 夜雨聆风
夜雨聆风





OpenAI Codex 文档看了一遍,发现多数人根本没用对
很多人第一反应都是:Codex 能不能直接改代码?能,当然能。可要是理解只停在这儿,那它最有意思的那部分,基本就被你错过了。
这两天把 OpenAI 官方的 Codex 文档从头到尾过了一遍。看完之后最强烈的感觉不是“这工具又多了哪些功能”,而是很多人一开始理解它的角度就偏了。
不少人现在说起 Codex,还是会把它归到“高级代码助手”这一类里。这个说法不能算错,但说轻了。
OpenAI 想做的,明显不只是一个会在编辑器里补代码的工具。他们想推的,是一个能进到真实工程流程里的代理。它不只是回答你“这段该怎么写”,而是真的能围着项目干活:看仓库、读上下文、跑命令、改文件、看 diff、接 GitHub,甚至接自动化。

先别急着问它多能写,先看它站在哪个位置上
如果只看表面结果,Codex 当然也能写代码、改 bug、补测试。这些能力大家都关心,也最容易被拿来做演示。
但看完文档后最大的感受,不是“它又会多写几个功能”,而是它站的位置变了。
它不是站在某个函数旁边,替你补两行;它是站在整个工程流程里,想把一段完整工作接过去。
这个差别其实非常大。
因为“让一个模型补代码”和“让一个代理处理一段真实开发任务”,压根不是一回事。前者比拼的是单点生成,后者考验的是上下文、边界、工具、流程、协作方式,甚至还有你团队本身的工程习惯。
再说直白一点:
Codex 真正有意思的地方,不是“它比别的 AI 更会写代码”,而是“它开始像一个能进工作流的人”。
为什么很多人第一次用 Codex,会觉得“好像也就这样”
因为用法往往从一开始就偏了。
很多人第一次用,往往就是先扔一句:
-
帮我修这个 bug -
帮我重构这段代码 -
帮我给这个项目加个功能
然后结果一会儿好、一会儿飘,就会下意识觉得是模型不行。
但从官方文档看,Codex 的设计思路恰恰不是“你随便扔一句,它就稳定替你做完”。它更像一个刚接手任务的工程同事。你给它的信息越像真实交接,它表现得就越像回事;你给它的信息越像随口一说,它就越只能猜。
所以文档里反复讲的那几个词,prompt、context、sandbox、subagents,看着像术语,其实都在讲一件事:
你得把它当成一个要进入项目现场的执行者,而不是聊天机器人。
真正决定体验的,往往不是模型参数,而是上下文
这一点我觉得特别值得单独说。
现在不少人评估 AI 工具,还是习惯先问:模型强不强?代码能力怎么样?多模态支不支持?
这些当然重要,但放到 Codex 身上,只看这些已经不够了。
Codex 很吃上下文,而且不是一般地吃。
你只说一句“修 bug”,它也能做,但大概率是在猜。你把下面这些东西给到位,它就会靠谱很多:
-
这个问题出现在哪个目录 -
报错怎么复现 -
哪些行为不能变 -
哪些文件可以动,哪些别碰 -
改完要怎么验证
这也是为什么我看完文档后,反而更能理解 OpenAI 为什么一直强调 AGENTS.md、Skills、MCP、配置文件这些东西。
因为他们想解决的,不是“单次对话里再聪明一点”,而是“它下次再来这个项目时,能不能少走弯路”。
Codex 最像人的地方,不是会写,而是能接流程
文档里把 Codex 分成几个入口:App、IDE、CLI、Web。乍一看像是不同终端形态,细想其实是在对应不同工作场景。
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这里真正值得注意的,不是谁喜欢哪个界面,而是这几个入口背后都有一个共同假设:
Codex 不只是来回答问题的,它是来接任务的。
比如在 App 里,它不是单纯开个聊天框,而是直接把 Review、Git、Worktree、Automations 这些都塞进来了;在 CLI 里,它不是只给你一个对话壳,而是给了 codex exec 这种明显面向脚本和流水线的入口;到了 Web 这一层,甚至已经在认真讨论环境、网络权限、GitHub 联动这些真正上线后才会碰到的问题。
这其实已经说明得很清楚了:它从设计上就不是一个“写几段代码就结束”的产品。
