 夜雨聆风
夜雨聆风





Codex App Windows 版高级教程(二):Subagent 手把手教你从用顺到真正高手
Codex 的 Subagent 功能在 3 月 17 号正式正式发布了。
实话说,这个功能我关注很久了——它解决的是一个很实际的问题:一个复杂任务,一个 Agent 干不过来,怎么办?
答案是:拆成多个 Agent,各自干各自的,最后汇总。
听起来简单,但怎么配、怎么用、怎么自定义,官方文档写得非常分散。这篇文章我把它捋成一条线,从”一句话试试”到”自定义专属团队”,全程给配置代码和 Prompt,你跟着做就行。
开始之前先说一下 config.toml
Subagent 的全局设置(并发数、嵌套深度等)是配在 config.toml 里的,自定义 Agent 的模型选择和沙箱权限也需要理解这个文件。如果你还不知道 config.toml 是什么、在哪,简单说一下:
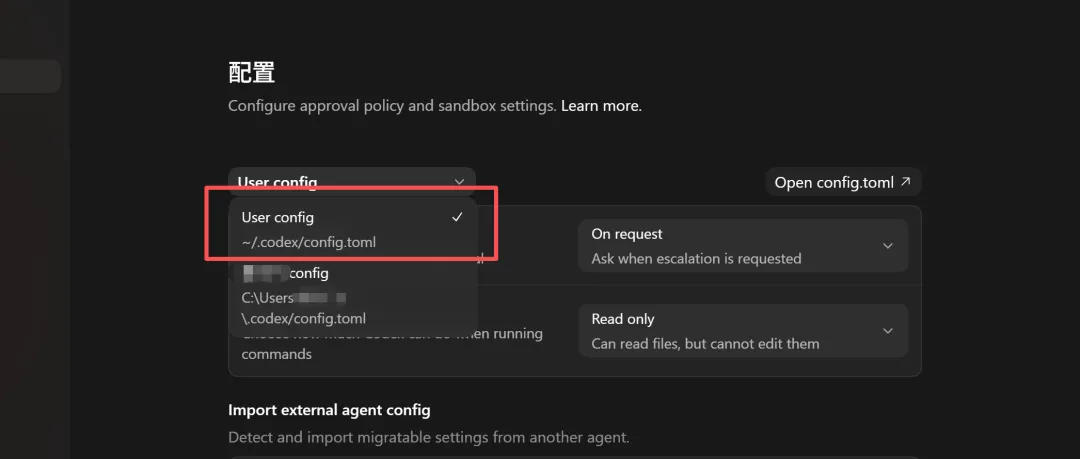
我这边出现两个是因为之前安装codex app 的时候做过codex_home目录的改动

现在我的 codex 的config.toml的目录位置在这个地方
个人级的在你的 CODEX_HOME 目录下(打开 Codex App 设置 > Open config.toml 就能找到),项目级的在项目根目录的 .codex/config.toml。后面会反复用到的几个关键配置项:model(用什么模型)、model_reasoning_effort(推理力度)、approval_policy(审批策略)、sandbox_mode(沙箱权限)。
开始之前可能会踩的坑
Subagent 本身不需要你手动开启,它是跟着你的 Prompt 指令自动启动的。但我一开始怎么试都不出来,而且菜单栏里的选项全都点不了。

一开始我还以为是自己 Windows 版本的问题,或者是 Codex App 更新没更新到位,排查了一圈都不是。最后发现原因是:本地状态文件里的云访问状态卡住了。
具体来说,Codex App 的全局状态文件 .codex-global-state.json 里有一个字段 codexCloudAccess,它的值卡在了 "enabled_needs_setup",导致 App 一直认为云端功能还没配置完成,Subagent 相关的能力全部不可用。
解决方法是打开 PowerShell,执行两条命令:
# 先备份,防止改坏没法回退Copy-Item "$env:CODEX_HOME\.codex-global-state.json" "$env:CODEX_HOME\backup-subagent-fix\.codex-global-state.json.manual.bak" -Force# 把卡住的状态改成正常(Get-Content "$env:CODEX_HOME\.codex-global-state.json" -Raw) -replace '"codexCloudAccess":"enabled_needs_setup"', '"codexCloudAccess":"enabled"' | Set-Content "$env:CODEX_HOME\.codex-global-state.json" -Encoding UTF8第一条是把当前的状态文件备份一份。第二条是读取 .codex-global-state.json,把 codexCloudAccess 从 "enabled_needs_setup" 改成 "enabled",再写回去。
改完之后重启 Codex App,菜单恢复正常了,Subagent 也能用了。
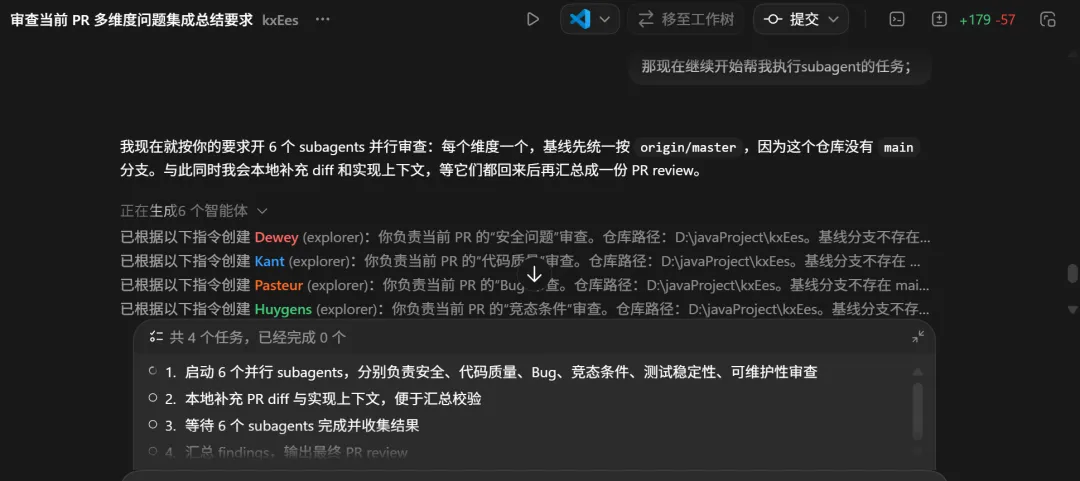
这个是codex app 里面通过提示词主要开启的subagent(内置的agent)
如果你的 Codex App 也是这样的症状——Subagent 死活不出来、菜单栏点不动——大概率也是这个原因。不是版本问题,不是系统问题,就是本地状态文件卡住了。
Subagent 到底在解决什么问题
先说个真实场景。
你让 Codex 帮你审查一批代码改动,一次性把安全、代码质量、测试覆盖率、性能全看一遍。单 Agent 的问题是什么?上下文污染。它一边看安全问题一边想着测试覆盖率,注意力会分散,容易漏东西。而且任务越多,上下文越长,模型输出质量越差——官方管这叫 “context rot”。
