 夜雨聆风
夜雨聆风





Claude Code 源码深度解析(上):1902 个文件背后的架构哲学
本文基于 Claude Code TypeScript 源码结构快照进行逐模块深度分析。我们不浮于表面,而是深入每个关键文件,理解其设计意图和实现细节。
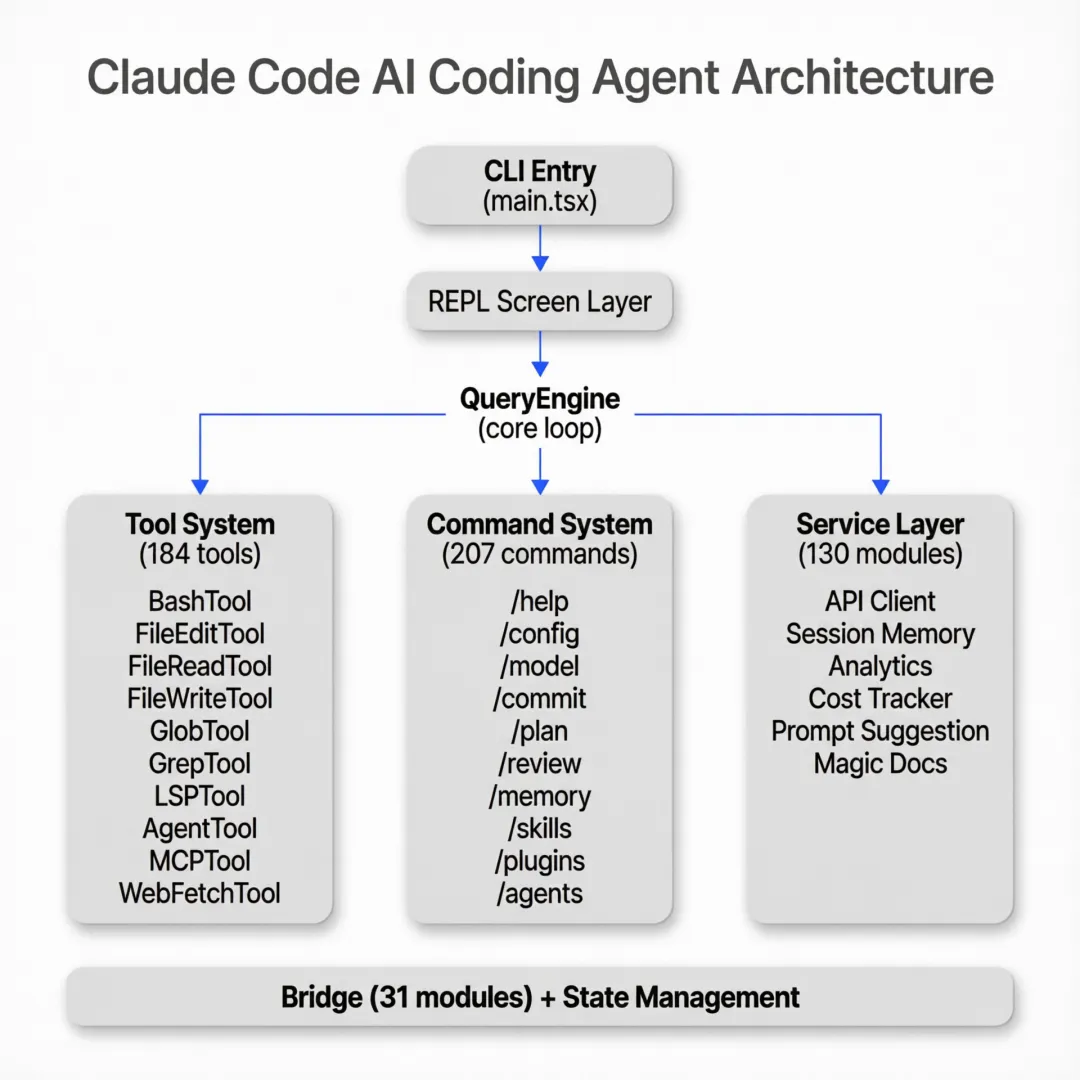
一、项目规模:超出你想象的工程量
先看一组数字:
| 维度 | 数量 |
|---|---|
| TypeScript/TSX 文件 | 1,902 |
| 顶层子系统 | 35 |
| 命令模块 | 207 |
| 工具模块 | 184 |
| UI 组件 | 389 |
| 服务模块 | 130 |
| React Hooks | 104 |
| Bridge 模块 | 31 |
| 内置技能 | 16 |
| CLI 传输协议 | 4 种 |
这不是一个 CLI 工具,而是一个完整的 Agent 操作系统。
二、35 个子系统全览
源码快照记录了完整的顶层目录结构:
src/
├── entrypoints/ (8) 入口层:CLI、SDK、MCP、沙箱
├── components/ (389) 渲染层:389 个 React Ink 终端组件
├── screens/ (3) 页面:REPL、Doctor、ResumeConversation
├── state/ (6) 状态层:AppState 全局状态管理
├── services/ (130) 服务层:API、记忆、分析、提示建议
├── bridge/ (31) 桥接层:IDE/远程连接
├── remote/ (4) 远程层:WebSocket、权限桥接
├── cli/ (19) CLI层:多传输协议
├── hooks/ (104) 钩子系统:权限回调、通知
├── commands/ (207+) 命令系统:斜杠命令
├── tools/ (184+) 工具系统:Agent 能力单元
├── memdir/ (8) 记忆系统:文件级记忆
├── skills/ (20) 技能系统:内置技能+MCP构建器
├── plugins/ (2) 插件系统
├── constants/ (21) 常量定义
├── types/ (11) 类型系统
