 夜雨聆风
夜雨聆风





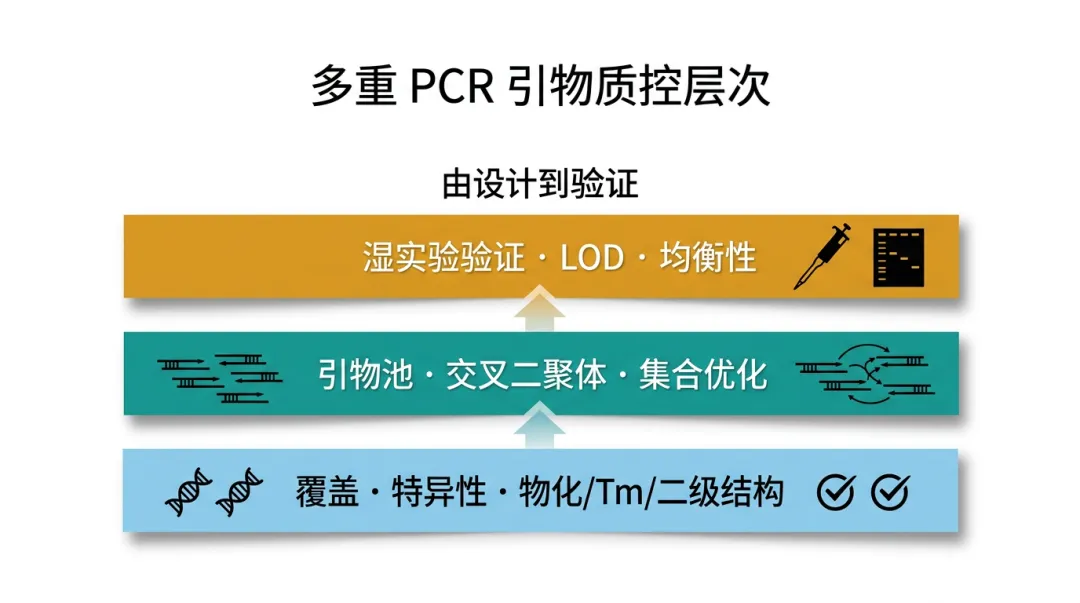
设计软件很多,但好引物池的共通标准就这几类
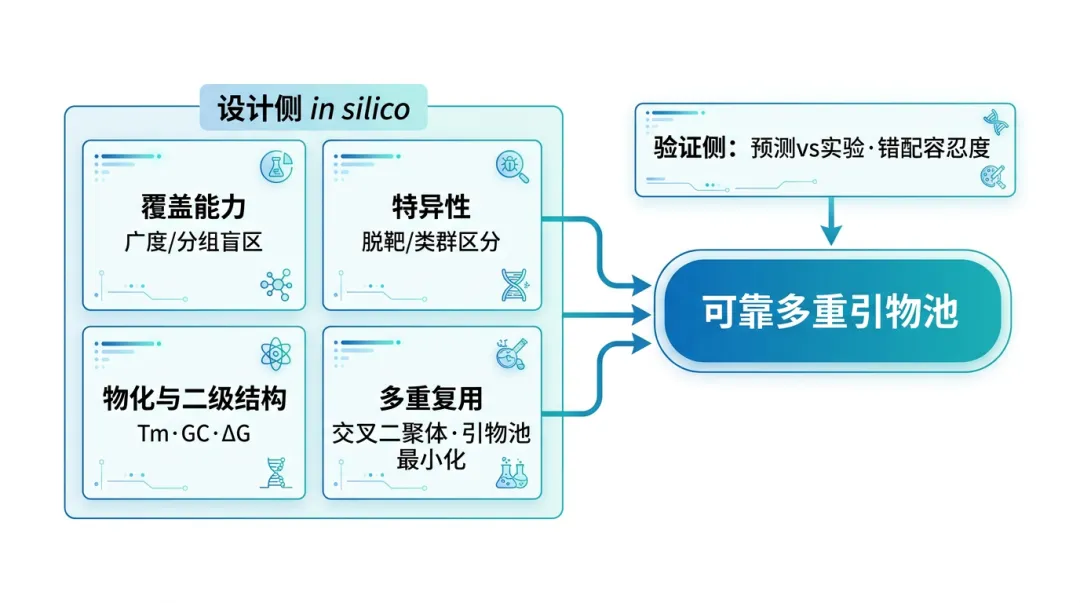
多重 PCR 能在单次反应中并行获取多路信息,其价值取决于引物池是否同时满足覆盖、特异、可扩增与可验证。设计软件很多,但不同场景权重不同:少量位点(如肿瘤复发监测)往往优先引物对间兼容性;微生物广谱或病原面板则更强调模板覆盖广度与类群水平特异性。把指标算清、再理解其生物学含义,才能筛出可重复的引物池。
下面通过表格来概览这些指标:
|
|
|
|
|
|---|---|---|---|
| 覆盖能力 |
|
|
|
|
|
|
|
|
| 特异性 |
|
|
|
|
|
|
|
|
| 稳定性 |
|
|
|
| 多重复用 |
|
|
|
|
|
|
|
|
| 预测准确率 |
|
|
|
|
|
|
|
上表覆盖了多重设计中最核心的 in silico 维度。下面几类指标在《应用场景》一文中常与具体领域绑定出现,实践中同样重要,但更多依赖实验标定或与 wet lab 联用,软件侧往往只提供间接支持(如 Tm 均一性、产物长度规划),故未全部并入上表,在此集中说明,避免遗漏。
|
|
|
|
|---|---|---|
| 灵敏度与检出限 |
|
|
| 扩增均衡性 |