Subagent 的思路是:别让一个人干所有事。拆成几个专门的 Agent,一个只看安全,一个只看代码质量,一个只看测试。各自独立跑,跑完汇总。
这个细节值得注意——Codex 只在你明确要求时才会启动 Subagent。它不会自作主张地拆任务。你说”每个维度 spawn 一个 agent”,它才动。
一句 Prompt 体验 Subagent
不用配任何东西,打开 Codex App,找一个有代码改动的项目(当前分支相对 main 有改动就行,不需要 push),直接粘贴这段 Prompt:
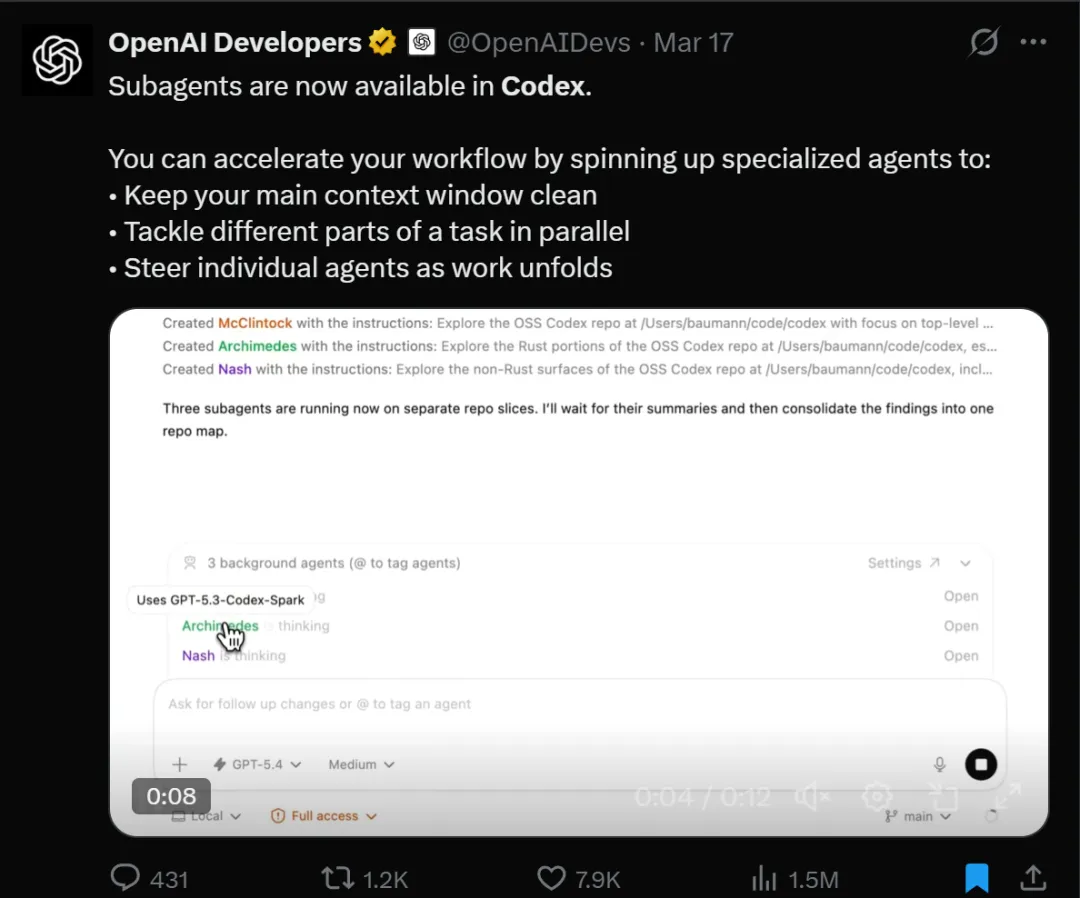
请对当前分支相对于 main 的改动进行以下几个维度的审查。每个维度 spawn 一个 agent,等所有 agent 完成后,汇总每个维度的结果。1. 安全问题2. 代码质量3. Bug4. 竞态条件5. 测试稳定性6. 代码可维护性发送之后你会看到 Codex 同时启动了 6 个子线程,每个线程只负责一个维度。
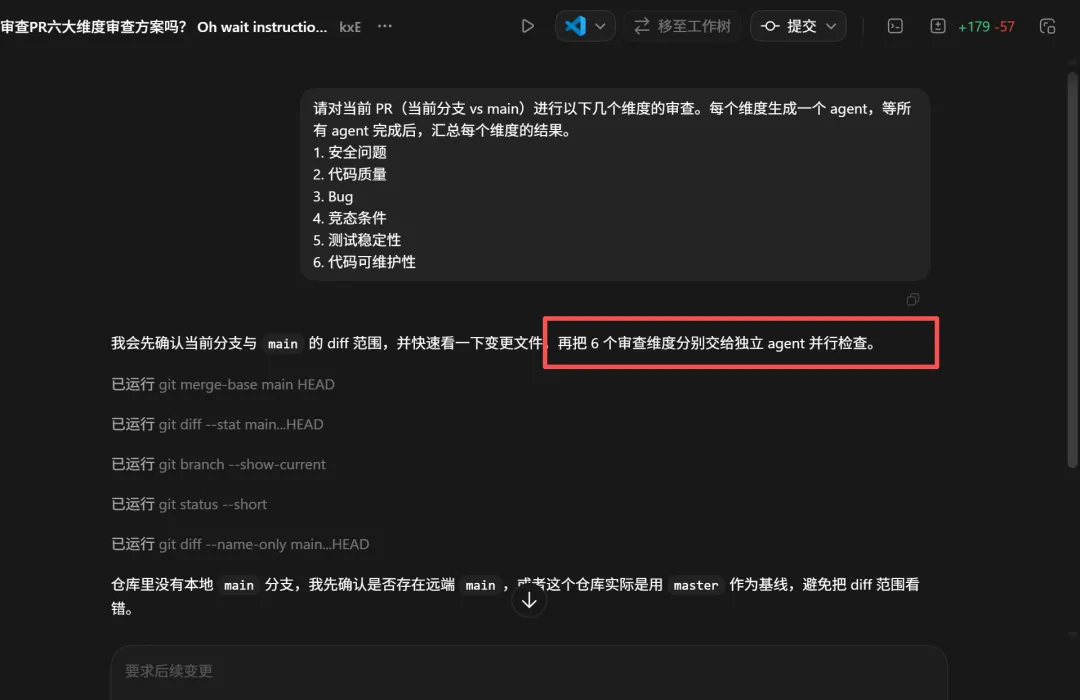
生成6个agent
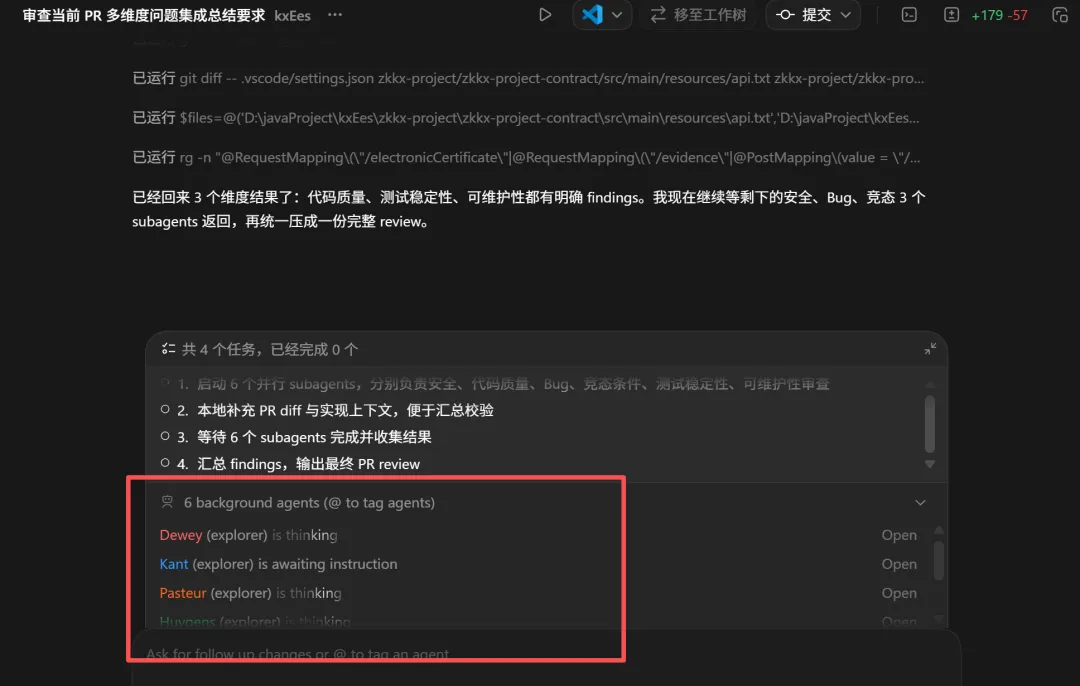
在同时并行
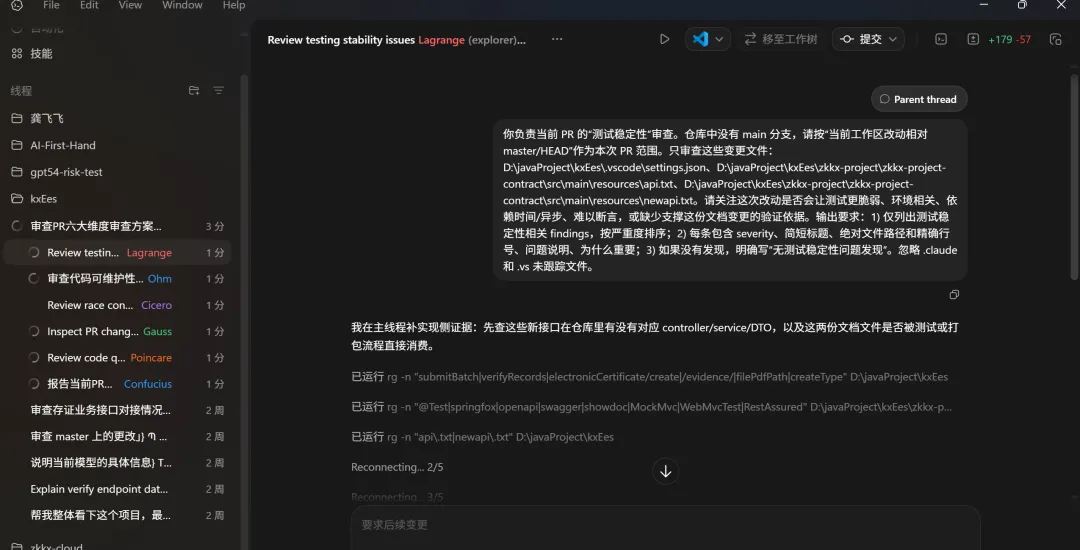
并且这个agent里面的提示词是codex app 根据你的主线程任务来自动生成的,所以这个是不可复制的agent,如果你有比较复用的agent功能的话,那就需要自定义agent了,下面会说。
等所有线程跑完,主线程会给你一个汇总报告。
这就是 Subagent 最基础的用法——不需要写任何配置文件,Prompt 里说清楚”每个点生成 一个 agent”就行。
如果你同时也在用 CLI,可以用 /agent 命令在运行中的线程之间切换,看每个 Agent 正在干什么。App 用户直接在左侧线程列表点击切换就行。
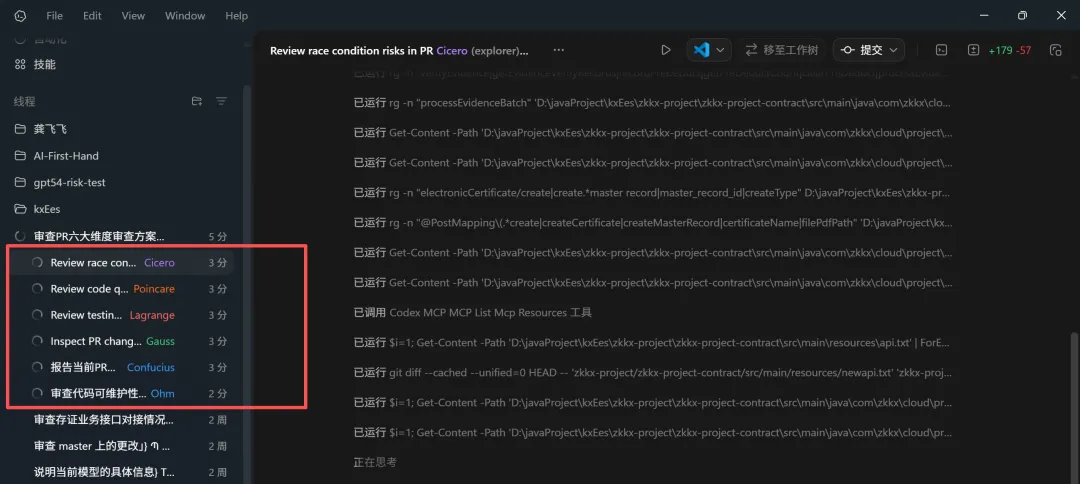
三个内置 Agent:default、worker、explorer
Codex 自带三个 Agent,不用配置就能用。
default ——通用型,什么都能干,是 Subagent 的默认选择。
worker ——执行型,适合跑大量重复性小任务。比如你有 50 个文件要逐一检查,worker 就是为这种场景设计的。
explorer ——只读型,专门用来读代码、看结构、搜文件。不会改任何东西,适合在动手之前先摸清状况。
实话说,default 和 worker 的边界不是特别清晰。我的理解是:单次复杂任务用 default,批量简单任务用 worker。后面讲 CSV 批处理的时候你会更明白 worker 的价值。
自定义 Agent:这才是 Subagent 真正的威力
内置的三个 Agent 能应急,但真正的生产力来自自定义 Agent。
你可能会问:Codex 已经有内置 Agent 了,为什么还要自己定义?
核心原因是复用。内置 Agent 是通用的,每次你都得在 Prompt 里写清楚”你要关注 SQL 注入、事务失效、缓存一致性…”这一大串要求。自定义 Agent 就是把这些要求固化到 TOML 文件里,配一次,以后每次只要在 Prompt 里说一句”让 java_reviewer 审查”就行了,不用重复写那一大段指令。
而且自定义 Agent 还能做到内置 Agent 做不到的事:给不同角色配不同的模型(侦察agent用便宜的 mini,审查agent用强的 5.4)、设不同的权限级别(侦察只读,修复可写)、甚至接不同的 MCP 工具。这些内置 Agent 全都做不到。
说白了,自定义 Agent 就是你团队的”岗位说明书”——写一次,反复用。
另一个常见疑问:配了自定义 Agent 之后,内置的 default、worker、explorer 还能用吗?能用。自定义 Agent 和内置 Agent 是共存的,不会互相替代。Codex 只在你 Prompt 里明确指名的时候才会调用自定义 Agent,没指名的话还是用内置的。唯一的例外是:如果你的自定义 Agent 的 name 和内置的同名(比如也叫 explorer),那你的版本会覆盖内置的。
文件放哪
