 夜雨聆风
夜雨聆风





《一款开源顶级 PDF 解析工具 | 本地部署 + 实战教程,RAG 开发者必看》
开篇引入
做过 AI 应用开发的朋友肯定都遭遇过 PDF 处理的噩梦:辛辛苦苦搭建的 RAG 系统,上传 PDF 后回答总是驴唇不对马嘴,要么是阅读顺序乱了,要么是表格内容完全提取错误,扫描版 PDF 更是直接变成一堆乱码。更头疼的是企业级场景下还要兼顾数据隐私和合规要求,上传到云端 API 根本行不通。今天就给大家分享一款近期 benchmark 排名第一的开源 PDF 解析工具——OpenDataLoader PDF,不仅精度吊打同类工具,还支持完全本地部署,兼顾性能、安全和合规性,看完就能上手用在自己的项目里。
项目详细介绍
OpenDataLoader PDF 是由 opendataloader-project 团队开发、Hancom Inc 提供技术支持的开源 PDF 处理工具,采用 Apache License 2.0 开源协议,完全免费可商用,官方仓库地址是 https://github.com/opendataloader-project/opendataloader-pdf。
这个项目的核心定位是”AI 就绪型 PDF 解析与可访问性自动化工具”,专门解决传统 PDF 解析工具丢失结构信息、复杂文档处理能力弱、合规改造成本高三大痛点,既能为 RAG 系统、大模型应用提供高质量的结构化数据输入,也能帮助企业快速完成大批量 PDF 文档的可访问性合规改造,完美适配开发者、企业 IT 部门、政务机构等不同用户的需求。
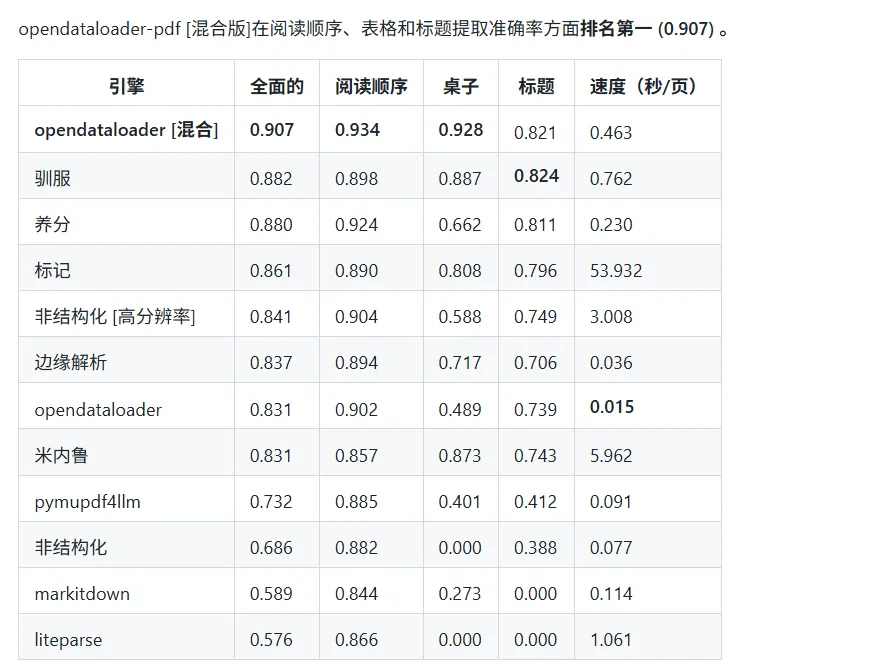
技术架构上采用分层设计:底层是 Java 11 编写的高性能解析引擎,中间层提供 Python、Node.js、Java 三种语言的 SDK 和命令行工具,上层可选混合 AI 服务处理复杂文档场景。这种设计既保证了解析性能(简单页面仅需 0.02 秒/页),又能通过 AI 扩展处理扫描件、复杂表格等特殊场景,目前在公开基准测试中总体精度达到 0.907,排名同类工具第一。
核心功能详解
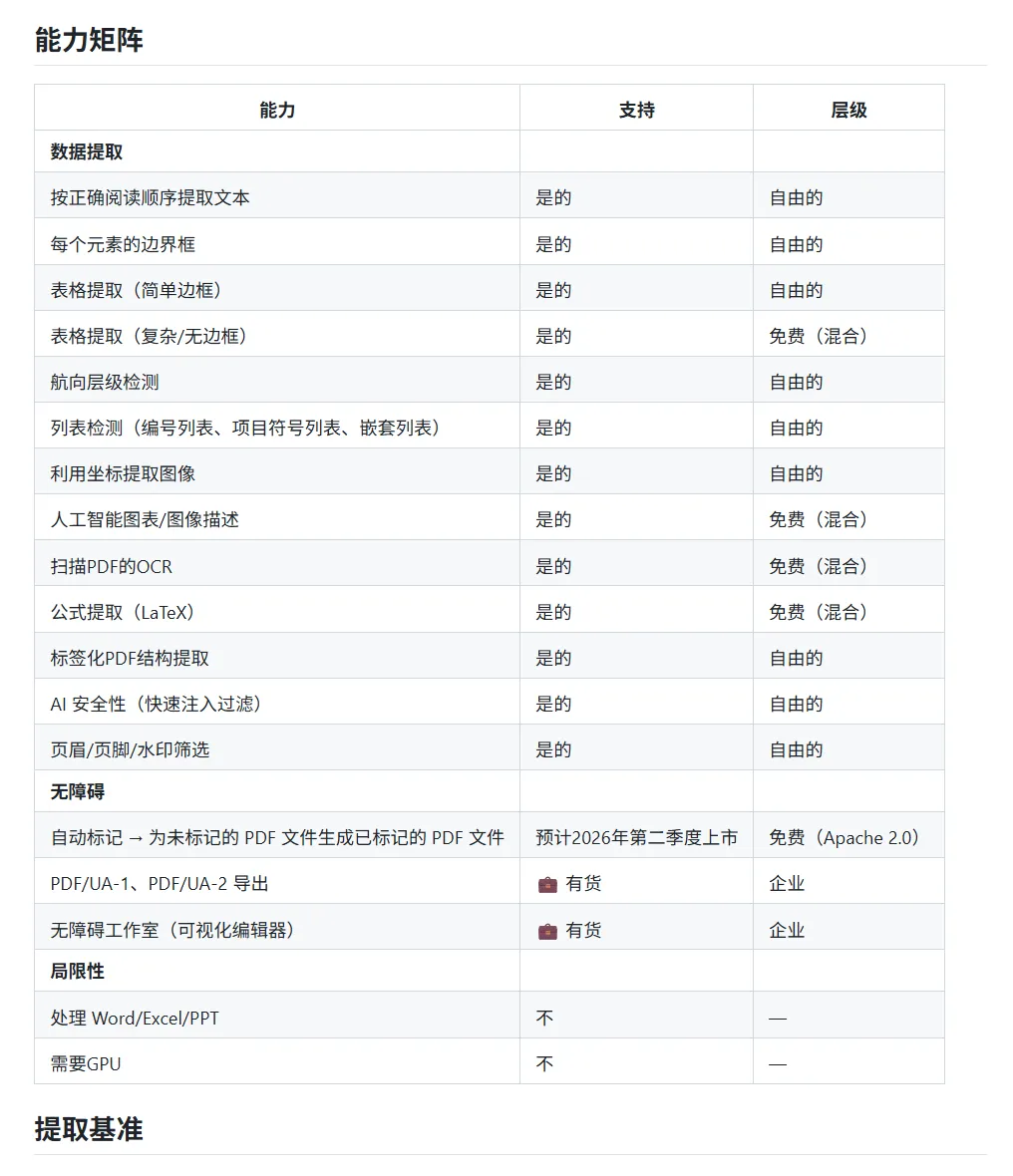
1. 高精度结构化数据提取
功能作用:从任意 PDF 文档中提取文本、表格、图像、标题等所有元素,完整保留阅读顺序和每个元素的精确坐标位置信息。
使用场景:RAG 系统数据准备、学术研究数据提取、文档内容分析、知识库建设等所有需要结构化 PDF 内容的场景。