|
|
| 产物长度规划 |
|
|
| 3′ 端与序列形态 |
|
|
| 分型场景 |
|
|
| 复杂样本 |
|
|
1. 覆盖能力 (Coverage) 的详细计算与意义
这是衡量引物能否成功扩增目标模板的核心指标。
-
模板覆盖度 (Template Coverage)
-
计算方式: 对于设计好的一组或多组引物,通过计算机模拟PCR(如使用 Primer3或BLAST算法),逐一比对每条目标模板序列。如果一条模板的上下游引物结合位点都能与引物序列成功匹配(通常允许一定数量的错配),则判定该模板可被扩增。最终,覆盖度 = (可被扩增的模板数量 / 输入的总模板数量) × 100% 。 -
生物学意义: 它直接反映了引物集检测目标多样性的广度。在微生物组研究或病原体检测中,如果覆盖度不够高,就会导致假阴性结果,即样本中存在的某些物种或变异株因为无法被引物扩增而检测不到,从而低估了生物多样性或导致漏检 。 -
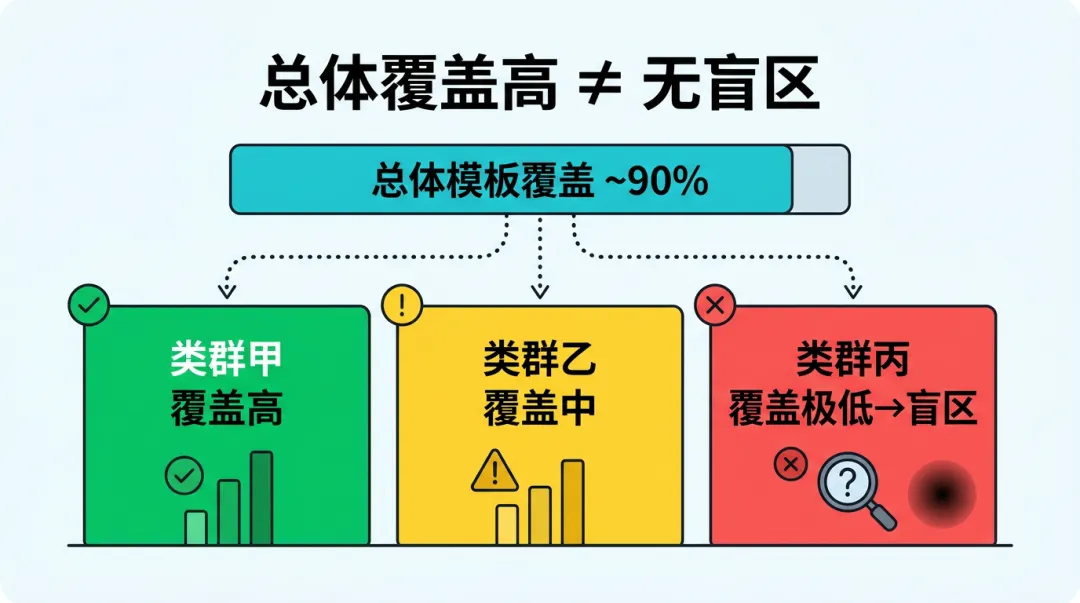
分组覆盖统计 (Group Coverage Statistics)
-
计算方式: 首先,将输入的模板序列根据其附带的分类学信息(如界、门、纲、目、科、属、种)进行分组。然后,在每个分组内部独立地重复上述“模板覆盖度”的计算。例如,分别计算引物集在“厚壁菌门”和“变形菌门”中的覆盖度 。 -
