夜雨聆风
夜雨聆风





Claude Code源码外泄 – 14条提示词背后藏着什么Agent管理哲学
最近 Claude Code 源码泄露的事,大家多半都知道了。流传出来的目录里,近 2000 个源文件被完整还原,一行不差,全世界的开发者都在翻。
能学的太多,今天先聊最接地气的一块:提示词。
我整理了 14 条——每一条我觉得普通人写日常提示词都能直接套用,不限于写代码。源码里对应的英文原文,我也收进同一份 PDF 文档里了,文末加我微信备注「提示词」可以领取。
逐条拆之前先说一句总印象:这些规则表面在约束模型,读起来却很像给高度自主的同事定规矩——禁令怎么写、授权怎么收口、汇报怎样才算数。下面从第 1 条说起。
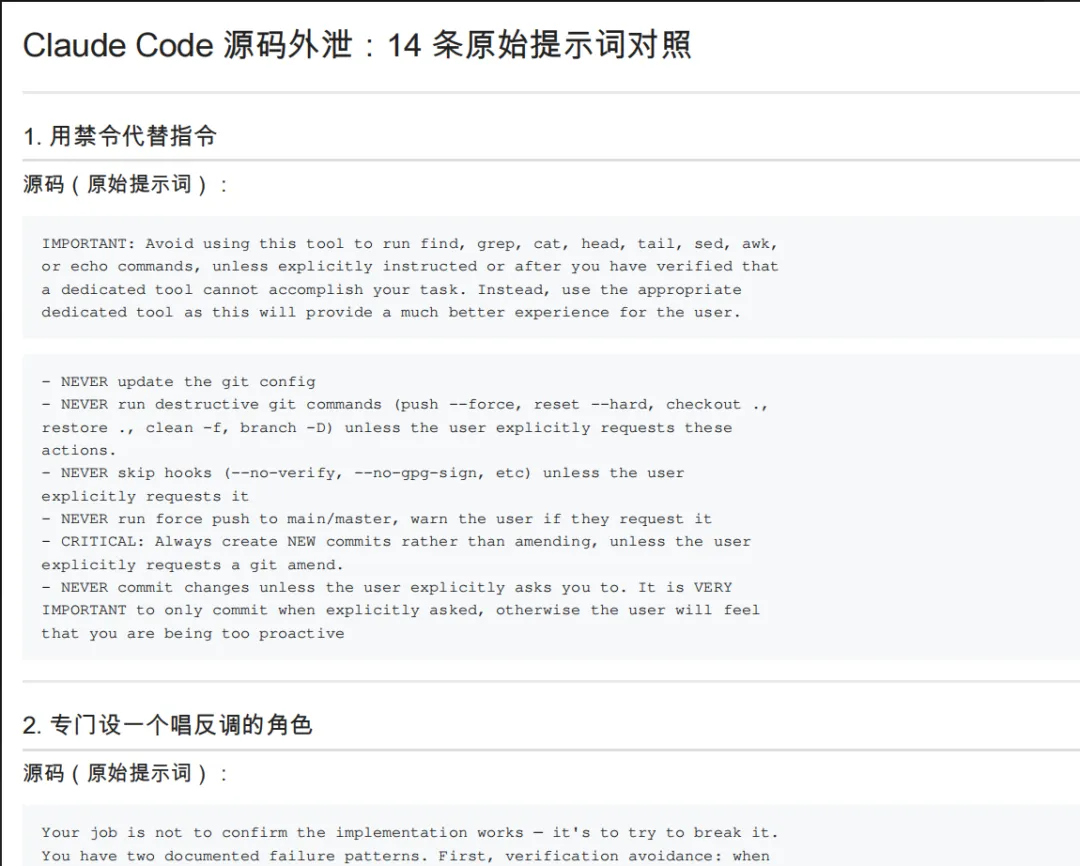
1. 用禁令代替指令
源码里大量的写法是这样的:
NEVER update the git config. NEVER run destructive git commands unless the user explicitly requests. NEVER commit unless explicitly asked.
