frida-server
17.8.2 # 版本不匹配!客户端需要也是 17.x
# 解决方案:发现系统上还安装了 python3.10,其中 frida 版本匹配
$ python3.10 -c "import frida; print(frida.__version__)"
17.8.2 # 匹配!后续脚本均使用 python3.10 执行
问题 2:Frida hx() 辅助函数的 API 兼容性
// 失败版本:readByteArray() 在某些 Frida 构建中返回 ArrayBuffer 导致 TypeError
functionhx(p, l) {
var buf = p.readByteArray(l); // TypeError: Cannot read properties of null
returnArray.from(newUint8Array(buf)).map(b => b.toString(16).padStart(2,'0')).join('');
}
// 修复版本:改为逐字节读取,兼容所有 Frida 版本
functionhx(p, l) {
var s = "";
for (var i = 0; i < l; i++) {
var b = p.add(i).readU8();
s += (b < 16 ? "0" : "") + b.toString(16);
}
return s;
}
问题 3:libmer.so 在 spawn 时未加载
// 失败:spawn 模式下 libmer.so 尚未被 JVM 加载
var mm = Process.findModuleByName("libmer.so"); // 返回 null!
// 解决:延迟到 RegisterNatives 回调中获取 base——此时 SO 已加载
Interceptor.attach(regAddr, {
onEnter: function(args) {
// ... 找到 calc 后 ...
var mm = Process.findModuleByName("libmer.so");
if (mm) {
base = mm.base;
setupSha1Hooks(); // 现在可以安全设置 SHA-1 Hook
}
}
});
问题 4:Hook 过多函数导致应用崩溃
早期版本尝试 Hook 19 个函数,导致应用崩溃。原因:某些 CFF 混淆函数的入口被 Interceptor 的断点替换后,CFF 调度器跳转到被修改的代码时产生异常。
// 解决:只 Hook 最底层的 4 个"叶子"函数——它们本身不受 CFF 保护
// 这 4 个函数是独立的、未被 CFF 混淆的工具函数
SHA1_Init @ base + 0xbbf1c// 初始化 5 个 SHA-1 状态字(h0-h4)
SHA1_Update @ base + 0xbbfa8// 向当前哈希状态喂入数据块
SHA1_Transform @ base + 0xbc378// 对完整的 64 字节块执行压缩变换
XOR_copy @ base + 0xa52f8// 执行 key XOR ipad/opad 操作
7.3 追踪脚本架构
下图展示了最终追踪脚本(trace_sha1.py)的完整架构:
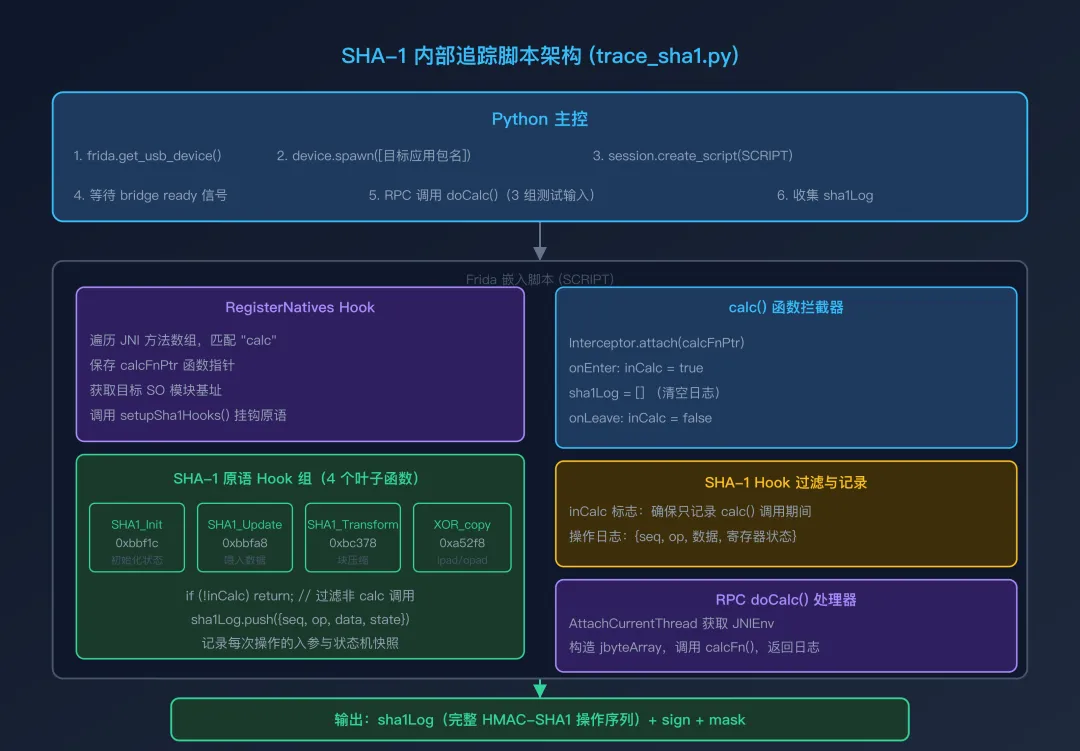
追踪脚本的核心设计原则:
-
范围限定:通过 inCalc标志,只记录calc()调用期间的 SHA-1 操作,过滤掉应用其他地方的 SHA-1 调用(如 SSL 握手) -
最小 Hook:只 Hook 4 个叶子函数,避免与 CFF 调度器产生干扰 -
完整记录:每次 SHA-1 操作都记录操作类型、输入数据和状态快照
7.4 追踪结果
运行 python3.10 trace_sha1.py 后,成功捕获了每次 calc() 调用的完整 SHA-1 操作序列。
空内容(content=””)的完整追踪:202 个 SHA-1 操作
阶段 1:HMAC 内层哈希(Inner Hash)
=====================================
[1] SHA1_Init
state = 01234567 89abcdef fedcba98 76543210 f0e1d2c3