生物学意义: 总体覆盖度很高,但可能掩盖了某个关键类群(如某个稀有物种或重要的致病菌)被完全遗漏的事实。分组覆盖统计可以精细地揭示引物集的检测盲区,帮助研究者判断是否需要为特定类群设计补充引物 。
2. 特异性 (Specificity) 的详细计算与意义
这部分关注的是引物能否“精准打击”,不产生噪音。
-
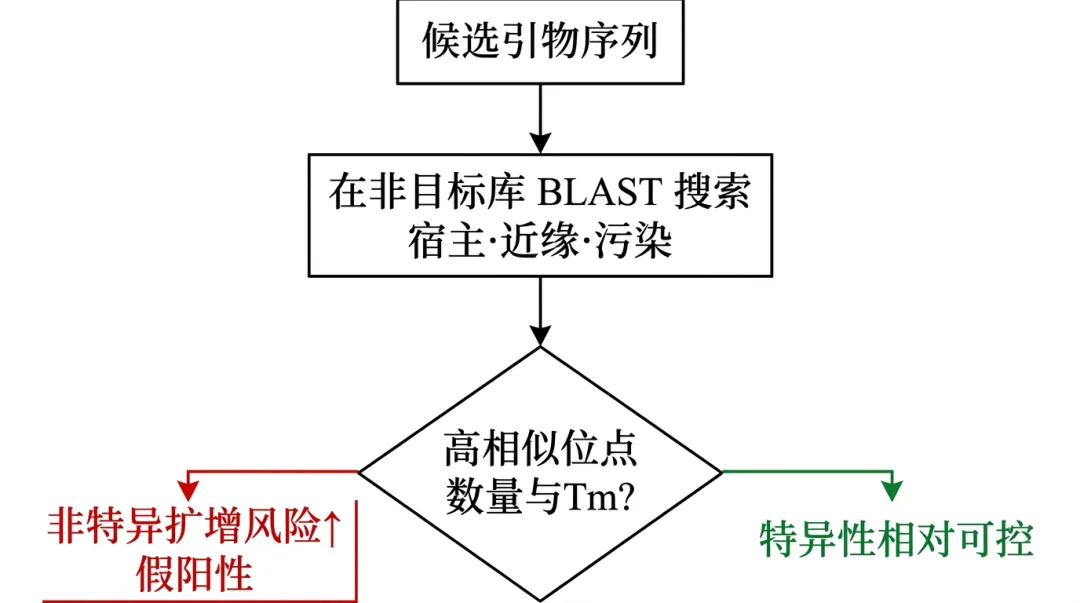
脱靶评估 (Off-target Evaluation)
-
计算方式: 将设计好的引物序列作为查询序列,通过 BLASTn等工具与一个庞大的非目标序列数据库(如宿主基因组、人类基因组、常见污染菌基因组或近缘物种的全基因组)进行比对。统计并分析引物序列与非目标序列产生高相似性匹配(Hits)的数量、位置和错配情况 。工具如AssayBLAST通过设置特定的BLAST参数(如调整word_size和打分矩阵)来优化短序列的搜索,并计算这些脱靶位点的熔解温度,以评估其在实际PCR反应中形成非特异性产物的可能性 。 -
生物学意义: 高脱靶率意味着引物可能在反应中结合到非目标DNA上,导致非特异性扩增,产生杂带或引物二聚体。这会消耗反应资源、降低目标扩增效率,并在测序结果中引入大量噪音,干扰结果分析 。对于临床诊断,这可能导致假阳性。 -
分类群特异性 (Taxon Specificity)
-
