 夜雨聆风
夜雨聆风





LED: 文档版面分析的"体检报告"来了——八类结构错误,你的模型能发现几个?
论文:LED: A Benchmark for Evaluating Layout Error Detection in Document Analysis
机构:忠南大学 · 2026-03-21 · arxiv
TL;DR
-
忠南大学团队提出 LED (Layout Error Detection),专门评估文档版面分析中结构错误的新基准 -
定义了 8 种标准化错误类型:Missing、Hallucination、Size Error、Split、Merge、Overlap、Duplicate、Misclassification -
构建了基于 DocLayNet 的合成数据集 LED-Dataset(4,996 张文档图片,约 70,000 个版面元素) -
设计了三个层次化评测任务:文档级错误检测、错误类型分类、元素级错误分类 -
实验结果:Gemini 2.5 Pro 全面领先,GPT-4o 粗粒度检测强但细粒度推理弱
一、问题:IoU 和 mAP 够用吗?
文档版面分析(Document Layout Analysis, DLA)是文档AI的基础任务——把一页文档分解为文本块、表格、图片等区域。现有的 YOLO、Deformable-DETR 等检测模型虽然在 mAP 上不断刷分,但实际使用中依然频繁出现结构性错误:明明是一个段落被拆成了两块(Split),两个不相关的区域被合并(Merge),或者某个元素完全漏掉(Missing)。
问题在于,IoU 和 mAP 这类传统指标只关注空间重叠度,根本无法捕捉这些逻辑层面的不一致。你的模型 mAP 可能很高,但文档理解的下游任务却一塌糊涂——因为结构乱了。
LED 就是要填补这个空白:不只看”检测准不准”,还要看”结构对不对”。
二、核心创新:八类错误的标准化定义

LED 的第一个贡献是对 DLA 中常见的结构错误进行了系统化、可量化的定义,并为每种错误配备了规则化注入算法:
|
|
|
|
|---|---|---|
| Missing |
|
|
| Hallucination |
|
|
| Size Error |
|
|
| Split |
|
|
| Merge |
|
|
| Overlap |
|
|
| Duplicate |
|
|
| Misclassification |
|
|
其中 Split、Merge 和 Overlap 是 LED 新引入的文档特有类型——这些恰恰是传统目标检测诊断框架(如 TIDE、ObjectLab)所忽略的。
三、LED-Dataset:基于真实错误分布的合成基准

