 夜雨聆风
夜雨聆风





2026最新AI编程工具推荐之Claude Code使用教程
根据2026年最新的市场数据、技术评测及开发者反馈,AI编程工具市场已从单纯的“代码补全”进化为“智能体(Agent)驱动”的全流程开发。
2026 全球综合排行榜 (Top 5)
这份榜单基于代码理解深度、多文件编辑能力、自主执行任务(Agent)能力及生态整合度加权评分。
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2026 中国本土优选榜 (特别推荐)
考虑到网络稳定性、中文语境理解、数据合规及免费/低成本因素,国内开发者应重点关注以下工具:
1. 🥇 字节 Trae (首选推荐)
- 优势:
- 原生中文支持:对中文注释、需求文档的理解准确率高达95%以上。
- 完全免费:目前对个人开发者完全免费,且提供高速模型(如豆包大模型)。
- Builder模式:输入一句话需求,直接生成完整项目结构,甚至能预览前端页面。
- 无缝迁移:兼容VS Code插件体系,上手零成本。
- 适用场景:快速原型开发、国内业务系统、个人项目。
2. 🥈 百度 文心快码 (Comate)
- 优势:
- 企业级落地:在C++、Java等企业级语言上表现优异,SPEC模式有效减少幻觉。
- 私有化部署:支持企业内部私有化部署,数据安全有保障。
- 深度集成:与百度智能云生态深度绑定。
- 适用场景:大型企业、对数据安全敏感的团队、传统后端开发。
-
3. 其他
1. 智能体能力 (Agentic Capability)
- Claude Code: 👑 最强。它不是一个插件,而是一个运行在终端的独立智能体。你可以让它“把支付模块从Stripe迁移到支付宝”,它会自动读取代码、修改文件、运行测试并报告结果。
- Cursor: 🥈 很强。通过Composer功能,可以选中多个文件进行统一修改,但在自主执行外部命令(如运行测试脚本)上略需人工确认。
- Copilot: 🥉 中等。主要聚焦于单文件或当前上下文的补全,多文件协同能力正在追赶(Copilot Workspace),但尚未普及。
2. 中文理解与本地化
- Trae / 文心快码: 🇨🇳 原生优化。能精准理解“高并发”、“幂等性”等中文技术术语,生成的注释和变量名符合国内规范。
- Claude Code / Cursor: 🌐 良好。虽然模型强大,但对纯中文需求的理解偶尔会出现偏差,且受网络环境影响大(需配置代理或国内镜像)。
3. 成本与门槛
- 免费梯队: Trae (目前免费)、通义灵码 (基础版免费)、CodeLlama (开源本地部署)。
- 付费梯队: Cursor ($20/月), Claude Code (按Token计费,较贵), GitHub Copilot ($10/月)。
Claude Code的安装和使用
-
解决网络访问问题
"hasCompletedOnboarding": true // 此项可跳过初始网络检查2. 修改配置文件:
-
获取中转 Key:从国内可信的 AI 服务商处获取 API Key(通常以 sk- 开头)。
-
找到配置文件
~/.claude/settings.json(Mac/Linux) 或%USERPROFILE%\.claude\settings.json(Windows)。如果没有该文件,先运行一次claude让它生成,或者手动创建。 -
填入配置:
{"ANTHROPIC_BASE_URL": "https://你的中转商域名/v1","ANTHROPIC_AUTH_TOKEN": "sk-你的中转商Key","ANTHROPIC_DEFAULT_SONNET_MODEL": "claude-sonnet-4-5-20260101"}
Claude Code 的这三种工作模式——Plan 模式、自动编辑模式(常被称为 Auto 或 Edit 模式)和 Yolo 模式。
这三种模式本质上代表了 AI 在编程协作中自主性(Autonomy)与安全性(Safety)之间的不同权衡点。
以下是这三种模式的深度解析与对比:
1. 🧠 Plan 模式:谋定而后动(架构师视角)
这是最安全、结构化的模式,适合处理复杂任务或你不希望 AI 乱改代码的场景。
核心逻辑:
-
只规划,不执行。完全只读状态,生成详细执行计划而不修改文件
-
输出结构化方案(含步骤说明、涉及文件、命令清单)至 plan.md
激活方式:
连续按两次 Shift+Tab
-
你提出需求(如“重构用户认证模块”)。 -
Claude 会先进行深度思考,生成一份详细的待办事项列表(TODO List)或执行计划。 -
它会列出要修改哪些文件、使用什么技术栈、步骤顺序如何。 - 关键点
:在你点击“批准”或输入“yes”之前,它绝不会修改任何一行代码。
适用场景:
-
复杂功能开发(如架构重构、数据库迁移)
-
关键生产文件修改前的方案预审
特色功能:
-
自动切换高性能模型(如 Opus 4.6)进行深度分析
-
通过 CLAUDE.md 沉淀规划知识,优化长期记忆
2. ✍️ 自动编辑模式:人机协作(编程视角)
自动执行文件读写操作,无需逐项确认编辑请求,这是 Claude Code 的默认模式,也是日常开发中最常用的模式。它在效率和可控性之间取得了平衡。
核心逻辑:
-
边做边问(Ask before edits)。自动执行文件读写操作,无需逐项确认编辑请求。
-
仅对 Shell 命令仍需手动批准(如运行测试、安装依赖)
激活方式:
会话中按一次 Shift+Tab 切换
工作流程:
-
你提出需求(如“重构用户认证模块”)。
-
Claude 会先进行深度思考,生成一份详细的待办事项列表(TODO List)或执行计划。
-
它会列出要修改哪些文件、使用什么技术栈、步骤顺序如何。
-
关键点:在你点击“批准”或输入“yes”之前,它绝不会修改任何一行代码。
适用场景:
-
日常的 Bug 修复、功能添加。
-
你需要把控代码细节,但不想写具体实现。
-
大多数标准的编程任务。
优势:效率显著提升,减少人工干预环节
3. 🚀 Yolo 模式:极速狂飙(全托管视角)
“Yolo”是“You Only Live Once”的缩写,在这个语境下意味着“后果自负,全权委托”。这是为追求极致效率而设计的模式。
核心逻辑:
-
直接执行,无需确认。
-
跳过所有权限确认,自由执行文件操作与 Shell 命令
-
内置安全层拦截高风险行为(如删除生产数据)
激活方式:
启动时添加命令行参数 –dangerously-skip-permissions
工作流程:
-
你提出需求。
-
Claude 跳过所有确认步骤,直接创建文件、修改代码、甚至运行 Shell 命令(如 npm install)。
-
关键点:它不会停下来问你“行不行”,而是直接干完,最后告诉你结果
适用场景:
-
从零搭建新项目(脚手架生成)。
-
简单的、重复性的批量修改。
-
你在容器或虚拟机中操作,即使出错也能一键重置。
-
大规模代码库重构(需严格隔离环境)
-
项目记忆:保存在项目根目录下的 CLAUDE.md,保存项目的架构、技术栈和开发规范等,可以提交到 Git 与其他成员共享,仅在当前项目中生效
-
用户记忆:保存在用户空间的 ~/.claude/CLAUDE.md,一般保存用户个人的偏好设置,在所有项目中生效
-
企业记忆:保存在 Claude 部署目录下( /Library/Application Support/ClaudeCode/Claude.md),存放公司级的安全、合规要求,由管理员配置
三个文件的加载顺序是:企业 → 项目 → 用户,后面的配置会覆盖前面的。因此,你的个人偏好拥有最高优先级!
