 夜雨聆风
夜雨聆风





Claude Code 源码拆解第二篇:为什么你写的 prompt 总是跑偏
不是教你写出完美 prompt 句式,而是教你怎么把任务交接写完整。
前几天,一个朋友给我发了一段他和 agent 的对话。
他问:”帮我看看这个项目怎么优化一下。”
十分钟后,agent 给了他一堆正确但没用的空话:代码风格建议、性能优化原则、架构重构思路。
他皱着眉问我:”为什么我写得这么清楚,它还是给我一堆废话?”
我看了眼他的 prompt,只写了一句话。
我说:”你不是在写任务,你是在许愿。”
如果你最近也有这些感受,这篇大概率对你有用:
-
prompt 写了不少,但结果总是要自己大改。 -
同样的任务,有时能对上,有时又跑偏。 -
总觉得”是不是我 prompt 还不够花”。

一、prompt 的真正作用:不是咒语,而是交接单
很多人把 prompt 当成”对着 AI 许愿”,觉得句式越花哨、效果越好。
但 Claude Code 源码把这件事定义得很朴素:
Brief the agent like a smart colleague who just walked into the room.
这句话的关键词不是 smart,而是 “just walked into the room”。
这意味着:
-
agent 不会读心术,它只看你写下来的东西。 -
你没写的,它只能猜;猜不准,就会给你一堆正确但没用的答案。 -
你的 prompt,本质上是在补齐一个陌生同事接手任务所需的信息。
这不是咒语,而是任务交接单。
为什么源码要写这些约束
很多人会问:为什么 Claude Code 要在 prompt 里写这么多”不要做这个、不要做那个”?
答案藏在源码的细节里。
约束一:fork prompt 是 directive(指令),不是背景交代
在 src/tools/AgentTool/prompt.ts 里有一句很容易忽略的话:
Since the fork inherits your context, the prompt is a directive — what to do, not what the situation is.
意思是:fork 继承了你的上下文,所以不需要重复背景,只需要明确”做什么”。
这解释了为什么 fork 的 prompt 可以写得很短——不是因为短就够,而是因为背景已经在上层对话里了。
约束二:Don’t peek 和 Don’t race
源码里还有两条看起来很严格的约束:
Don’t peek. The tool result includes an
output_filepath — do not Read or tail it unless the user explicitly asks for a progress check.Don’t race. After launching, you know nothing about what the fork found. Never fabricate or predict fork results.
为什么这么严?
-
“Don’t peek”:中途读 fork 的输出文件,会把 fork 的工具噪声拉进你的上下文,这违背了 fork 的初衷。 -
“Don’t race”:fork 结果没回来前,你什么都不知道,不能脑补结果。
这两条约束的本质是:信任通知机制,不要自己偷看或猜测。
约束三:placeholder result 和 prompt cache 共享
在 src/tools/AgentTool/forkSubagent.ts 里,所有 fork child 使用相同的 placeholder result:
Placeholder text used for all tool_result blocks in the fork prefix. Must be identical across all fork children for prompt cache sharing.
这意味着:所有 fork child 的 API 请求前缀是字节级一致的,这让 fork 在 cache 上非常便宜。
你看,源码里的每一条”不要”,背后都是工程成本的考量。
二、为什么简短指令一定会翻车
源码里有一句很重的话:
terse command-style prompts produce shallow, generic work.
翻译成一句话:简短指令,只能换来浅层结果。
这不是模型能力问题,而是任务信息不足导致的必然结果。
来看一个典型差 prompt:
你去看看这个项目怎么优化一下。
问题在哪?
-
范围没说:哪个模块?什么粒度? -
目标没说:优化性能、可维护性、还是架构? -
输出没说:要代码?要方案?要对比? -
边界没说:哪些不要碰?
你只给了一句愿望,agent 只能给你一堆正确但没用的空话。
翻车的四种典型模式
源码里那句 “terse command-style prompts produce shallow work”,背后的根因是信息缺失。我们拆开看四种最常见的翻车模式。
模式一:范围过大
你去看看这个项目怎么优化一下。
翻车原因:
-
没限定模块:是整个项目,还是某个目录? -
没限定粒度:是要代码级改动,还是架构级建议? -
没限定关注点:是性能、可维护性,还是安全性?
结果:agent 给你一堆正确但没用的空话,因为范围太大了。
模式二:输出格式没说
帮我分析一下这个迁移是否安全。
翻车原因:
-
你要的是”安全/不安全”的结论,还是详细的风险清单? -
要的是一句话总结,还是逐条分析?
