 夜雨聆风
夜雨聆风





OpenClaw 老忘事?这个开源插件,终于把 AI 的“短期记忆”补上了
跟 OpenClaw 聊久了的人,大概都遇到过同一种烦躁。
前面明明已经说过一遍的项目背景、目录结构、约定好的命名规则,聊着聊着它就开始“失忆”了。你让它继续改一个文件,它忽然像刚进群一样,重新理解一遍上下文;你让它沿着之前的思路往下做,它又开始跑偏。最后最累的不是模型,而是你——一边开发,一边反复给它补课。
这事其实不新鲜,本质上还是上下文窗口有限。对话一长,旧信息要么被挤掉,要么被压缩得太狠,最先丢的偏偏还是那些最关键、但又不是每轮都会重复提到的细节。
OpenClaw 的作者显然也意识到了这个问题,所以最近推荐了一个挺实用的开源插件:ossless-claw。名字也很直白,就是想尽量“无损”地把上下文留住。
它的思路我觉得挺聪明,不是硬把所有聊天记录一股脑塞回模型里,那样 Token 很快就爆了。它做的是另一件事:把每条消息先持久化到 SQLite 里,再把旧消息逐步整理成树状摘要。
这个设计有点像你做项目时的工作笔记。
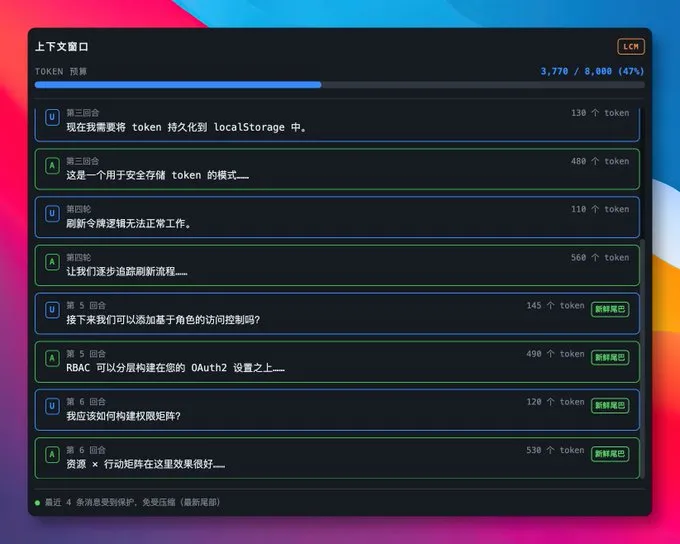
最新发生的事,先原样放着,方便随时调用;更早的内容,不是简单删掉,而是按主题和层级慢慢折叠起来。这样模型既不会被一大坨历史记录压垮,又不至于把前面聊过的重要信息忘得干干净净。
更有意思的是,它不只是在“存”。
为了让 AI 真能把丢掉的细节找回来,ossless-claw 还给它配了几种专门的检索工具,比如 lcm_grep、lcm_describe。前者更像是在聊天历史里做精准搜索,后者则适合快速概览某段记录到底讲了什么。你可以理解成,它一边帮模型做摘要,一边又给了模型一把回头翻档案的钥匙。
这点特别重要。
很多所谓“记忆方案”,最后只是把旧内容压缩成一段模糊总结。问题在于,摘要这种东西很容易把项目里那些真正有用的细枝末节抹平。比如某个函数为什么不能动、某个接口之前踩过什么坑,这些信息一旦丢了,AI 后面就很容易一本正经地帮你重复犯错。
而 ossless-claw 的想法更接近一个靠谱的工程习惯:摘要负责节流,原始记录负责兜底。
安装也不折腾。官方给的方式基本是一条命令就能接进去,而且可以自己调参数,比如保留最近多少条消息不压缩、聊到什么阈值开始触发整理。这种可调性挺有必要,因为不同人的工作流差别很大:有人是短平快提问,有人是真的拿它跑长链路开发,记忆策略肯定不能一刀切。
我会觉得,这类工具真正打中的,不只是“AI 会忘事”这个表面问题,而是大家开始把 AI 用进更复杂、更长期的任务里了。
以前问几个问题、写一段代码,忘了也就忘了。现在不少人已经在拿 AI 参与持续迭代的项目,帮忙读仓库、改模块、接着昨天的工作继续往下推。这时候,记忆能力就不再是体验优化,而是实打实影响可用性的基础设施。
说白了,一个总要你重复背景的 AI,不像搭档,更像实习生第一天上工。
所以如果你正在用 OpenClaw,或者本来也在折腾别的 AI 编程工具,又恰好被上下文限制烦得不轻,ossless-claw 确实值得装上试试。它未必能彻底解决“遗忘”,但至少给了一种更工程化、也更现实的处理方式:别指望模型天生记性好,先把记忆系统搭起来再说。
有时候,AI 能不能用得顺,不取决于它会不会思考,而取决于它还记不记得。
GitHub地址:martian-engineering/lossless-claw