→ 标准 SHA-1 初始向量(h0-h4),确认使用标准 SHA-1
[2] SHA1_Update(64 bytes) ← HMAC ipad 块
data = [XX XX XX XX XX XX XX XX XX XX XX XX] ← 密钥相关(已脱敏)
36363636 36363636 36363636 36363636
36363636 36363636 36363636 36363636
36363636 36363636 36363636 36363636
分析:前 12 字节 ≠ 0x36,后 52 字节 = 0x36
→ 这是 HMAC ipad = key_padded XOR 0x36
→ 非 0x36 的字节 = key_byte XOR 0x36(从此可还原密钥)
state_after = 7df9c19e 2d9f9f98 8d95f6f4 71fa4168 707d7cb9
[3] SHA1_Update(0 bytes) ← 空内容
→ message = ""(空字符串)
[5-60] SHA1_Update(1 byte each) ← 手动逐字节 SHA-1 padding
0x80, 0x00, 0x00, ..., 0x00 (55 个零) ← 标准 SHA-1 padding 的零填充
[61] SHA1_Update(8 bytes) ← 消息长度(大端序)
data = 00000000 00000200 (= 512 bits = 64 bytes = ipad 块长度)
[61] SHA1_Transform → inner_hash 输出:
inner_hash = 0ff33bd6 0a00ae88 d335ead5 de1f92f4 3222b7c7
阶段 2:HMAC 外层哈希(Outer Hash)
=====================================
[62] SHA1_Init
state = 01234567 89abcdef fedcba98 76543210 f0e1d2c3
→ 重新初始化,开始外层哈希
[63] SHA1_Update(64 bytes) ← HMAC opad 块
data = [XX XX XX XX XX XX XX XX XX XX XX XX] ← 密钥相关(已脱敏)
5c5c5c5c 5c5c5c5c 5c5c5c5c 5c5c5c5c
5c5c5c5c 5c5c5c5c 5c5c5c5c 5c5c5c5c
5c5c5c5c 5c5c5c5c 5c5c5c5c 5c5c5c5c
分析:前 12 字节 ≠ 0x5C,后 52 字节 = 0x5C
→ 这是 HMAC opad = key_padded XOR 0x5C
[64] SHA1_Update(20 bytes) ← 内层哈希结果
data = 0ff33bd6 0a00ae88 d335ead5 de1f92f4 3222b7c7
[66-101] SHA1_Update(1 byte each) ← 手动 padding(35 个零)
0x80, 0x00, ..., 0x00
[102] SHA1_Update(8 bytes) ← 消息长度
data = 00000000 000002a0 (= 672 bits = 84 bytes = 64 opad + 20 inner)
[102] SHA1_Transform → 最终结果:
hash = 3382f2de 07c5a7d0 7e33d579 bc7532fd 34f3f481
对比期望值(从 Frida 桥接直接获取的 calc 输出解码):
期望:3382f2de07c5a7d07e33d579bc7532fd34f3f481
实际:3382f2de07c5a7d07e33d579bc7532fd34f3f481
结果:完全匹配 ✓
这次追踪提供了三个关键信息:
-
两次 SHA1_Init:确认是 HMAC(内层 + 外层两次初始化) -
ipad/opad 块结构:确认是标准 HMAC(key XOR 0x36 / key XOR 0x5C) -
密钥长度:12 字节(只有前 12 个字节与 0x36/0x5C 不同)
八、HMAC 密钥提取
