第一章:引子——一个 60MB 的调试文件,炸出了行业最贵的秘密3月31日,深夜。一个叫 Chaofan Shou 的安全研究员盯着屏幕,表情有点奇怪。他刚刚下载了 Claude Code 最新版本的 npm 包,准备做例行的安全分析。但有一个细节让他停了下来——这个包的体积,从上一个版本的 17MB,突然涨到了 31MB。多出来的 14MB,藏在哪里?他打开文件目录,一个一个往下翻。然后他看到了一个后缀为 .map 的文件,57MB,安静地躺在那里,像一枚没有被引爆的手雷。他点开。沉默了几秒。这是一个 source map 文件。对于前端开发者来说,这东西再熟悉不过——它是专门用于调试的辅助文件,里面包含了从编译后的 JavaScript 代码反推回去的完整 TypeScript 原始源码。它的存在意义是:当线上代码出了问题,工程师可以通过它还原出原始代码,方便定位 bug。它本应在发布前被排除在外。但这一次,没有。Anthropic 把 Claude Code 的完整源码,亲手打包进了自己对外发布的 npm 包里。任何人,只要下载这个包,打开这个文件,就能看到完整的 TypeScript 源代码。不需要任何技术手段,不需要任何授权,就像走进一家银行,发现金库的门没有关上。几分钟后,Chaofan Shou 在 X 上发了一条推文,没有什么煽情的语言,就是一句话:“Claude code source code has been leaked via a map file in their npm registry!”这条推文,像一颗石子扔进了平静的湖面。接下来的事情,有点像一场有组织的”知识抢劫”——完全合法,但速度极快。有人立刻把源码同步到了 GitHub,建了一个公开仓库。有人写脚本批量下载存档。有人开始逐文件分析,把实时发现发到 X 上。开发者社区的群消息开始刷屏,转发速度肉眼可见地加快。几个小时内,这个 GitHub 仓库的 Star 数冲到了数万,Fork 数同样以惊人的速度攀升。大家都清楚一件事:Anthropic 一旦反应过来,会立刻发起 DMCA 投诉,仓库会被强制删除。所以每个人都在抢时间——不是为了”偷”什么,而是为了在窗口关闭之前,把这份难得的学习材料留存下来。而更让人哭笑不得的是:这已经不是 Anthropic 第一次犯这个错误了。在 Claude Code 刚发布的早期版本,一模一样的事情就发生过一次。那次被发现了,修复了,构建脚本加上了排除规则。然后,时间过去了将近一年。某次版本迭代中,构建配置被改动了,排除规则不知道为什么失效了。前一个版本 v2.1.87 还是干净的,v2.1.88 一发布,source map 又回来了。一家市值数百亿美元的顶尖 AI 公司,用自己的双手,把自己的源码推送到了全世界每一个下载这个 npm 包的人的电脑上。我看到这条消息的时候,正在用 Claude Code 拆一个产品需求文档。