真正适合 Codex 的,不是“灵感型提问”,而是“交付型任务”
如果你问我,看完文档后最明显的使用建议是什么,我会先说一句很实际的话:
别拿 Codex 去做那种特别轻飘的提问,优先拿它去接有交付边界的任务。
比如这些场景,它通常更容易发挥:
-
帮新同事快速看懂一个仓库 -
解释一个模块为什么老出问题 -
沿着错误日志追调用链 -
在明确约束下修一个 bug -
给 PR 做一轮有上下文的 review -
把重复流程沉淀成可重复执行的能力
也就是说,越接近真实工程协作,它反而越有价值。
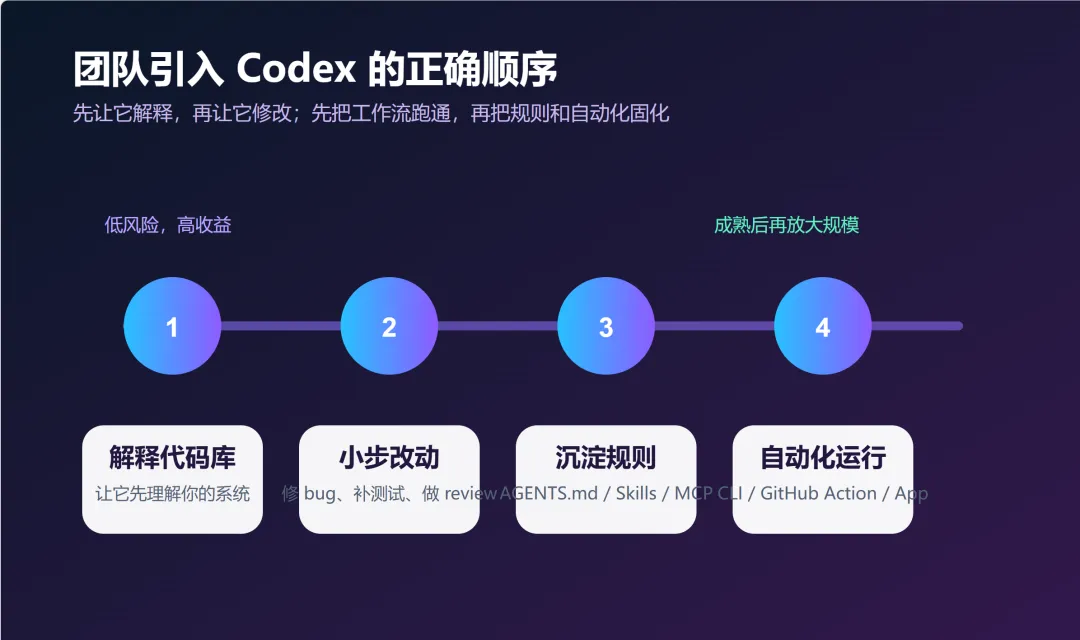
如果是团队第一次上 Codex,该怎么起步
如果是一个团队第一次引入 Codex,反而不建议一上来就冲着“自动改代码”去。
更稳的顺序大概是这样。
第一阶段:先让它解释
别急着改,先看它理解得怎么样。
你可以先让它做这些事:
-
解释项目里最关键的模块 -
讲清楚一个请求是怎么走的 -
总结某块代码的主要风险 -
说出它觉得这个仓库最需要补的规则
这一步看起来没那么炫,但其实最值钱。因为你会很快知道,它到底是真的读懂了,还是只是在表面上说得像懂。
第二阶段:让它做小而明确的改动
等你确认它对项目基本有感觉了,再把任务推进到:
-
修一个边界明确的 bug -
给一个函数补测试 -
帮你 review 某个 PR -
先出计划,再按计划动手
这一阶段不是追求它替你干完所有事,而是先把协作节奏跑顺。
第三阶段:把经验固定下来
如果某些提示反复有效,就不要每次重说了,直接写进:
AGENTS.md-
Skills -
MCP -
项目级配置
这是很多团队最容易忽略的一步,但其实最关键。因为它决定了 Codex 会不会越用越顺,而不是每次都像重新认识一遍你的项目。
第四阶段:最后再谈自动化
到了这一步,再去接:
codex exec-
GitHub Action -
App 里的 Automations -
云端任务
顺序为什么不能反?因为自动化不是把一段模糊需求定时运行,而是把一套已经被验证过的工作流稳定复用。
说到底,自动化的前提不是“模型够强”,而是“任务边界够清楚”。
哪些团队会最先吃到红利
我自己的判断是,如果一个团队有下面这些特点,Codex 的收益通常会来得比较快:
-
仓库大,新人上手慢 -
PR 多,Review 压力重 -
修 bug 和补测试特别占时间 -
工具链已经比较规范,至少 Git 流程是清楚的 -
团队有不少重复性的工程动作,值得标准化
反过来,如果一个团队连最基本的目录约定、测试习惯、评审方式都还没成型,那 Codex 当然也能用,但效果多半不会太稳定。因为它接不住一个本来就很松散的流程。
我看完文档后,最认同的一点
不是某个功能,不是某个模型,也不是哪个界面。
而是 OpenAI 对 Codex 的那个隐含判断:AI 编程工具真正往前走,不会只是“生成得更像人”,而是“开始进入真实的软件生产过程”。
这句话听起来有点大,但拆开看其实很具体:
-
它要知道项目规则 -
它要理解权限边界 -
它要能和 Git、PR、Issue、Slack 打通 -
它要能在必要时被审查、被回滚、被约束 -
它最好还能把经验沉淀下来,下次继续用
做到这一步,AI 才不是漂在开发流程外面的外挂,而是真的往流程里长进去了。
最后说个很实用的起手式
如果你准备第一次认真试 Codex,我不建议上来就说“帮我写个功能”。
我更建议你先发这样一句:
先别改代码。先告诉我,这个仓库最重要的模块是什么、最容易出问题的地方在哪,以及如果以后长期用 Codex,这个项目最该补哪几条规则。
这句话的好处是,它一下子把 Codex 拉到了更对的位置上:不是让它表演,而是让它进入工作。
结尾
看完这一整套文档后,我对 Codex 最直接的判断反而变简单了。
它当然是个很强的编码工具,但如果只把它当编码工具,反而有点可惜。
它真正值得关注的地方,是它已经不太像一个“辅助你写代码的功能”,而更像一个开始参与工程协作的角色。
这件事一旦成立,后面变化的就不只是写代码的效率,而是团队分工、代码评审、自动化,甚至整个研发流程的组织方式。
ps: 这是codex自己写的文章,这跟龙虾也差不多了