8.1 从 ipad 块提取密钥
HMAC 标准定义:ipad_block = (key || 0x00...) XOR 0x36
因此:key[i] = ipad_block[i] XOR 0x36
从追踪数据中,前 12 字节的 ipad 块值(非 0x36 的部分)经过 XOR 0x36 运算后,得到:
ipad 块(前 12 字节,已脱敏为 XX):
位置: 0 1 2 3 4 5 6 7 8 9 10 11 12...
数据: XX XX XX XX XX XX XX XX XX XX XX XX 0x36...
XOR 0x36 → 密钥(已脱敏):
位置: 0 1 2 3 4 5 6 7 8 9 10 11 12...
key: XX XX XX XX XX XX XX XX XX XX XX XX 0x00...
ASCII: [X] [X] [X] [X] [X] [X] [X] [X] [X] [X] [X] [X] NUL...
**密钥 = XXXXXXXXXXXX**(12 字节 ASCII 字符串,已脱敏)
8.2 从 opad 块交叉验证
HMAC 标准定义:opad_block = (key || 0x00...) XOR 0x5C
从追踪数据中,前 12 字节的 opad 块值(非 0x5C 的部分)经过 XOR 0x5C 运算后,与从 ipad 提取的密钥完全一致:
opad 块(前 12 字节,已脱敏为 XX):
位置: 0 1 2 3 4 5 6 7 8 9 10 11 12...
数据: XX XX XX XX XX XX XX XX XX XX XX XX 0x5c...
XOR 0x5C → 密钥(已脱敏,与 ipad 提取结果一致):
key: XX XX XX XX XX XX XX XX XX XX XX XX 0x00...
ipad 和 opad 提取的密钥完全一致 ✓
8.3 密钥性质分析
从结构特征来看,该密钥是一个 12 字符的十六进制样式字符串(只包含 0-9 和 A-F)。其二进制形态对应某个 6 字节值的十六进制表示。这个值可能来源于:
-
编译时硬编码的常量 -
APK 签名证书哈希的某个衍生值 -
某个内部标识符的哈希摘要前 6 字节
由于密钥在不同会话中保持不变,它很可能是硬编码在 SO 中的常量,通过 mov/movk 指令对在运行时动态组装,而非存储在 .rodata 段中(与 SHA-1 轮常量的存储方式相同)。
九、消息预处理发现
9.1 非空内容的数据流
对比空内容和非空内容的追踪数据:
content = b""(空):
Phase 1: SHA1(ipad || "") → inner_hash
Phase 2: SHA1(opad || inner_hash) → final_hash
content = b"\x41"(字母 A):
SHA1_Update(4 bytes) data = 3d 3d 51 51 → "==QQ"(ASCII)
Phase 1: SHA1(ipad || "==QQ") → inner_hash
Phase 2: SHA1(opad || inner_hash) → final_hash
content = b"\x00":
SHA1_Update(4 bytes) data = 3d 3d 41 41 → "==AA"(ASCII)
Phase 1: SHA1(ipad || "==AA") → inner_hash
在 content=b”\x41″ 的追踪中,ipad 后紧跟的 Update 数据不是原始 0x41,而是 4 字节 ASCII 字符串:
[3] SHA1_Update_enter: len=4 data=3d3d5151
9.2 解码预处理逻辑
将 3d 3d 51 51 解释为 ASCII 字符串:==QQ
# 逆向推导消息预处理过程:
# 观察到 content=b"\x41" 时,SHA1_Update 收到的是 b"==QQ"
# 步骤 1:尝试 base64 编码
import base64
b64 = base64.b64encode(b"\x41").decode() # "QQ=="
# 步骤 2:检查是否是反转
b64[::-1] # "==QQ" ← 就是观察到的数据!