├── vim/ (5) Vim 模式
├── voice/ (1) 语音模式
├── buddy/ (6) 向导陪伴系统
├── coordinator/ (1) 协调模式
├── bootstrap/ (1) 启动引导
├── moreright/ (1) 右侧面板扩展
├── migrations/ (-) 数据迁移
├── outputStyles/ (1) 输出样式
├── upstreamproxy/ (2) 上游代理
├── native-ts/ (4) 原生模块绑定
├── keybindings/ (-) 键绑定
├── schemas/ (1) Schema 定义
├── assistant/ (1) 助手会话历史
├── server/ (3) 直接连接服务
├── context/ (-) 上下文管理
├── ink/ (-) Ink 渲染辅助
├── query/ (-) 查询引擎辅助
├── tasks/ (-) 任务系统辅助
├── utils/ (-) 工具函数加粗的根级文件(18 个)也是核心模块:
src/
├── QueryEngine.ts # 核心:Agent 执行引擎
├── Task.ts # 任务结构定义
├── Tool.ts # 工具基础类型
├── commands.ts # 命令注册
├── context.ts # 上下文构建
├── cost-tracker.ts # 成本追踪
├── costHook.ts # 成本钩子
├── dialogLaunchers.tsx # 对话启动器
├── history.ts # 会话历史
├── ink.ts # Ink 渲染辅助
├── interactiveHelpers.tsx # 交互辅助
├── main.tsx # 主入口
├── projectOnboardingState.ts # 项目引导状态
├── query.ts # 查询请求/响应
├── replLauncher.tsx # REPL 启动器
├── setup.ts # 环境初始化
├── tasks.ts # 任务列表
└── tools.ts # 工具注册2.2 分层架构全景
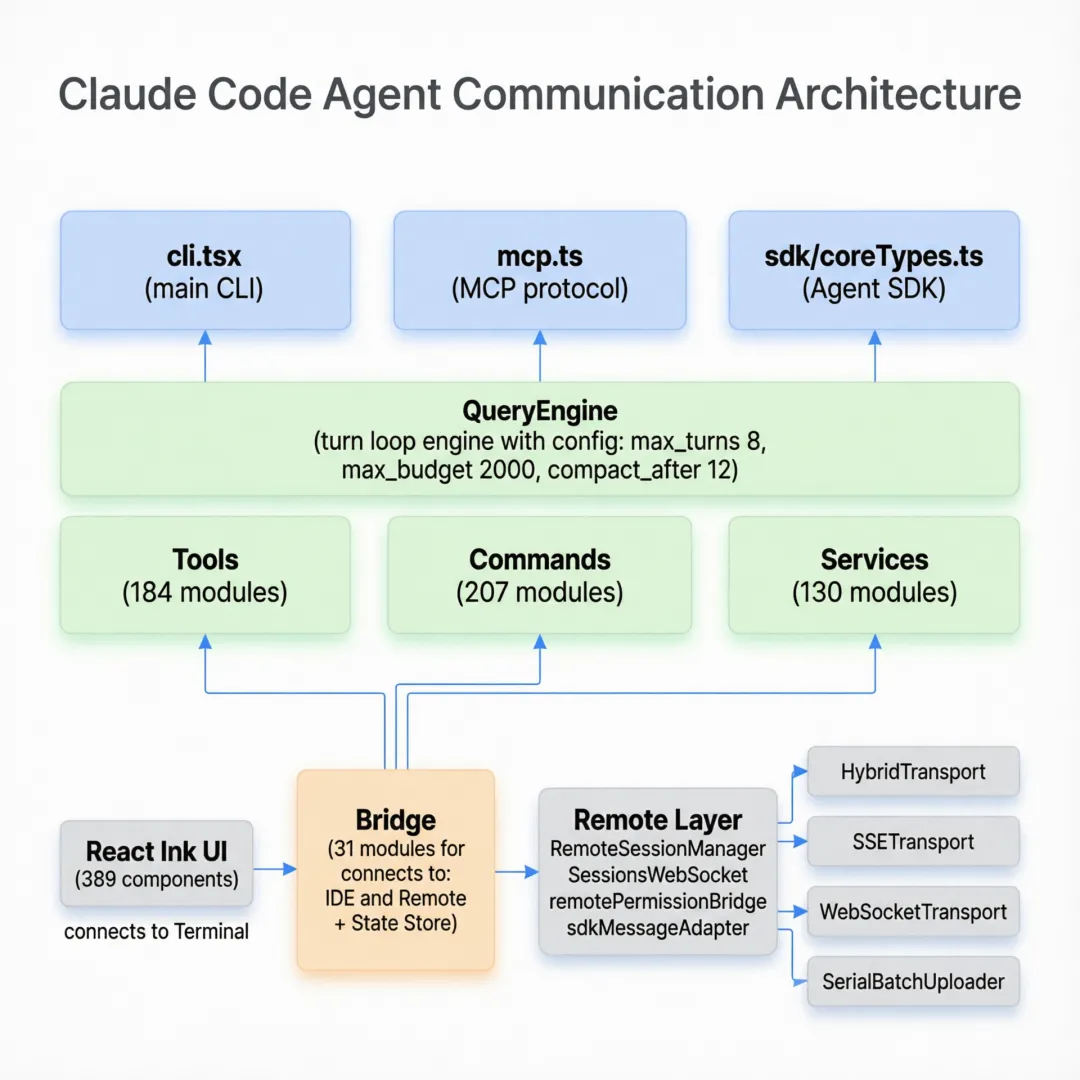
设计背景:为什么分成这么多层?
