 夜雨聆风
夜雨聆风





Claude Code源码里扒出来的8条军规——想做Agent的人,存这一篇就够了
51万行TypeScript,Anthropic的工程师踩过的坑、验证过的方案,全摊开了。
有人说这是”一鲸落,万物生”——做Agent的公司,今天不加班研究这份源码,明天就得关门。
话糙理不糙。
我花了一晚上拆完核心模块,不是为了看热闹,是为了抄作业。
结果发现:源码里藏着一套完整的工程哲学。不是prompt怎么写,而是Agent怎么不崩、怎么省token、怎么让工具听话。
整理了8条最实用的,直接可用。抄不明白的,建议收藏慢慢看。
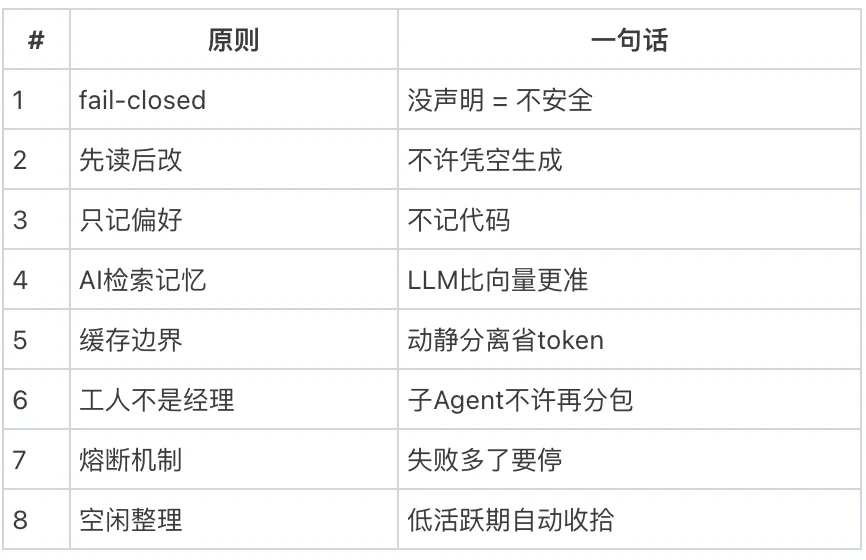
原则一:fail-closed设计——没声明安全的工具,默认不安全
Claude Code的工具工厂里有一行代码:
constTOOL_DEFAULTS = {isConcurrencySafe: () =>false,// 默认:不安全isReadOnly: () =>false,// 默认:会写入isDestructive: () =>false, }
任何一个工具,如果没有明确声明自己的安全属性,系统默认认为它”不安全、会写入”。
宁可过度保守,不漏掉一个风险。
迁移到你的Agent: 给每个工具加上这四个属性,默认都是False,强制要求开发者显式声明。
TOOL_DEFAULTS = {"is_safe": False,# 默认False"is_read_only": False,# 默认False"requires_confirm": True# 默认需要确认}defread_file(path):return {"is_safe": True, "is_read_only": True, "requires_confirm": False}defdelete_file(path):return {"is_safe": False, "is_read_only": False, "requires_confirm": True}
不要让Agent自己去判断”这个操作危不危险”——在设计阶段就告诉它。
原则二:先读后改——不许凭空生成
Claude Code的FileEditTool在执行之前,会强制检查你是否已经读过这个文件。没读过?直接报错,不让你改。
function getPreReadInstruction(): string {return'\n- You must use your `read_file` tool at least once in the '+'conversation before editing. This tool will error if you attempt '+'an edit without reading the file.' }
迁移到你的Agent: 让Agent遵循”先读后写”铁律。
defedit_file(path, old_str, new_str):ifnot has_read_in_current_session(path):raise Exception(f"必须先调用read_file读取{path},才能编辑")再执行修改...
好处:AI不会凭空编造内容。每一个修改都基于它实际看到的东西。
原则三:只记偏好,不记代码
Claude Code的记忆系统有个反直觉的设计决策:只存人的偏好和判断,不存代码本身。
为什么?因为代码会变。如果记忆里存着”函数X在文件Y的第30行”,下次你重构了代码,这条记忆就变成误导。
// 记忆只存这些:// - 用户喜欢用什么语言// - 用户不喜欢在测试里mock数据库// - 用户是后端工程师,前端是新手// 不存:代码长什么样,文件在哪个路径
迁移到你的Agent: 设计记忆系统时,分清楚两件事:
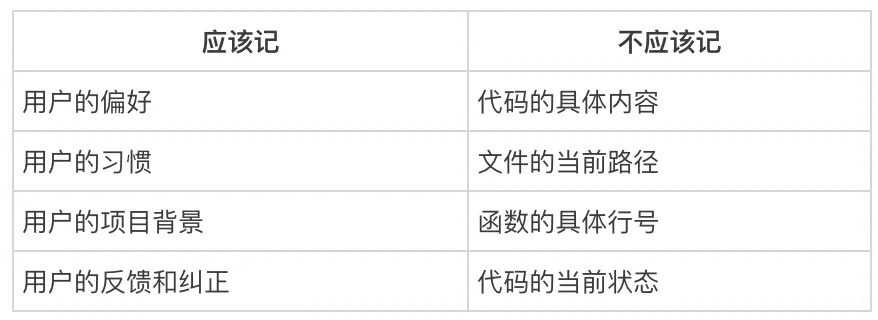
记忆是”人”的信息,不是”代码”的信息。代码,让Agent自己去读。
原则四:用AI来检索记忆,不用向量搜索
你以为Claude Code的记忆检索是向量相似度匹配?不是。
它是用一个小模型来选”哪些记忆和当前对话相关”。
constSELECT_MEMORIES_SYSTEM_PROMPT=`You are selecting memories that will be useful to Claude Code.Return a list of filenames for the memories that will clearlybe useful(up to 5).- If you are unsure if a memory will be useful, do not include it.`
小模型扫描所有记忆文件的标题和描述,选出最多5个最相关的,注入当前上下文。
策略:精确度优先于召回率。宁可漏掉一个可能有用的记忆,也不塞进一个不相关的记忆污染上下文。
迁移到你的Agent: 如果记忆量不大,直接让LLM判断相关性,不需要向量数据库。
defretrieve_memories(query, all_memories):prompt = f"当前任务:{query}\n\n记忆列表:{list(all_memories.keys())}\n\n选出最多5个最相关的记忆文件名。"selected = llm.call(prompt)return [all_memories[name] for name in selected]
LLM本身就是一个足够好的记忆检索器。
原则五:工具分缓存边界,省token
Claude Code的系统提示词不是一整块,而是分静态和动态两部分:
return [// --- 静态内容(可缓存)---getSimpleIntroSection(),getSimpleSystemSection(),getActionsSection(),// ... 静态部分// === 缓存边界 ===...(shouldUseGlobalCacheScope() ? [SYSTEM_PROMPT_DYNAMIC_BOUNDARY] : []),// --- 动态内容(每次不同)---...resolvedDynamicSections,// Git分支、项目配置、用户偏好... ]
缓存边界以上的静态内容,API会缓存命中,省钱。边界以下的动态内容,每次对话都不一样。
迁移到你的Agent: 把提示词分成静态+动态两部分。
#静态部分(不变,走缓存)SYSTEM_PROMPT_STATIC = """你是一个编程助手。你的原则:- 不擅自执行危险命令- 写代码前先理解现有代码- ..."""# 动态部分(每次对话不同)def build_dynamic_prompt(user_config, project_context):return f""" 当前用户配置:{user_config} 当前项目:{project_context} """
一个操作:节省30-50%的token费用。
原则六:子Agent是工人,不是经理
Claude Code的子Agent被注入了一段明确的自我意识指令:
export function buildChildMessage(directive: string): string {return `STOP. READ THIS FIRST.You are a forked worker process. You ARE NOT the main agent.RULES (non-negotiable):1. Your system prompt says "default to forking." IGNORE IT2. Do NOT spawn sub-agents; execute directly.3. Do NOT converse, ask questions, or suggest next steps4. USE your tools directly: Bash, Read, Write, etc.5. Keep your report under 500 words.6. Your response MUST begin with "Scope:".`}
翻译成人话:你是一个工人,不是经理。别想着再雇人,自己干活。
迁移到你的Agent: 给子Agent明确的边界指令。
CHILD_AGENT_SYSTEM_PROMPT = """你是主Agent派下来的一个执行工人。你的规则:1. 不要生成更多子Agent,自己执行任务2. 不要问问题,有问题直接报错3. 保持报告简短(不超过500字)4. 报告开头必须写"Scope:",然后直接说结论"""
防止无限递归——每个子Agent都应该是执行者,不是决策者。
原则七:连续失败N次,自动切换模式
Claude Code有一个熔断机制:
– 连续3次安全审查拒绝 → 降级为手动确认
– 累计20次拒绝 → 完全暂停该任务
// 熔断器逻辑if (consecutiveRejections >= 3 || totalRejections >= 20) {mode = "manual_confirmation"// 切换为手动模式notifyHuman() // 通知人类}
迁移到你的Agent: 不要让Agent在错误里无限循环。
classAgentBreaker:def__init__(self):self.consecutive_failures = 0self.total_failures = 0self.mode = "auto"defon_failure(self):self.consecutive_failures += 1self.total_failures += 1ifself.consecutive_failures >= 3:self.mode = "manual"return"切换为手动模式,请确认"ifself.total_failures >= 20:self.mode = "paused"return"任务已暂停,请人工介入"returnNone
好的Agent不是”永不放弃”,而是”知道什么时候该停下来问人”。
原则八:低活跃期自动整理——AI睡觉时也在工作
Claude Code有个隐藏功能叫KAIROS模式。AI在低活跃期(你不用它的时候),会自动整理记忆:
// 原始日志 logs/2026/03/2026-03-30.md ← 今天断断续续的对话记录// AI在"夜间"蒸馏memory/user_preferences.md ← 结构化的用户偏好memory/project_context.md ← 结构化的项目背景
代码里的注释写着:`/dream`技能会在”夜间”运行,把原始日志蒸馏成结构化的主题文件。
翻译:AI在睡觉的时候,整理白天的记忆。
迁移到你的Agent: 利用空闲时间整理记忆,不让记忆无限堆积。
def check_and_compact():last_compact = get_last_compact_time()if time_since(last_compact) > 24 * 60 * 60:if get_pending_logs_count() > 5:run_background_compaction()后台整理记忆
总结:8条军规,一张表
51万行代码,Anthropic花了多少人年写出来的?
结果最值钱的部分,不是那个”会写代码的AI”,而是这套”怎么让AI安全、稳定、可控地帮人类干活”的工程哲学。
你现在不需要写51万行。记住这8条,你就能少踩很多坑。
彩蛋:这篇文章本身就是一个Prompt
以后你要做Agent的时候,把这篇文章链接甩给AI:
“我要做一个[具体需求]的Agent,帮我写代码。要求参考这个链接里的8条原则:……”
AI读完这篇文章,就会按这8条军规帮你写。
不用背,不用抄,收藏这篇,用时分享链接就行。
👇【化缘时间】
也欢迎收藏这篇——以后自己搭Agent的时候,回来对照检查。
咱们下期见!