计算方式: 通常通过对比“目标分类群内的覆盖度”和“非目标分类群内的覆盖度”来体现。一个理想的引物,在目标群内的覆盖度应接近100%,而在非目标群内的覆盖度应接近于0%。例如,为“葡萄球菌属”设计的引物,应能扩增所有葡萄球菌,但不能扩增任何链球菌 。 -
生物学意义: 这是引物区分“敌我”的能力。在需要从复杂环境样本(如粪便、土壤)中检测特定病原体或标志物时,高分类群特异性至关重要,它确保扩增产物主要来源于目标生物,而非背景菌群。
3. 物化性质与热力学稳定性
这些是引物在试管中能否顺利工作的化学和物理基础。
-
基础参数合规性 (Physicochemical Properties)
-
长度: 直接统计引物的碱基数。 -
GC含量: (G + C的个数) / 总碱基数 × 100%。最佳范围通常为40%-60% 。 -
熔解温度 (Tm): 常用计算方法有碱基组成法: Tm = 4×(G+C) + 2×(A+T),适用于15-20nt的短引物 。更精确的方法是基于最近邻热力学模型,由Primer3等核心设计工具实现,它会计算引物与模板结合时的自由能变化,从而得出更准确的Tm值 。 -
计算方式: -
生物学意义: 这些参数决定了PCR反应的成功窗口。上下游引物的Tm值需要匹配(通常相差不超过5°C),否则难以找到共同的最优退火温度。GC含量过低会导致结合不稳定,过高则易形成二级结构,降低扩增效率 。 -
