 夜雨聆风
夜雨聆风





Claude Code 深度源码解析与架构哲学
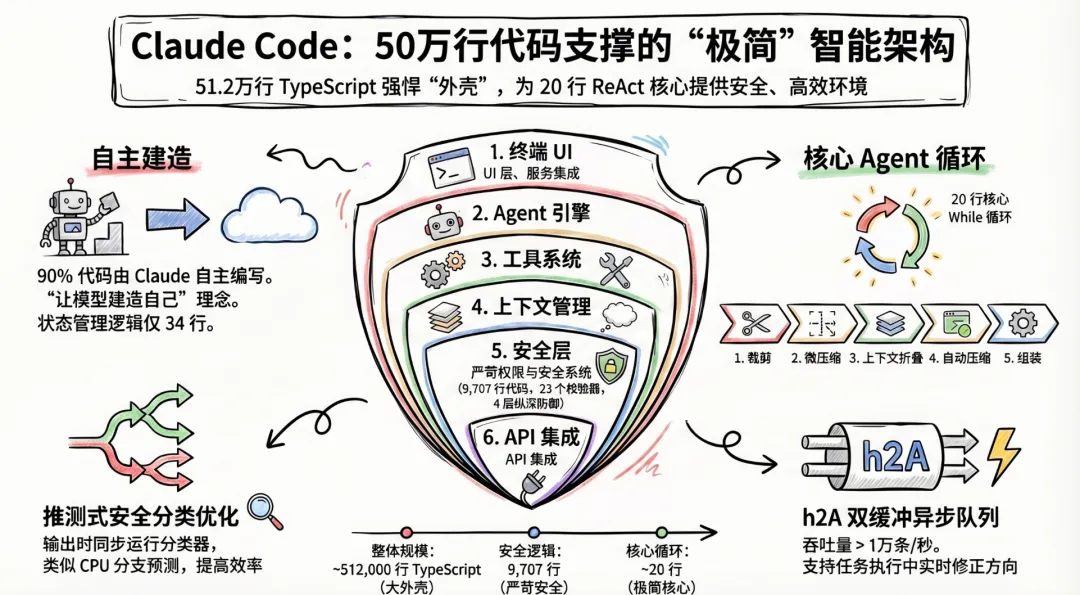
Claude Code 的核心设计可以用一句话概括:用 50 万行 TypeScript 构建的”harness”,服务于一个 20 行的 while 循环。 这个看似矛盾的比例恰恰揭示了 Anthropic 对 agent 系统的根本理解——模型足够强时,架构的职责不是”编排智能”,而是”为智能提供安全、高效的工作环境”。本报告基于 2026 年 3 月源码泄露(v2.1.88,约 1,906 个 TypeScript 文件、512,000 行代码)、shareAI-lab/Yuyz0112 等社区逆向分析、Anthropic 官方工程博客,以及中英文社区深度解读,对 Claude Code 进行全面的源码级架构剖析。
1.整体架构:六层结构与核心数据流
Claude Code 的架构可以抽象为六个层次,每一层都有清晰的职责边界:

技术栈选择体现了”让模型建造自己”的理念:TypeScript(Claude 最擅长的语言)、React + Ink(终端 UI)、Bun(构建与运行时,Anthropic 已收购 Bun)、Zod v4(运行时类型校验)。创始工程师 Boris Cherny 明确表示:”约 90% 的 Claude Code 代码由 Claude Code 自身编写。”状态管理仅 34 行代码——一个 createStore() 配合 React 的 useSyncExternalStore,没有 Redux,没有 Zustand。
2.Agent 主循环:20 行核心 + 5 步预处理管线
核心循环伪代码
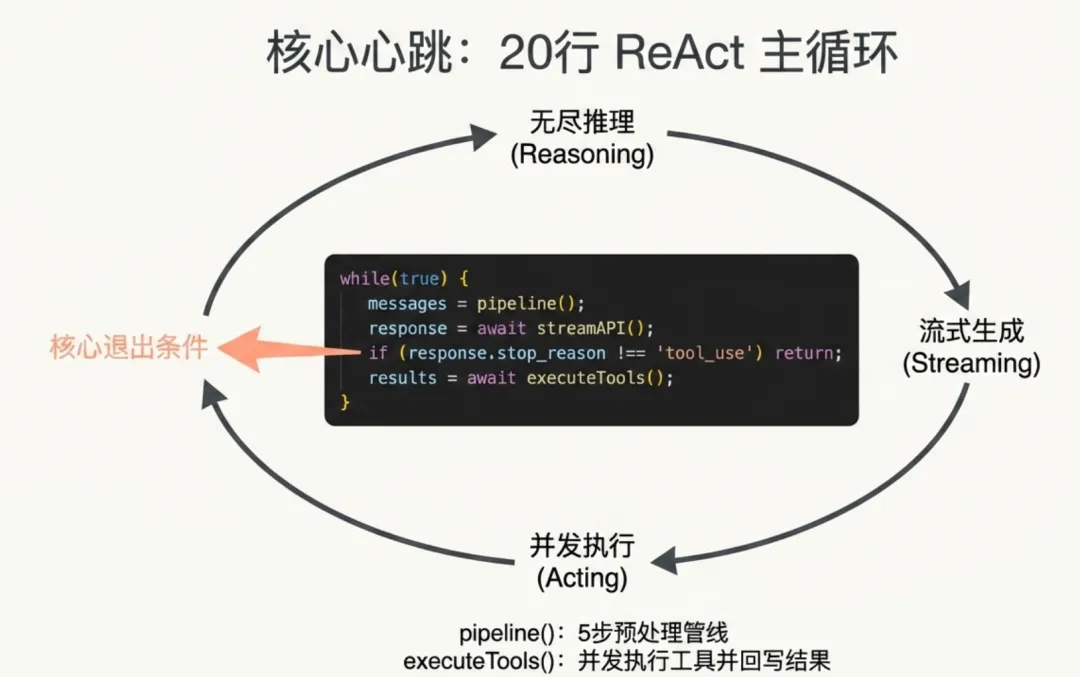
主循环位于 query.ts,实现了经典的 ReAct(Reasoning + Acting)模式:
asyncfunction*agentLoop(messages, tools, systemPrompt) {while (true) {// 5 步预处理管线messages=snip(messages); // 裁剪超长工具输出messages=microCompact(messages); // 清除旧工具结果(保留最近 5 条)messages=contextCollapse(messages); // 折叠冗余上下文messages=autoCompact(messages); // 若仍超阈值,执行完整压缩constrequest=assembleRequest(messages, tools, systemPrompt);constresponse=awaitstreamAPI(request); // POST /v1/messages (SSE)yield*streamToUI(response); // 实时输出到终端if (response.stop_reason!