结果:agent 给了一个很长的分析,但你只想要一个结论。
模式三:边界模糊
看看这里有没有问题。
翻车原因:
-
什么叫”问题”?性能问题?安全问题?代码风格问题? -
你没界定边界,agent 只能按自己的理解来。
结果:agent 检查了一堆你不在乎的东西,漏掉了你真正想看的。
模式四:判断外包
基于你的分析,给出优化建议。
翻车原因:
-
你把”什么是好的优化”这个判断标准,外包给了 agent。 -
它给的优化建议,可能完全不符合你的业务目标。
结果:你收到一堆技术上正确、业务上跑偏的建议。
源码里还有一句更直接的提醒:
Never delegate understanding. Don’t write “based on your findings, fix the bug”.
意思是:不要把理解和判断整包外包给 agent。
如果你连问题是什么都没说清楚,就不要指望它替你做判断。
三、源码真正推荐的 prompt 写法
源码给出了一个很朴素的建议:
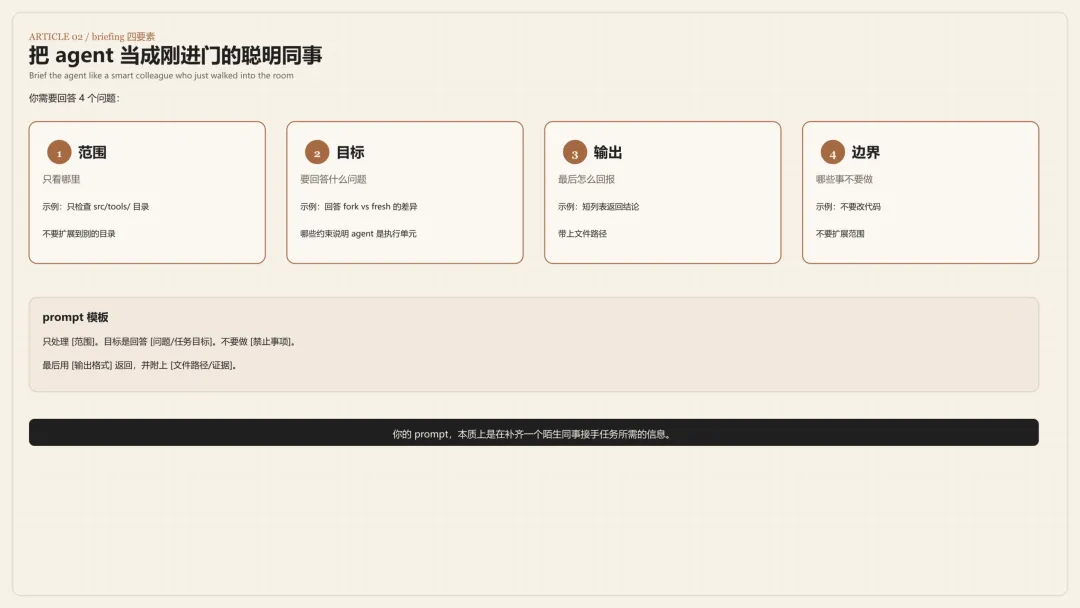
把 agent 当成刚进门的聪明同事,你需要回答 4 个问题:
-
范围:只看哪里。 -
目标:要回答什么问题。 -
输出:最后怎么回报。 -
边界:哪些事不要做。
一个够用的模板是这样的:
只处理 [范围]。
目标是回答 [问题/任务目标]。
不要做 [禁止事项]。
最后用 [输出格式] 返回,并附上 [文件路径/证据]。
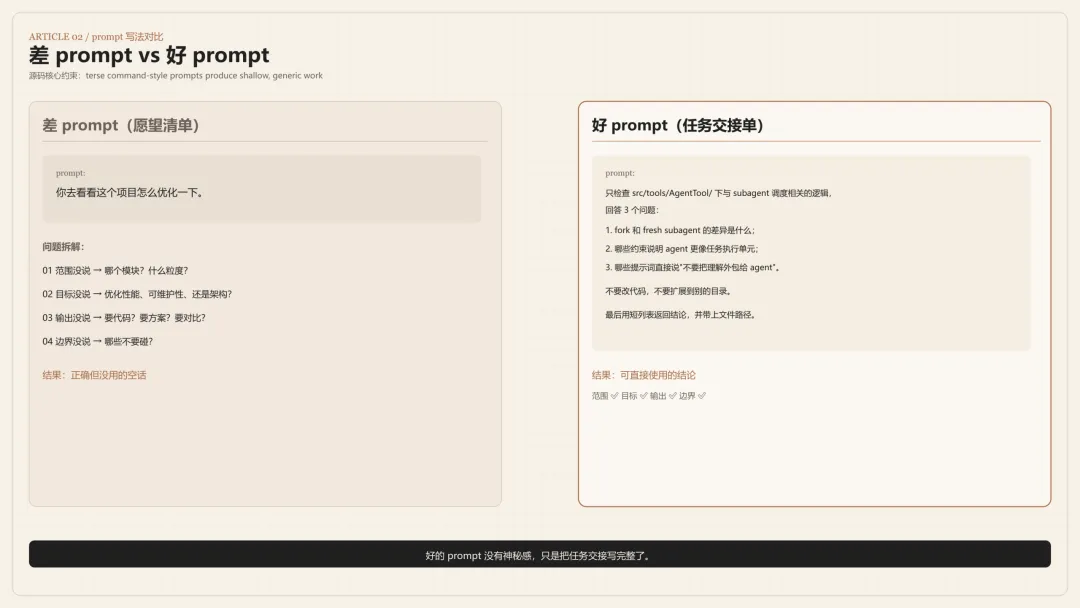
差 prompt vs 好 prompt
差:
你去看看这个项目里 agent 是怎么实现的,顺便看看有什么值得注意的地方。
好:
只检查 src/tools/AgentTool/ 下与 subagent 调度相关的逻辑,回答 3 个问题:
1. fork 和 fresh subagent 的差异是什么;
2. 哪些约束说明 agent 更像任务执行单元;
3. 哪些提示词直接说"不要把理解外包给 agent"。
不要改代码,不要扩展到别的目录。
最后用短列表返回结论,并带上文件路径。
你会发现,好的 prompt 没有任何神秘感,只是把任务交接写完整了。
四、fresh agent 的背景补全:从零开始,必须重新 briefing
Claude Code 有两种 subagent:
fork
:继承你当前的上下文,适合从正在进行的任务里拆出一个分支。 fresh subagent
:从零开始,像刚走进会议室的同事。
如果你给 fresh agent 只写一句半截话,它真的只能给你半吊子结果。
源码里说得很直:
When spawning a fresh agent, it starts with zero context. Brief the agent like a smart colleague who just walked into the room.
