 夜雨聆风
夜雨聆风





IMRD 语义情感分析模型微调项目文档:从 0 到 1 跑通第一版模型
IMRD这个项目是我离职前给某学校做的一个小模型微调的项目,需求不复杂,对文本进行情感分析。最早因为算法同事离职,刚接的时候也是一脸懵逼,不过看了一下huggingface官方transformers库的文档,也就硬着头皮上。现在想想也算是一个很好的精力,分享一下。

1. 这篇文章适合谁
在Claude Code爆火之前,有一度我认为小模型才是未来。还是有点受英伟达那篇论文的影响。
论文地址: https://arxiv.org/pdf/2506.02153
如果你是下面这三类同学,这篇文章就是给你写的:
-
刚接触大模型微调,不知道从哪里开始
-
会一点 Python,但没完整做过训练到推理闭环
-
想把“能跑”变成“能解释、能优化”
本文基于一个二分类任务示例来讲思路,重点是学习路径和工程习惯。
2. 先搞懂:什么是“微调”
一句话理解:
微调就是在已有大模型能力上,用你的任务数据做“定向训练”,让模型更擅长某个具体任务。
在这个项目中,任务是文本二分类,标签可以理解为:
-
类别 0:夸大陈述
-
类别 1:未夸大陈述
你不需要从零训练一个模型,只需要在现有模型基础上做小规模适配。
这里新手可以了解一下,根基的指令微调也是要构建prompt的,尤其在一些商用的能力问答场景,RAG是一种本地知识库的方式,其实微调也是一个选择。以及工具调用成功率,多轮对话调用工具,其实失败的概率很大的。如果不进行prompt优化或者任何其他的办法介入,微调也可以选择,但是针对工具调用的微调,给我的感觉挺微乎其微的。
3. 为什么新手推荐 LoRA
LoRA 是参数高效微调方法,适合新手的原因有三点:
-
显存压力更小:不必更新全部参数(只调整一部分参数)
-
训练速度更友好:试错成本低
-
工程上更稳:训练权重与基础模型可以分离管理
对于刚上手的同学,先把 LoRA 跑通,再考虑更复杂方案,学习曲线会顺很多。
4. 项目学习地图(建议按顺序)
你可以把整个学习过程拆成 4 个阶段:
-
数据理解:看清任务输入、标签定义、样本质量
-
构建两个数据集,一部分用于微调,一部分用于评估。如果合并为一个。huggingface的 dataset库也可以在代码里拆出一部分进行 -
训练跑通:完成一次可复现训练
-
评估复盘:看懂指标,不只看单个准确率
-
这里边重要的指标就是Loss (损失函数值)。Loss 衡量模型预测与真实标签之间的差异,在训练过程中,它应该随着多轮的微调(epochs)逐步趋近于0。Loss 是一个训练优化指标,反映模型学习的程度,而不是最终性能评估指标。 -
推理落地:单条预测和批量预测都能跑
只要这 4 步通了,你已经超过很多只会“抄命令”的入门者。
5. 新手最容易忽略的 3 个基础点
5.1 标签必须是“真实标签”
文本分类任务里,labels 必须来自样本标签列,而不是 input_ids 的复制。
如果 labels 错了,模型会学偏,训练看起来在跑,结果其实没有学习到正确任务。
5.2 训练集和验证集要分开
同一份数据既训练又验证,会导致指标虚高。你以为模型很强,实际上泛化能力很弱。
5.3 指标要看组合,不看单点
新手常见误区是只看 Accuracy。更稳妥的做法是一起看以下评估指标:
-
Accuracy (准确率):模型正确预测的样本数占总样本数的比例。这是最直观的指标,但当类别不平衡时可能具有误导性。 -
Precision (精确率):在所有模型预测为正例的样本中,实际为正例的比例。它衡量模型识别正例的准确性。 -
Recall (召回率):在所有实际为正例的样本中,模型正确预测为正例的比例。它衡量模型找出所有正例的能力。 -
F1 Score (F1 值,尤其是 weighted F1):精确率和召回率的调和平均值。它综合了精确率和召回率,当精确率和召回率都很重要时,F1 值是一个很好的综合指标。 weighted F1更适用于类别不平衡的数据集,因为它会根据每个类别的样本数量进行加权平均。
注意: 以上指标主要用于训练完成后对模型性能的评估。而 Loss (损失函数值) 是一个训练过程中的优化指标,用于指导模型学习,不直接作为最终的模型性能评估指标。
6. 一次标准的训练流程(思维版)
下面是你应该记住的训练闭环:
-
定义标签映射(id2label 和 label2id)
-
加载 tokenizer 和分类模型
-
读取数据并 tokenize
-
正确设置 labels
-
配置 LoRA 与训练参数
-
启动训练并保存最佳模型
-
在验证集做指标评估
-
用单条和批量样本做推理验收
建议把这 8 步写成你自己的检查清单,每次项目都能复用。
7. 参数怎么调:给新手一个实用起点
第一版别追求极致,先用“稳妥参数”跑通:
-
学习率:先从 5e-5 附近开始
-
epoch:先跑 3-5 轮
-
batch size:先按显存能稳定运行的最小值起步
-
max length:先用中等长度,避免显存爆炸
调参顺序建议:
-
先保训练稳定(不报错)
-
再看过拟合(训练升、验证不升)
-
最后细调学习率和长度
8. 如何判断“这次微调是成功的”
新手常问:跑完了,怎么算成功?