实现逻辑:基于独创的 XY-Cut++ 算法,能够智能识别多列布局、嵌套表格、混合排版等复杂页面结构,通过确定性规则解析不需要 GPU 支持,同时为每个提取出来的元素附带精确的 bounding box 坐标,方便后续的溯源和定位。
优势亮点:基准测试总体精度 0.907 领先所有同类开源工具,是为数不多能同时支持简单表格和复杂无边框表格提取的工具,返回结果包含完整的层级结构信息,不会像传统工具那样把多列内容混排在一起。
2. 混合 AI 模式处理复杂文档
功能作用:结合本地快速解析引擎和轻量化 AI 后端,自动处理扫描版 PDF、复杂无边框表格、数学公式、图表等需要语义理解的复杂场景。
使用场景:扫描版 PDF 数字化、历史档案处理、包含大量复杂表格的财务/科研文档处理、图表内容识别与描述生成等。
实现逻辑:采用智能路由策略,简单页面直接用本地引擎快速处理(0.02 秒/页),识别到复杂页面时自动路由到本地 AI 后端处理,集成 Docling 模型实现 90%+ 的表格提取精度,同时支持 80+ 语言的 OCR 识别,完全不需要联网。
优势亮点:所有 AI 处理都在本地完成,不需要上传文档到第三方云端,彻底解决数据隐私问题;相比纯 AI 解析工具成本降低 80% 以上,速度提升 5 倍,同时保持了极高的解析精度。
3. PDF 可访问性自动化改造
功能作用:自动为未标记的 PDF 文档生成结构标签,输出符合 PDF/UA 标准的可访问性 PDF,帮助企业满足全球各地区的可访问性法规要求。
使用场景:企业大批量文档合规改造、政府/教育机构公开文档可访问性建设、无障碍服务适配等。
实现逻辑:采用”审计-自动标记-合规导出”三步 workflow:首先检测现有 PDF 的标签结构问题,然后基于布局分析自动生成符合标准的结构标签(全功能将于 2026 年 Q2 发布),最终导出通过 veraPDF 验证的 PDF/UA 合规文件,企业版还提供可视化标签编辑器功能。
优势亮点:全球首个开源的端到端 PDF 自动标记工具,与 PDF Association 合作开发,合规性有权威保障,相比传统人工标记成本降低 90% 以上,处理效率提升数十倍。
4. AI 安全与数据隐私保护
功能作用:内置 AI 安全防护能力,自动过滤潜在恶意内容,防止提示注入攻击,支持敏感数据脱敏,保护 AI 系统和数据安全。
使用场景:处理未知来源的 PDF 文档、政务/金融等敏感文档处理、云环境 AI 服务安全防护等。