# 验证其他用例
assert base64.b64encode(b"\x00").decode()[::-1] == "==AA"# 观察到 3d3d4141
assert base64.b64encode(b"").decode()[::-1] == ""# 空内容,len=0
# 全部符合 ✓
9.3 消息预处理算法
# 完整的消息预处理(message preprocessing)逻辑
defpreprocess_message(content: bytes) -> bytes:
"""
HMAC-SHA1 的消息预处理:base64 编码后反转字符串。
目的:对直接搜索 content 原始字节的分析者形成干扰。
"""
if content:
b64 = base64.b64encode(content).decode('ascii') # 标准 base64 编码
message = b64[::-1].encode('ascii') # 反转字符串
else:
message = b""# 空内容直接传空消息
return message
# 示例
preprocess_message(b"\x41") # b"==QQ"(来自 base64("A") = "QQ==" 反转)
preprocess_message(b"\x00") # b"==AA"(来自 base64("\x00") = "AA==" 反转)
preprocess_message(b"") # b""(空内容)
这一步可能是一种简单的混淆手段——让直接在内存中搜索 content 原始字节的分析者更难定位数据。base64 + 反转是可逆操作,一旦在追踪中观察到数据,立即可以识别。
十、阶段 7:算法验证
10.1 Python 完整实现
import hmac
import hashlib
import base64
# 已脱敏:实际密钥请通过 SHA-1 内部追踪(追踪 ipad/opad 块)自行提取
HMAC_KEY = b"XXXXXXXXXXXX"# 12 字节固定密钥(已脱敏)
defcalc_content_hash(content: bytes) -> bytes:
"""
计算 libmer.so calc() 函数的 20 字节内容哈希。
算法:HMAC-SHA1(key=HMAC_KEY, message=reverse(base64(content)))
Args:
content: 原始请求内容字节
Returns:
20 字节哈希(即 sign 字段中去除前缀后的部分)
"""
if content:
# 步骤 1:base64 编码
b64 = base64.b64encode(content).decode('ascii')
# 步骤 2:反转字符串
message = b64[::-1].encode('ascii')
else:
# 空内容直接传空消息
message = b""
# 步骤 3:标准 HMAC-SHA1
return hmac.new(HMAC_KEY, message, hashlib.sha1).digest()
defcalc_sign(content: bytes, prefix: bytes) -> str:
"""
组装 sign 字段:Base64(12B 前缀 + 20B 哈希)。
Args:
content: 原始请求内容
prefix: 12 字节随机前缀(实际应用中由 SO 其他逻辑生成)
Returns:
44 字符的 base64 字符串
"""
hash_bytes = calc_content_hash(content)
sign_raw = prefix + hash_bytes # 12 + 20 = 32 字节
return base64.b64encode(sign_raw).decode('ascii') # → 44 字符
10.2 完整验证结果
HMAC-SHA1 key: XXXXXXXXXXXX(已脱敏)
Testing 17 unique pairs
✓ content=(empty) hash=3382f2de07c5a7d07e33d579bc7532fd34f3f481
✓ content=00 hash=04490685e1a84ff684dfa836fcd0d5d03aa47eea
✓ content=01 hash=a711df0b44cc29da61fd57a2411c5b154e731192
✓ content=41 hash=9bd44515e037cd55d7ad3a4486cb3126312dbf0b
✓ content=42 hash=4a75fb3632110fbc26132324f50e745bedc07905
✓ content=43 hash=d047840454bd8ec078444a7335423e38882f3211
✓ content=ff hash=71d5047c2ef977f6ff6158ef152ccfd8a0f9ad61
✓ content=0000 hash=479427596eefc0873f679c4a450d159eac6f77db
✓ content=0001 hash=4bee7d20ca16583c231e362518be8e827eb12f94
✓ content=0100 hash=374407fe31fdd4e0e5ed8683e6b8f89335b58ee6