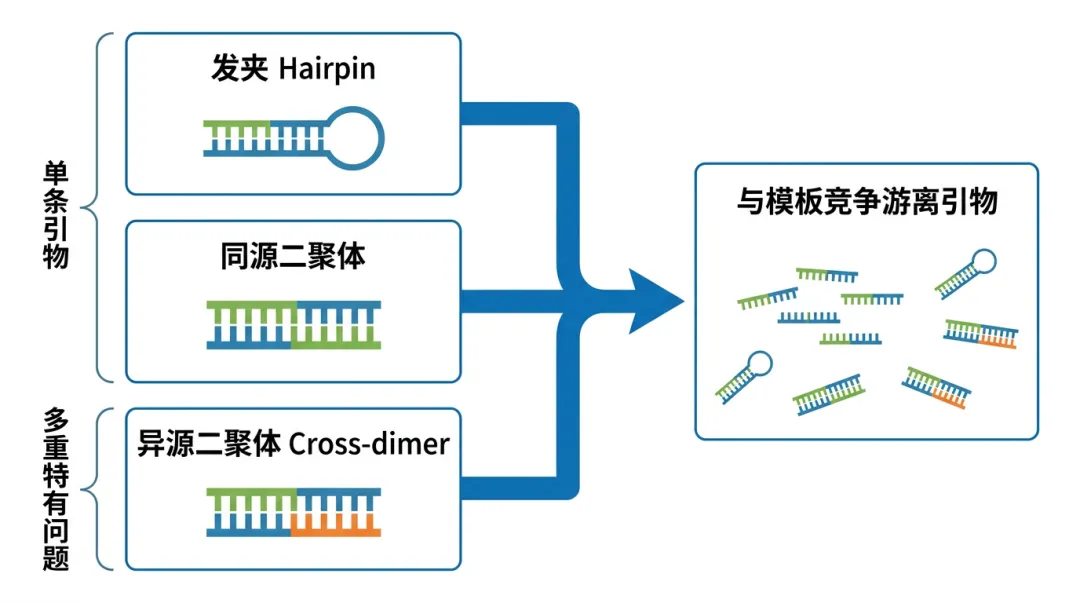
二级结构预测 (Secondary Structure)
-
计算方式: 通过热力学算法(如 mfold或Primer3内置算法)预测引物在溶液中可能形成的内部结构,如**发夹 (Hairpin)、同源二聚体 (Self-dimer)、异源二聚体 (Cross-dimer)**。其稳定性用吉布斯自由能 ΔG 来衡量。ΔG值越负,表明结构越稳定,越容易形成。一般要求ΔG大于某个阈值(如 -9 kcal/mol),以确保这些有害结构在PCR温度下无法稳定存在 。 -
生物学意义: 稳定的二级结构会与目标模板竞争结合引物,导致有效引物浓度下降,扩增效率降低甚至完全失败。引物二聚体还可能在凝胶电泳中形成假阳性条带,干扰结果判读 。
4. 多重复用能力和兼容性
这是从单对引物到多对引物体系的进阶考量。
-
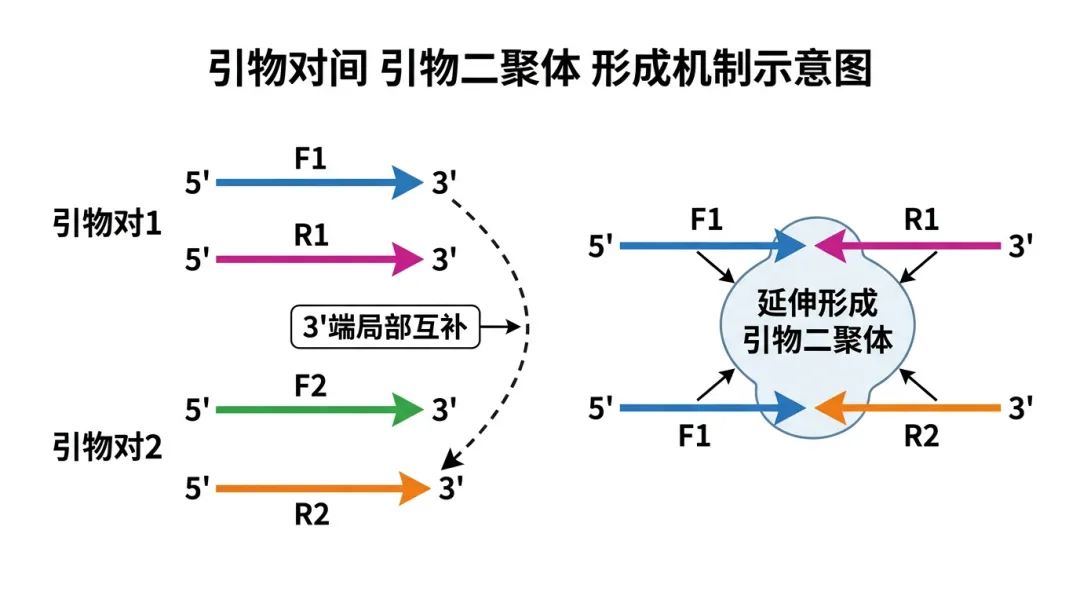
引物间兼容性 (Primer Compatibility) -
计算方式: 在多对引物构成的集合中,对任意不同对的引物(特别是不同对的上下游引物)进行两两比对,计算它们之间形成异源二聚体的可能性,同样通过计算ΔG值来评估。例如, openPrimeR等工具会将引物间二聚体预测作为筛选引物池的关键步骤 。 -