自定义 Agent 是 TOML 文件,放在两个地方:
个人级(CODEX_HOME 下的 agents/ 文件夹)—— 所有项目都能用。
我的就是在这个目录下,你们可以根据自己的电脑环境来配置
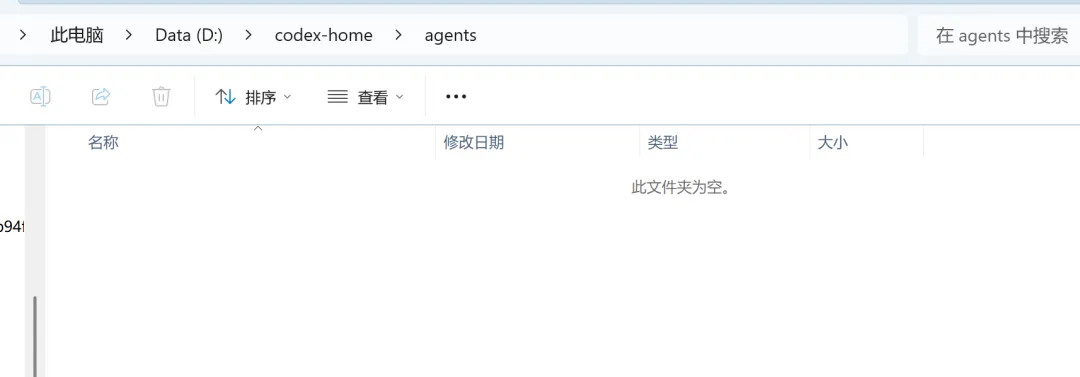
项目级(项目根目录下的 .codex/agents/ 文件夹)—— 只在当前项目生效。
个人级目录到底在哪?关键看你的 config.toml 在哪。最简单的确认方法:打开 Codex App 设置页,点右上角的 “Open config.toml”,看它打开的文件在哪个目录——agents 文件夹就建在 config.toml 的同级目录下。
举个例子,如果你的 config.toml 在 D:\Data\codex-home\config.toml,那个人级 Agent 文件就放 D:\Data\codex-home\agents\java-reviewer.toml。如果你没改过默认设置,config.toml 在 C:\Users\你的用户名\.codex\config.toml,那就放 C:\Users\你的用户名\.codex\agents\java-reviewer.toml。
java-reviewer.toml就代表是你的个人级的agent文件
注意看规律:agents 文件夹和 config.toml、skills、AGENTS.md 是平级的,都在 CODEX_HOME 根目录下。不需要额外套一层 .codex 目录。
项目级的就不一样了——必须放在项目根目录的 .codex/agents/ 下面。你的项目根目录下默认是没有 .codex 文件夹的,需要手动创建。Windows 下可以用 PowerShell 一行搞定:
# 在你的项目根目录下执行mkdir .codex\agents或者直接在文件资源管理器里右键新建文件夹,先建 .codex,再在里面建 agents。
所以完整路径举例:个人级 Agent 文件 D:\Data\codex-home\agents\java-reviewer.toml(和 config.toml 同级),项目级 Agent 文件 D:\Projects\my-app\.codex\agents\sql-analyzer.toml(在项目的 .codex 下面)。
如果你在 Codex App 里用的是 WSL 模式,路径就是 Linux 风格的 ~/.codex/agents/,跟 Windows 原生模式不共享。想共享的话需要在 WSL 里设 CODEX_HOME 环境变量指向 Windows 那边的同一个目录。
agents 文件夹不管是个人级还是项目级,都不会自动生成,需要你手动建。
每个 TOML 文件定义一个 Agent。文件名无所谓,Codex 认的是里面的 name 字段。
必填三件套
每个自定义 Agent 必须有这三个字段:
name = "你的Agent名字"description = "什么时候该用这个Agent(给Codex看的)"developer_instructions = """这个Agent具体要做什么、怎么做(核心指令)"""name 是 Codex 调用这个 Agent 的唯一标识。description 决定 Codex 什么时候会自动选它。developer_instructions 是它的行为准则。
可选但重要的字段
model = "gpt-5.4" # 用哪个模型model_reasoning_effort = "high" # 推理力度:low / medium / highsandbox_mode = "read-only" # 沙箱模式:read-only / workspace-write / danger-full-accessnickname_candidates = ["Atlas", "Echo", "Delta"] # 显示昵称(多实例时区分用)这些字段如果不写,就继承父会话的配置。
nickname_candidates 这个设计很细心——当你同时跑多个相同类型的 Agent 时,UI 上会显示不同的昵称(比如 Atlas、Echo),而不是一堆同名的”reviewer”。纯粹是为了你看得清楚,不影响功能。
实战配置一:Java 后端提交前代码审查