实现逻辑:内置隐藏文本检测功能,自动识别并过滤页面外内容、透明文本等潜在的恶意注入内容;支持自定义敏感数据规则,自动替换身份证号、手机号、银行卡号等敏感信息;所有处理流程完全在本地完成,数据不会流出用户环境。
优势亮点:是少有的内置 AI 安全防护的 PDF 解析工具,完美适配等保 2.0、数据安全法等合规要求,处理敏感文档完全不用担心数据泄露问题。
5. 多格式输出支持
功能作用:支持 Markdown、JSON、HTML、Annotated PDF 等多种输出格式,满足不同场景的使用需求。
使用场景:大模型上下文输入、结构化数据分析、Web 页面展示、调试可视化、文档预览等。
实现逻辑:采用统一的输出抽象层,支持同时生成多种格式的输出,JSON 格式包含完整的元素元数据和位置信息,Markdown 格式保留完整的文档结构和排版,Annotated PDF 可以直观看到每个元素的识别结果。
优势亮点:所有输出格式都附带元素位置信息,方便后续的溯源和引用,支持格式组合使用(比如同时生成 markdown 和 json),无需多次解析同一个文档。
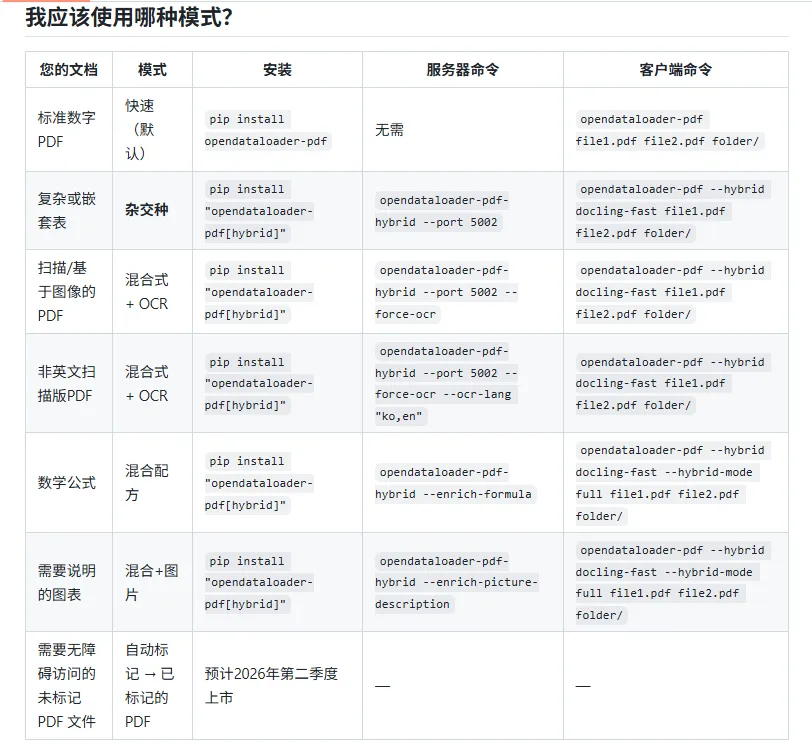
部署方法详解
环境准备
首先需要准备基础运行环境:
- Java 11+
:核心解析引擎依赖 Java 环境,推荐安装 Adoptium OpenJDK 11 或更高版本 -
检查 Java 版本:在命令行执行 java -version,确认版本号大于等于 11 -
安装方法:Windows/macOS/Linux 用户都可以从 Adoptium 官网下载对应版本一键安装 - Python 3.10+(可选)
:如果使用 Python SDK 需要 Python 3.10 或更高版本 - Node.js(可选)
:如果使用 JavaScript/TypeScript 绑定需要 Node.js 环境
安装步骤
OpenDataLoader 提供多种安装方式,开发者可以根据自己的技术栈选择:
Python 版本安装(最常用)
# 基础版本安装(包含核心解析功能,不需要AI能力选这个)
pip install -U opendataloader-pdf
# 混合模式安装(包含AI能力,需要处理扫描PDF、复杂表格选这个)
pip install -U "opendataloader-pdf[hybrid]"
Node.js 版本安装
npm install @opendataloader/pdf
实战使用教程
1. 命令行快速使用