Claude Code 的分层架构遵循一个核心原则——关注点分离。每一层只做一件事:
- • 入口层决定”怎么启动”(CLI、SDK、MCP 三种入口对应三种使用方式)
- • 渲染层决定”怎么显示”(389 个组件确保终端 UI 的精致体验)
- • 引擎层决定”怎么执行”(QueryEngine 是纯逻辑,不关心显示和存储)
- • 工具层决定”能做什么”(184 个工具是 Agent 的能力边界)
- • 服务层决定”怎么通信”(API、分析、记忆都是基础设施)
这种分层让团队可以并行开发——UI 团队改组件、工具团队加工具、引擎团队优化循环,互不干扰。
三、核心引擎 QueryEngine:Agent 的心脏
3.1 配置体系
QueryEngine 是整个系统的心脏,通过 QueryEngineConfig 控制行为:
# query_engine.py — 核心配置
@dataclass(frozen=True)
class QueryEngineConfig:
max_turns: int = 8 # 最大对话轮次
max_budget_tokens: int = 2000 # Token 预算上限
compact_after_turns: int = 12 # 消息压缩阈值
structured_output: bool = False # 结构化输出(JSON)
structured_retry_limit: int = 2 # 结构化重试次数对应原始 TypeScript 的 QueryEngine.ts,这些参数控制着 Agent 的”生命体征”:
- • 8 轮上限 — 防止 Agent 陷入无限循环
- • 2000 Token 预算 — 防止 Token 消耗失控
- • 12 轮压缩 — 超过 12 轮对话自动裁剪上下文
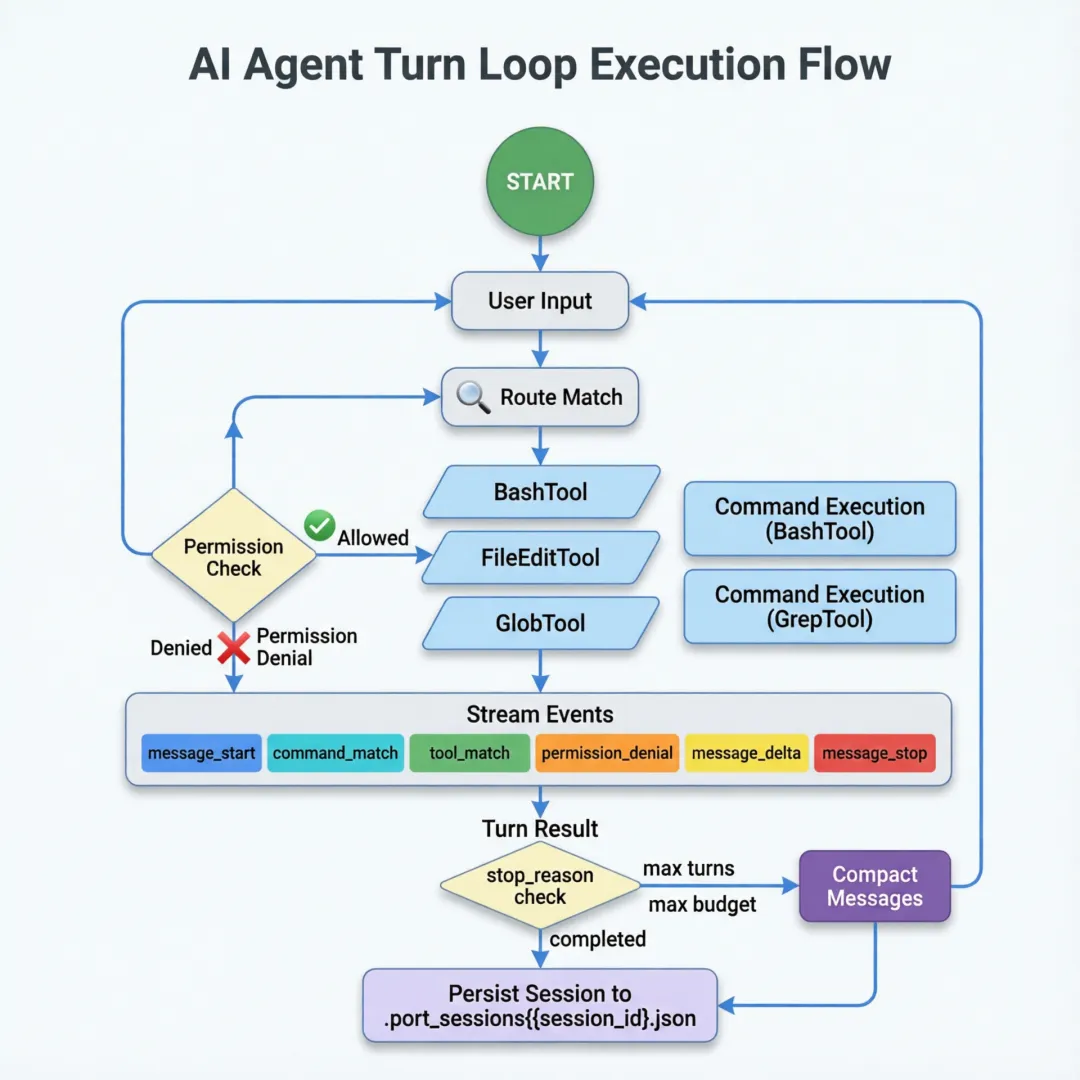
3.2 Turn Loop 完整执行流程
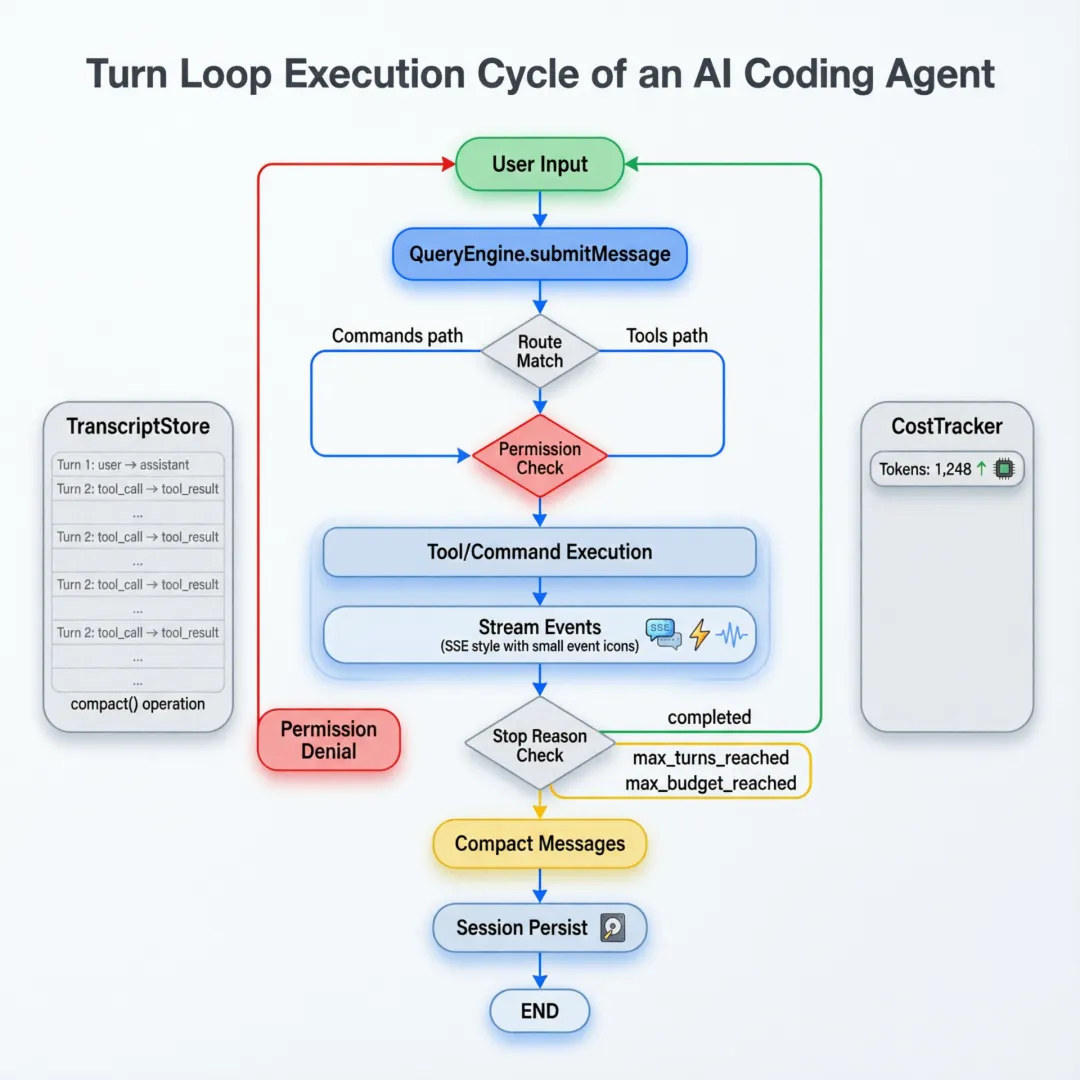
设计背景:为什么采用 Turn Loop 而非单次请求?
传统 LLM 应用采用”一问一答”模式,但 AI Agent 需要连续执行多个步骤(读文件→理解代码→修改→验证),才能完成一个任务。Turn Loop 让 Agent 能在单次用户输入中连续执行多轮工具调用。max_turns 和 max_budget 是防止 Agent 陷入无限循环的安全阀——这是 Agent 系统必须具备的基础保障。
3.3 TurnResult — 每个 Turn 的完整结果
@dataclass(frozen=True)
class TurnResult:
prompt: str # 用户输入
output: str # Agent 输出
matched_commands: tuple[str, ...] # 匹配的命令
matched_tools: tuple[str, ...] # 匹配的工具
permission_denials: tuple[PermissionDenial, ...] # 权限拒绝
usage: UsageSummary # Token 用量
stop_reason: str # 停止原因每个 Turn 的结果包含 7 个维度的信息。stop_reason 有三种值:
- •
completed— 正常完成 - •
max_turns_reached— 达到最大轮次 - •
max_budget_reached— 超出预算
3.3 流式事件系统
def stream_submit_message(self, prompt, matched_commands, matched_tools, denied_tools):
yield {'type': 'message_start', 'session_id': self.session_id, 'prompt': prompt}
if matched_commands:
yield {'type': 'command_match', 'commands': matched_commands}
if matched_tools:
yield {'type': 'tool_match', 'tools': matched_tools}
if denied_tools:
yield {'type': 'permission_denial', 'denials': [...]}
result = self.submit_message(prompt, ...)
yield {'type': 'message_delta', 'text': result.output}
yield {
'type': 'message_stop',
'usage': {'input_tokens': ..., 'output_tokens': ...},
'stop_reason': result.stop_reason,
'transcript_size': len(self.transcript_store.entries),
}这是一个完整的 SSE 风格事件流。注意事件是有序的:message_start → command_match/tool_match → permission_denial → message_delta → message_stop。UI 层可以据此实现实时渲染。
3.4 消息压缩算法
def compact_messages_if_needed(self) -> None:
if len(self.mutable_messages) > self.config.compact_after_turns:
# 只保留最近 N 条消息
self.mutable_messages[:] = self.mutable_messages[-self.config.compact_after_turns:]
# 转录记录同步压缩
self.transcript_store.compact(self.config.compact_after_turns)这是滑动窗口算法——保留最近的 12 轮对话,丢弃更早的。这在 LLM 上下文窗口有限的情况下至关重要。
3.5 会话持久化
# session_store.py
@dataclass(frozen=True)
class StoredSession:
session_id: str # 会话唯一 ID
messages: tuple[str, ...] # 所有消息记录
input_tokens: int # 输入 Token 累计
output_tokens: int # 输出 Token 累计
def save_session(session, directory=None):
target_dir = directory or DEFAULT_SESSION_DIR # .port_sessions/
target_dir.mkdir(parents=True, exist_ok=True)
path = target_dir / f'{session.session_id}.json'
path.write_text(json.dumps(asdict(session), indent=2))
return path会话以 JSON 文件形式存储在 .port_sessions/{session_id}.json,包含完整的消息历史和 Token 统计。支持通过 from_saved_session() 恢复。
3.6 TranscriptStore — 转录管理器
# transcript.py
@dataclass
class TranscriptStore:
entries: list[str] = field(default_factory=list)
flushed: bool = False
def append(self, entry: str):
self.entries.append(entry)
self.flushed = False
def compact(self, keep_last: int = 10):
if len(self.entries) > keep_last:
self.entries[:] = self.entries[-keep_last:]
def replay(self) -> tuple[str, ...]:
return tuple(self.entries)
def flush(self):
self.flushed = TrueTranscriptStore 是一个独立的转录记录器,与 mutable_messages 并行存在。它支持:
- •
append— 追加记录 - •
compact— 滑动窗口压缩 - •
replay— 回放所有记录 - •
flush— 标记已刷入磁盘
flushed 标志是一个简单但重要的设计——用于判断是否有未持久化的数据。
四、启动流程:从 main.tsx 到 Agent 就绪
4.1 Setup 阶段
# setup.py — 环境初始化
@dataclass(frozen=True)
class WorkspaceSetup:
python_version: str # 运行时版本
implementation: str # 实现类型(CPython/PyPy)
platform_name: str # 平台信息
test_command: str # 测试命令
def startup_steps(self) -> tuple[str, ...]:
return (
'start top-level prefetch side effects', # 预取副作用
'build workspace context', # 构建工作上下文
'load mirrored command snapshot', # 加载命令快照
'load mirrored tool snapshot', # 加载工具快照
'prepare parity audit hooks', # 准备审计钩子
'apply trust-gated deferred init', # 信任门控延迟初始化
)启动分为 6 个步骤,按顺序执行。最值得关注的是信任门控延迟初始化。
4.2 Prefetch 预取系统
# prefetch.py — 并行预取
@dataclass(frozen=True)
class PrefetchResult:
name: str
started: bool
detail: str
def start_mdm_raw_read(): # MDM 原始数据预读
def start_keychain_prefetch(): # 密钥链预取
def start_project_scan(root): # 项目扫描三个预取任务在启动时并行执行:
- • mdm_raw_read — 预读 MDM(移动设备管理)原始数据
- • keychain_prefetch — 预取密钥链凭证(避免后续阻塞)
- • project_scan — 扫描项目结构(为上下文构建做准备)
4.3 延迟初始化(Deferred Init)
# deferred_init.py
@dataclass(frozen=True)
class DeferredInitResult:
trusted: bool # 是否在信任模式下
plugin_init: bool # 插件初始化
skill_init: bool # 技能初始化
mcp_prefetch: bool # MCP 预取
session_hooks: bool # 会话钩子
def run_deferred_init(trusted: bool) -> DeferredInitResult:
enabled = bool(trusted) # 只有信任模式下才启用
return DeferredInitResult(
trusted=trusted,
plugin_init=enabled,
skill_init=enabled,
mcp_prefetch=enabled,
session_hooks=enabled,
)关键设计:插件、技能、MCP、会话钩子的初始化都受信任模式控制。在非信任环境下,这些都会被跳过——这是一个安全措施。
4.4 System Init 消息
# system_init.py
def build_system_init_message(trusted=True):
setup = run_setup(trusted)
commands = get_commands()
tools = get_tools()
return f"""
# System Init
Trusted: {setup.trusted}
Built-in commands: {len(built_in_command_names())}
Loaded commands: {len(commands)}
Loaded tools: {len(tools)}
Startup steps: {setup.setup.startup_steps()}
"""System Init 消息是注入给 LLM 的系统提示的一部分——告诉模型当前有多少命令和工具可用。
五、Runtime 系统:Agent 的完整生命周期
5.1 RoutedMatch — 智能路由
# runtime.py
@dataclass(frozen=True)
class RoutedMatch:
kind: str # 'command' 或 'tool'
name: str # 模块名称
source_hint: str # 源文件路径
score: int # 匹配分数路由系统将用户输入匹配到具体的命令和工具。评分算法基于 token 匹配:
@staticmethod
def _score(tokens: set[str], module: PortingModule) -> int:
haystacks = [
module.name.lower(),
module.source_hint.lower(),
module.responsibility.lower()
]
score = 0
for token in tokens:
if any(token in haystack for haystack in haystacks):
score += 1
return score这是一个简单但有效的 TF 匹配——用户输入的每个词如果在模块名称、源路径或职责描述中出现,就加 1 分。
5.2 路由策略
def route_prompt(self, prompt: str, limit: int = 5) -> list[RoutedMatch]:
tokens = {token.lower() for token in prompt.replace('/', ' ').replace('-', ' ').split() if token}
by_kind = {
'command': self._collect_matches(tokens, PORTED_COMMANDS, 'command'),
'tool': self._collect_matches(tokens, PORTED_TOOLS, 'tool'),
}
selected = []
# 每种类型取最高分的一个
for kind in ('command', 'tool'):
if by_kind[kind]:
selected.append(by_kind[kind].pop(0))
# 剩余按分数排序补充
leftovers = sorted(
[match for matches in by_kind.values() for match in matches],
key=lambda item: (-item.score, item.kind, item.name),
)
selected.extend(leftovers[:max(0, limit - len(selected))])
return selected[:limit]路由策略很有讲究:
- 1. 先分命令和工具两组