以下两套实战配置基于官方文档推荐的模板,针对 Java 后端开发场景做了调整。你拿到之后根据自己项目的实际情况改 developer_instructions 就行。
先说清楚一个容易搞混的点:这不是 GitHub 上那种 Pull Request Review,而是你 push 代码之前的本地审查。实际工作流是这样的——你在一个分支上写了代码,还没提交、没 push。这时候你想在提交之前先让 AI 帮你过一遍:有没有 SQL 注入、事务有没有问题、MyBatis 映射对不对、Redis 缓存会不会不一致。Codex 会对比你当前分支和 main 分支的差异,相当于你自己给自己做 Code Review。
为什么要在本地就审查?等代码都 push 上去了再发现问题,还得改了重新提交。在本地就审完,省得来回折腾。
为什么拆成两个 Agent
这里用了两个 Agent,一个是侦察兵agent,一个是审查官agent,你可能会想:两个 Agent 还不如一个搞定算了,何必这么麻烦?
实话说,如果你就想简单用,一个 Agent 完全能搞定代码审查。但拆成两个有两个实际好处:
并行跑更快。 一个 Agent 从头到尾又摸底又审查,时间是叠加的。两个同时跑,总时间取决于跑得慢的那个。项目大的时候差距很明显。
省钱。 侦察兵agent只是读代码梳理调用关系,用便宜的 mini 模型就够了。审查官agent需要理解业务逻辑判断有没有 bug,必须用强模型。拆开各配各的,比一个 Agent 全程烧强模型便宜。
先配全局设置
在你的个人级 config.toml 里加(就是 CODEX_HOME 下的那个,和 agents 文件夹同级的 config.toml):
[agents]max_threads = 6 # 最多同时跑 6 个线程max_depth = 1 # 子 Agent 不能再 spawn 子 Agent(防止递归爆炸)max_depth = 1 这个默认值别动。改大了容易出现 Agent 套 Agent 套 Agent 的情况,Token 消耗会指数级增长。
code_explorer:侦察兵
创建 agents/code-explorer.toml(个人级放 CODEX_HOME 下,项目级放 .codex/ 下):
name = "code_explorer"description = "只读的代码探索者,梳理改动范围和影响面。"model = "gpt-5.4-mini"model_reasoning_effort = "medium"sandbox_mode = "read-only"developer_instructions = """保持探索模式,不要修改任何代码。重点梳理以下内容:1. 这次改动涉及了哪些文件,影响了哪些 Service、Mapper、Controller2. 被改动的方法在其他地方有没有被调用,调用方会不会受影响3. 有没有改动 MyBatis 的 XML 映射文件,对应的 SQL 是否受影响4. 涉及的数据库表有哪些,有没有涉及跨表操作引用具体的文件路径和方法名,不要笼统地说"可能有影响"。"""
侦察兵用 gpt-5.4-mini 就够了,只读场景不需要最强模型。sandbox_mode = "read-only" 确保它不会手贱改文件。
java_reviewer:Java 后端主审官
创建 agents/java-reviewer.toml(同样,个人级放 CODEX_HOME 下,项目级放 .codex/ 下):
name = "java_reviewer"description = "专注于 Java 后端项目的代码审查者,关注安全、事务、SQL 和缓存问题。"model = "gpt-5.4"model_reasoning_effort = "high"sandbox_mode = "read-only"developer_instructions = """像有 5 年经验的 Java 后端 leader 一样审查代码。重点关注以下问题:安全类:- SQL 注入风险(特别是 MyBatis 里用了 ${} 而不是 #{})- 接口有没有做参数校验和权限控制事务类:- @Transactional 注解用得对不对,有没有事务失效的场景(比如 private 方法、自调用)- 长事务风险,有没有在事务里做 RPC 调用或者耗时操作数据类:- SQL 有没有性能问题(全表扫描、缺少索引、N+1 查询)- Redis 缓存和数据库的一致性有没有考虑(先删缓存还是先改库)- 并发场景下有没有竞态条件代码质量:- 异常处理是否合理(有没有吞异常、catch 了 Exception 没处理)- 空指针风险- 资源有没有正确关闭(数据库连接、IO 流)每个发现都要引用具体的文件和行号,给出修复建议。避免纯风格类评论。"""nickname_candidates = ["Reviewer-A", "Reviewer-B", "Reviewer-C"]