处理单个 PDF 文档,同时输出 Markdown 和 JSON 格式:
opendataloader-pdf 输入文件.pdf --output-dir 输出目录/ --format markdown,json
2. 混合模式处理扫描 PDF
如果需要处理扫描版 PDF,先启动混合 AI 后端服务:
# 启动混合模式后端服务,端口5002
opendataloader-pdf-hybrid --port 5002 &
然后用混合模式处理扫描文档,强制开启 OCR:
opendataloader-pdf --hybrid docling-fast --force-ocr 扫描文件.pdf --output-dir 输出目录/
3. Python API 批量处理
如果需要批量处理多个 PDF 文档,推荐使用 Python API,效率更高:
import opendataloader_pdf
# 批量处理多个PDF文件
opendataloader_pdf.convert(
input_path=["文档1.pdf", "文档2.pdf", "文档3.pdf"],
output_dir="output/",
format="markdown,json",
hybrid="docling-fast"# 不需要AI能力可以去掉这个参数
)
验证与注意事项
-
执行完成后可以到输出目录查看生成的文件, .md文件是提取的 Markdown 内容,.json文件包含完整的结构化信息和元素坐标 - 重要提示
:每次 convert()调用都会启动一次 JVM,频繁调用单个文档建议使用批处理模式,能大幅提升处理效率 -
混合模式会占用更多系统资源,建议在 8G 以上内存的机器上运行,处理大批量文档时可以适当调整并行数参数
实际应用案例
案例 1:企业内部知识底座 RAG 系统
某头部金融科技公司需要搭建内部知识库 RAG 系统,需要处理 10 万 + 份内部制度、产品文档、研报等 PDF 资料,之前用传统工具提取的内容结构混乱,RAG 回答准确率只有 62%,还经常出现幻觉。
使用 OpenDataLoader PDF 后:
-
结构化提取准确率提升到 97%,完整保留了文档层级结构和表格内容 -
RAG 系统回答准确率提升了 35%,幻觉率降低了 28% -
所有处理完全在企业内网完成,满足金融行业数据合规要求 -
整体处理成本相比使用云端 API 降低了 70%
案例 2:政务文档可访问性合规改造