给 fresh agent 的差 prompt
你去看看这个迁移是否安全。
给 fresh agent 的好 prompt
Review migration 0042_user_schema.sql for safety.
Context: 我们要给一个 5000 万行的表加 NOT NULL 列,现有行用默认值回填。
我已经检查过锁行为,但想再确认在并发写入下是否安全。
请回答:这个迁移是否安全?如果不安全,具体哪里会出问题?
差别在哪?
-
补齐了背景:为什么要做这个迁移,你已经排查了什么。 -
明确了问题:要回答”是否安全”和”具体哪里会出问题”。 -
收束了范围:只看这个迁移,不要扩展到别的表。
很多人觉得 fresh agent “变笨了”,其实往往是背景给少了,结果自然发虚。
五、不要把理解外包:最容易被忽略的一条
源码里有一句约束,很多人会忽略:
Never delegate understanding. Don’t write “based on your findings, fix the bug”.
这句话的意思是:
-
问题 framing 这件事,先由你来做。 -
判断和决策,不要整包交给 agent。
四种理解外包的错误模式
源码里那句 “Never delegate understanding”,背后是对四种常见错误的约束。
错误模式一:判断外包
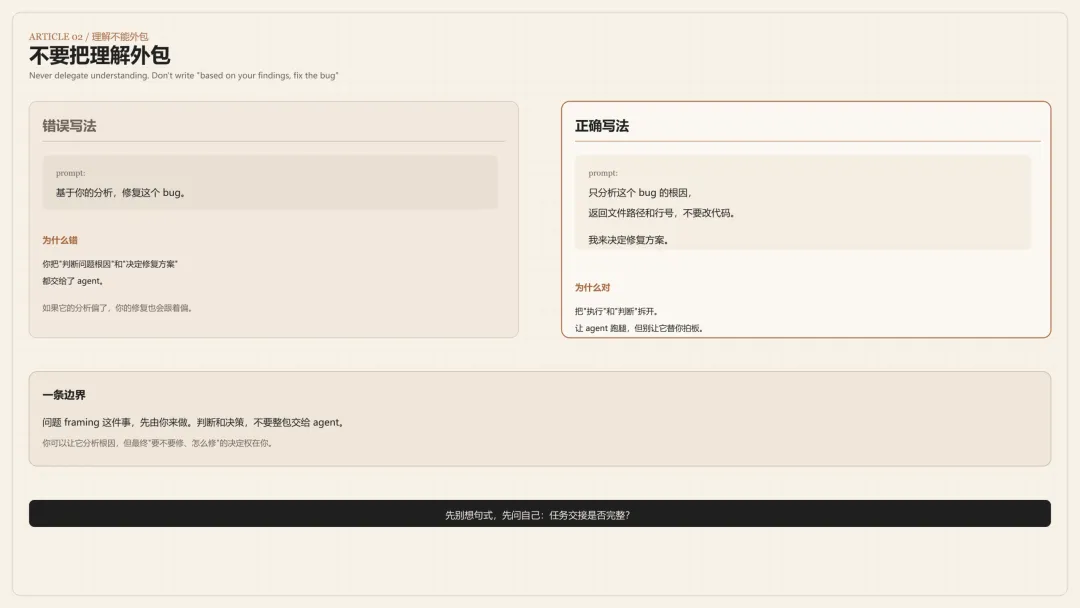
基于你的分析,修复这个 bug。
问题:你把”判断问题根因”和”决定修复方案”都交给了 agent。如果它的分析偏了,你的修复也会跟着偏。
正确写法:
只分析这个 bug 的根因,返回文件路径和行号,不要改代码。
我来决定修复方案。
错误模式二:标准外包
看看有什么值得注意的地方。
问题:什么叫”值得注意”?这是把判断标准外包了。agent 可能给你一堆你不在乎的东西,漏掉你真正想看的。
正确写法:
只检查安全相关的代码路径,返回可能存在风险的文件和行号。
错误模式三:范围外包
顺便帮我优化一下。
问题:什么是”优化”?性能?可读性?架构?你没说清楚,agent 只能按自己的理解来。
正确写法:
只优化这个函数的性能,目标是减少 O(n²) 到 O(n),不要改接口签名。
错误模式四:优先级外包
给我一些建议。
问题:哪些建议是重要的?这个判断你也没给。agent 可能给你一堆低优先级的建议,漏掉真正重要的。
正确写法:
按风险等级排序,列出前 3 个最需要处理的问题。
把”执行”和”判断”拆开,让 agent 跑腿,但别让它替你拍板。

六、一个够用的 prompt 检查清单
每次写完 prompt,先过这 5 个问题:
-
我有没有把范围说清楚? -
我有没有把目标说清楚? -
我有没有把输出格式说清楚? -
我有没有把边界说清楚? -
我是不是正在把理解偷偷外包给 agent?
只要有两个答案是”没有”,先别开 agent。
七、进阶:prompt cache 和 schema 稳定性
如果你关心成本,还有一件事值得知道。
Claude Code 会缓存工具 schema,任何字节级变化都会导致约 11K token 的缓存失效。
源码里有一句注释:
Tool schemas render at server position 2, any byte-level change busts the entire ~11K-token tool block.
这意味着:
-
动态工具描述会让系统变贵。 -
频繁改 prompt 或工具定义,会打爆缓存。
这也是为什么 Claude Code 会把 agent 列表放到消息附件里,而不是嵌入工具描述:
为了保持 prompt cache 稳定。
这个话题我们下一篇继续拆:工具越多不一定越强,上下文越脏 agent 越笨。
八、进阶:长工具输出的上下文污染
还有一类踩坑,很多人不会意识到,但源码里做了防御。
问题:你让 agent “看看整个日志”,这个日志会一直留在上下文里。
在 src/utils/toolResultStorage.ts 里,系统会对超长的工具输出做持久化:
Output too large. Full output saved to: <filepath>
系统会用 preview 替换完整输出,避免上下文爆炸。
为什么长输出会污染上下文:
-
每次工具调用,输出都会进入消息历史。 -
如果你让 agent “看看整个日志”,这个日志会一直跟着你。 -
系统会尽力帮你止血(持久化 + preview),但根本解决方案是:写 prompt 时就限定范围。
给读者的实操建议:
-
不要让 agent “看看整个日志”,而是指定行号范围。 -
不要让 agent “列出所有文件”,而是先用 glob 收窄。 -
如果你发现上下文越来越重,检查一下是否有长工具输出。
这个话题我们会在第三篇继续展开。
最后总结
写 prompt 不是许愿,而是写清楚一份能让陌生同事接手的任务单。
如果你只记住一句话,我建议记这个:
先别想句式,先问自己:任务交接是否完整?
本文提到的源码位置
src/tools/AgentTool/prompt.ts:95-113, 115-154
(briefing、directive、Never delegate understanding) src/tools/AgentTool/forkSubagent.ts:92-93
(placeholder result 和 prompt cache 共享) src/utils/toolSchemaCache.ts:3-8
(schema 稳定性和 11K token 缓存) src/utils/toolResultStorage.ts:130-184
(长工具输出的持久化)
如果你觉得这篇有用,下一篇我继续拆 tool 和 context:为什么工具越多不一定越强,上下文越脏 agent 越笨。Claude Code 源码里藏着很多容易被忽略的工程约束,我们一篇一篇把它拆清楚。