主审官用最强模型 gpt-5.4,推理力度拉满。developer_instructions 里列了 Java 后端最常踩的坑——SQL 注入、事务失效、缓存一致性、N+1 查询。这些是你日常开发中真正会出问题的地方。
启动审查
配置完了,用一句 Prompt (注意提示词里面需要特定指出自定义的name,也就是你刚刚配置的name)就能调度:
审查我当前分支相对于 main 分支的所有改动。让 code_explorer 梳理这次改动的范围和影响面,java_reviewer 从安全、事务、SQL 性能和缓存一致性等角度找出风险点。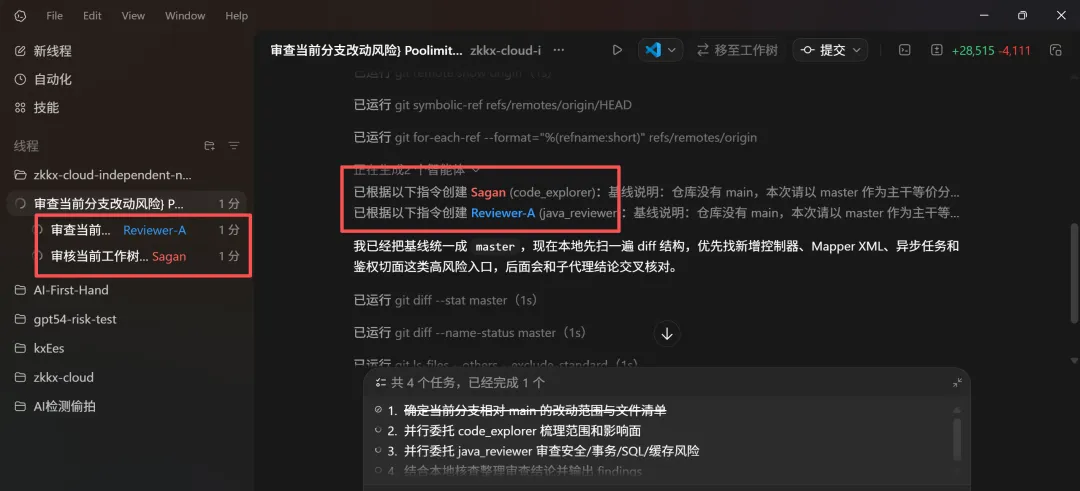
Codex 会同时启动两个 Agent,各自在自己的线程里干活,完了自动汇总一份审查报告。你看完觉得没问题,再 commit 和 push。
实战配置二:Java 后端 Bug 并行排查
后端 Bug 排查是 Subagent 另一个很实际的场景。你遇到一个线上 bug 或者测试反馈的问题,日志翻半天找不到原因——这时候让多个 Agent 同时从不同角度排查,比你一个人从头到尾翻要快得多。
先说清楚一个边界:这些 Agent 做的是静态代码分析,不是运行时调试。它们只能读你项目里的源代码,不会连你的 Redis 看缓存数据,也不会连 MySQL 查表。它们做的是:读你的代码逻辑,判断写法有没有问题——比如缓存更新顺序对不对、SQL 拼接有没有漏洞、异常有没有被吞掉。相当于一个经验丰富的同事帮你 review 代码找 bug,而不是帮你登服务器查日志。
这里的关键是:所有 Agent 都是并行的,各查各的,最后汇总结论。修复是你看完排查结果之后再决定怎么改的事情,不放在并行流程里。
三个角色,三个角度,同时开跑:
call_chain_tracer:调用链追踪者
创建 agents/call-chain-tracer.toml(个人级放 CODEX_HOME 下,项目级放 .codex/ 下,下面两个同理):
name = "call_chain_tracer"description = "只读的调用链追踪者,从入口到数据库梳理完整的代码执行路径。"model = "gpt-5.4-mini"model_reasoning_effort = "medium"sandbox_mode = "read-only"developer_instructions = """从 Controller 入口开始,追踪完整的调用链:Controller → Service → Mapper → SQL重点梳理:1. 请求参数在每一层是怎么传递和转换的2. 有没有条件分支导致某些场景走了不同的代码路径3. 涉及哪些数据库表,执行了哪些 SQL(看 MyBatis XML 映射)4. 有没有异步操作或者 MQ 消息发送5. 异常处理逻辑里有没有吞掉异常(catch 了但没 log)输出完整的调用链路图,引用具体的类名、方法名和文件路径。不要修改任何代码。"""
sql_analyzer:SQL 分析者
创建 agents/sql-analyzer.toml:
name = "sql_analyzer"description = "专门分析 MyBatis SQL 映射文件,找出 SQL 逻辑错误和性能问题。"model = "gpt-5.4"model_reasoning_effort = "high"sandbox_mode = "read-only"developer_instructions = """只关注 SQL 相关的问题:SQL 正确性:1. 读 MyBatis XML 映射文件,分析 SQL 逻辑是否正确2. 动态 SQL(if/choose/foreach)的条件判断有没有边界问题3. 参数传递有没有用错(${} vs #{})4. UPDATE/DELETE 语句有没有漏 WHERE 条件的风险SQL 性能:1. 有没有全表扫描、缺索引的查询2. 有没有 N+1 查询(循环里调数据库)3. 大 IN 查询有没有做分批4. 批量插入有没有用 foreach 而不是逐条 insert如果能定位到具体问题,指出是哪个 XML 文件哪个 SQL id。不要修改任何代码。"""