某副省级市政府需要对过去 10 年的 5 万多份公开 PDF 文档进行可访问性改造,满足《信息无障碍国家标准》要求,之前用人工处理每份文档需要 1 小时以上,成本极高,进度缓慢。
使用 OpenDataLoader PDF 的自动标记功能后:
-
单份文档处理时间缩短到 10 秒以内,整体处理效率提升 360 倍 -
处理后的文档 100% 通过 PDF/UA 合规验证,完全符合国家标准 -
整体项目成本相比人工处理降低了 92%,提前 3 个月完成改造任务
常见问题与解决方案
1. Java 环境相关问题
问题:运行时提示”Java 未找到”或”Java 版本过低”
解决方案:首先确认已经安装 JDK 11 或更高版本,然后检查 JAVA_HOME 环境变量是否正确配置,推荐从 Adoptium 官网下载官方版本,避免使用阉割版 JDK。
2. 混合模式不生效
问题:处理复杂文档或扫描 PDF 时效果很差,没有用到 AI 能力
解决方案:首先确认已经安装了混合模式版本(pip install -U "opendataloader-pdf[hybrid]"),然后确保在处理前已经启动了混合模式后端服务,处理时添加了 --hybrid docling-fast 参数。
3. 扫描 PDF 无法提取文本
问题:扫描版 PDF 处理后输出内容为空或者乱码
解决方案:处理扫描文档必须使用混合模式,同时添加 --force-ocr 参数强制开启 OCR,如果是非中文/英文文档,需要先安装对应语言的 OCR 语言包。
4. 大批量处理速度慢
问题:处理几百上千份文档时速度很慢
解决方案:不要循环调用单文件处理接口,使用 Python API 的批处理模式一次性传入所有文件路径,工具会自动利用多线程并行处理,效率提升 5 倍以上。
总结与展望
OpenDataLoader PDF 凭借其领先的解析精度、完全本地部署的隐私安全优势、多场景适配能力,已经成为目前开源 PDF 处理领域的首选工具,无论是个人开发者搭建 RAG 系统,还是企业级的文档处理和合规改造,都能很好地满足需求。
后续项目还将在 2026 年 Q2 发布全自动 PDF 标记功能,支持更多自定义 AI 模型接入,进一步提升超大文档的处理性能,感兴趣的朋友可以去 GitHub 点个 Star 关注后续更新。
结尾互动
如果觉得这篇干货对你有帮助,欢迎点赞、在看、转发给更多开发者朋友 ~ 关注我的公众号,后续会分享更多实用开源工具、AI 落地实战教程,有任何使用问题或者想了解的技术内容,欢迎在留言区交流哦 👇