 夜雨聆风
夜雨聆风





claude code初体验:一个小工具烧了800万token
今天的工作节奏还算友好,没有那么多火急火燎的事情。趁着这点空闲,我终于把心心念念的Claude Code搭建了起来。
说实话,安装过程实在没啥技术含量。网上教程早就烂大街了,跟着复制粘贴几条命令,敲一下回车,就算搞定了。这年头,工具的门槛越来越低,真正卡住人的,从来不是安装,而是后续的“粮草”——大模型本身。
既然Claude的API贵得让人肉疼,我这次把目光投向了性价比之选:智谱的GLM-4.7。刚注册,系统就大方地送了我500万token。
500万! 看着这个数字,我瞬间有种“暴发户”的错觉,心里暗爽:这下够我折腾一阵子了吧?
一切就绪,那就开干
我想做个有意思的小工具:前端界面上,让用户选择一个年代,再简单描述一个场景,然后输入一句话。大模型要模仿那个时代的人说话风格给出回答;与此同时,根据年代和场景,调用豆包生成一张匹配的图片。
我把这个需求丢给了Claude Code,它转悠了半天,吐出了一堆代码。我按照文档指引跑起来,结果却有点尴尬——大模型回答的语气不太对味,豆包生成的图片更是跟想象差了十万八千里。
不过没关系,这才是常态。我像教一个聪明但没经验的新人,一点点跟Claude Code沟通:“语气再复古一点”、“场景描述要再具象一些”、“图片风格要贴近那个年代的质感”……
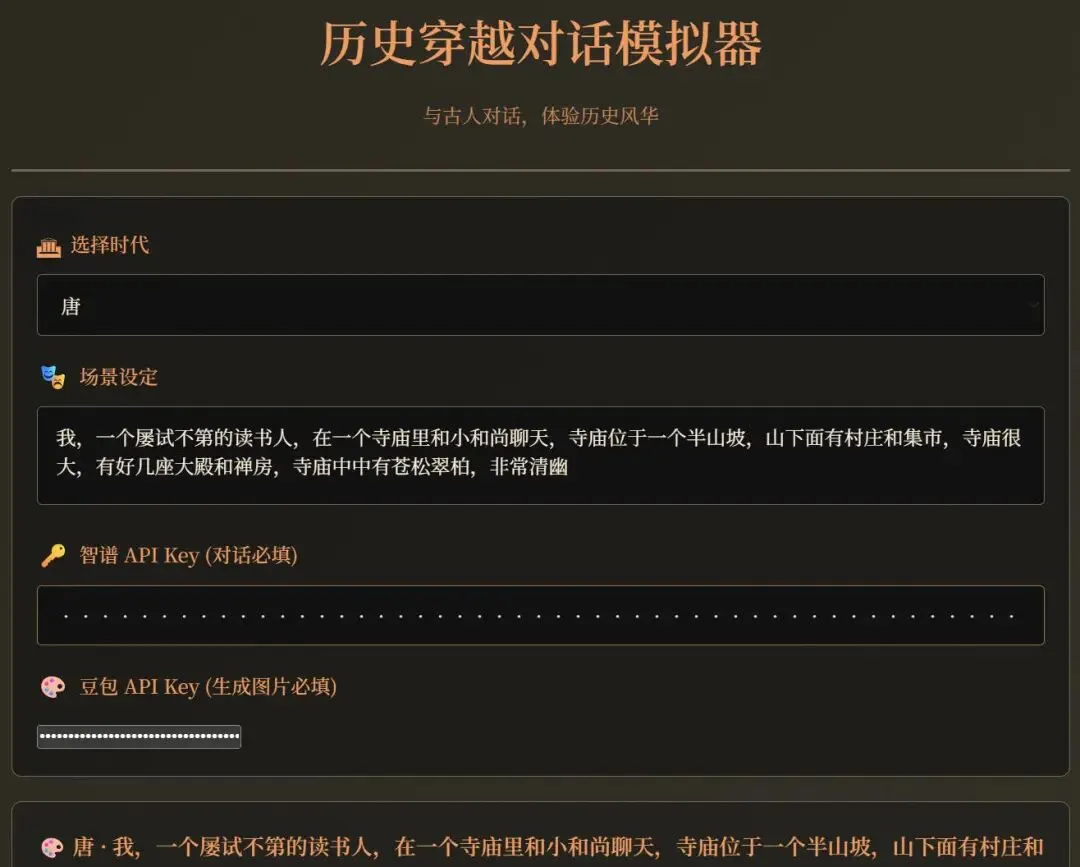
改了几轮之后,工具慢慢有了点样子,界面顺眼了,回答也开始有那么点“穿越”的味道了。我正调试得起劲,屏幕右上角突然弹出一条告警:
“Token 余额不足。”
我愣住了。这才多久?那可是500万token啊!我赶紧去后台看了一眼消耗记录,那一行行密密麻麻的调用记录,像极了一张失控的购物小票。
原来,在AI的世界里,500万也不过是几轮深度对话、几次反复调试的代价。工具还没完全打磨好,免费的“粮草”已经耗尽了。
没办法,只能咬牙续费,又消费了300万流量之后,勉强把工具磕磕绊绊地搞了出来。

成本这盘账,越算越清醒
工具虽然跑通了,但仔细一盘算,心里有点不是滋味。
除了大模型那边的token消耗,图片这块更狠。为了追求效果,我选了豆包的生图接口,一张图片两毛五。虽然看着单价不高,但架不住调试过程中一遍遍地生成,几十张图跑下来,几十块钱就没了。
说实话,这次体验让我对“大模型生态”有了更直观的感受。发展到现在,表面上是技术的比拼,是算法的炫技,但落到我们这些普通开发者和用户头上,本质就是资源的比拼,说白了,就是烧钱。
我们这些想用AI做点事的人,就像是闻声赶来的淘金客。大家听说这里能挖出金子,兴致勃勃地扛着新铲子跳进来。结果发现,铲子确实是好铲子,比当年的铁锹快多了,但卖铲子的人已经布好了局——按次收费、按量计费,你挖得越起劲,他赚得越稳妥。
我们想用这把新铲子挖出点属于自己的东西,可还没等挖到金子,卖铲子的已经开始收割了。
一点感想
技术的进步,确实让很多曾经不敢想的事变得触手可及。哪怕是一个普通开发者,花几个小时就能搭出一个跨时空对话的小工具,这在几年前是不可想象的。
但与此同时,成本的焦虑也如影随形。流量如流水,token如散沙,当我们沉浸在创造的乐趣中时,账户余额的数字却在悄悄流逝。
这大概是这个时代所有技术尝鲜者共同的困境:我们站在巨人肩膀上看得更远了,但想站稳,就得一直给巨人付租金。
不过话说回来,抱怨归抱怨,工具最后还是搞出来了。看着它能够按照用户的需求,用老北京的语气聊着天,配上一张颇有年代感的泛黄图片,那一刻,还是觉得这钱花得值。
毕竟,有些尝试的代价,总要有人先付。但愿下一次,能把这把“铲子”用得再聪明一点,效率再高一点,争取在被收割完之前,先挖到属于自己的那块金子。
后记:
如果你也在折腾AI应用,建议一定看好账户余额。800万token听起来很多,但经不起调试时的反复试错。 有时候,最贵的不是大模型本身,而是我们在“调通”路上交的学费。