SQL 分析用 gpt-5.4,因为理解复杂的动态 SQL 条件判断需要强推理。
cache_checker:缓存一致性检查者
创建 agents/cache-checker.toml:
name = "cache_checker"description = "专门检查 Redis 缓存逻辑,找出缓存和数据库不一致的问题。"model = "gpt-5.4"model_reasoning_effort = "high"sandbox_mode = "read-only"developer_instructions = """只关注缓存相关的问题:缓存一致性:1. 写操作是先删缓存还是先改库?顺序对不对?2. 有没有缓存和数据库双写不一致的场景3. 缓存 key 的构造逻辑是否正确,会不会出现 key 冲突4. 缓存有没有设过期时间,过期时间是否合理缓存异常场景:1. 缓存穿透(查不存在的数据,每次都打到数据库)2. 缓存击穿(热 key 过期瞬间大量请求打到数据库)3. 缓存雪崩(大批 key 同时过期)4. 并发场景下有没有竞态条件引用具体的代码位置和缓存 key 构造逻辑。不要修改任何代码。"""
启动并行排查
比如测试反馈”用户修改个人信息后,页面显示的还是旧数据”,你可以这样启动:
排查"用户修改个人信息后页面显示旧数据"的问题。让 call_chain_tracer 从 UserController 的 updateUserInfo 接口开始追踪完整调用链,sql_analyzer 分析相关的 MyBatis SQL 逻辑有没有问题,cache_checker 检查 Redis 缓存的更新逻辑是否正确。三个同时跑,跑完汇总结论。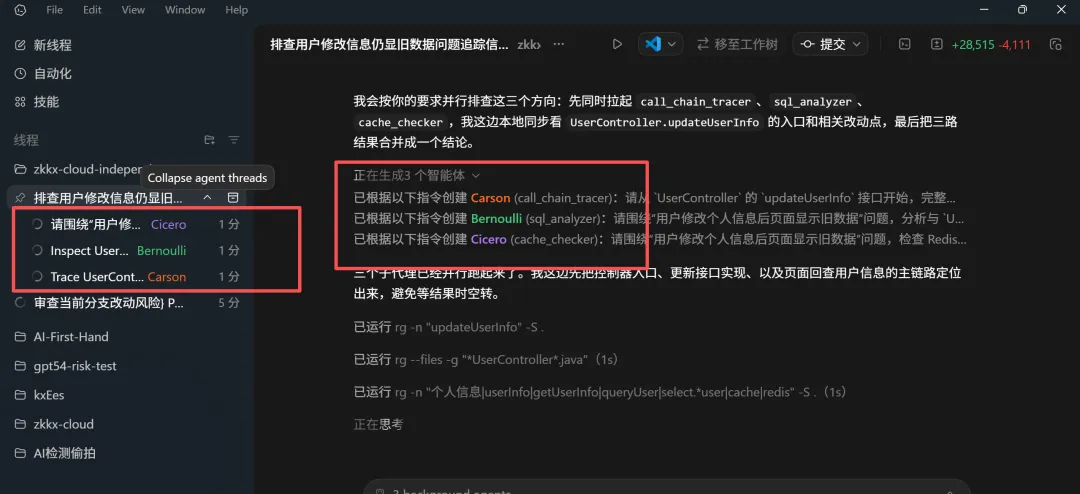
三个 Agent 同时从不同角度排查:一个看代码怎么走的,一个看 SQL 对不对,一个看缓存一不一致。这种”显示旧数据”的问题,大概率缓存那个 Agent 能最快找到原因。
排查完之后怎么修?看完汇总报告,你确认了问题原因,再单独跟 Codex 说”帮我修一下这个缓存更新逻辑”就行。修复是下一步的事情,不需要放在并行排查流程里。
进阶玩法:CSV 批量任务
前面两套配置的思路是”几个不同专家同时审一份代码”——侦察兵agent看调用链、审查官agent看安全风险,各司其职。
CSV 批量任务的思路完全不一样,它是”同一个审查员同时审几十份代码”。你不需要定义自定义 Agent,Codex 有一个内置工具叫 spawn_agents_on_csv:你给它一个 CSV 文件,每一行是一个待处理的文件,Codex 自动为每一行 spawn 一个内置的 worker Agent,所有 worker 做同样的事情(你在 Prompt 里定义),只是处理的文件不同。
这个功能还在实验阶段,但对批量审查的场景非常实用。
场景:你的项目有几十个 Service 类需要逐一审查,比如检查有没有事务注解用错、有没有吞异常。手动一个个喂给 Codex?太慢了。spawn_agents_on_csv 可以一次性把 CSV 里的每一行变成一个独立的 Agent 任务,并行跑完后导出一份汇总报告。
操作步骤
直接给 Codex 一个 Prompt,让它自己创建 CSV 然后批量跑:
先扫描项目里所有的 Service 类,创建 /tmp/services.csv,包含 path 和 module 两列(module 根据包名推断)。然后调用 spawn_agents_on_csv:- csv_path: /tmp/services.csv- id_column: path- instruction: "审查 {path}({module})。重点检查事务注解是否正确、有没有吞异常、SQL 有没有性能风险。通过 report_agent_job_result 返回包含 path、risk_level、problems、suggestions 字段的 JSON。"- output_csv_path: /tmp/services-review.csv- output_schema: 包含 path、risk_level、problems、suggestions 四个必填字符串字段的对象如果你不想让 Codex 自己扫描,也可以手动准备 CSV 文件,格式像这样:
path,modulesrc/main/java/com/example/service/UserService.java,用户模块src/main/java/com/example/service/OrderService.java,订单模块src/main/java/com/example/service/PaymentService.java,支付模块src/main/java/com/example/service/ProductService.java,商品模块准备好之后把 Prompt 里”先扫描项目…”那句去掉,直接从”调用 spawn_agents_on_csv”开始就行。
Codex 会为 CSV 里的每一行 spawn(拉起) 一个 worker Agent,并行跑完后导出结果到 /tmp/services-review.csv。导出的 CSV 里会包含原始数据加上 job_id、status、result_json 等字段。(我项目服务比较多暂时就不做演示,这是更高进阶的功能,大家根据需要来使用)
关键限制
每个 worker 必须调用 report_agent_job_result 一次来报告结果。如果 worker 没报告就退出了,那行会被标记为 error。
超时设置:默认每个 worker 1800 秒(30 分钟)。可以在 config.toml 的 [agents] 里改 job_max_runtime_seconds,也可以在每次调用时通过 max_runtime_seconds 覆盖。
沙箱和审批:Subagent 的安全边界
这块容易被忽略,但很重要。
先说清楚 sandbox_mode 的三个级别——Codex App 的 UI 上显示了”默认权限”和”完全访问权限”两个选项,对应关系是这样的:
"read-only" → 最严格,只能读文件,不能改任何东西。App UI 上没有直接对应的选项,只能通过 TOML 配置。
"workspace-write" → 对应 App 里的”默认权限”,能读能写项目目录下的文件,超出项目范围的操作会弹窗请求你确认。
"danger-full-access" → 对应 App 里的”完全访问权限”,完全不限制,什么都能干。
这就是为什么自定义 Agent 有价值——TOML 配置里多了一个 read-only 级别,App UI 上选不到。你可以给侦察兵和分析者设 read-only(连项目文件都不让它改),而不是所有 Agent 都开”完全访问权限”。
Subagent 继承父会话的沙箱策略。你在主线程里设的权限级别,子 Agent 也会遵守。即使自定义 Agent 文件里写了不同的默认值,运行时你在 App 或 CLI 里临时调整的权限设置会覆盖它。
不过反过来也成立:你可以在自定义 Agent 里主动收紧权限。比如你主线程开了 workspace-write,但侦察兵的 TOML 里写了 sandbox_mode = "read-only",侦察兵就只能读不能写。收紧可以,放宽不行。
如果你同时也在用 CLI:子 Agent 需要审批时,会在你当前线程弹一个审批提示,显示是哪个线程发的请求。按 o 可以跳到那个线程看详情。App 用户会直接在对应线程看到审批弹窗。
模型选择的省钱策略
Subagent 的 Token 消耗是倍数级的——6 个 Agent 并行,就是 6 倍的 Token。所以模型选择很关键:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
如果你是 ChatGPT Pro 用户,侦察兵可以换成 gpt-5.3-codex-spark,速度会更快。不是 Pro 用户的话,gpt-5.4-mini 就是最佳的轻量选择。
核心原则:不是每个 Agent 都需要最强模型。按职责分配算力,该省省该花花。
全局配置参考
把所有 Subagent 相关的全局设置汇总一下,放在你的个人级 config.toml(CODEX_HOME 下的那个)的 [agents] 部分:
[agents]# 最大并发线程数,默认 6max_threads = 6# Agent 嵌套深度,默认 1(子 Agent 不能再 spawn 子 Agent)# 除非你明确需要递归委派,否则别改这个max_depth = 1# CSV 批处理每个 worker 的超时时间(秒),默认 1800job_max_runtime_seconds = 1800如果你的自定义 Agent 的 name 和内置 Agent 同名(比如也叫 explorer),你的自定义版本会覆盖内置的。
什么时候该用 Subagent,什么时候不该
适合用的场景: 提交前代码审查(多维度并行审查)、Bug 排查(多角度并行分析代码逻辑)、批量代码审计(CSV 批处理)、大型重构的前期调研(多个 explorer 同时摸底)、多文件迁移(每个文件一个 worker)。
不适合用的场景: 简单的单文件修改(一个 Agent 就够了,别浪费 Token)、强依赖顺序的任务(A 必须等 B 完成才能开始,并行没意义)、上下文高度关联的分析(拆开反而丢信息)。
Subagent 不是万能的。它的核心价值在”并行”和”隔离”,如果你的任务天然不是并行的,硬用 Subagent 反而增加复杂度和成本。
完整文件结构一览
最后给一个完整的文件树,方便你照着建:
# 个人级(你的 CODEX_HOME 目录,和 config.toml 同级)# 通过 Codex App 设置 > Open config.toml 确认位置D:\Data\codex-home\ (或默认的 C:\Users\你的用户名\.codex\)├── config.toml # 全局配置├── AGENTS.md # 全局指令├── skills\ # Skills 目录└── agents\ # 个人级自定义 Agent(手动新建) ├── code-explorer.toml └── java-reviewer.toml# 项目级(你的项目根目录下,手动新建 .codex\agents\)D:\Projects\your-project\├── .codex\│ ├── config.toml # 项目级配置(项目特有的设置)│ └── agents\ # 项目级自定义 Agent(手动新建)│ ├── call-chain-tracer.toml│ ├── sql-analyzer.toml│ └── cache-checker.toml├── AGENTS.md # 项目规范(Subagent 也会读)└── ...个人级的 Agent 所有项目通用(比如代码审查的侦察兵和审查官)。项目级的 Agent 只在当前项目生效(比如针对特定项目的 Bug 排查三人组)。两边有同名的,项目级优先。
不想自己写?去抄现成的
GitHub 上已经有人整理好了大量现成的 Subagent 配置,直接下载复制到你的 agents 目录就能用:
Codex 原生格式(TOML): GitHub 上搜 codex subagents,有不少仓库整理了上百个覆盖不同场景的 Agent 配置,从代码审查到安全扫描到重构都有。
Claude Code 格式(Markdown): https://github.com/VoltAgent/awesome-claude-code-subagents ,这个是给 Claude Code 用的,格式是 Markdown 不是 TOML,不能直接用在 Codex 里,但里面的 instructions 思路可以参考,改成 TOML 格式就行。
自己写 Agent 配置的核心其实就是写好 developer_instructions——这些开源仓库最大的价值就是给你提供 instructions 的灵感和模板。
写在最后
Subagent 这个功能,核心就一句话:把一个人干不好的事,拆成多个专家各干各的。
配置不复杂——每个 Agent 就是一个 TOML 文件,几行代码的事。但选对模型、写好 instructions、控制好安全边界,这些细节决定了效果。
我建议的上手路径:先用内置 Agent 跑一次代码审查,觉得好用,照着”代码审查两人组”的配置抄一份,然后根据你自己的项目特点调整 developer_instructions,等批量任务场景出现了再试 CSV 批处理。
以上觉得有用的话,关注下、点个赞或收藏、转发给你需要的朋友,如果想第一时间收到推送,也可以给我个星标⭐ 谢谢你看我的文章,下次见。