我每个月给 Claude 付 200 美元,几乎每天都在用它写代码、写文章、拆需求、做竞品分析。用了这么久,我一直知道它”好用”,但如果你认真问我:它到底好用在哪里?为什么它比其他工具感觉更稳?老实说,我之前只能给出一些模糊的答案:”感觉模型强””上下文比较稳””不容易乱删文件””出错之后恢复得快”。这些答案都对,但都停留在”感觉”层面。我没办法把它说清楚,更没办法把它变成可以复用的产品方法论。而现在,答案第一次被完整地摊在我面前。1902 个文件,51.2 万行 TypeScript 代码。我让 Claude Code 帮我一起读完了它自己的源码——这件事本身就有点超现实。这不是一次单纯的”源码事故”。对产品经理来说,这是一份几乎不可能再出现第二次的竞品分析样本。它不是竞品的 PPT,不是公关口径,不是对外宣传的技术博客,而是真实的、生产级别的、一行一行写在代码里的产品决策。第二章:我翻源码之前的预期,和翻完之后的震惊在真正开始读这 51 万行代码之前,我心里其实是有预期的。作为一个长期使用 Claude Code 的人,我以为我会在源码里看到的,是这些东西
大量复杂的模型调用逻辑,各种精心设计的 API 调用策略
各种参数调优配置,temperature、top_p 之类的精细控制
一些”黑魔法”式的 prompt 技巧,通过特定的语言模式让模型表现得更聪明
可能还有一些对模型输出做后处理的逻辑,过滤、校验、重试
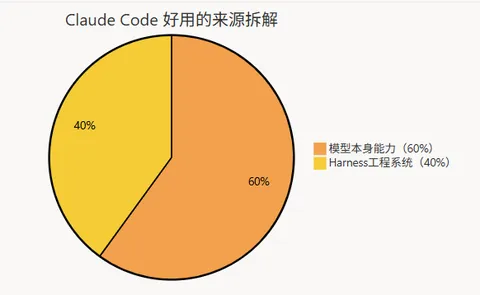
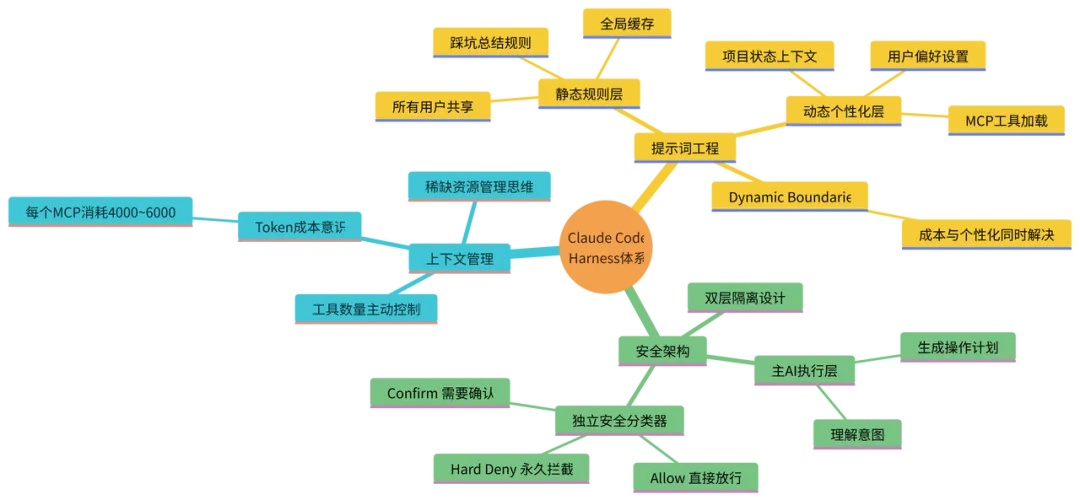
但真正让我震惊的,是这些反而不是重点。当然,这些东西都存在,但它们不是 Claude Code 区别于其他工具的核心。翻到中段之后,我逐渐形成了一个非常清晰的判断:Claude Code 好用,大约 60% 来自模型本身的能力——Opus 系列模型确实比很多竞品更强。但另外 40%,来自围绕模型构建的一整套工程系统。而这 40%,才是这次泄露真正的价值所在。在 AI 产品圈,今年有一个被 OpenAI 和 Anthropic 都反复提及的概念,叫 Harness(控制系统)。理解这个概念,有一个非常直观的比喻:把 AI 模型想象成一匹野马。它力量极强,速度极快,但输出难以预测——你不知道它下一步会往哪个方向跑,会不会突然停下来,会不会把骑手甩出去。Harness,就是套在这匹野马身上的那套装备。缰绳、马鞍、方向盘、护栏。Harness 决定的不是这匹马”能跑多快”,而是:
它会不会突然冲出赛道,做出用户完全没有预期的操作
它会不会把骑手甩下来,把用户的项目搞得一团糟
它能不能在正确的时间、正确的地点稳定停下来,把任务交付给用户
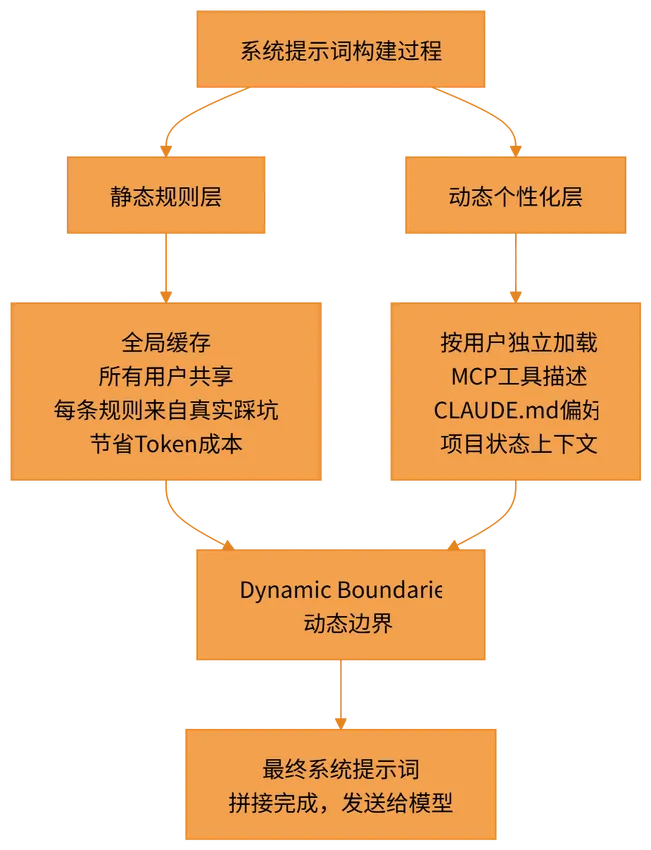