生物学意义: 多重PCR中,所有引物在同一管内共存。如果不同引物对的3‘端序列互补,它们就会相互结合并被延伸,形成“引物二聚体”。这不仅消耗了珍贵的引物和聚合酶,产生的二聚体还会在测序文库中占据大量reads,严重影响测序数据的质量和利用率 。
-
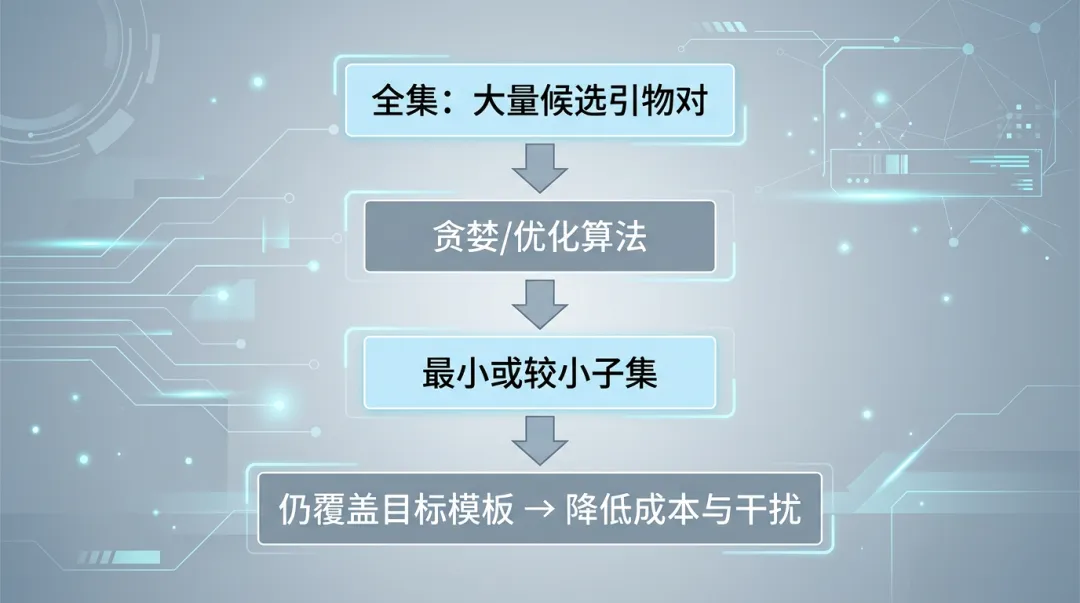
引物池最小化 (Primer Pool Minimization) -
计算方式: 这是一个数学上的集合覆盖优化问题。在拥有大量候选引物对的情况下,软件通过算法(如贪婪算法)寻找一个数量最少的引物组合,使其能覆盖最大范围的模板。 Prider工具的核心就是解决这个问题,它先生成全量的候选引物覆盖图,然后逐步剔除冗余度高或覆盖范围窄的引物,最终得到一个近似最优的引物集 。 -
生物学意义: 引物对越少,多重PCR反应的体系优化就越简单,不同引物间相互干扰的可能性也越低。这直接关系到实验的成本、效率和成功率。
5. 预测准确率和计算性能
这是评估软件本身是否值得信赖的指标。
-
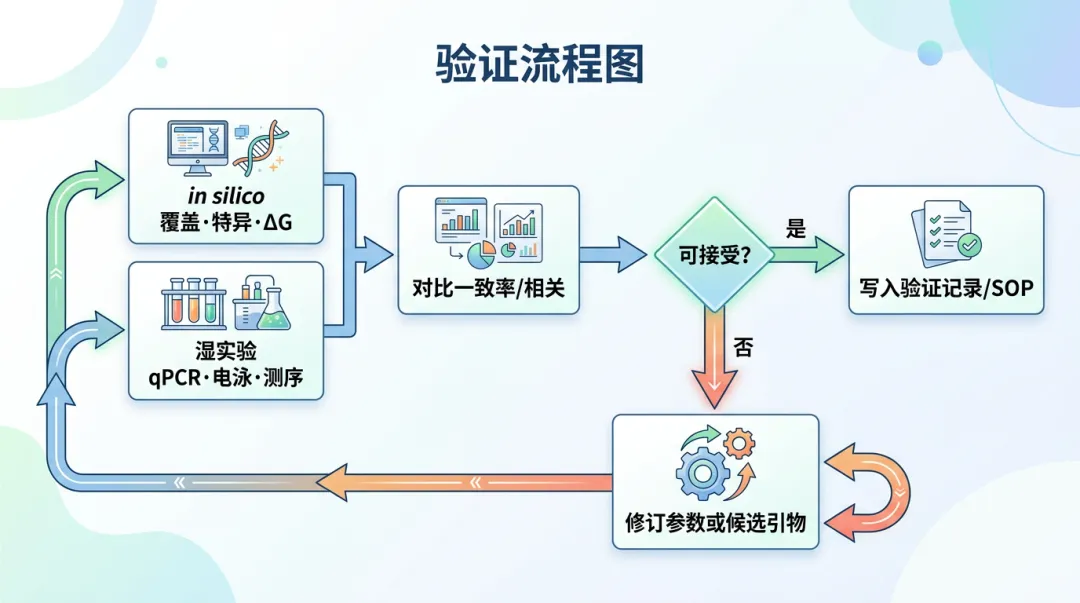
与实验数据的相关性 (Correlation with Experimental Data)
-