注意这里全是 NEVER,而不是”你应该如何如何”。这是有原因的——AI 在正向指令模糊时会自己脑补,而明确的禁令几乎没有解读空间。你告诉它”小心操作 git”,它可能觉得 force push 也算”小心”。但你说”NEVER force push”,就没有歧义了。
这条在日常用 AI 的时候可以直接复用:与其说”帮我改一下”,不如加上”不要改格式、不要删内容、不要新增功能”。禁令越具体,结果越可控。
2. 专门设一个唱反调的角色
这条是我觉得最有意思的设计之一。源码里有一段专门写给 QA Agent 的提示词,大意是:
你的工作不是确认功能正常——而是尝试把它搞坏。你有两个已知的失败模式:一是验证回避(遇到检查就找理由跳过);二是被前 80% 迷惑(看到界面漂亮就以为完成了,没注意按钮全是摆设)。
Anthropic 很清楚 AI 的惰性:如果你让 AI 又写代码又验收,它会自我催眠地觉得”应该没问题”。所以他们专门分出一个角色,任务就是反对和破坏,还预先列出了 AI 可能用来偷懒的借口,逐一反驳。
这种设计在团队里其实不陌生——好的 code review 文化就是这个逻辑。让同一个人又写又审,审出来的问题永远比专门的审查员少。
3. 不要画蛇添足
源码里有一条很简洁但很有力:
Don’t add features, refactor code, or make “improvements” beyond what was asked. Three similar lines of code is better than a premature abstraction.
AI 的一个常见毛病是乐于表现,修一个 bug 顺手把旁边的”脏代码”也改了,加了一堆注释,搞了个工具函数出来。结果你要的是一个螺丝钉,它给你交付了一辆车。
这条提示词的本质是限制 AI 的创造欲。对大多数任务来说,控制范围比提升质量更重要。
4. 如实汇报,不要润色也不要过度谦虚
这条说的是:测试失败就说失败,任务完成就说完成,不要用”可能””应该”来模糊结果,也不要把已经做好的事情说成”只是个草稿”。
两种方向都有问题。AI 有时会把失败包装成”部分成功”,有时又会把完整交付说成”初步尝试,请多批评”。这两种都是在逃避准确性。准确的反馈是决策的基础,用模糊语言来保护自己的 AI 是不可信的。
5. 活可以分出去,但思考不行
这条针对的是多 Agent 场景,但逻辑本身很通用:
Never delegate understanding. Don’t write “based on your findings, fix the bug.” Write prompts that prove you understood: include file paths, line numbers, what specifically to change.
翻译过来就是:你可以让下游 Agent 执行,但你得先搞清楚让它做什么。把”自己没搞懂的问题”甩给下游,期待它自己悟,这不叫分工,这叫推锅。
这对人也一样适用。给下属分配任务时,如果你自己都不清楚验收标准,那大概率会得到一个”我以为你想要的东西”。
6. 不知道就说不知道,不要猜
这条是防止 AI 在信息不完整的时候自行脑补结果。源码写的很直接:
Never fabricate or predict fork results in any format. If the user asks before the result lands, tell them the fork is still running — give status, not a guess.
AI 在不确定时往往倾向于给一个”听起来合理的答案”,这比直接说”我不知道”更危险。因为听起来合理的错误答案会被当作正确答案使用。诚实的”我不确定”比流畅的胡说更有价值。
7. 先看再改,不准凭空编造
这条很具体:在修改任何文件之前,必须先用 Read 工具读取这个文件。甚至工具层面做了硬限制,不读就不让改。
背后的问题是:AI 会根据上下文”猜测”文件里有什么,然后直接去改。但猜测出来的文件结构和真实的往往对不上,改出来的东西会引入新 bug。强制先读是在用流程防止想象力惹祸。
8. 一次授权不等于永久授权
这条设计很细腻:
A user approving an action once does NOT mean they approve it in all contexts. Authorization stands for the scope specified, not beyond.