/init 命令初始化、/memory 命令直接编辑,以及通过 # 操作符写入。使用 /init 初始化
在项目根目录打开 Claude,然后输入 /init 命令,Claude 会自动分析你的项目,并创建一个包含基本信息的 CLAUDE.md 文件。
使用 /memory 编辑
任何时候你都可以在 Claude 对话窗口输入 /memory 命令,它会直接在编辑器里打开 CLAUDE.md 文件,让你进行更详细的编辑和整理。
但是新版的/memory命令已经发生了更新,有了配置自动记忆的开关,如下图:
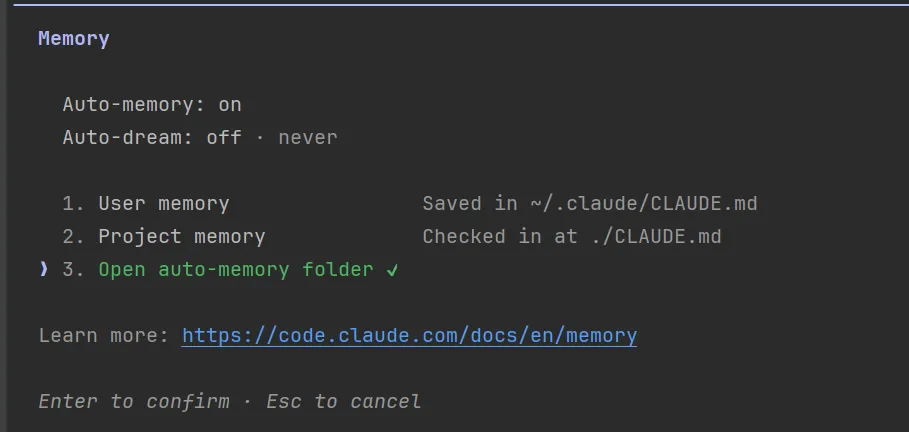
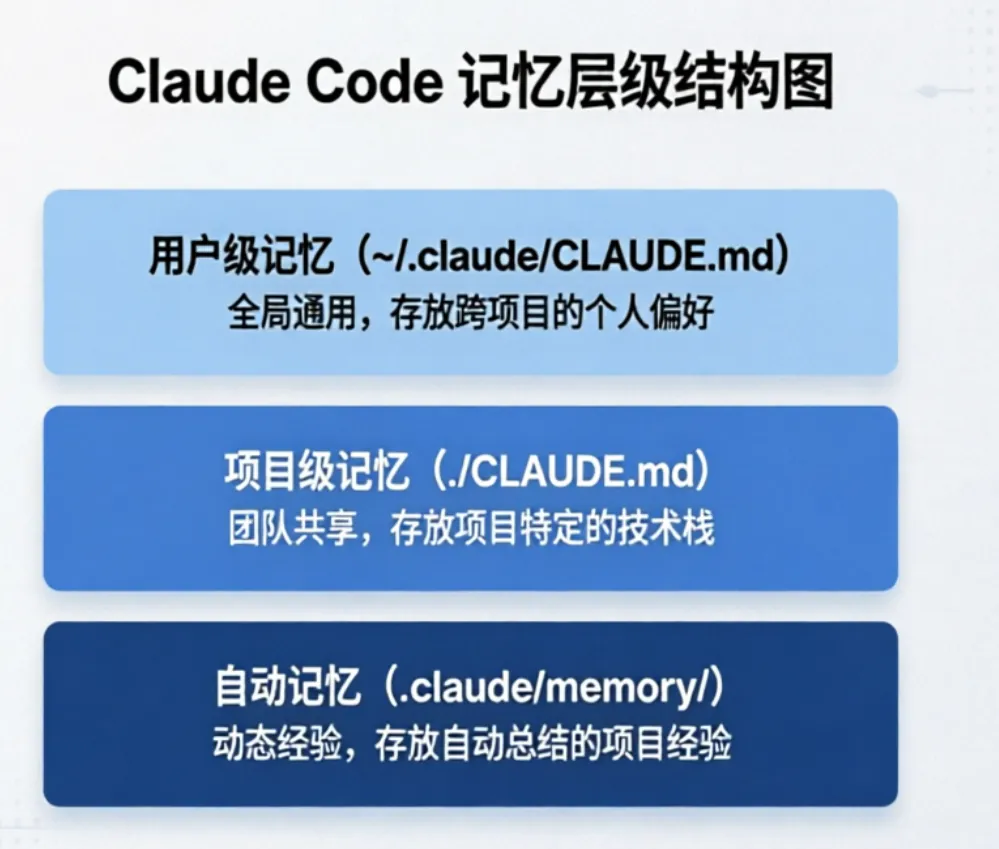
既然企业记忆我们一般不能编辑,那么新的CLAUDE.md文件分类可以如下理解:
三种记忆层级的配置
- User memory(用户级记忆)
存储路径: ~/.claude/CLAUDE.md作用:保存跨项目的个人偏好、通用编码习惯、工具链选择等全局规则。 - Project memory(项目级记忆)
存储路径: ./CLAUDE.md作用:保存当前项目特定的技术栈、构建命令、团队规范、目录结构等,是团队协作和项目上下文的核心。 - Open auto-memory folder(自动记忆文件夹)
作用:点击可打开自动记忆的存储目录(通常位于 .claude/memory/),查看 AI 自动归纳的项目经验、排障记录、高频操作模式等。
Claude Code 的记忆系统是其区别于传统代码助手的核心能力之一。它不再只是“一次性回答”,而是通过 用户级(个人习惯)、项目级(团队规范)、自动级(AI 自主学习)三层结构,构建出一个持续演进的“工作记忆”。
-
用户级确保你每次打开项目都能延续自己的编码风格。 -
项目级确保团队成员共享统一的开发规范。 -
自动级则让 AI 越用越懂你,比如它会记住“你上次调试这个接口时用了 Redis”,下次会自动提醒或复用该上下文。
实用建议
保持 CLAUDE.md 精简:记忆内容会被塞入系统提示词,过长会导致上下文溢出。建议将细节拆分到独立文件,主文件只保留核心规则。
定期检查自动记忆:虽然 AI 会自动归纳,但建议偶尔打开 .claude/memory/ 文件夹,确认是否有错误或冗余信息。
善用项目级记忆:在新项目启动时,第一时间在项目根目录创建 CLAUDE.md,写入技术栈、启动命令、目录说明,能极大提升 AI 的响应质量。
这个界面不仅是配置工具,更是你与 AI 协同开发的“大脑中枢”。用好它,Claude 就不只是一个代码生成器,而是一个真正懂你、懂项目的“开发伙伴”。
模块化记忆
如果项目过于复杂,CLAUDE.md 可能会变得臃肿。此时可以使用 @ 导入语法,将其他文件的内容引入 CLAUDE.md,实现记忆的模块化管理。
各层级的记忆的管理
OK,不管是项目级别记忆,还是个人级别记忆,都要保证CLAUDE.md精简,尽可能的抽象。项目记忆,init后,尽量保持原样不要更改,里面保存了项目的架构结构、业务领域模块,服务API集成点、命名约定等等内容。
- 文件臃肿:文件会变得巨大,难以阅读和维护。
- 上下文溢出:Claude 的上下文窗口是有限的。如果 CLAUDE.md过大,会挤占宝贵的上下文空间,导致它“忘记”当前正在处理的代码文件,或者无法处理更复杂的任务。
- 噪音干扰:不相关的历史细节会干扰 AI 对当前任务的判断。
为什么“驳杂记忆”会让Agent变得不专业?