计算方式: 这是一个验证性指标。具体做法是:将软件对一组引物的预测结果(如覆盖度、特异性)与后续真实的湿实验结果(如qPCR的Ct值、扩增子测序的reads count、微阵列的荧光信号强度)进行比对。通过计算两者之间的一致性百分比或相关性系数(如皮尔逊相关系数)来量化。例如, AssayBLAST工具在验证其准确性时,将计算机预测的704个寡核苷酸与12株金葡菌微阵列实验的杂交结果进行对比,最终达到了97.5%的预测准确率 。 -
生物学意义: 这是衡量一个设计工具是否实用的黄金标准。高准确率意味着软件的热力学模型和算法能较好地模拟真实的PCR反应,其设计出的引物有更高的成功率,可以减少研究者后续实验验证的工作量。 -
错配容忍度分析 (Mismatch Tolerance Analysis)
-
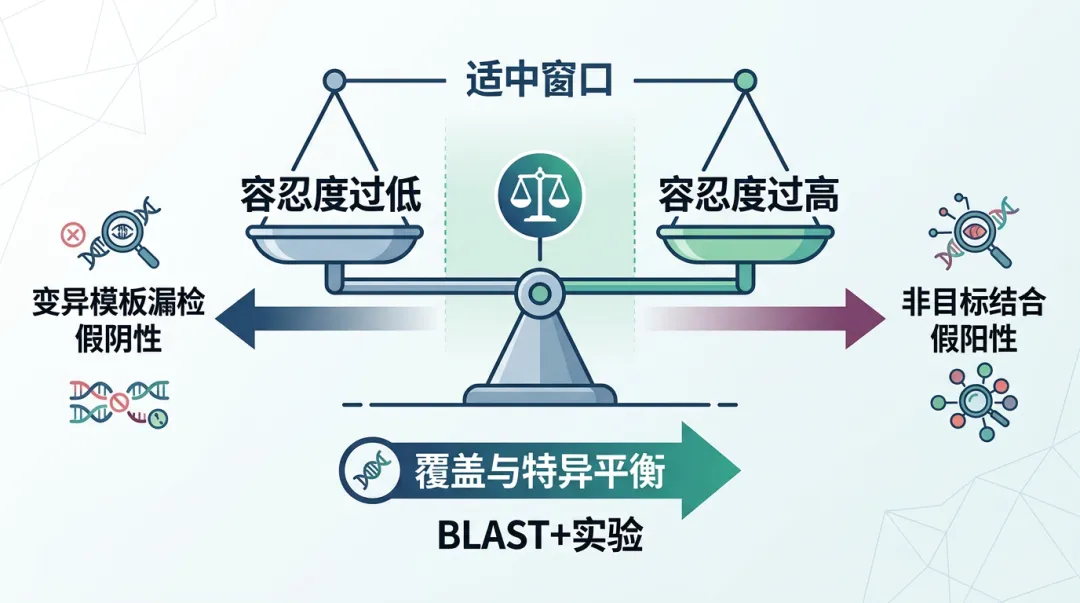
计算方式: 通过计算机模拟,系统地评估在引物序列与模板序列之间存在不同数量(如0、1、2个) 或不同类型(转换/颠换)的错配碱基时,引物还能否有效结合并引发扩增。高级工具如 AssayBLAST允许用户设定错配阈值(如默认4个),并分析所有在阈值范围内的结合位点 。 -
生物学意义: 现实世界中的模板序列充满了遗传变异。引物对一定数量的错配有“容忍度”,是它能够覆盖多样本模板的前提。但这个容忍度是双刃剑:容忍度过低,会漏掉变异株(假阴性);容忍度过高,则可能与非目标序列结合(假阳性)。通过分析,研究者可以了解引物在实际应用中的稳健性边界。
6. 与场景绑定的补充指标(实验与工艺侧)
-
