个人/中小团队AI工具选型:用厂商API还是本地部署?算完账你就懂了
对绝大多数个人/中小团队而言,现阶段直接调用厂商API比自己本地跑模型要划算得多,也更省心。今天就把这笔账算明白,帮你快速做决策。
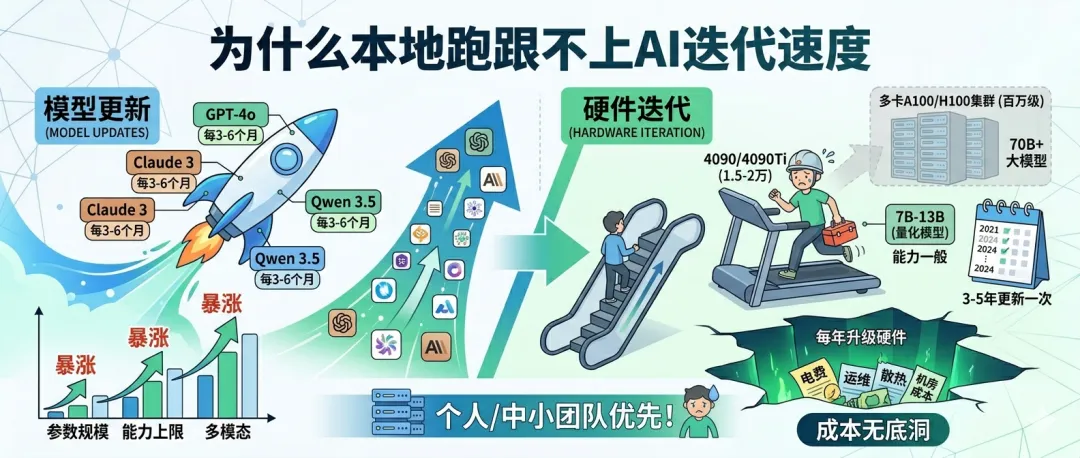
– 新模型(比如GPT-4o、Claude 3、Qwen 3.5等)每3-6个月就有一次大升级,参数规模、能力上限、多模态支持一直在暴涨
– 普通显卡/服务器通常3-5年才会更换一次,硬件寿命完全跟不上模型迭代的节奏
– 单张4090/4090Ti要1.5-2万,只能跑7B-13B的量化模型,能力远不如最新的公域大模型
– 要跑70B+的大模型,需要多卡A100/H100集群,光是硬件投入就要百万级
– 再算上电费、运维、散热、机房成本,每年还要多花硬件价格的20%-30%
– 想跟上最新模型的话,每年都要升级硬件,简直是无底洞
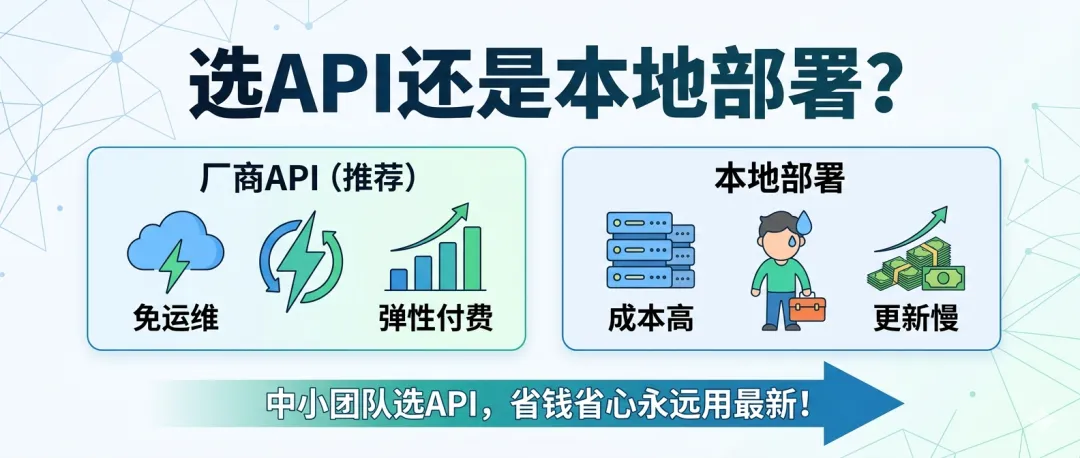