可以用这 4 条判断:
-
指标比基线有稳定提升
-
多次训练结果波动不大
-
典型样本预测方向正确
-
线上或模拟业务样本上没有明显崩坏
只要满足其中 3 条,通常就可以进入下一轮优化。
9. 常见报错速查(新手版)
9.1 显存不足
处理顺序:
-
降低 batch size
-
缩短 max length
-
再考虑换更小模型
9.2 列名报错
本质是数据字段和代码预期不一致,先统一列名再训练。
9.3 dtype 不兼容
问题描述:不同硬件(尤其是 GPU)对 bfloat16 的支持不同。在不支持的硬件上加载 bfloat16 权重的模型时,会引发数据类型不兼容的错误。
解决方案:在 from_pretrained 方法中设置 torch_dtype="auto",这是最推荐的做法。框架会自动检测硬件能力并选择最佳的数据类型(例如,在安培架构的 GPU 上使用 bfloat16,在旧款 GPU 上则使用 float16)。
# 推荐做法model = AutoModel.from_pretrained("model_name", torch_dtype="auto", device_map="auto")备选方案:如果 torch_dtype="auto" 在您的特定环境(例如在 CPU 上或某些 MPS 设备)中引发问题,您可以显式指定 torch.float16 或 torch.float32。
# 备选:显式指定model = AutoModel.from_pretrained("model_name", torch_dtype=torch.float16 )9.4 指标异常高或异常低
优先排查:
-
labels 是否正确
-
训练/验证是否混用
-
标签分布是否严重不平衡
10. 入门后的进阶路线
当你跑通第一版后,建议按这个顺序升级:
-
做更规范的数据划分和数据清洗
-
加入混淆矩阵,分析哪一类最容易错
-
做不平衡处理(重采样或损失加权)
-
固定随机种子和实验记录,提升可复现性
-
尝试更大模型或更优推理策略
11. 给新手的最后建议
第一阶段目标不是“追最强指标”,而是“建立完整认知”:
-
我知道模型在学什么
-
我知道指标代表什么
-
我知道问题出在哪一环
当你能独立完成“数据 -> 训练 -> 评估 -> 推理 -> 复盘”全链路时,就已经真正入门了。
继续做下去,你会发现微调并不神秘,它本质是工程化的迭代能力。
整个项目概述
虽然上一家单位现在没员工了,完整代码还是不太敢放出来,以后把。下边截取了一些代码做说明,如果有朋友想试试,可以去网上搜索文本语义微调的案例,作为入门是个不错的选择。我没有选择一些微调工具,如果还是想看看代码,如果需要也可以选择。都是基于SFT的一些微调。
1. 项目概述
本项目实现了一个基于Qwen2.5-0.5B-Instruct的微调小模型,专用于语义情感分析任务,特别是区分文本中的夸大陈述与未夸大陈述两类情感倾向。采用LoRA(低秩适应)高效微调技术,在保证模型效果的同时大幅降低计算资源消耗。
2. 技术栈与环境
2.1 核心依赖
-
PyTorch 2.0+ (支持BFloat16计算) -
Transformers 4.37+ (Hugging Face库) -
PEFT 0.7.0+ (参数高效微调) -
Datasets 2.16+ (数据集处理) -
Loguru (日志管理)
2.2 硬件要求
# 配置指定GPU卡 (第6号GPU)os.environ['CUDA_VISIBLE_DEVICES'] = '6'-
建议至少 24GB显存 的GPU -
推荐使用 BFloat16 精度训练
3. 模型架构
3.1 基础模型
-
Qwen2.5-0.5B-Instruct (5亿参数指令微调版本) -
通过 AutoModelForSequenceClassification扩展为分类模型 -
输出类别:2类 ( 夸大陈述/未夸大陈述)
3.2 LoRA微调配置
LoraConfig( task_type=TaskType.SEQ_CLS, target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"], r=64, # LoRA秩 lora_alpha=128, # 缩放系数 lora_dropout=0.1)-
关键优势:仅需训练0.1%的参数量,显著降低显存需求 -
适配层:针对Transformer各注意力头和FFN层进行适配
4. 数据处理流程
4.1 数据格式要求
-
输入数据: val_train.csv(CSV格式)数据方面我其实更推荐
jsonl格式的数据文件,操作起来更精简,处理起来更快速。 -
必需字段: -
content:待分析文本 -
label:分类标签 (0=夸大陈述, 1=未夸大陈述)
4.2 预处理步骤
-
分词处理: tokenizer(examples['content'], max_length=64, padding=True, truncation=True) -
标签映射: id2label = {0: "夸大陈述", 1: "未夸大陈述"}label2id = {"夸大陈述":0, "未夸大陈述":1} -
数据整理: -
移除原始文本列 ( content) -
添加 labels列用于训练
5. 训练配置
5.1 关键参数
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5.2 训练流程
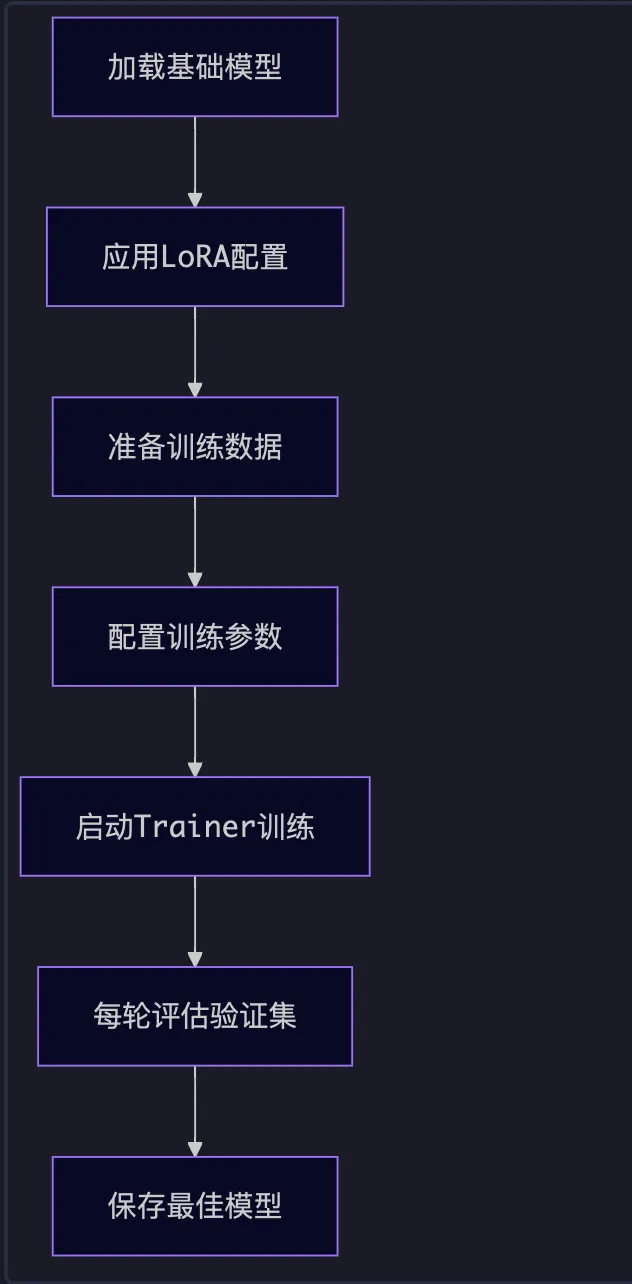
6. 评估指标
6.1 主要指标
-
F1 Score (加权):核心评估指标 -
Accuracy:准确率 -
Precision/Recall:精确率/召回率 (按micro/macro/weighted计算)
6.2 评估实现
defcompute_metrics(eval_pred): predictions, labels = eval_pred predictions = np.argmax(predictions, axis=1)return {"f1": f1_score(labels, predictions, average='weighted')}7. 模型使用指南
7.1 推理代码示例
from transformers import pipelineclassifier = pipeline("text-classification", model="./outputs/models", device=0# 使用GPU)result = classifier("这项技术将彻底改变整个行业格局!")print(result) # 输出: [{'label': '夸大陈述', 'score': 0.92}]7.2 部署建议
-
服务化部署: # 使用FastAPI封装uvicorn app:app --reload --port 8000 -
批处理模式: results = classifier(["文本1", "文本2", ...], batch_size=16)
8. 优化建议
-
数据增强:
-
对少数类样本进行回译增强 -
添加对抗性样本提升鲁棒性 -
模型调优:
# 尝试调整LoRA参数config = LoraConfig(r=32, lora_alpha=64) # 降低资源消耗 -
评估完善:
-
添加混淆矩阵可视化 -
增加错误案例分析模块
9. 常见问题处理
9.1 显存不足
-
解决方案: # 在模型加载时添加model = AutoModelForSequenceClassification.from_pretrained( ..., torch_dtype=torch.float16, # 降低精度 load_in_4bit=True# 4比特量化)
9.2 评估指标异常
-
检查点: -
确认 label2id映射正确 -
验证数据集中无缺失标签 -
检查 compute_valid_metrics函数中的变量定义