灵敏度与检出限(LOD):临床与监测场景的核心 KPI。引物设计软件给出的结合能、特异性评分不能直接等同于 LOD;需在目标基质(如痰液、全血、拭子洗脱液)中做系列稀释与重复实验,并与提取方法、反应体积一并记录。 -
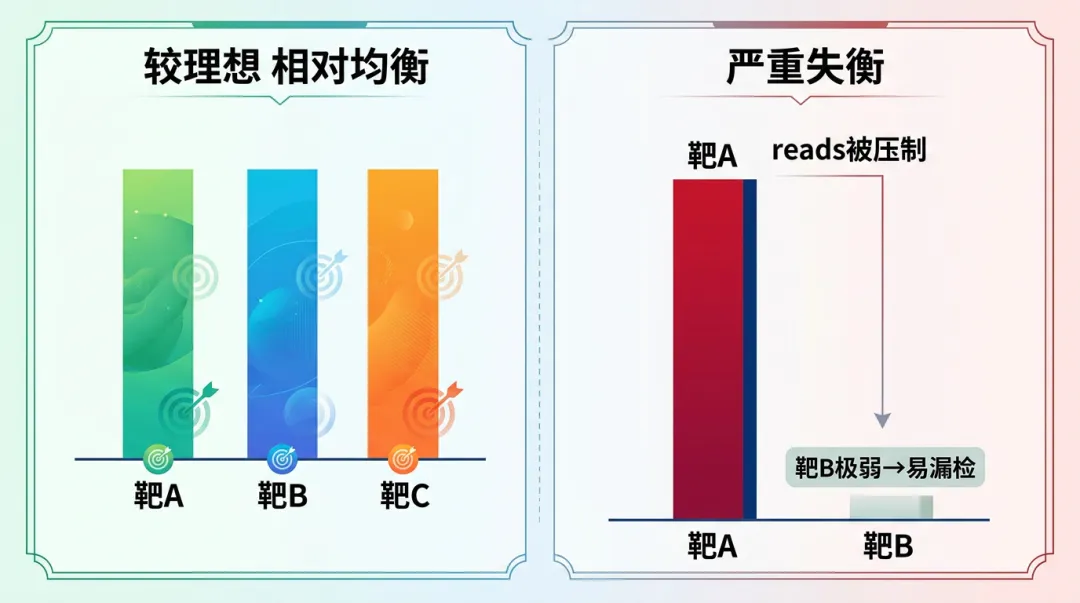
扩增均衡性:同一管内多靶点的相对产量。qPCR 可看 ΔCt;tNGS 可看各 amplicon 的 reads 计数分布。严重失衡时,低丰度靶在测序或弱荧光通道下易被掩盖。设计上可尽量使各对引物的 Tm、长度、GC% 接近,并在预实验中调整个别引物浓度。 -
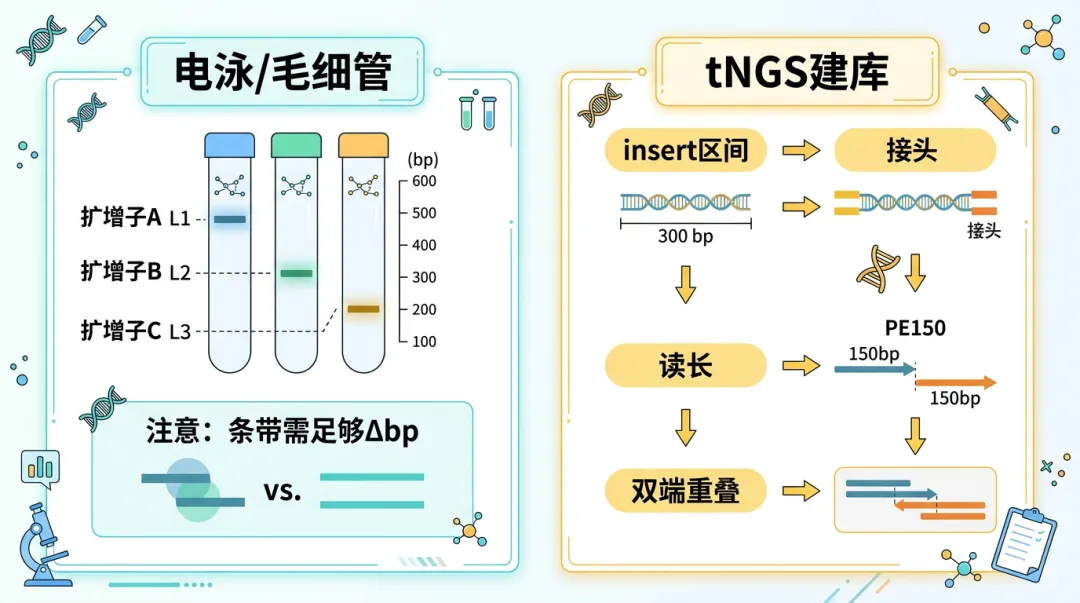
产物长度与平台约束:非测序场景需在电泳分辨率内拉开条带间距;tNGS 需满足片段长度、侧翼是否便于加 universal tail、是否与测序引物或 index 区互补(避免额外非特异)。 -
等位基因均衡:SNP/indel 共扩增时,两等位基因产物量应接近,否则杂合误判为纯合或比例失真。除引物设计外,退火温度、延伸时间与循环数也需优化。 -
抑制剂与内参:环境、临床未提纯样本常见。设计阶段避免极端序列仅属辅助;可靠做法包括内参基因、阳性对照与提取质控。
若需将上述指标落到具体实验类型与工具组合,关注可以查看后续文章。
如果你对引物还没有基础的了解可以查看往期文章: