 夜雨聆风
夜雨聆风





“AI受理助手”政务服务智能体建设方案
一、项目背景与目标
1.1 痛点分析
咨询量大、重复度高,基层工作人员超负荷运转
政策更新频繁,人工记忆易出错,答复口径不统一
居民对政策理解偏差,反复咨询导致办事效率低
特殊群体(老年人)数字鸿沟问题突出
1.2 建设目标
建设基于大语言模型的智能客服系统,实现7×24小时精准问答
部署多模态交互终端,覆盖语音、文字、图片等交互方式
构建数据驱动的民意分析能力,辅助社区服务决策
将窗口工作人员从重复解答中解放,满意度提升30%以上
二、数据
1、数据采集
(1)、政策知识库构建
来源:国家、省、市、区级政策文件,社区办事指南,内部规程(由街道办统一提供)
处理:对PDF/Word文件进行结构化解析,提取标题、发文单位、生效日期、适用对象、核心条款
更新机制:每月同步最新政策文件,自动入库,对已过期政策进行标记
(2)、常见问题库
来源:历史12345热线工单、窗口咨询记录、社区微信群问答
处理:人工标注形成标准问答对(Q&A),用于模型微调和兜底回答
(3)、动态反馈机制
居民可对回答进行“有用/无用”评价,评价数据用于持续优化模型和知识库
2、数据清洗
政策文件多为PDF、Word、扫描图片。采用以下技术进行结构化
PDF解析库(如PyPDF2、pdfplumber)提取文本与表格。
扫描件使用OCR(PaddleOCR、阿里云OCR)识别,保留原始版面结构。
利用大模型对非结构化文本进行段落切分,按“政策标题、发文单位、生效日期、适用对象、核心条款”等维度自动标注元数据。
对重复文件进行去重,对错误字符、乱码进行清洗;对已过期政策通过人工审核标记“已失效”,不进入活跃知识库。
3、知识切片与向量化
文本切片:将长政策文档按语义切分为适合检索的片段(chunk),每个片段约200~500字,保留上下文连贯性。采用递归字符分割(RecursiveCharacterTextSplitter)结合段落边界。
向量化嵌入:选用国产开源Embedding模型(如bge-large-zh-v1.5、text2vec-large-chinese)将每个切片转化为768维向量。模型部署于GPU服务器,支持批量推理。
向量存储:使用Milvus等向量数据库,建立索引,存储向量及对应的元数据(政策来源、生效日期、所属领域等)。为提升检索速度,采用IVF_PQ索引。
(可选)4、结构化知识库
FAQ库:从历史咨询工单中提取高频问答对,人工审核形成标准问答库(Q&A Pair),用于兜底回答和微调训练。
知识图谱(graphrag):对政策条款之间的关联(如“高龄津贴”与“户籍地”“年龄”的依赖关系)进行图谱化,支持复杂推理。
三、意图识别与路由
在用户输入(语音或文字)后,系统需快速判断用户意图,决定调用哪个技能或知识模块。
1、语音转文字(ASR)
技术:采用科大讯飞或阿里云ASR服务,支持当地方言,并针对社保、医保等专业术语进行热词定制,提升识别准确率。
部署:线上服务调用API,线下终端可内置离线ASR引擎,确保网络不稳定时仍能工作。
2、意图分类
模型:使用轻量级BERT模型(如bert-base-chinese)在政务咨询语料上微调,将用户问题分类至预设的10~20个粗粒度类别(如:社保咨询、医保报销、高龄津贴申请、办事地点查询等)。分类器部署于CPU,响应时间<50ms。
路由规则:根据意图类别,选择对应的处理流程:(1)高频标准化问题->直接匹配FAQ库回答;(2) 政策查询类(后面专门一章节讲解)->进入RAG检索增强生成;(3)、办事资讯类(后面专门一章节讲解):调用流程知识库,输出分布指引。(4)、复杂对话(后面专门一章节讲解):进入多轮对话
3、实体抽取
技术:采用序列标注模型(如BERT-BiLSTM-CRF)抽取关键实体,如“年龄”“户籍地”“缴费年限”等,为后续检索提供过滤条件。
示例:“我今年65岁,住在莲花社区,能领什么补贴?” → 实体{年龄:65, 居住地:莲花社区},用于检索相关补贴政策。
四、检索增强生成(RAG)
1、检索阶段
混合检索:(1)向量语义检索:将用户问题向量化,在milvus中检索最相似的5-10个知识片段,返回相关度得分。(2)关键词检索:同时使用elasticsearch对用户问题进行bm25关键词匹配,召回包含高频词的政策 (3)融合排序
重排序:引入交叉编码器(如bge-reranker-large)对召回片段进行精确重排,进一步提升相关性。
2、提示词构造
模板设计:
你是一名社区政务助手,请根据以下政策原文,准确回答居民的问题。如果政策原文中没有相关信息,请明确告知“目前暂未查到相关政策,建议咨询窗口工作人员”。请严格引用原文。政策原文:{context}居民问题:{question}回答:
动态注入
3、生成阶段
大模型:选用通义千问(Qwen2.5-32B)或智谱GLM-4,在政务领域进行指令微调,增强对政策术语的理解和引用能力。
推理加速:部署时使用vLLM或TensorRT-LLM进行量化推理,保证单次回答延迟<3秒。
输出规范:生成内容需包含:
五、办事指南类
1、数据来源与结构化
数据来源:社区提供的办事指南手册、政务服务网办事指南页面、内部操作规程、窗口工作人员经验总结。
结构化抽取:采用人工+大模型结合的方式,将每个办事事项抽取为固定格式的流程对象。例如:
{"item_name": "高龄津贴申请","target_audience": "年满80周岁、户籍在本社区的老年人","required_materials": ["身份证复印件", "户口本首页及本人页", "近期免冠照片2张", "本人银行卡复印件"],"steps": [{"step_no": 1, "description": "携带材料到社区党群服务中心窗口", "tips": "建议避开每月1-5日高峰期"},{"step_no": 2, "description": "填写《高龄津贴申请表》", "tips": "可请工作人员协助填写"},{"step_no": 3, "description": "等待审核,约15个工作日", "tips": "审核结果会以短信通知"}],"processing_time": "15个工作日","fee": "免费","contact_phone": "12345转社区","online_channel": "可通过浙里办APP在线申请(仅限部分街道)"}
存储方式:结构化数据存入关系型数据库(如MySQL)的“办事指南表”,便于精确检索和字段填充。同时将文本描述部分切片,存入向量数据库,支持语义匹配。
2、流程知识的分类与索引
为每个办事事项打上标签:所属领域(社保、医保、养老等)、适用人群(老年人、残疾人等)、办理方式(线上/线下/混合)。
建立倒排索引,支持关键词快速检索(如“高龄津贴”“办社保”)。
3、意图识别与路由
当用户输入“我要办高龄津贴”时,系统经过意图识别,判定为“办事指南类”。
(1)、意图分类
轻量级BERT分类器输出类别为guide_inquiry(办事指南咨询)。
实体抽取提取关键实体:办事事项=高龄津贴。
(2)、流程匹配
精确匹配:首先在关系型数据库中通过事项名称关键词(如“高龄津贴”)进行精确匹配,若找到唯一事项,则直接调用该流程对象。
模糊匹配:若精确匹配失败(如用户说“领老人钱”),则使用向量检索,将用户问题与流程对象的描述字段(如事项名称、适用人群、步骤描述)进行语义相似度计算,取最相似的前3个候选,再由模型或规则选择最相关的一个。
4、分步指引生成
匹配到流程对象后,系统需要生成友好、清晰的分步指引。生成方式分为两类:模板填充和大模型增强。
(1)、模板填充(首选,保证格式稳定)
对于标准办事事项,使用预先设计的回答模板,将结构化数据动态填充:
【事项名称】{item_name}【办理对象】{target_audience}【所需材料】{required_materials}【办理步骤】{steps}【办理时限】{processing_time}【费用】{fee}【咨询电话】{contact_phone}【温馨提示】{tips}
例如输出:
高龄津贴申请
办理对象:年满80周岁、户籍在本社区的老年人
所需材料:身份证复印件、户口本首页及本人页、近期免冠照片2张、本人银行卡复印件
办理步骤:
携带材料到社区党群服务中心窗口(建议避开每月1-5日高峰期)
填写《高龄津贴申请表》(可请工作人员协助)
等待审核,约15个工作日(审核结果会以短信通知)
办理时限:15个工作日费用:免费咨询电话:12345转社区
(2)、大模型增强(处理复杂或模糊情况)
若匹配到多个相似事项,或用户有额外约束(如“我腿脚不便,有没有线上办理?”),则使用大模型进行二次生成:
构造提示词,包含候选流程对象、用户问题、附加信息。
要求大模型以自然语言生成分步指引,并强调必须基于给定的材料清单和步骤,不能凭空捏造。
示例提示:
你是一名社区政务助手。用户想办理“高龄津贴”,但希望知道能否线上办理。以下是该事项的标准流程信息:{流程对象JSON}请结合用户需求,给出办理指南,优先介绍线上渠道(如有),并列出材料和步骤。
3.3 多模态输出
文字:以列表、表格等形式展示,便于阅读。
语音:对于线下终端,将关键步骤转为语音播报,同时屏幕显示文字。
二维码:若事项支持线上办理,自动生成办理入口二维码。
5、动态辅助信息
除了固定流程,系统还需根据用户实际情况动态补充辅助信息。
(1)、个性化提醒
根据用户画像(如年龄、户籍)自动判断是否符合条件,并给出提醒。例如用户65岁问“高龄津贴”,系统回复:“您目前尚未达到80周岁,符合条件后请携带……材料办理。”
若用户提供的位置信息,可自动匹配最近的办理地点。
(2)、多渠道办理指引
若事项同时支持线上、线下,系统输出两种方式,并对比优缺点(如线上省时、线下有专人指导)。
提供链接或二维码直达线上办理入口。
6、完整示例流程
用户输入:“我想申请高龄津贴,需要带什么?去哪里办?”
意图识别:办事指南类,实体:高龄津贴。
流程匹配:从流程知识库中检索到“高龄津贴申请”对象。
生成回答:
输出:显示结构化文本,同时语音播报关键步骤。
7、技术实现组件
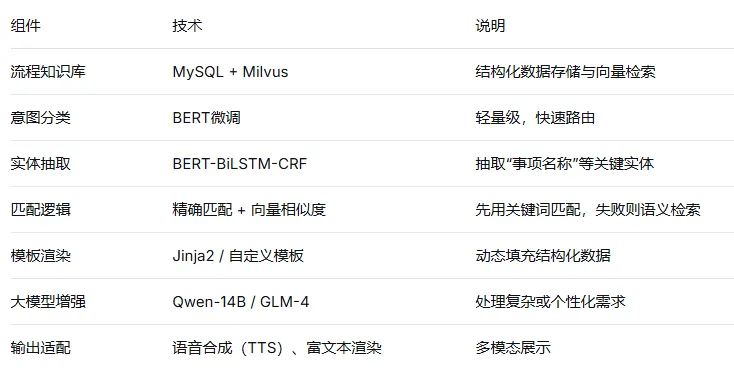
六、多轮对话管理
1、总体架构
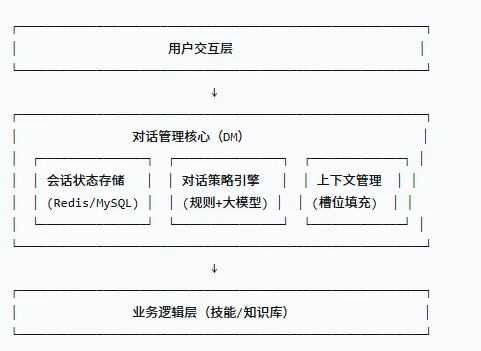
2、会话状态存储
技术选型:Redis(高性能、支持过期时间)为主存储,MySQL做持久化备份。
存储内容:
生命周期:会话保留30分钟无活动自动过期;若用户登录,可跨会话持久化用户画像。
3、上下文理解和槽位填充
(1)、什么是槽位
每个办事事项预定义一组必要槽位,例如:
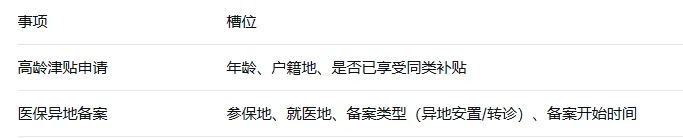
(2)、槽位提取
初始轮:从用户输入中通过实体识别(BERT-BiLSTM-CRF)提取槽位值。
后续轮:结合对话历史,通过上下文解析补全省略内容(如“我是本社区的” → 更新户籍槽位)。
规则补充:对于敏感信息(如身份证号),可在提示中引导用户提供,或调用第三方接口校验(如政务身份认证)。
(3)、槽位填充驱动
当用户首次表达意图后,系统启动该任务对应的槽位填充流程。
根据缺失槽位列表,生成追问。例如:
(4)、槽位校验
对槽位值进行格式/逻辑校验(如年龄应为数字且≥0;户籍地应与社区行政区划匹配)。
若校验失败,要求用户重填。
4、对话策略引擎
对话策略决定系统在每一步应该做什么(追问、澄清、执行动作、结束)。采用规则+大模型混合策略。
(1)、规则引擎(确定性流程)
适用于任务明确、步骤固定的场景,如办事指南、预约等。
(2)、大模型驱动(灵活对话)
适用于开放式咨询、意图模糊、需要自然交互的场景。
将当前会话状态(历史、槽位、缺失信息)构造成提示,输入大模型,由模型决定下一轮回复内容和动作。
提示模板示例:
你是一名社区政务助手。当前对话状态:用户意图:{intent}已收集信息:{slots}缺失信息:{missing_slots}对话历史:{history}请根据以上信息,生成一句友好的追问,引导用户提供缺失信息。如果已收集完整,请给出最终答案或执行动作。
5、上下文管理
短期记忆:保留最近5~10轮对话的完整内容(用户输入、系统回复、意图、槽位),用于上下文消歧。
长期记忆:若用户登录,可存储用户画像(年龄、常用地址、历史咨询记录),用于个性化推荐。
跨任务上下文:当用户在一个对话中切换话题(如先问高龄津贴,再问社保卡),系统需保留原任务状态,允许用户随时返回。可采用栈结构管理多任务上下文。
6、对话流程控制
(1)、主循环
接收用户输入(文本或语音转文字)。
更新会话状态(记录新轮次)。
意图识别 + 实体抽取。
判断是否属于当前任务:
生成回复(模板填充/大模型生成)。
更新会话状态(包括槽位、历史、当前任务状态)。
输出回复(文本/语音)。
(2)、异常处理
超时:用户长时间未回复,可发送提醒消息(如“您还在吗?需要继续办理吗?”)。
跳出任务:用户突然问无关问题,系统可先回答,再询问是否继续原任务。
槽位收集失败:多次追问无果,可提供人工客服入口。
7、示例:高龄津贴申请多轮对话
用户:“我想申请高龄津贴。”
系统(意图识别为“高龄津贴申请”,启动任务):
当前缺失槽位:年龄、户籍、是否已享受同类补贴。
策略:规则驱动,逐个追问。
系统:“请问您的年龄?”
用户:“我80岁了。”
系统(更新槽位age=80):“好的。您的户籍是在本社区吗?”
用户:“是的,我住在莲花社区。”
系统(更新residence=莲花社区):“请问您是否已享受其他高龄或养老补贴?”
用户:“没有。”
系统(所有槽位收集完毕):
调用资格校验(年龄≥80,户籍在本社区,无冲突补贴) → 通过。
生成回复:“您符合高龄津贴申请条件。请携带以下材料到社区党群服务中心窗口办理:身份证复印件、户口本首页及本人页、近期免冠照片2张、本人银行卡复印件。办理时限15个工作日,免费。如需线上办理,可下载‘浙里办’APP搜索‘高龄津贴’。”
用户:“线上办理怎么操作?”
系统(上下文切换至新话题,但保留原任务状态):
给出线上办理指引:“在APP中点击‘办事’→‘个人服务’→‘老年人’,选择‘高龄津贴申请’,按提示上传材料即可。”
随后询问:“您还需要其他帮助吗?或者继续办理高龄津贴?”
用户:“谢谢,暂时不需要了。”
系统:结束对话,清理任务状态。
七、反馈与持续优化
系统需具备闭环迭代能力,随着使用不断优化。
(1)、用户反馈收集
显式反馈:在回答下方设置“有用/无用”按钮,收集用户评价。
隐式反馈:记录用户是否在收到回答后继续提问或跳出,作为间接质量指标。
(2)、日志与监控
全链路日志:记录每次问答的意图、检索片段、生成答案、用户评分,存入数据仓库。
监控指标:响应时间、意图识别准确率、检索召回率、用户满意度等,实时可视化展示。
(3)、模型与知识库更新
定期微调:每月根据积累的标注数据对意图分类器和大模型进行增量微调。
知识库增量更新:新政策文件入库后自动触发切片与向量化,旧政策标记“已失效”,确保知识时效性。
FAQ库扩展:从用户实际咨询中提取新的高频问答,经人工审核后加入FAQ库,作为快速响应来源。
八、技术架构总览
┌──────────────────────────────────────────────────────────┐│ 用户交互层 ││ 语音输入/文字输入/图片上传 → ASR/OCR → 文本 │└──────────────────────────────────────────────────────────┘↓┌──────────────────────────────────────────────────────────┐│ 意图识别层 ││ 意图分类(BERT)→ 实体抽取(BERT-BiLSTM-CRF) │└──────────────────────────────────────────────────────────┘↓┌──────────────────────────────────────────────────────────┐│ 高频标准化问题 ││ 政策查询类 |│ 办事指南类 |│ 复杂对话 |└──────────────────────────────────────────────────────────┘↓┌──────────────────────────────────────────────────────────┐│ 生成层 ││ 大模型(Qwen2.5-32B/GLM) + 提示词模板 ││ ↓ ││ 答案生成(含政策引用) │└──────────────────────────────────────────────────────────┘↓┌──────────────────────────────────────────────────────────┐│ 后处理与反馈层 ││ 事实核查 → 格式化 → 语音合成 → 多轮状态更新 → 用户评价 │└──────────────────────────────────────────────────────────┘