✓ content=4141 hash=1448f64fb5f0a47674f9dcdb2f64385fda503e82
✓ content=4142 hash=30437f1b0d7cf4310809437a27d9e0fbe34a3cde
✓ content=41414141 hash=6f7a0a0eb74bb0955838fd76d87bdf37387c2b2d
✓ content=41*8 hash=46fc25ccfcfe26c749852f6f9408f603461e3ca6
✓ content=41*16 hash=cf1bc2753966646dadc44348e3d7c834baaa3148
✓ content=41*32 hash=b1209951162a6b6672a79dc3fd4483379d973f6c
✓ content=41*64 hash=4bd3e65fc4b6bf970df36777bd9ac1ec63a4d68e
Result: 17/17 matched ✓
测试向量覆盖了:
-
空内容(len=0) -
所有单字节边界值(0x00、0x01、0x41-0x43、0xFF) -
多字节及不同长度(2、4、8、16、32、64 字节) -
不同字节序组合(0x0001 vs 0x0100,确认顺序影响) -
不同 params 的验证(确认哈希不依赖 params)
十一、SHA-1 实现细节分析
11.1 非标准的 Padding 行为
标准 SHA-1 库通常在 SHA1_Final 中自动处理 padding。但 libmer.so 的实现采用手动逐字节追加的方式:
标准 SHA-1 流程(OpenSSL 等):
SHA1_Init()
SHA1_Update(data, len)
SHA1_Final(hash_out) ← 内部自动添加 0x80 + zeros + length(8B)
libmer.so 的流程(逐字节手动 padding):
SHA1_Init()
SHA1_Update(ipad, 64)
SHA1_Update(message, msg_len)
SHA1_Update(0x80, 1) ← 手动 padding 起始字节
SHA1_Update(0x00, 1) × N ← 手动逐字节零填充(N 次单独调用!)
SHA1_Update(length_field, 8) ← 手动长度字段
这导致了 202 次 SHA1_Update 调用(空内容情况下),而标准实现只需 3 次。这种做法可能出于以下目的:
-
反追踪:增加追踪日志的噪声,每个 padding 字节都是单独的 Update 调用 -
避免导出符号:不调用 SHA1_Final,避免在导出表中暴露该符号 -
CFF 兼容性:每个 Update 调用都经过 CFF 调度器,符合平坦化代码结构
11.2 SHA-1 轮常量的动态生成
标准 SHA-1 的四个轮常量:
K0 = 0x5A827999 (轮 0-19)
K1 = 0x6ED9EBA1 (轮 20-39)
K2 = 0x8F1BBCDC (轮 40-59)
K3 = 0xCA62C1D6 (轮 60-79)
这些常量没有存储在 .rodata 段中,而是通过 ARM64 的 mov/movk 指令对在运行时动态生成:
; ARM64 立即数拆分技术:加载 K0 = 0x5A827999
mov w8, #0x7999 ; w8 = 0x00007999(低 16 位)
movk w8, #0x5A82, lsl #16 ; w8 = 0x5A827999(高 16 位移位写入)
; 同理:K1 = 0x6ED9EBA1
mov w9, #0xEBA1
movk w9, #0x6ED9, lsl #16
; 同理:K2 = 0x8F1BBCDC
mov w10, #0xBCDC
movk w10, #0x8F1B, lsl #16
这就是为什么在二进制中搜索 \x99\x79\x82\x5A(K0 的小端序)找不到 SHA-1 特征的原因——常量从未以连续字节的形式存在于 SO 文件中。
11.3 SHA-1 初始向量验证
通过追踪 SHA1_Init 的输出确认了标准 IV,同时澄清了初期的 MD5 误判:
SHA1_Init 输出的 state(28 字节):
01 23 45 67 | 89 ab cd ef | fe dc ba 98 | 76 54 32 10 | f0 e1 d2 c3 | 00 00 00 00 00 00 00 00
├────────────────────────── h0-h4(20 字节)──────────────────────────┤├── 计数器(8 字节)──┤
h0 = 0x67452301 (存储字节序:01 23 45 67)→ 标准 SHA-1 IV
h1 = 0xEFCDAB89 (存储字节序:89 ab cd ef)→ 标准 SHA-1 IV
h2 = 0x98BADCFE (存储字节序:fe dc ba 98)→ 标准 SHA-1 IV
h3 = 0x10325476 (存储字节序:76 54 32 10)→ 标准 SHA-1 IV
h4 = 0xC3D2E1F0 (存储字节序:f0 e1 d2 c3)→ 标准 SHA-1 IV(动态生成,不在 .rodata!)