图1:LED-Dataset 示例。红框为含错误的预测框,绿框为真实标注。
LED-Dataset 基于 DocLayNet 测试集构建,通过规则化注入算法生成。关键设计理念:错误注入的概率分布来源于真实商用DLA模型的预测(maskrcnn_dit_base),而不是均匀随机。
最终数据集包含 4,996 张文档图片和约 70,000 个版面元素。错误分布极不均衡:
- Missing
:64.89%(最多) - Hallucination
:14.69% - Size Error
:10.97% - Misclassification
:8.77% -
Split、Merge、Overlap、Duplicate 合计不到 2%
这种长尾分布恰恰反映了现实中DLA模型的失败模式。
四、三层评测任务:从”有没有错”到”哪里错了”
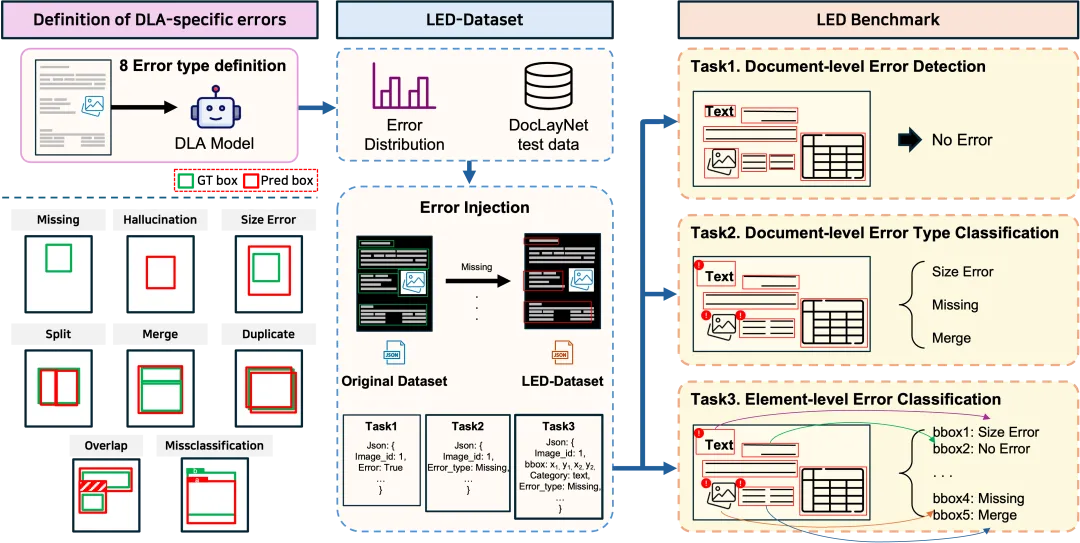
图2:LED框架整体架构。定义八类错误,构建LED-Dataset,通过T1/T2/T3三个任务进行层次化评估。
LED 设计了三个递进式任务:
T1:文档级错误检测(二分类)
判断一份文档的版面预测中是否存在任何结构错误。评估指标:Accuracy。
T2:文档级错误类型分类(多标签)
识别文档中存在哪些类型的错误。每份文档对应一个 8 维二值向量。评估指标:F1-score。
T3:元素级错误分类(细粒度)
对每一个预测框进行错误分类——是 Missing、Split 还是”正确”。这是最难的任务,要求模型精确定位并诊断。
五、实验结果:Gemini 碾压,GPT 偏科,LLaMA 掉队
论文在 8 个主流多模态模型上进行了零样本评估:
|
|
|
|
|
|---|---|---|---|
| Gemini 2.5 Pro |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
关键发现:
1. Gemini 全面领先:从 Flash Lite 到 Flash 到 Pro,F1 稳步提升(0.229 → 0.372 → 0.490),更大的模型规模确实带来更好的结构理解能力。
2. GPT 系列”偏科”:GPT-4o 在 T1 表现不错,但 T2/T3 急剧下降。有趣的是,较小的 GPT-4o-mini 在 T3 上反而优于 GPT-4o(0.159 vs 0.066),小模型在特定错误模式上可能保留了更强的专注力。
3. 开源模型差距明显:DeepSeek V3 和 LLaMA 4 在 T3 上 F1 接近零,尚未针对文档结构推理进行优化。
4. 输入方式很重要:提供 JSON 结构化数据始终优于仅提供可视化叠加框,结构化文本信息对推理的贡献大于纯视觉线索。
六、行业启示
- 对文档AI产品
:LED 提供了标准化的质量诊断工具。传统指标告诉你”准不准”,LED 告诉你”哪里有问题、什么类型的问题” - 对模型开发者
:当前多模态模型在文档结构理解上仍有很大提升空间,尤其是 Missing 和 Size Error 这类空间推理相关的错误 - 对评测体系
:仅靠 IoU/mAP 远远不够。LED 的层次化评测思路值得借鉴
七、局限性
-
数据集仅基于 DocLayNet,领域覆盖有限 -
未纳入基线检测质量作为变量 -
合成错误与真实错误之间仍存在分布差异
八、总结
LED 填补了文档版面分析中结构错误诊断的空白。它不仅定义了一套完整的错误分类体系,还通过合成数据集和三级评测任务,首次系统性地揭示了当前多模态模型在文档结构理解上的能力与不足。对于追求文档AI质量的团队来说,LED 是一个值得关注的新基准。