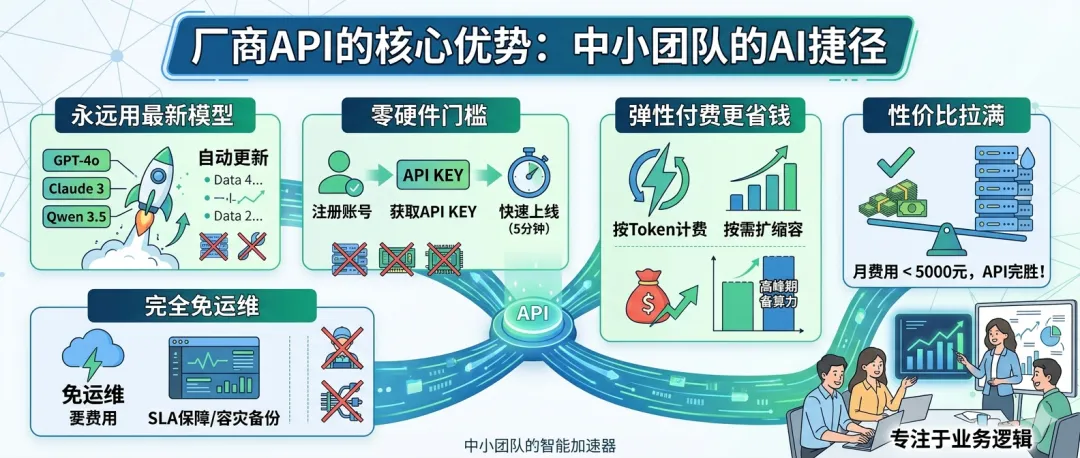
✅ 永远用最新模型:厂商会自动更新迭代最新的模型能力,你完全不用管硬件采购、部署适配这些麻烦事
✅ 零硬件门槛:注册账号→拿到API Key→直接调用,最快5分钟就能上线你的AI功能
✅ 弹性付费更省钱:按实际调用的token计费,不用的时候一分钱不花;流量波动的时候也能自动扩缩容,不用为峰值提前备算力
✅ 完全免运维:服务SLA保障、运行监控、容灾备份全由厂商负责,你只需要专注业务逻辑就行
✅ 性价比拉满:只要你月均API费用不到5000元,本地部署几乎不可能比用API更划算
当然不是说本地部署完全没用,如果你符合下面的场景,再考虑自己跑模型:
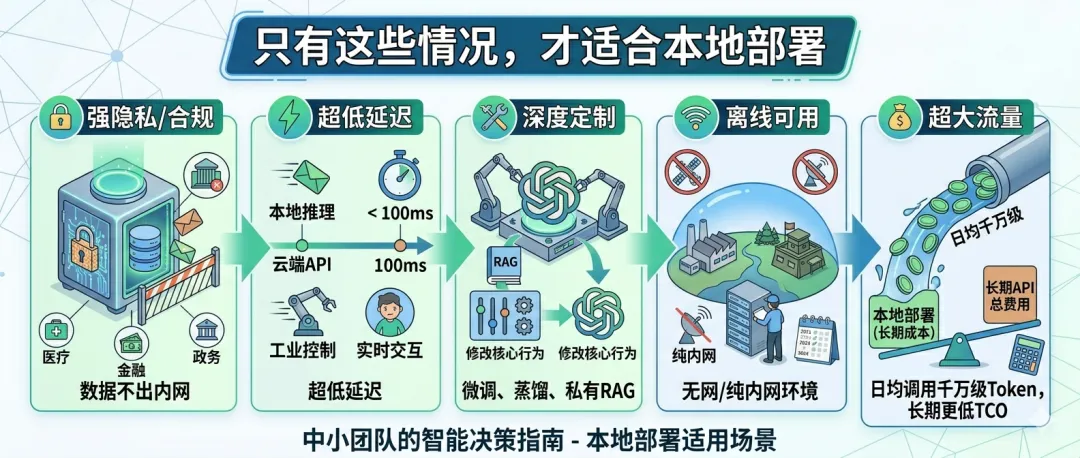
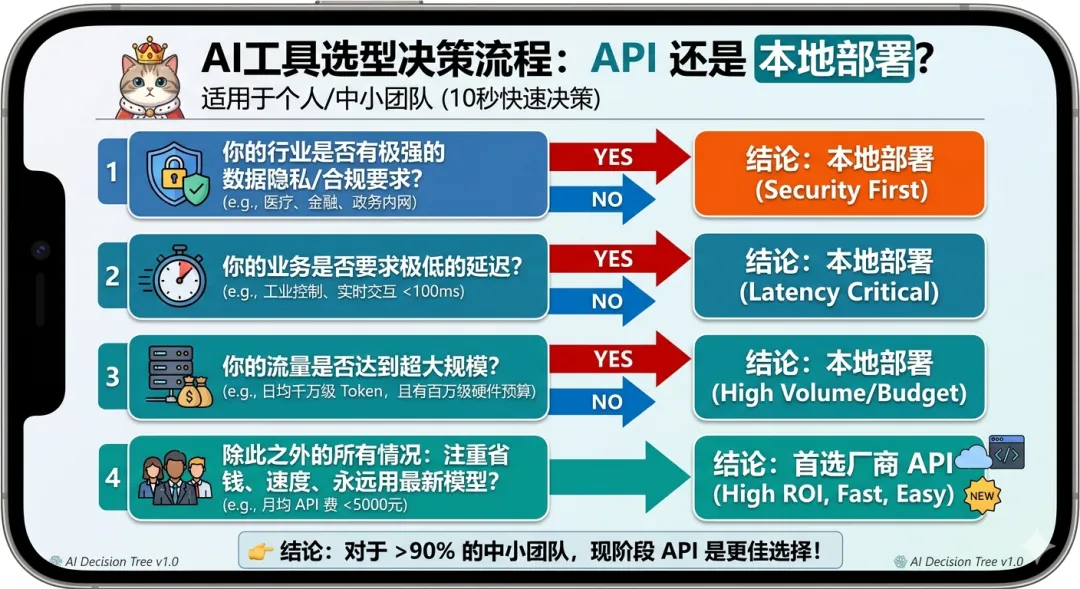