一个没有 Harness 的 AI 产品,就算模型再强,用户也不敢真正依赖它。而 Claude Code 的源码,几乎就是一份 Harness Engineering 的实战教科书。接下来,我想分享三个让我印象最深的发现。它们各自对应 Harness 体系的一个核心模块,每一个都是那 40% 的重要组成部分。第三章:发现一——系统提示词不是”一段话”,而是一套工程决策大多数人理解的系统提示词,大概是这样的:“你是一个专业的编程助手,请认真帮助用户解决问题,回答要简洁清晰,如果不确定请说不知道……”这种写法在很多 AI 产品里都能看到。它不能说错,但它本质上是一种”写给模型看的说明书”,是单向的、静态的、一次性的。但在 Claude Code 的源码里,系统提示词根本不是这么一回事。它是一整套工程系统,有架构,有分层,有明确的设计意图。1. Prompt 不是一个文件,是一个系统在源码中,你会看到大量类似 prompt.ts、prompt-builder.ts、system-prompt.ts 的文件,分布在多个目录下,数量之多,第一眼看到会有点发懵。打开之后你会发现,它们不是纯文本,而是高度结构化的拼接逻辑。整个系统提示词被切分成两个截然不同的层次,像一座建筑的承重墙和可移动隔断:第一层:静态规则层(全局共享缓存)这一层的特点非常鲜明:内容固定,所有用户共享,不随个人偏好变化。它里面写的,是一系列关于”Claude Code 应该怎么行事”的具体规则。注意,是具体规则,不是模糊的价值观表达。比如,源码里明确包含这样的规则:
不要编造不存在的函数或 API,如果不确定就说不确定
不要随意删除用户文件,除非被明确要求,且要再次确认
优先使用专用工具完成任务,而不是用通用方案绕路
不要过度工程化,不要在用户没有要求的情况下增加抽象层
不要添加用户没有明确要求的功能,哪怕你觉得那个功能”很有用”
在执行不可逆操作之前,优先询问用户,而不是假设用户同意
读到这里,我的第一感受是:这些规则没有一句是废话,也没有一句是”正确的废话”。所谓”正确的废话”,就是那种听起来很对、但对模型行为没有任何约束力的表述,比如”请保持专业””请尽量准确”。Claude Code 的静态规则层里,几乎找不到这类表述。每一条规则都非常具体,具体到你可以想象出它背后的失败场景。”不要随意删除用户文件”——这背后一定有某个版本的 Claude 把用户文件删光了的真实事故。”不要添加用户没有要求的功能”——这背后一定有某个版本的 Claude 把一个简单需求”优化”成了一个用户完全不认识的复杂系统。这些规则,是从真实的生产失败里蒸馏出来的产品知识。更重要的是,这一层内容会被全局缓存。全球几百万用户共用同一份静态规则,不需要每次请求都重新加载和计算,极大地降低了整体的 token 成本。第二层:动态个性化层(按用户独立加载)这一层与静态层完全相反:内容因人而异,按项目状态动态拼接,每次请求都可能不同。它包含的内容大致有:
你在这个项目里接入的 MCP 工具列表及其描述
你通过 CLAUDE.md 文件设置的项目级偏好和规范