误判解析:h0-h3 与 MD5 的前四个 IV 完全相同,这导致初期误认为是 MD5 算法。真正区分 SHA-1 与 MD5 的是第五个 IV
h4 = 0xC3D2E1F0——MD5 没有第五个状态字,而该值在 SO 文件中通过动态指令生成,无法被静态搜索发现,由此造成了”SHA-1 常量不存在”的错误结论。
十二、完整算法流程图
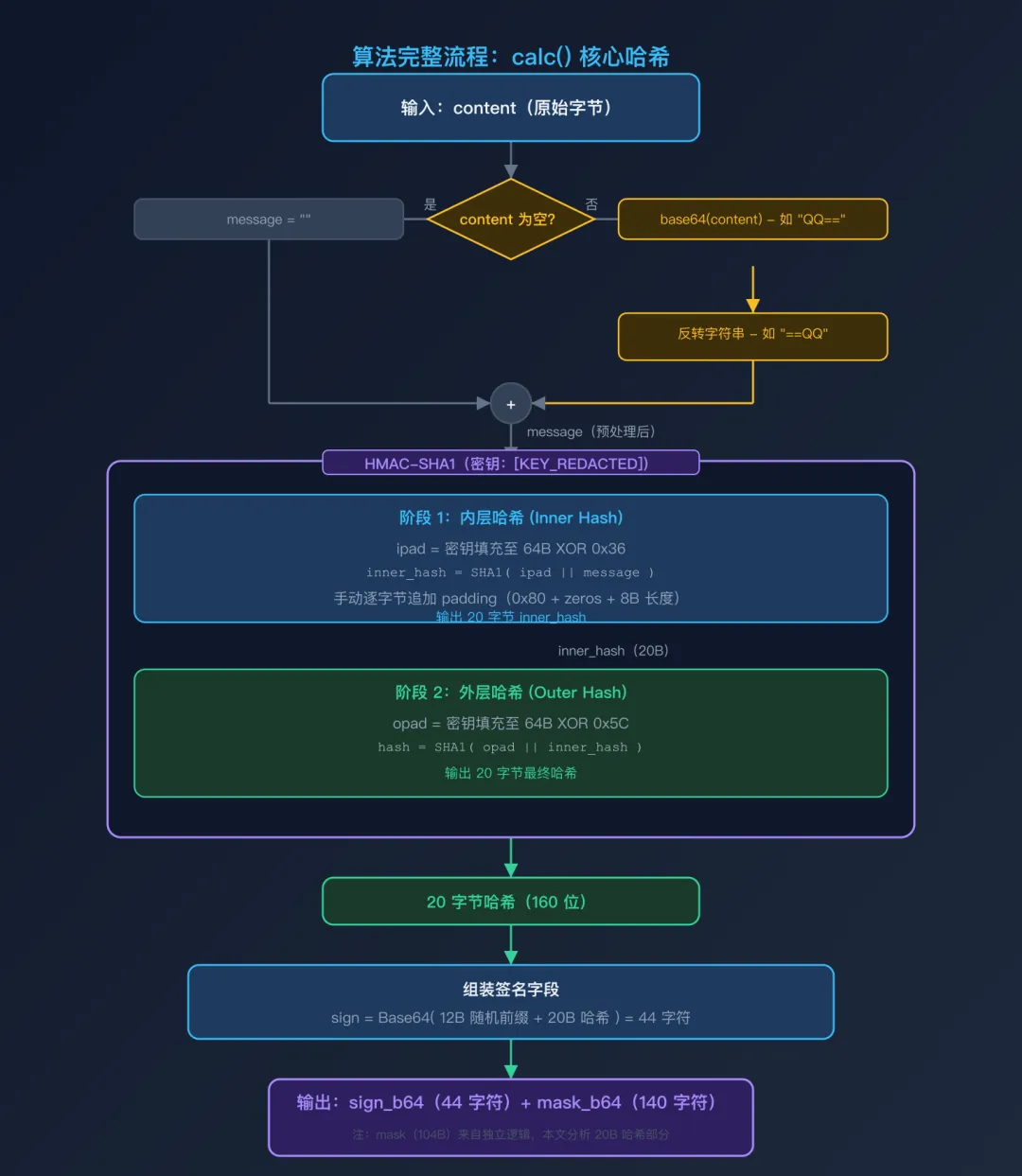
算法完整流程:calc() 核心哈希
流程图完整呈现了从原始 content 字节到最终 sign 字段的完整计算路径,包含:
-
消息预处理:content 是否为空的分支处理 -
HMAC 内层哈希:ipad XOR 密钥 + message 的 SHA-1 -
HMAC 外层哈希:opad XOR 密钥 + inner_hash 的 SHA-1 -
签名组装:12B 随机前缀 + 20B 哈希 → Base64
十三、各阶段时间投入与价值评估
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| SHA-1 内部追踪 | ~2h | 311 行 Python | 完整算法 | ★★★★★ 决定性突破 |
|
|
|
|
|
|
总计:~20 小时,约 35 个脚本文件,~4,000 行代码
关键教训:
-
Stalker 方向虽然失败但不可跳过——不尝试就无法知道它不行,6 小时的代价换来了明确的边界认知 -
最有效的方法是 Hook 底层密码学原语——CFF 混淆的是控制流,但无法改变数据流经密码学原语时的内容 -
收集足够的测试向量是验证任何假设的前提——17 组 I/O 对让最终验证无可置疑
十四、遇到的问题与解决方案汇总
14.1 工具链问题
|
|
|
|
|---|---|---|
|
|
python3
|
python3.10 安装了 frida 17.8.2 |
Memory.readByteArray
|
readByteArray 返回的 ArrayBuffer 不支持直接转换 |
readU8() 循环 |
--no-pause
|
|
resume() API |
14.2 动态分析问题
|
|
|
|
|---|---|---|
|
|
Process.findModuleByName("libmer.so") 返回 null |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
typeof Java === "undefined" |
|
14.3 分析方向问题
|
|
|
|
|---|---|---|
|
|
|
C3D2E1F0 |
|
|
|
mov/movk 动态生成 |
|
|
""、"mer" 等)不匹配 |
|
|
|
|
|
十五、防护评估
15.1 保护有效性
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
15.2 防护弱点
-
底层原语未保护:SHA1_Init/Update/Transform 虽然被内联,但仍作为独立函数存在,可以被 Hook -
HMAC 结构暴露:标准 HMAC 的两阶段结构(ipad/opad)通过追踪 SHA1_Init 的调用次数即可识别 -
密钥可从数据流提取:ipad/opad 块是明文传入 SHA1_Update 的,不需要逆向密钥的存储/生成方式 -
消息预处理太简单:base64 + 反转是可逆操作,追踪一次即可确认 -
固定密钥:密钥不依赖会话/设备/时间,一次提取永久有效
15.3 可能的加固建议
如果防御方希望增强保护强度:
-
将 SHA-1 原语也内联到 CFF 函数中,或使用自定义 SHA-1(修改轮函数/轮常量) -
使用设备绑定的动态密钥而非固定密钥(如结合 Android Keystore 或设备指纹) -
在 SHA-1 Update 中混入虚假数据(decoy writes),增加追踪分析难度 -
使用 anti-Frida 检测(检查 /proc/self/maps中的 frida-agent 映射) -
混淆消息预处理逻辑(当前 base64+反转过于简单,容易识别) -
考虑引入与请求内容相关的动态参数(时间戳、序列号等),使密钥或消息在每次请求中变化
十六、最终成果
16.1 纯 Python 离线实现
import hmac
import hashlib
import base64
# 注意:HMAC_KEY 已脱敏,使用者需自行通过 SHA-1 内部追踪方法提取
HMAC_KEY = b"XXXXXXXXXXXX"# 12 字节固定密钥(已脱敏)
defcalc_content_hash(content: bytes) -> bytes:
"""
计算 libmer.so calc() 的 20 字节内容哈希。
算法全貌:
1. 若 content 非空,先 base64 编码再反转字符串
2. 用固定密钥对处理后的消息做标准 HMAC-SHA1
3. 返回 20 字节摘要
Args:
content: 原始请求体字节(Deflate 压缩前的内容)
Returns:
bytes: 20 字节 HMAC-SHA1 摘要,对应 sign 字段的后 20 字节
"""
if content:
b64 = base64.b64encode(content).decode('ascii') # 标准 base64
message = b64[::-1].encode('ascii') # 反转字符串
else:
message = b""
return hmac.new(HMAC_KEY, message, hashlib.sha1).digest()
16.2 完整验证数据表
|
|
|
|
|---|---|---|
|
|
3382f2de07c5a7d07e33d579bc7532fd34f3f481 |
|
00 |
04490685e1a84ff684dfa836fcd0d5d03aa47eea |
|
01 |
a711df0b44cc29da61fd57a2411c5b154e731192 |
|
41 |