🔒 强隐私/合规要求:比如医疗、金融、政务行业,数据绝对不能流出内网
⚡ 超低延迟要求:实时交互、工业控制这类场景,需要本地推理延迟低于100ms
🛠️ 深度定制需求:需要对模型做微调、蒸馏,搭私有知识库RAG,或者要修改模型核心行为
📶 离线可用要求:无网/纯内网环境(比如工厂、军事场景、偏远地区)
💰 超大流量规模:日均调用千万级token,长期下来本地部署的总拥有成本可能更低
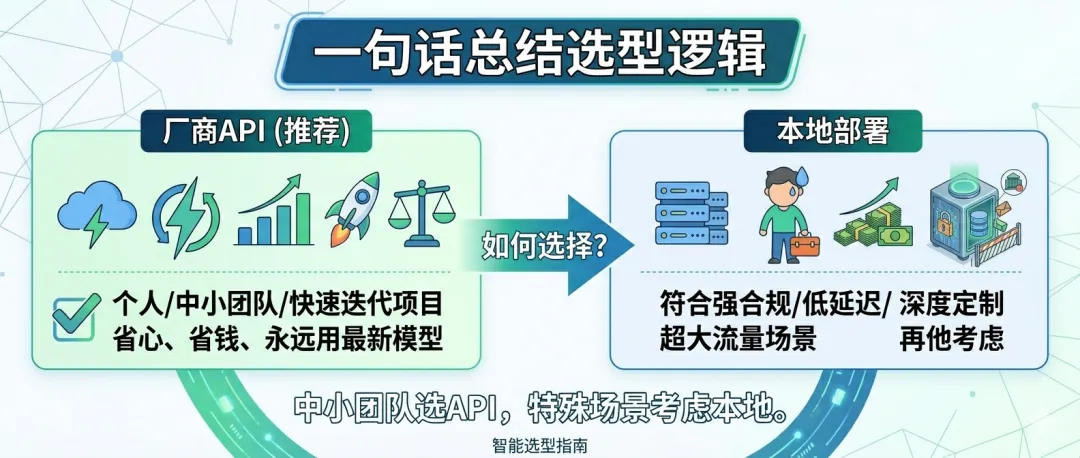
👉 个人/中小团队/快速迭代项目:优先选厂商API,省心、省钱、永远用最新模型
👉 符合强合规/低延迟/深度定制/超大流量场景:再考虑本地部署
💡 选型纠结症?10秒给出你的答案!
如果你还是拿不准该选 API 还是本地部署,不妨对照下方的“个人/中小团队 AI 选型清单”。我把最关键的决策因子做成了投票,看看你目前卡在哪个环节?
(选好后,评论区可以聊聊你的具体业务,我来帮你拆解算账!)
 夜雨聆风
夜雨聆风