你之前让 Claude 记住的个人偏好,比如”我喜欢用 TypeScript,不喜欢用 any 类型”
当前仓库的状态描述,比如项目结构、主要技术栈等
这一层让每个用户的 Claude Code 都有自己的”个性”,同时又不影响全局规则的稳定性。2. Dynamic Boundaries:一刀切出两个世界Anthropic 在这里做了一个让我印象极深的架构设计,叫 Dynamic Boundaries——动态边界。它的核心思路用一句话说清楚:把”所有人都需要的规则”和”每个人独有的上下文”,在系统层面明确切开,分别处理,分别缓存。这条边界线,同时解决了两个长期矛盾的产品问题成本控制:静态规则层全局缓存,不需要每次请求都重新计算,节省大量 token 开销。个性化体验:动态层独立加载,保证每个用户的 Claude Code 都能感知到自己的偏好和项目状态。这两个目标,在没有 Dynamic Boundaries 之前,是互相矛盾的——要个性化就要每次重新加载,要节省成本就要牺牲个性化。Dynamic Boundaries 用一个架构决策,把这个矛盾化解了。产品启示: 系统提示词的质量,本质上是产品经理对用户场景理解深度的直接体现。大多数 AI 产品的提示词写得平庸,不是因为工程师不努力,而是因为没有人认真做过”哪些规则是所有用户共性需要的,哪些内容是每个用户独有的”这个分析。这是产品经理的责任,不是工程师的。更进一步说,提示词里每一条具体规则的背后,都应该有一个真实的用户失败场景作为支撑——如果你写不出这个场景,这条规则大概率是废话。第四章:发现二——Claude Code 背后,其实跑着两个 AI如果你用过市面上多款 AI 编程工具,大概率遇到过这样的噩梦:让 AI 帮你重构一个函数,结果它顺手把相关的三个文件也”优化”了,而且改得面目全非。让 AI 跑一条测试命令,结果它直接执行了一条你没想到的清理命令,把本地环境搞乱了。一步操作走错,项目陷入混乱,回滚都困难。这类事故在 AI 编程工具的早期版本里极为常见,也是很多开发者不敢在真实项目里用 AI 工具的核心原因——不是不信任模型的能力,而是不信任模型的边界感。而 Claude Code 给人的一个非常强烈的感受是:稳。它很少”翻车”。即使在 auto 模式下,它对高风险操作的处理也明显比其他工具保守和谨慎。用它做开发,你不会时刻提心吊胆,不会觉得需要一直盯着它防止它做出什么意外的事情。源码告诉了我背后的原因。1. 一个 AI 负责干活,另一个 AI 专门”审判”在 Claude Code 的源码里,有一个文件名非常有意思,叫 yolo-classifier。YOLO,You Only Live Once,活在当下,放手去干。但这个文件实际做的事情,和 YOLO 精神完全相反——它是整个系统里最谨慎、最保守的一个模块。每当主 AI 想要执行一个操作——比如写文件、运行 shell 命令、修改系统配置、调用外部 API——都不会直接执行,而是先触发这个独立的安全分类器。这个分类器有完全独立的系统提示词,和主 AI 的提示词毫无关联,它的职责只有一个:判断这个操作,安不安全。它的判断结果只有三种,没有模糊地带,没有”视情况而定”:
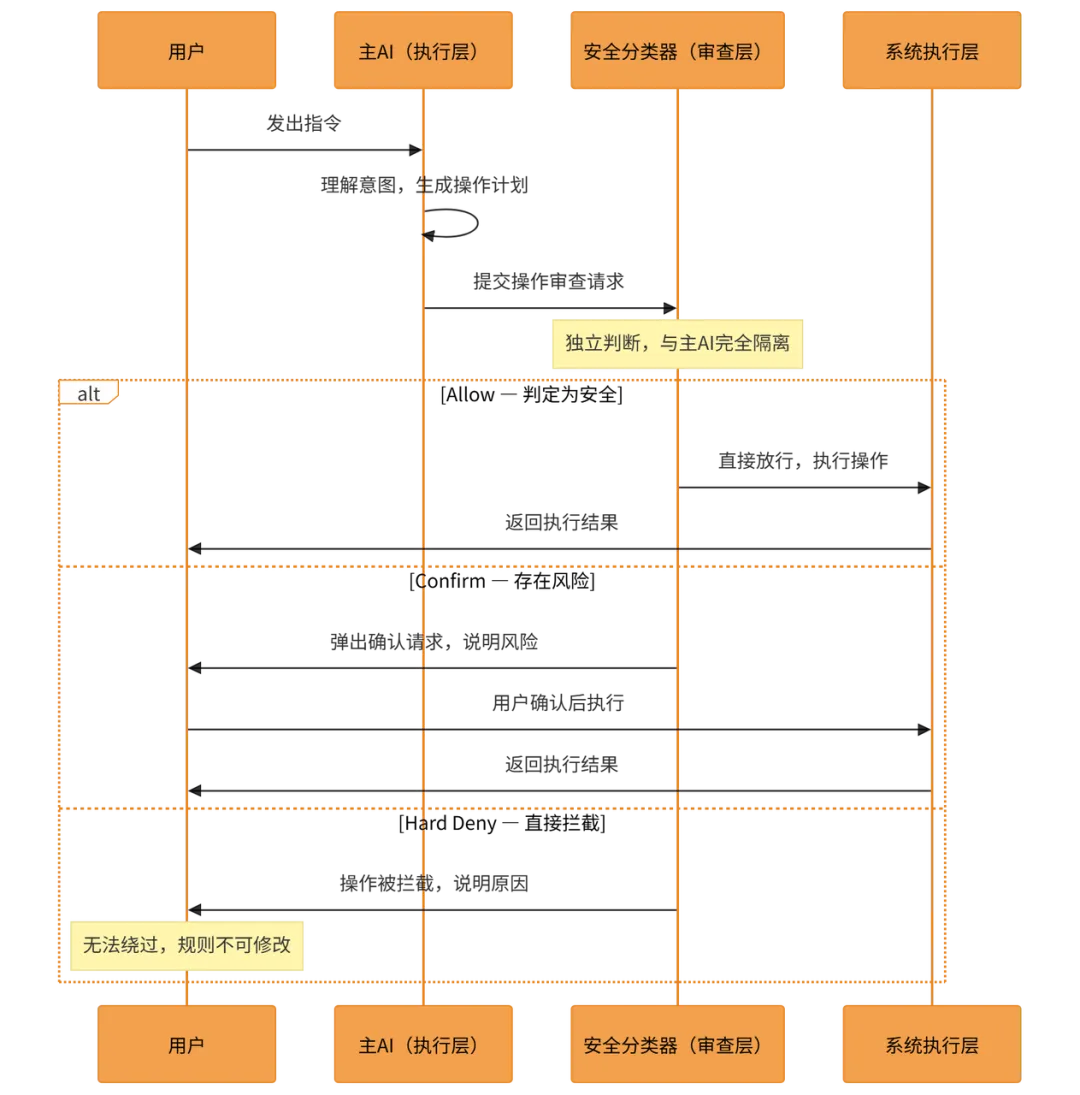
Allow(放行):操作被判定为安全,直接执行,用户无感知
Confirm(确认):操作存在潜在风险,需要用户手动确认才能继续
Hard Deny(硬性拦截):操作被直接拦截,用户无法绕过,规则写死,不可修改
2. 为什么这个设计如此重要?因为它把一个模糊的信任问题,转化成了一个清晰的架构问题。很多 AI 产品在面对”AI 会不会做危险操作”这个问题时,给出的答案是:“我们会继续优化模型,让它更聪明,更准确,更有边界感。”这个答案听起来合理,但它本质上是在说:我们把安全寄托于概率。模型越来越强,犯错的概率越来越低,但永远不会是零。而 Claude Code 的答案是:“我们不依赖主模型的自我约束,我们在架构层面建了一道独立的审查机制,它和主模型是完全隔离的。”这两种思路的本质差异在于:前者把安全建立在模型的”自律”上,后者把安全建立在系统的”他律”上。用一个更直观的比喻来理解这套设计——它非常像一栋写字楼的多重门禁系统:
第一道:刷工卡自动通过,日常进出无感,覆盖 80% 的场景
第二道:保安核验身份,确认是员工,处理有疑问的情况
第三道:特殊楼层需要额外授权确认,不是谁都能进
第四道:核心机房永久禁区,任何人都无法进入,规则写死在系统里
Claude Code 的安全机制,就是这样一套分层的、有明确边界的、不依赖单点判断的门禁体系。Claude Code 很少”翻车”,不是因为它的模型从不犯错,而是因为错误在到达用户之前,就被独立的安全层拦截了。产品启示: AI 产品的安全感,不是靠”模型更聪明”来解决的,而是靠工程架构设计出来的。这是产品经理需要主动推动的决策——你需要问清楚:我们的产品里,有没有独立于主模型的安全审查层?这个层的判断逻辑是谁来定义的?哪些操作属于 Hard Deny,这个清单是怎么来的,谁来维护?这些问题如果没有清晰的答案,AI 产品的稳定性就永远依赖运气,而不是设计。第五章:发现三——工具不是越多越好,每个 MCP 都在偷吃你的上下文这是我个人觉得最反直觉、但对产品经理来说也最有实际价值的一个发现。在 AI 产品的功能规划里,有一种非常常见的思维定势:功能越多越好。工具越丰富,产品越强大。这个逻辑在传统软件产品里基本成立。多一个功能,多一个用户价值,顶多增加一点界面复杂度,对核心功能的影响几乎可以忽略不计。但在 AI 产品里,这个逻辑是危险的。源码和相关文档里明确揭示了一个大多数用户和产品经理都不知道的事实:每一个 MCP 工具的描述文件,都会消耗 4000\~6000 个 token 的上下文空间。这个数字,乍一听好像不大。但换算一下就会发现问题的严重性:
 夜雨聆风
夜雨聆风