角色冲突:负责“SQL优化”的Agent需要记住的是:数据库结构、索引策略、慢查询日志、执行计划分析技巧。负责“拆解业务逻辑”的Agent需要记住的是:领域驱动设计(DDD)原则、业务术语表、用户故事、模块划分规范。如果把这两套记忆混在同一个CLAUDE.md里,当AI被要求“拆解业务逻辑”时,它可能会突然想起“索引优化”的知识,开始给你建议加索引,这就会让它的回答偏离角色定位,显得不专业。提示词污染:每个Agent的核心是它的“系统提示词”,即“你是一个XXX专家”。如果记忆文件里混杂了大量无关信息,这些信息会和系统提示词“打架”。AI在理解任务时,会受到无关记忆的干扰,导致它无法完全沉浸在“XXX专家”的角色中。
所以,开启了自动记忆之后,还需要自己手动将自动记忆文件拆解为各个独立文件(也可以通过对话,让AI帮你通过某种角度的分类来拆解)而调用了不同的Agent之后,需要通过对话,让它加载特定的记忆文件。
AI 预设一个角色它会更加擅长处理我们的任务,这是为什么呢?
预设角色能让AI更高效、更专业地完成任务,因为它本质上是在为AI创建一个“工作身份”和“思维框架”。就像你在公司里不会让同一个人既当产品经理又当法务审计还兼着设计师,AI也一样——角色越清晰,产出越精准。
这背后的原理主要有三点:
-
认知聚焦:人类专家解决问题时,会调用领域特定的思维模式。AI 通过角色设定模拟这种认知框架。当你告诉AI“你是一位资深前端工程师”,它会自动激活与该角色相关的知识体系、术语习惯和思维方式,避免输出泛化或偏离专业语境 。
-
减少上下文污染:技术本质:LLM 是“上下文模式匹配器”,Claude 这类大模型没有真正的意识或身份,它的核心能力是:根据输入的上下文(prompt),预测最可能的下一个词序列。当你提供角色设定时,你实际上是在塑造上下文的语义分布。如果在同一对话中反复切换任务类型(比如一会儿写代码、一会儿写文案),AI的思维容易混杂。而通过角色预设,尤其是像Claude中的Sub-agent机制,可以让不同角色在相对隔离的上下文中工作,主对话只负责调度 。
-
可复用性与团队协同:一旦定义好一个角色配置(如.claude/agents/test-engineer.md),整个团队都可以复用这个“AI员工”,保证输出风格和质量的一致性,相当于建立了AI层面的岗位说明书 。
所以Claude Code这样的系统会引入Sub-agent(子代理)概念——它把“角色”工程化、标准化,让AI协作更接近真实团队作业模式 。
Sub-Agent
为了防止混淆 Codex中的AGENTS.md文件和Claude Code中的sub-Agent文件,这里讲一下它们的区别。
AGENTS.md
它是 OpenAI 推动的跨厂商统一标准(旨在统一 .cursorrules、.agentrc 等碎片化配置)。它的核心作用是解决“AI 写的代码不符合团队规范”的问题。它是Agent 行为调度中枢,定义技能调用规则与任务执行逻辑,相当于 Agent 的“操作手册”。所以,AGENTS.md 中的内容一般是规范、约定、约束、校验标准。更像是一份工程合同或法律条文,定义了严格的边界和执行标准
Claude Code里面的没有AGENTS.md文件,与之对标的是CLAUDE.md文件,它是 Claude Code 的上下文提示文档。它的核心作用是解决“AI 记不住项目习惯”的问题。它告诉 Claude “在这个项目里,我们习惯怎么做”。比如“我们用 pnpm 而不是 npm”,“我们的 API 前缀是 /api/v1”。它更像是一个资深员工的经验笔记,包含了很多非强制性的最佳实践、避坑指南和项目背景知识。
但Claude Code中的sub-Agent不是规范约束、也不是经验背景,它是给智能体设置了一个身份角色。
1. 什么是 Sub-Agent?
Sub-Agent(子代理) 是 Claude Code 中的专门化 AI 助手实例。每个子代理运行在独立的上下文窗口中,拥有:
-
自定义系统提示 — 定义行为和专长
-
独立的工具权限 — 可限制只允许读取或只允许特定操作
-
隔离的对话历史 — 不会污染主对话的上下文
-
可选的持久记忆 — 跨会话积累领域知识
Sub-Agent(子代理)是专门处理特定类型任务的 AI 助手。在 Claude Code 的语境下,一个 sub-Agent = 专属系统提示词 + 独立的上下文(可以加载特定的记忆文件) + 特定的工具权限 + 指定模型(可选)。
在 Claude Code 中,一个 sub-Agent 并不是独立的进程,而是由以下三个核心要素构成的“临时专家身份”:
- 角色(Role):
通过系统提示词(System Prompt)定义,例如:“你是一位资深 SQL 优化专家”。 决定 AI 的思考方式和输出风格。 - 记忆(Memory):
通过专属记忆文件提供,例如 ./agents/sql_optimizer.md。决定 AI 的知识范围和经验积累。 - 上下文(Context):
由主 Agent 或用户显式加载相关文件和代码片段。 决定 AI 的当前任务和操作对象。
概念对比:
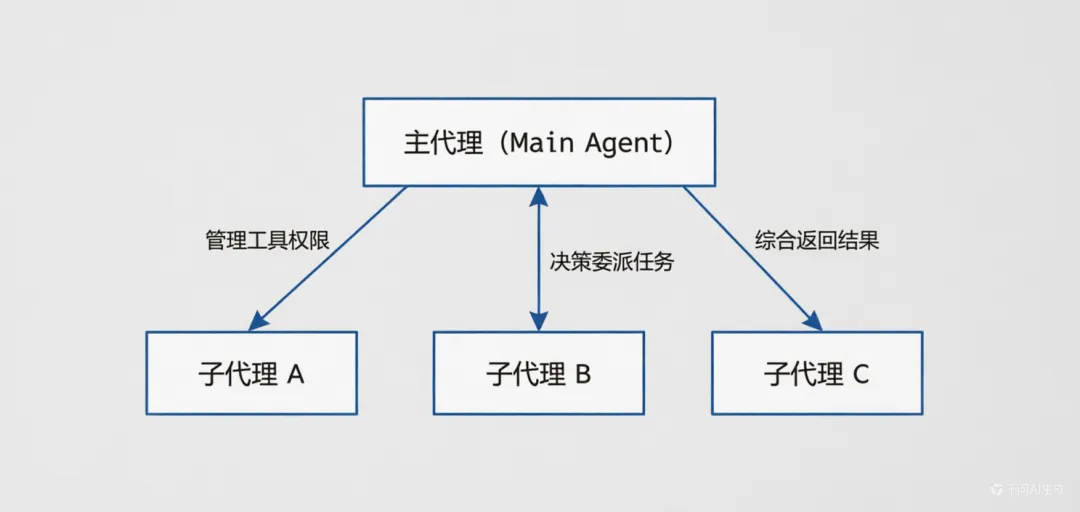
-
• Main-Agent(主代理):Claude 本身就是一个 Agent,我们可以理解为 Main-Agent。它是主要的上下文对话,有权限调用不同的 Tools、MCP、Skills 和 Sub-Agent,目的在于完成任务。 -
• Sub-agents(子代理):是任务委派。你召唤一个独立的、专业的 AI 分身去处理一个特定任务。它在独立的上下文中运行,拥有专属的工具权限,最终把结果返回给 Main-agent 进行处理。
为什么需要 Sub-Agent?
| 问题 | Sub-Agent 如何解决 |
|---|---|
| 主对话上下文膨胀 | 子代理在独立窗口中工作,只返回摘要 |
| 任务安全性 | 可限制工具(如只读模式),防止误操作 |
| 并行效率 | 多个子代理可同时运行不同任务 |
| 成本控制 | 可路由到更便宜的模型(如 Haiku) |
| 专业化分工 | 不同子代理专注不同领域(审查、测试、分析) |
| 跨项目复用 | 配置一次,在所有项目中使用 |
2. 架构设计与工作原理
2.1 Agent Tool — 主代理与子代理的桥梁
Agent 工具是主代理启动子代理的唯一入口。调用参数如下:
| 参数 | 类型 | 必需 | 说明 |
|---|---|---|---|
prompt |
string | 是 | 分配给子代理的任务描述 |
description |
string | 是 | 3-5 个词的简短描述 |
subagent_type |
string | 否 | 指定子代理类型 |
model |
string | 否 | 模型覆盖:sonnet/opus/haiku |
run_in_background |
boolean | 否 | 是否后台运行 |
isolation |
string | 否 | "worktree" 表示在隔离工作树中运行 |
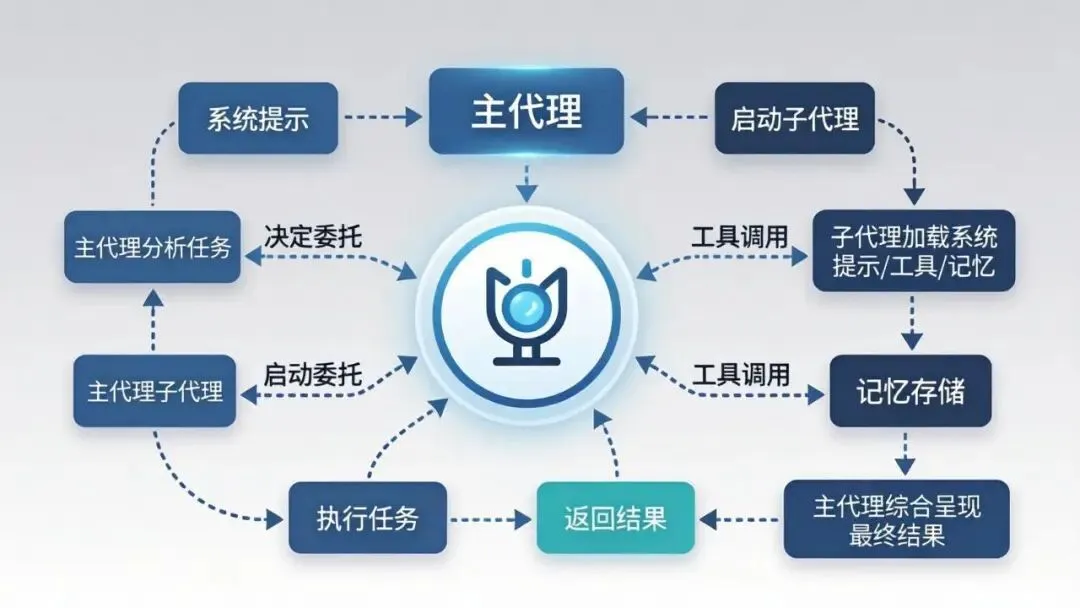
2.2 生命周期
用户请求↓主代理分析 → 决定是否委托↓Agent Tool 启动子代理↓子代理初始化:├─ 加载系统提示(.md 文件的 body 部分)├─ 加载 CLAUDE.md(自动继承)├─ 应用工具限制(tools / disallowedTools)├─ 连接 MCP 服务器(如配置)├─ 加载持久记忆(如配置 memory 字段)└─ 应用权限模式↓子代理执行任务(多轮工具调用)↓子代理返回结果 → 主代理接收↓主代理综合结果 → 呈现给用户
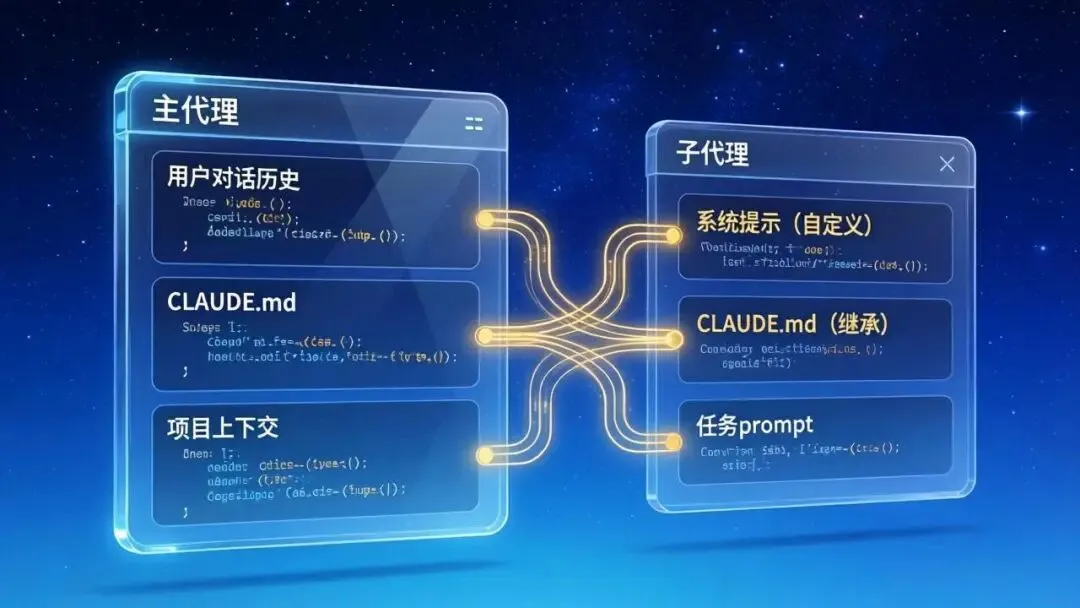
2.3 上下文隔离模型
主代理上下文窗口 子代理上下文窗口┌──────────────────┐ ┌──────────────────┐│ 用户对话历史 │ │ 系统提示(自定义) ││ CLAUDE.md │ ──prompt──→ │ CLAUDE.md(继承) ││ 项目上下文 │ │ 任务 prompt ││ 工具调用历史 │ │ 工具调用历史(独立)││ 所有子代理返回摘要 │ ←─result── │ 执行结果 │└──────────────────┘ └──────────────────┘
核心要点:
-
子代理不继承主对话历史
-
子代理自动继承 CLAUDE.md 指令
-
子代理的详细工具调用日志不会回传到主上下文
-
主代理只收到子代理的最终返回消息
3. 内置子代理类型详解
aude Code Sub-Agent 也分为两种:内置 Sub-Agent 和 自定义 Sub-Agent。
3.1 类型对照表
| 类型 | 默认模型 | 可用工具 | 核心用途 | 触发场景 |
|---|---|---|---|---|
general-purpose |
继承主会话 | 全部工具 | 复杂多步任务 | 默认类型 |
Explore |
Haiku | 只读(Read/Glob/Grep/WebFetch/WebSearch) | 代码搜索、文件发现 | 需要广泛探索代码库时 |
Plan |
继承主会话 | 只读(同 Explore) | 规划模式下的研究 | 设计实现方案时 |
architect |
Opus | 全部(不含 Agent) | 架构分析、重构建议 | 架构决策、代码异味检测 |
claude-code-guide |
Haiku | 只读 + WebFetch/WebSearch | 回答 Claude Code 功能问题 | 用户问”如何使用 Claude Code” |
statusline-setup |
Sonnet | Read/Edit | 配置状态行 | /statusline 命令 |
3.2 各类型详细说明
general-purpose(通用型)
最灵活的子代理,继承所有工具权限。能够处理复杂、多步骤任务的代理,这些任务需要探索和操作。
-
模型:继承自主对话 -
工具:所有工具
-
目的:复杂研究、多步骤操作、代码修改 -
使用场景:
搜索关键字后修改多处代码
运行测试并修复失败用例
在独立上下文中完成完整特性开发
Explore(探索型)
-
模型:Haiku(快速、低延迟) -
工具:只读工具(拒绝访问写入和编辑工具) -
目的:文件发现、代码搜索、代码库探索 -
使用场景举例:
– “项目中有哪些 API 端点?”
– “找到所有使用 Redis 的文件”
– “分析这个模块的架构”
调用 Explore 时,Claude 指定一个彻底程度:quick 用于有针对性的查找,medium 用于平衡的探索,或 very thorough 用于全面分析。
Plan
在 计划模式 期间用于研究计划之前收集的上下文。
-
模型:继承自主对话 -
工具:只读工具(拒绝访问写入和编辑工具) -
目的:用于规划的代码库研究
当你处于计划模式且 Claude 需要理解你的代码库时,它会将研究委托给 Plan 子代理。这样可以防止无限嵌套(子代理无法生成其他子代理),同时仍然收集必要的上下文。
architect(架构师型)
使用 Opus 模型(最强推理能力),专注于架构级分析。
4. 文件构成与目录结构
4.1 核心目录
~/.claude/├── agents/ # 全局子代理定义(所有项目可用)│ ├── architect.md # 架构师子代理│ ├── code-reviewer.md # 代码审查子代理│ └── ...├── agent-memory/ # 子代理持久记忆(memory: user)│ ├── architect/│ │ └── MEMORY.md # 记忆索引│ └── code-reviewer/│ └── MEMORY.md├── settings.json # 全局配置├── CLAUDE.md # 全局指令(所有代理继承)└── projects/└── {projectId}/├── {sessionId}/│ └── subagents/ # 子代理运行记录│ ├── agent-xxx.jsonl # 子代理完整对话历史│ └── agent-xxx.meta.json # 子代理元数据└── memory/ # 项目级记忆项目目录/├── .claude/│ ├── agents/ # 项目级子代理定义(可提交到版本控制)│ │ ├── test-runner.md│ │ └── db-validator.md│ ├── agent-memory/ # 项目级代理记忆(memory: project)│ │ └── test-runner/│ │ └── MEMORY.md│ └── agent-memory-local/ # 本地代理记忆(memory: local,不提交 git)│ └── test-runner/│ └── MEMORY.md├── CLAUDE.md # 项目指令└── AGENTS.md # 项目级代理行为指引
4.2 加载优先级
子代理定义文件按以下优先级加载(高→低):
| 优先级 | 来源 | 说明 |
|---|---|---|
| 1(最高) | --agents CLI 标志 |
仅当前会话 |
| 2 | .claude/agents/ |
当前项目,可提交版本控制 |
| 3 | ~/.claude/agents/ |
全局,所有项目可用 |
| 4(最低) | 插件的 agents/ 目录 |
随插件分发 |
4.3 子代理运行记录格式
每次子代理运行会生成两个文件:
gent-xxx.meta.json — 元数据:
{"agentType": "Explore","description": "Search agent definition files"}
agent-xxx.jsonl — 完整对话历史(JSON Lines 格式),包含子代理的所有工具调用和返回值。
5. 自定义 Sub-Agent
5.1 创建自定义子代理(保姆级教程)
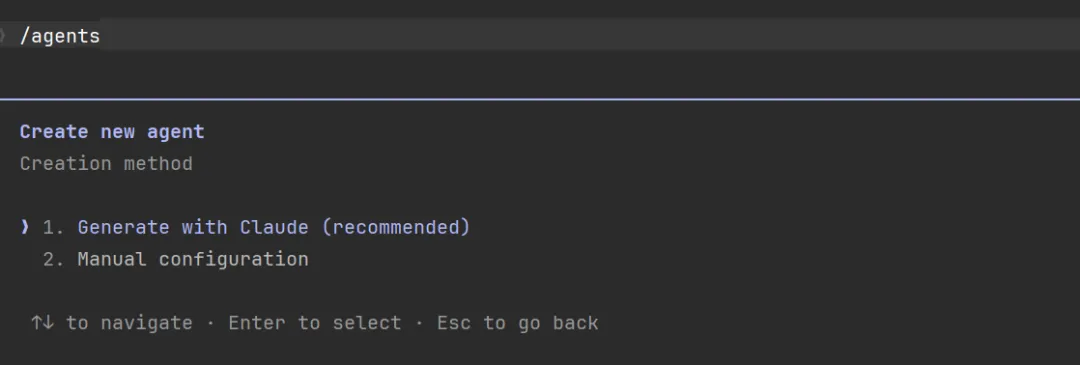
方式一:通过 /agents 命令交互式创建
第一步:确定代理级别
首先,在 Claude Code 中运行 /gents 命令:
创建用户/项目级代理
Agents6 agents❯ Create new agentCrCaee new agentntUsers\32827\.claude\agents)Choose locationpus · user memory1. Projectg(.claude/agents/)lable)2. Personal-(~/.claude/agents/)
第二步:选择创建方式:手动填写 / 让 Claude 生成
第三步:配置名称、描述、工具、模型、颜色等
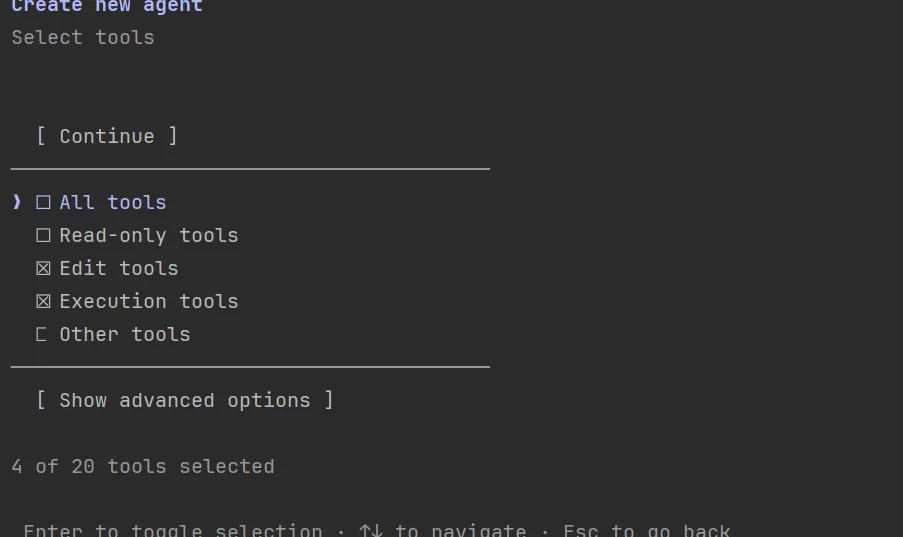
选择颜色
第四步:保存
方式二:手动创建 Markdown 文件
就是这个图中的第二个选项
---name: code-reviewerdescription: >专业代码审查员。在修改代码后主动审查代码质量、安全性和可维护性。使用场景:代码审查、安全审计、质量检查。model: sonnettools: Read, Grep, Glob, Bashmemory: project---你是一位资深代码审查专家。当被调用时:## 审查流程1. 运行 `git diff` 查看最近更改2. 聚焦修改过的文件3. 立即开始审查## 审查清单- 代码清晰度和可读性- 正确的错误处理- 无安全漏洞或密钥泄露- 输入验证- 测试覆盖率- 性能考虑## 输出格式按优先级分类反馈:- **严重**(必须修复):安全漏洞、数据丢失风险- **警告**(建议修复):性能问题、代码异味- **建议**(可选优化):风格改进、可读性提升
这种方式要求理解Frontmatter 字段:
格式:
---# [必需] 唯一标识符,小写字母+连字符name: code-reviewer# [必需] 描述何时应使用此子代理(主代理据此路由)description: >描述越精确,自动路由越准确。可以包含具体使用场景示例。# [可选] 模型选择# opus — 最强推理,适合复杂架构分析# sonnet — 平衡型,适合大多数任务# haiku — 最快最便宜,适合简单搜索# inherit — 继承主会话模型(默认行为)model: sonnet# [可选] 允许使用的工具列表(逗号分隔)# 不指定 = 继承所有工具tools: Read, Grep, Glob, Bash# [可选] 禁止使用的工具列表(与 tools 二选一)# disallowedTools: Write, Edit# [可选] 持久记忆范围# user — ~/.claude/agent-memory/{name}/(跨项目)# project — .claude/agent-memory/{name}/(项目级,可提交 git)# local — .claude/agent-memory-local/{name}/(项目级,不提交 git)memory: project# [可选] UI 显示颜色color: blue# [可选] 权限模式# default — 默认,需要用户批准# acceptEdits — 自动接受编辑# dontAsk — 不询问权限# plan — 规划模式permissionMode: default# [可选] 最大执行轮次maxTurns: 10# [可选] 推理努力程度:low / medium / high / maxeffort: medium# [可选] 是否默认后台运行background: false# [可选] 隔离模式:worktreeisolation: null# [可选] 预加载的技能skills:- code-patterns# [可选] 自定义钩子hooks:PreToolUse:- matcher: "Bash"hooks:- type: commandcommand: "./scripts/validate-cmd.sh"---
提要:
|
|
|
|
|---|---|---|
name |
|
|
description |
|
|
tools |
|
|
disallowedTools |
|
|
model |
|
模型
sonnet、opus、haiku 或 inherit。默认为 sonnet |
permissionMode |
|
权限模式
default、acceptEdits、dontAsk、bypassPermissions 或 plan |
skills |
|
|
hooks |
|
|
方式三:CLI 参数临时定义
claude --agents '{"quick-checker": {"description": "快速代码检查员","prompt": "你是一个快速代码检查员,只关注明显的 bug 和安全问题。","tools": ["Read", "Grep"],"model": "haiku"}}'
注意:这种方式仅对当前会话有效,不会持久化。
5.2 配置 Sub-Agent
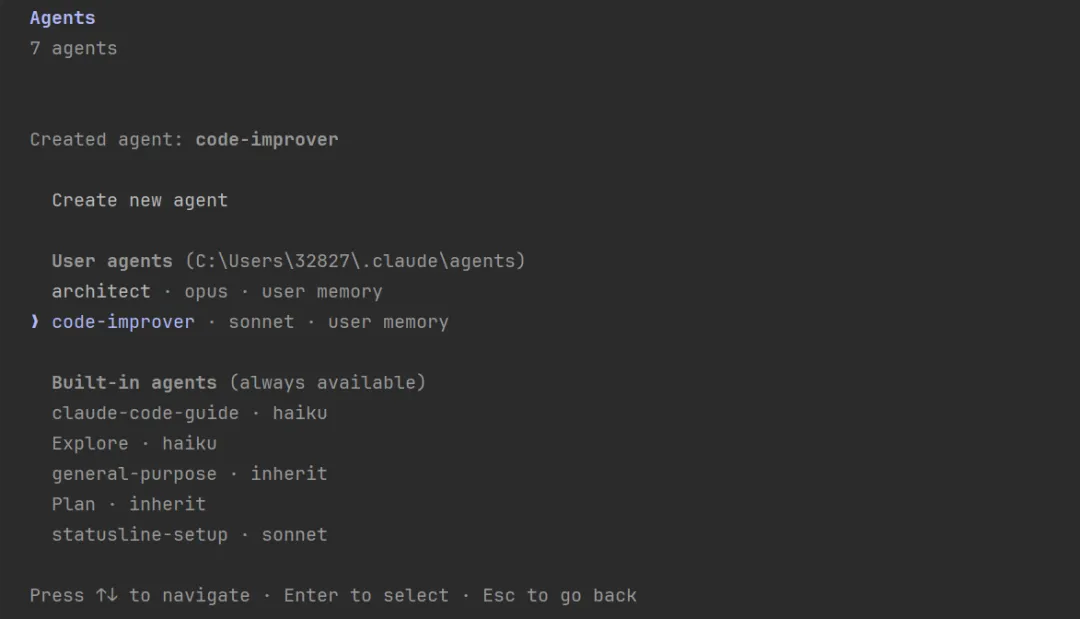
这里可以选择创建新的 Sub-Agent ,也可以选择管理已有的 Sub-Agent 。选择上面创建好的 code-improver 回车会进入该 Sub-Agent 的管理页面:
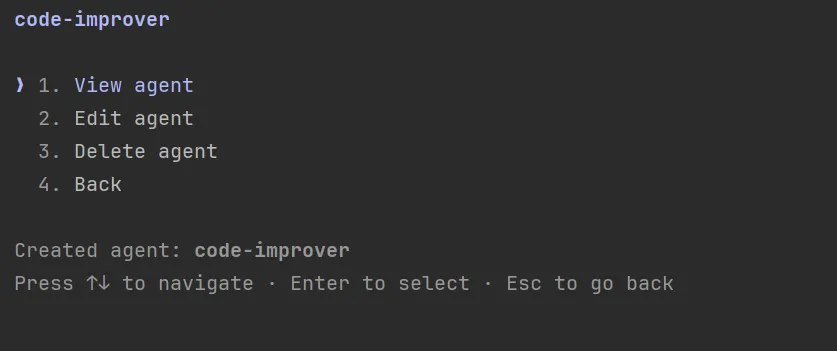
管理页面支持预览 agent 的功能、编辑 agent 和删除 agent 。选择 Edit agent 可以直接编辑 Sub-Agent 的 tools:
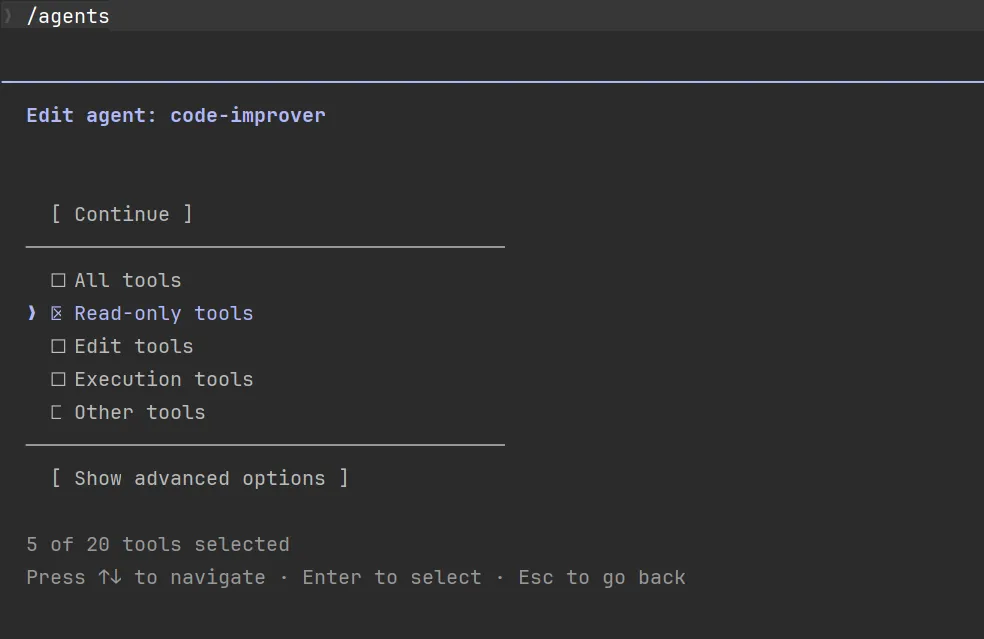
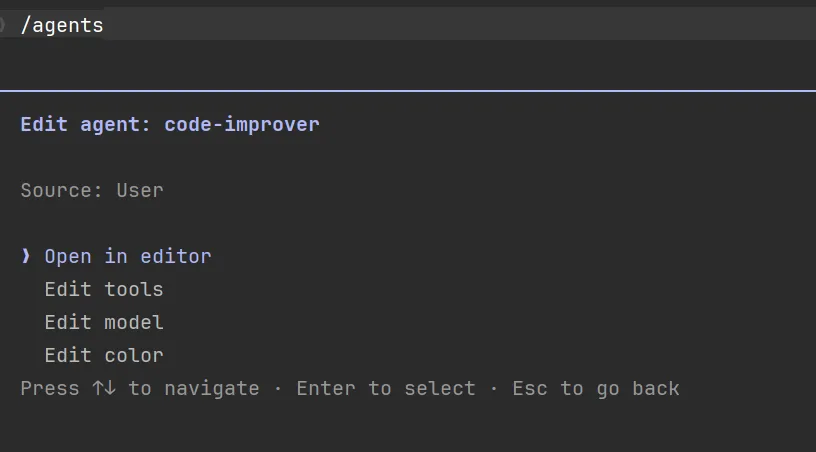
也可以 直接直接打开编辑器编辑:
5.3 验证
# 显式调用@code-reviewer 审查一下最近的代码改动# 或者自然语言触发(主代理根据 description 自动路由)帮我审查一下刚才的代码修改
也可以:
使用 code-reviewer 代理为此项目做CR6. 路由决策流程
用户发出请求↓主代理分析请求内容↓┌─────────────────────────────────────┐│ 路由决策树 ││ ││ 1. 用户使用 @-提及? ││ └─ 是 → 强制委托给指定子代理 ││ ││ 2. 请求匹配某子代理 description? ││ └─ 是 → 自动委托 ││ ││ 3. 任务适合并行化? ││ └─ 是 → 启动多个子代理并行工作 ││ ││ 4. 以上都不满足 ││ └─ 主代理直接处理 │└─────────────────────────────────────┘
6.1 三种调用方式
方式一:自动委托(推荐)
主代理根据子代理的 description 字段自动匹配。description 写得越精确,路由越准确。
# 如果存在 description 包含 "代码审查" 的子代理用户:帮我审查一下 auth 模块的代码→ 主代理自动委托给 code-reviewer 子代理
方式二:@-提及(强制执行)
@code-reviewer 审查 src/auth/ 目录下的所有改动上面已经演示过
方式三:会话级代理
# 整个会话使用某个子代理的系统提示和工具限制claude --agentcode-reviewer
6.2 并行调度
主代理可以在一条消息中启动多个子代理并行工作:
举例:
# 用户请求同时分析认证模块、数据库层和 API 设计# 主代理行为:1. 启动 Explore 子代理 A → 分析认证模块2. 启动 Explore 子代理 B → 分析数据库层 # 与 A 并行3. 启动 Explore 子代理 C → 分析 API 设计 # 与 A、B 并行4. 等待所有子代理返回5. 综合三个结果呈现给用户
6.3 前台 vs 后台调度
| 维度 | 前台(默认) | 后台 |
|---|---|---|
| 阻塞主对话 | 是,等待完成 | 否,立即可继续 |
| 权限处理 | 交互式逐个批准 | 启动前一次性预批准 |
| 适用场景 | 需要结果才能继续的任务 | 独立的长时间任务 |
| 启动方式 | 默认行为 | run_in_background: true |
| 快捷键 | — | Ctrl+B 后台化当前任务 |
6.4 SendMessage 继续机制(恢复子代理)
子代理完成后会返回一个 agentId,主代理可以通过 SendMessage 恢复该子代理:
# 第一次调用用户:用 code-reviewer 审查 auth 模块→ 子代理完成,返回 agentId: agent-abc-123# 继续调用(保留完整上下文)用户:继续审查 authorization 逻辑→ 主代理通过 SendMessage 发送给 agent-abc-123→ 子代理恢复,拥有之前审查的全部上下文
子代理成绩单独立于主对话持久化:
-
主对话压缩:当主对话压缩时,子代理成绩单不受影响,它们存储在单独的文件中。 -
会话持久性:子代理成绩单在其会话中持久化,可以通过恢复相同会话在重启 Claude Code 后 恢复子代理。 -
自动清理:成绩单根据 cleanupPeriodDays设置进行清理(默认:30 天)。
6.5 自动压缩机制
子代理支持使用与主对话相同的逻辑进行自动压缩。当子代理的上下文接近其限制时,Claude Code 会总结较旧的消息以释放空间,同时保留重要上下文。压缩事件记录在子代理成绩单文件中:
{"type": "system","subtype": "compact_boundary","compactMetadata": {"trigger": "auto","preTokens": 167189}}
7. 上下文记忆(Memory)分配机制
7.1 上下文传递矩阵
| 内容 | 主代理 → 子代理 | 子代理 → 主代理 |
|---|---|---|
| 完整对话历史 | 不传递 | 不传递 |
| CLAUDE.md 指令 | 自动继承 | — |
| 任务 prompt | 通过 Agent 工具传递 | — |
| 执行结果 | — | 只返回最终消息 |
| 持久记忆 | 各自独立加载 | 各自独立保存 |
| 项目文件访问 | 共享(同一文件系统) | 共享 |
| git 状态 | 共享 | 共享(除非 worktree 隔离) |
7.2 持久记忆(Memory)系统详解
记忆范围
# 方式一:用户级记忆 — 跨所有项目memory: user# 存储位置:~/.claude/agent-memory/{agent-name}/# 适用场景:通用偏好、个人风格、跨项目知识# 方式二:项目级记忆 — 可版本控制memory: project# 存储位置:.claude/agent-memory/{agent-name}/# 适用场景:项目架构知识、团队约定、项目特定模式# 方式三:本地项目记忆 — 不提交 gitmemory: local# 存储位置:.claude/agent-memory-local/{agent-name}/# 适用场景:个人笔记、本地环境配置、敏感信息
记忆工作原理
子代理启动↓系统提示自动注入记忆管理指令↓加载 MEMORY.md 索引(前 200 行)↓子代理可随时:├─ 读取记忆文件获取历史知识├─ 创建新记忆文件保存发现└─ 更新 MEMORY.md 索引↓记忆持久保存到磁盘↓下次调用时自动加载
记忆文件格式
每个记忆文件使用 Markdown + Frontmatter:
---name: auth-patternsdescription: 项目中认证模块的常见模式和约定type: project---## 认证模式- JWT Token 存储在 Redis,TTL 24 小时- 所有 API 端点通过 AuthInterceptor 拦截- 权限校验使用 RBAC 模型**Why:** 团队在 2024Q4 统一了认证架构**How to apply:** 新功能涉及认证时遵循此模式
MEMORY.md 索引格式
- [认证模式](auth-patterns.md) — JWT + Redis + RBAC 认证架构- [数据库约定](db-conventions.md) — 分库分表规则和索引策略- [API 风格](api-style.md) — RESTful API 设计规范
7.3 记忆隔离示意图
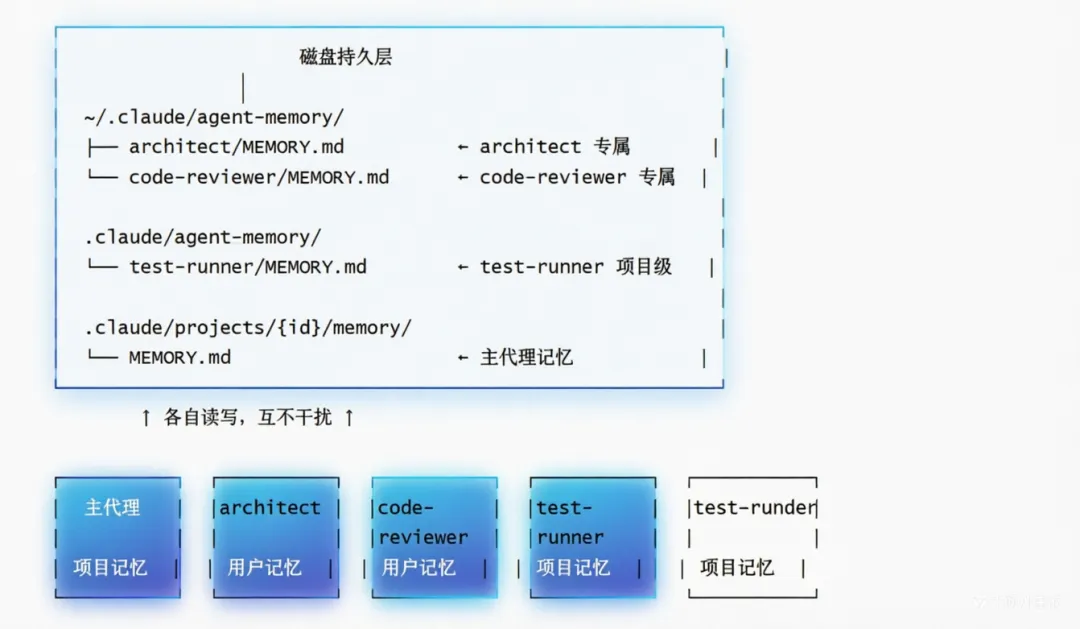
核心要点:
-
每个子代理有独立的记忆空间
-
主代理和子代理的记忆互不可见
-
记忆范围由
memory字段决定 -
子代理可以在执行过程中主动读写记忆
-
MEMORY.md 的前 200 行会自动注入到系统提示中