- 2. 每组取最高分的一个(保证类型多样性)
- 3. 剩余按分数降序补充到 limit
5.3 Turn Loop — 多轮执行
def run_turn_loop(self, prompt, limit=5, max_turns=3, structured_output=False):
engine = QueryEnginePort.from_workspace()
engine.config = QueryEngineConfig(
max_turns=max_turns,
structured_output=structured_output
)
matches = self.route_prompt(prompt, limit)
command_names = tuple(m.name for m in matches if m.kind == 'command')
tool_names = tuple(m.name for m in matches if m.kind == 'tool')
results = []
for turn in range(max_turns):
turn_prompt = prompt if turn == 0 else f'{prompt} [turn {turn + 1}]'
result = engine.submit_message(turn_prompt, command_names, tool_names, ())
results.append(result)
if result.stop_reason != 'completed':
break # 非正常停止就退出循环
return resultsrun_turn_loop 是外部可调用的多轮执行接口。注意第 2 轮开始 prompt 会附加 [turn N] 标记——这帮助 LLM 理解当前是第几轮执行。
5.4 完整的 RuntimeSession
@dataclass
class RuntimeSession:
prompt: str # 原始输入
context: PortContext # 工作上下文
setup: WorkspaceSetup # 环境信息
setup_report: SetupReport # 启动报告
system_init_message: str # 系统初始化消息
history: HistoryLog # 会话历史
routed_matches: list[RoutedMatch] # 路由匹配结果
turn_result: TurnResult # Turn 结果
command_execution_messages: tuple[str, ...] # 命令执行结果
tool_execution_messages: tuple[str, ...] # 工具执行结果
stream_events: tuple[dict, ...] # 流式事件
persisted_session_path: str # 持久化路径一个完整的 RuntimeSession 包含 13 个维度 的信息——从环境配置到执行结果到持久化路径,确保整个执行过程可审计、可恢复。
六、工具系统:184 个工具模块详解
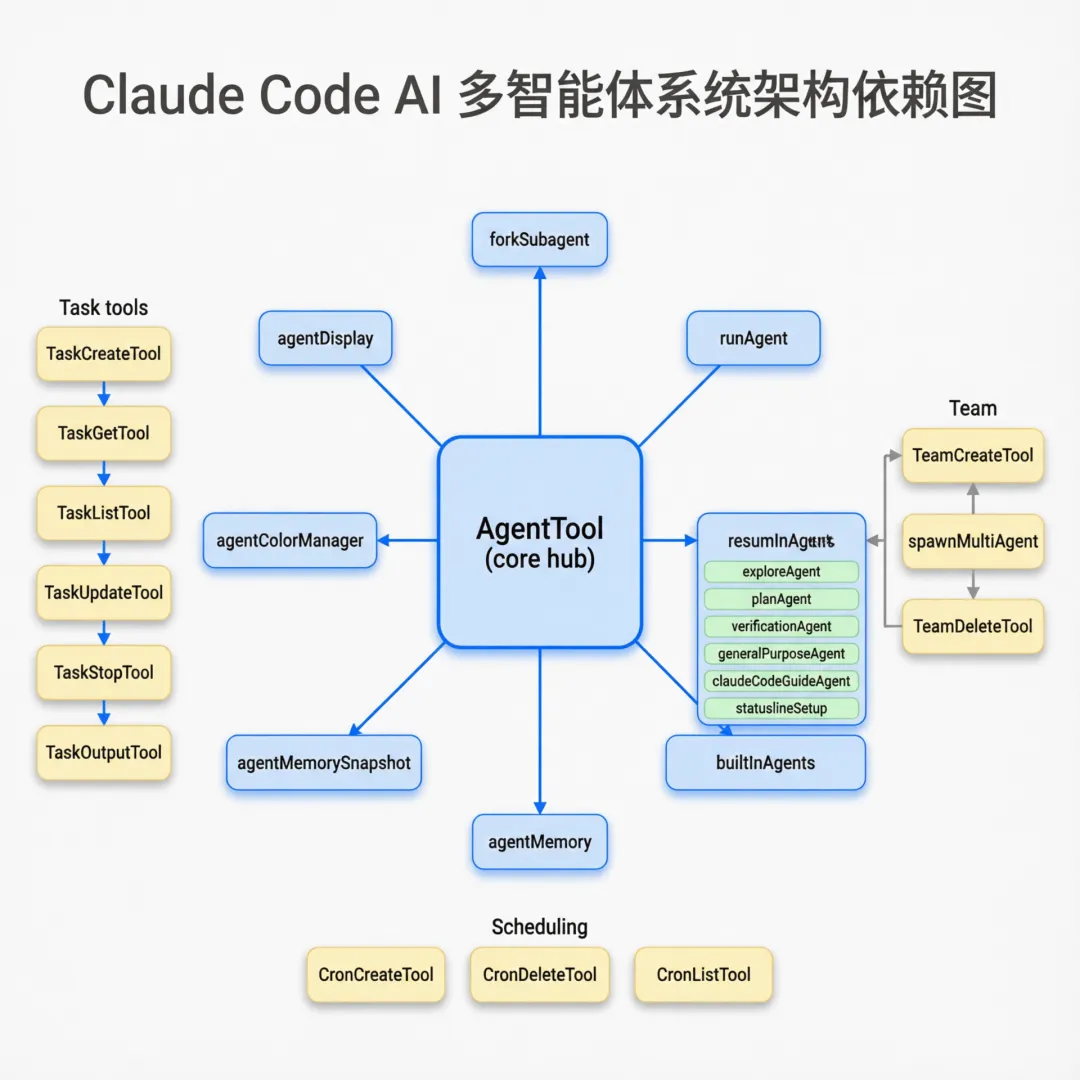
设计背景:为什么是 184 个工具而不是一个大工具?
Claude Code 选择了”小工具、多职责”的微工具架构,而非将所有能力塞进一个”万能工具”。这种设计有三个关键优势:
- 1. LLM 精度更高 — 工具描述越精准,LLM 越容易选对工具。BashTool 和 FileEditTool 的 Prompt 差异巨大,模型能精确选择
- 2. 权限控制更细 — 可以单独授权/拒绝每个工具,而非一刀切
- 3. 可测试性强 — 每个工具独立测试,互不影响
这是 Anthropic 在 Agent 工程实践中的重要设计决策——工具粒度决定了 Agent 的能力上限。
6.1 工具注册与发现
# tools.py — 工具注册
@lru_cache(maxsize=1)
def load_tool_snapshot() -> tuple[PortingModule, ...]:
raw_entries = json.loads(SNAPSHOT_PATH.read_text())
return tuple(
PortingModule(
name=entry['name'],
responsibility=entry['responsibility'],
source_hint=entry['source_hint'],
status='mirrored',
)
for entry in raw_entries
)
PORTED_TOOLS = load_tool_snapshot()工具从 JSON 快照加载,使用 lru_cache 缓存——确保只加载一次。每个工具模块记录了:
- • name — 工具名称
- • source_hint — 原始 TS 文件路径
- • responsibility — 职责描述
- • status — 状态(mirrored = 已映射)
6.2 工具池动态组装
# tool_pool.py
@dataclass(frozen=True)
class ToolPool:
tools: tuple[PortingModule, ...]
simple_mode: bool # 简单模式(只有3个基础工具)
include_mcp: bool # 是否包含 MCP 工具
def assemble_tool_pool(simple_mode=False, include_mcp=True, permission_context=None):
return ToolPool(
tools=get_tools(simple_mode, include_mcp, permission_context),
simple_mode=simple_mode,
include_mcp=include_mcp,
)工具池在运行时动态组装——根据模式(simple/full)、是否包含 MCP、权限上下文三个维度过滤。
6.3 工具过滤策略
def get_tools(simple_mode=False, include_mcp=True, permission_context=None):
tools = list(PORTED_TOOLS)
# 简单模式:只保留 3 个基础工具
if simple_mode:
tools = [t for t in tools if t.name in {
'BashTool', 'FileReadTool', 'FileEditTool'
}]
# 排除 MCP 工具
if not include_mcp:
tools = [t for t in tools
if 'mcp' not in t.name.lower()
and 'mcp' not in t.source_hint.lower()]
# 权限过滤
return filter_tools_by_permission_context(tuple(tools), permission_context)三层过滤的设计精妙之处:
- 1. 简单模式 — 新手安全区,只有读写和执行三个工具
- 2. MCP 过滤 — 在不信任外部工具时关闭
- 3. 权限上下文 — 最精细的控制,可以按名称或前缀拒绝特定工具
6.4 ExecutionRegistry — 执行注册表
# execution_registry.py
@dataclass(frozen=True)
class MirroredCommand:
name: str
source_hint: str
def execute(self, prompt: str) -> str:
return execute_command(self.name, prompt).message
@dataclass(frozen=True)
class MirroredTool:
name: str
source_hint: str
def execute(self, payload: str) -> str:
return execute_tool(self.name, payload).message
@dataclass(frozen=True)
class ExecutionRegistry:
commands: tuple[MirroredCommand, ...]
tools: tuple[MirroredTool, ...]
def command(self, name: str) -> MirroredCommand | None:
lowered = name.lower()
for cmd in self.commands:
if cmd.name.lower() == lowered:
return cmd
return None
def tool(self, name: str) -> MirroredTool | None:
lowered = name.lower()
for t in self.tools:
if t.name.lower() == lowered:
return t
return NoneExecutionRegistry 是命令和工具的统一执行注册表——名字查找是大小写不敏感的,这是一个小但重要的用户体验优化。
6.5 工具目录结构全景
源码快照揭示了每个工具的完整文件组织。以最复杂的 BashTool 为例:
tools/BashTool/
├── BashTool.tsx # 主执行逻辑
├── BashToolResultMessage.tsx # 结果消息 UI 渲染
├── UI.tsx # 工具 UI 组件
├── bashCommandHelpers.ts # 命令辅助函数
├── bashPermissions.ts # 权限检查
├── bashSecurity.ts # 安全审计(最关键)
├── commandSemantics.ts # 命令语义解析
├── commentLabel.ts # 命令注释标签
├── destructiveCommandWarning.ts # 危险命令预警
├── modeValidation.ts # 执行模式校验
├── pathValidation.ts # 路径安全校验
├── prompt.ts # 工具的 System Prompt
├── readOnlyValidation.ts # 只读模式校验
├── sedEditParser.ts # sed 编辑解析器
├── sedValidation.ts # sed 命令校验
├── shouldUseSandbox.ts # 沙箱自动判定
├── toolName.ts # 工具名称常量
└── utils.ts # 工具函数18 个文件实现一个 Bash 工具!其中安全相关的就有 5 个(bashSecurity、destructiveCommandWarning、pathValidation、readOnlyValidation、shouldUseSandbox)。
6.6 其他工具的文件组织
AgentTool(14 个文件)— 多 Agent 核心:
tools/AgentTool/
├── AgentTool.tsx # 入口
├── UI.tsx # 显示
├── agentColorManager.ts # Agent 颜色标识
├── agentDisplay.ts # 状态显示
├── agentMemory.ts # Agent 记忆
├── agentMemorySnapshot.ts # 记忆快照
├── agentToolUtils.ts # 工具辅助
├── builtInAgents.ts # 内置 Agent 注册
├── constants.ts # 常量
├── forkSubagent.ts # 子 Agent 派生
├── loadAgentsDir.ts # 自定义 Agent 目录加载
├── prompt.ts # 系统 Prompt
├── resumeAgent.ts # 恢复暂停的 Agent
└── runAgent.ts # Agent 执行
└── built-in/ # 内置 Agent 实现
├── claudeCodeGuideAgent.ts # 使用指南 Agent
├── exploreAgent.ts # 探索 Agent
├── generalPurposeAgent.ts # 通用 Agent
├── planAgent.ts # 规划 Agent
├── statuslineSetup.ts # 状态栏设置
└── verificationAgent.ts # 验证 AgentLSPTool(5 个文件)— 代码语义:
tools/LSPTool/
├── LSPTool.ts # LSP 工具入口
├── UI.tsx # UI
├── formatters.ts # 输出格式化
├── prompt.ts # Prompt
├── schemas.ts # 请求 Schema
└── symbolContext.ts # 符号上下文提取FileEditTool(6 个文件)— 精确编辑:
tools/FileEditTool/
├── FileEditTool.ts # 编辑逻辑
├── UI.tsx # 编辑 UI
├── constants.ts # 常量
├── prompt.ts # Prompt
├── types.ts # 编辑操作类型
└── utils.ts # 编辑算法6.7 共享工具
tools/shared/
├── gitOperationTracking.ts # Git 操作追踪
└── spawnMultiAgent.ts # 多 Agent 并发派生spawnMultiAgent 是多 Agent 并发的核心——不在任何单个工具内部,而是放在 shared/ 目录下,供所有工具共享。
6.8 任务工具链(6 个工具)
tools/TaskCreateTool/ → 创建任务(目标 + Agent 分配)
tools/TaskGetTool/ → 获取任务详情
tools/TaskListTool/ → 列出所有任务
tools/TaskUpdateTool/ → 更新任务状态
tools/TaskStopTool/ → 停止任务
tools/TaskOutputTool/ → 获取任务输出6.9 团队与调度
tools/TeamCreateTool/ → 创建 Agent 团队
tools/TeamDeleteTool/ → 解散 Agent 团队
tools/TodoWriteTool/ → TODO 写入
tools/ToolSearchTool/ → 动态工具发现tools/ScheduleCronTool/
├── CronCreateTool.ts → 创建定时任务
├── CronDeleteTool.ts → 删除定时任务
└── CronListTool.ts → 列出定时任务七、权限系统:三道防线
设计背景:为什么需要三层权限过滤?