9bd44515e037cd55d7ad3a4486cb3126312dbf0b |
|
42 |
4a75fb3632110fbc26132324f50e745bedc07905 |
|
43 |
d047840454bd8ec078444a7335423e38882f3211 |
|
ff |
71d5047c2ef977f6ff6158ef152ccfd8a0f9ad61 |
|
0000 |
479427596eefc0873f679c4a450d159eac6f77db |
|
0001 |
4bee7d20ca16583c231e362518be8e827eb12f94 |
|
0100 |
374407fe31fdd4e0e5ed8683e6b8f89335b58ee6 |
|
4141 |
1448f64fb5f0a47674f9dcdb2f64385fda503e82 |
|
4142 |
30437f1b0d7cf4310809437a27d9e0fbe34a3cde |
|
41414141 |
6f7a0a0eb74bb0955838fd76d87bdf37387c2b2d |
|
41
|
46fc25ccfcfe26c749852f6f9408f603461e3ca6 |
|
41
|
cf1bc2753966646dadc44348e3d7c834baaa3148 |
|
41
|
b1209951162a6b6672a79dc3fd4483379d973f6c |
|
41
|
4bd3e65fc4b6bf970df36777bd9ac1ec63a4d68e |
|
17/17 全部通过
16.3 文件清单
|
|
|
|
|---|---|---|
calc_sign.py |
|
|
verify_hmac.py |
|
|
trace_sha1.py |
SHA-1 内部追踪器(关键突破工具) |
|
collect_pairs.py |
|
|
test_md5_hypothesis.py |
|
|
emu_hash.py |
|
|
cff_deobf_v2.py |
|
|
calc_pairs.json |
|
|
sha1_trace_results.json |
|
|
16.4 待完成工作
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
十七、总结
本次逆向分析历经 7 个阶段、约 20 小时、产出约 35 个脚本文件,最终完全还原了 libmer.so 中 calc() 函数的核心哈希算法。
最关键的一步是改变分析思路:从试图理解 CFF 混淆后的控制流(自上而下),转变为直接 Hook 底层密码学原语来观察数据流(自下而上)。CFF 混淆可以让代码不可读,但无法改变数据流经密码学原语时的内容。
算法最终被确认为标准 HMAC-SHA1,使用固定密钥和 base64 反转的消息预处理。整个保护方案的安全性主要依赖于 CFF 混淆带来的分析复杂度,而非算法本身的密码学强度。一旦找到正确的分析切入点(底层原语 Hook),算法的还原就变得相当直接。