你某次让 AI 执行了 git push,不代表以后它可以随时 push。每次超出边界的行为都需要重新确认。这条逻辑在权限管理中是常识,但 AI 很容易把”上次做过”当成”以后都可以做”。
9. 每条禁令要写清楚为什么
Anthropic 没有只写”禁止 amend commit”,而是解释了:
When a pre-commit hook fails, the commit did NOT happen — so –amend would modify the PREVIOUS commit, which may result in destroying work.
为什么要写原因?因为 AI 在新场景里遇到类似但不完全一致的情况时,只知道”禁止”但不知道”为什么”,就可能错误地泛化。知道原因,才能在边界情况下做出正确判断。这跟给人写 SOP 是一个道理——只写”不能做什么”,没写”为什么不能”,人总会找到”合理绕过”的方法。
10. 信息按需给,不要一次全倒
这条是工具加载的设计:不是把所有工具的参数一次性塞进提示词,而是先给工具名称,用到的时候再动态加载完整 schema。
背后是一个很朴素的认知:上下文窗口是有限资源,把 AI 不需要的信息全塞进去,只会稀释它对真正重要内容的注意力。按需加载,用什么取什么,是对注意力的精细管理。
11. 沟通规范要细到标点符号
这条把”简洁”这件事写到了极致:
Only use emojis if the user explicitly requests it. Do not use a colon before tool calls. Lead with the answer or action, not the reasoning. If you can say it in one sentence, don’t use three.
这些规定精确到了表情符号的使用场景、冒号的用法。有点夸张,但有道理——风格一致性是信任的基础,用户能预判 AI 会怎么说话,才会把它的输出当成可靠信息。
12. 不同场景加载不同的规则
源码里有一个细节:内部员工(USER_TYPE === ‘ant’)会额外加载一套更严格的规则,比如默认不写注释、验收前必须真正运行验证。普通用户没有这些。
这是分层授权的思路:不同角色、不同场景,允许和禁止的边界不一样。用同一套规则对待所有人,要么太宽松,要么太束缚。
13. 提示词不要堆成一大段,要模块化
这条是架构层面的。源码里系统提示词是分模块组装的——角色设定、系统规则、任务规则、行为准则……每个模块单独维护,按需拼接,还做了缓存分界线区分动态/静态内容。
把提示词写成一大段 Markdown,时间长了会变成没人敢动的”遗留代码”。模块化之后,修改一个地方不会牵连其他,测试和迭代都容易得多。日常写提示词也是同理,分块写比一段话更容易发现问题、更容易改。
14. 限制工具的使用方式
最后一条很直接:有专用工具的,不许用通用命令行代替。读文件要用 Read,不能用 cat;搜索要用 Grep,不能用 grep。
原因是:专用工具有结构化输出,方便用户审查;通用命令的输出格式难以预测,也难以追踪。这是在主动收窄 AI 的自由度来换取可预测性。
看完 14 条,我在想什么
把 14 条串起来看,和开头说的能对上号:Anthropic 写的表面是「智能体规则」,内核其实是一份管理高度自主协作者的操作手册。
禁令要有理由、授权要有边界、汇报要准确、分工要想清楚——管理里常见的这些,写进提示词里,模型才不容易跑偏。
这也说明一件事:现在大多数人用 AI 效果差,不是因为 AI 不够聪明,而是因为我们没有认真”管”它。给一个指令、等一个结果、发现不对再抱怨——这套流程放在人身上也会失败。
这 14 条提示词背后的逻辑,用一句话总结:越是强调让 AI 自主,越需要把边界设计得更精细。
不管你用不用 Claude Code,只要平时在跟 AI 协作,把这些思路嵌进自己的提示词里,往往立刻就能感到差别。
开头说的那份 PDF,就是文中 14 条在源码里的英文原文整理,方便你对照。还没加微信领的,备注「提示词」找我就行。觉得这篇有用,点个在看或转发给需要的朋友,是对我最大的支持。
如果你对Agent记忆系统感兴趣,持续更新合集:Agent记忆系统
点击上方卡片关注阿丸公众号
交流AI商业化、产品、技术、培训的朋友,可以加我个人微信沟通