AI Agent 的核心矛盾是能力 vs 安全。Agent 越强大(拥有 shell 执行、文件写入、网络访问能力),误操作的风险越高。三层过滤的设计思路是:
- • 第一层(工具池裁剪) — 在 Agent 启动前决定它能看到哪些工具。简单模式只有 3 个工具,把出错概率降到最低
- • 第二层(运行时权限上下文) — 根据用户信任级别动态调整。高级用户可以开放更多工具
- • 第三层(场景化处理器) — 即使同一个人,在不同场景下(交互模式 vs 协调模式 vs 群集模式)的权限策略也不同
这种”洋葱模型”是安全工程的经典范式——每一层都独立可配置,任何一层被突破还有下一层保护。
7.1 ToolPermissionContext
# permissions.py
@dataclass(frozen=True)
class ToolPermissionContext:
deny_names: frozenset[str] = field(default_factory=frozenset)
deny_prefixes: tuple[str, ...] = ()
def blocks(self, tool_name: str) -> bool:
lowered = tool_name.lower()
return (lowered in self.deny_names
or any(lowered.startswith(prefix) for prefix in self.deny_prefixes))权限上下文支持两种拒绝方式:
- • 按名称 — 精确拒绝(如
deny_names={'BashTool'}) - • 按前缀 — 模式拒绝(如
deny_prefixes=('mcp',)}拒绝所有 MCP 工具)
7.2 权限推断
# runtime.py
def _infer_permission_denials(self, matches):
denials = []
for match in matches:
if match.kind == 'tool' and 'bash' in match.name.lower():
denials.append(PermissionDenial(
tool_name=match.name,
reason='destructive shell execution remains gated'
))
return denials系统会自动推断权限拒绝——例如 Bash 工具默认会被标记为需要额外权限。
7.3 三种权限处理器(hooks层)
源码快照记录了 hooks/toolPermission/handlers/ 中的三种处理器:
hooks/toolPermission/handlers/
├── coordinatorHandler.ts # 协调模式:多 Agent 编排时
├── interactiveHandler.ts # 交互模式:用户直接对话时
└── swarmWorkerHandler.ts # 群集模式:大规模并行任务时不同场景下的权限策略不同:
- • 交互模式 — 弹出确认对话框,等待用户批准
- • 协调模式 — 主 Agent 可以代表用户做部分决策
- • 群集模式 — 更严格的限制,因为大量 Agent 并发执行
八、成本追踪系统
# cost_tracker.py
@dataclass
class CostTracker:
total_units: int = 0
events: list[str] = field(default_factory=list)
def record(self, label: str, units: int):
self.total_units += units
self.events.append(f'{label}:{units}')
# costHook.py — 钩子方式记录
def apply_cost_hook(tracker, label, units):
tracker.record(label, units)
return tracker成本追踪通过 Hook 模式集成——在任何需要记录成本的地方调用 apply_cost_hook。events 列表保留了完整的成本事件历史。
九、上下文构建
# context.py
@dataclass(frozen=True)
class PortContext:
source_root: Path # 源码根目录
tests_root: Path # 测试根目录
assets_root: Path # 资源根目录
archive_root: Path # 归档根目录
python_file_count: int # Python 文件数
test_file_count: int # 测试文件数
asset_file_count: int # 资源文件数
archive_available: bool # 归档是否可用上下文构建时会扫描整个工作空间,统计文件数量,判断归档是否可用。这些信息会注入到 Agent 的系统提示中。
十、远程运行时模式
# remote_runtime.py
@dataclass(frozen=True)
class RuntimeModeReport:
mode: str # 'remote' | 'ssh' | 'teleport'
connected: bool # 是否已连接
detail: str # 详情
def run_remote_mode(target): ... # 远程模式
def run_ssh_mode(target): ... # SSH 模式
def run_teleport_mode(target): ... # Teleport 模式三种远程模式:
- • remote — 通过 WebSocket 远程控制
- • ssh — 通过 SSH 代理
- • teleport — Teleport 协议(恢复/创建)
十一、直接连接与深度链接
# direct_modes.py
@dataclass(frozen=True)
class DirectModeReport:
mode: str # 'direct-connect' | 'deep-link'
target: str # 目标
active: bool # 是否激活
def run_direct_connect(target): ...
def run_deep_link(target): ...两种特殊连接模式:
- • direct-connect — 直连模式(不经过 Bridge)
- • deep-link — 深度链接(从外部应用跳转)
十二、Parity Audit — 持续一致性审计
# parity_audit.py — 关键映射表
ARCHIVE_ROOT_FILES = {
'QueryEngine.ts': 'QueryEngine.py',
'Task.ts': 'task.py',
'Tool.ts': 'Tool.py',
'commands.ts': 'commands.py',
# ... 18 个根文件映射
}
ARCHIVE_DIR_MAPPINGS = {
'assistant': 'assistant',
'bridge': 'bridge',
# ... 35 个目录映射
}Parity Audit 持续检查 Python 移植版本与原始 TS 快照的一致性,确保没有遗漏关键模块。
十三、HistoryLog — 会话历史
# history.py
@dataclass(frozen=True)
class HistoryEvent:
title: str
detail: str
@dataclass
class HistoryLog:
events: list[HistoryEvent] = field(default_factory=list)
def add(self, title, detail):
self.events.append(HistoryEvent(title=title, detail=detail))
def as_markdown(self):
lines = ['# Session History', '']
lines.extend(f'- {e.title}: {e.detail}' for e in self.events)
return '\n'.join(lines)每个重要操作都通过 history.add() 记录,形成可读的 Markdown 格式历史。
下篇预告:《Claude Code 源码深度解析(下):多 Agent 编排、记忆三层架构与创新设计》将深入分析 AgentTool 的 6 种内置 Agent、三层记忆系统、Plan Mode、Thinkback 回溯、Coordinator 协调模式、技能系统、Buddy 向导等创新设计。