=="tool_use") returnresponse;consttoolCalls=response.toolUseBlocks;constresults=awaitexecuteTools(toolCalls); // 并发安全工具并行执行messages.push(response, ...results); }}
源码注释揭示了一个关键的顺序依赖:Context Collapse 刻意在 AutoCompact 之前执行——如果折叠操作就能将 token 数降到阈值以下,AutoCompact 就变成 no-op,从而保留更细粒度的上下文而非生成单一摘要。
流式执行与推测优化
Claude Code 在流式处理上有三个值得关注的优化:
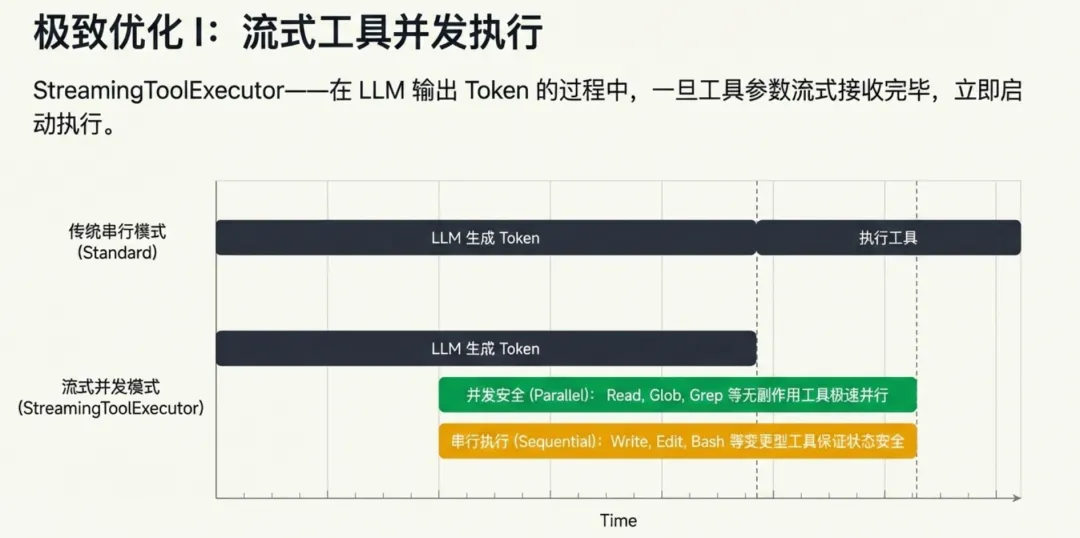
StreamingToolExecutor 在 LLM 尚未完成输出时就开始执行工具——当工具参数已经完整流式到达,执行立即启动。它将工具调用分为并发安全(Read、Glob、Grep 等只读工具)和串行执行(Write、Edit、Bash 等有副作用工具),前者并行处理。
推测式安全分类(startSpeculativeClassifierCheck):当模型正在流式输出 BashTool 的参数时,安全分类器已在并行运行。等输出完成时,分类结果可能已就绪——类似 CPU 的分支预测。
h2A 双缓冲异步消息队列实现了实时转向(steering)机制:当用户在 agent 执行过程中输入新消息,消息绕过缓冲区直接通过 Promise 解析送达(零延迟路径),吞吐量 >10,000 条/秒。这使得用户可以在 agent 工作时随时中断或修正方向。
3.工具系统:自描述、薄封装、权限内嵌
工具接口设计
每个工具通过 buildTool(definition) 工厂函数创建,拥有超过 20 个生命周期方法:
interfaceTool<Input, Output, Progress> {// 核心call(input: Input): Promise<Output>;inputSchema: ZodSchema; // Zod v4 运行时校验prompt(): string; // LLM 可见的工具描述// 能力声明isReadOnly(): boolean; // 无副作用?isConcurrencySafe(): boolean; // 可并行?isDestructive(): boolean; // 不可逆?interruptBehavior(): 'cancel'|'block';// 权限checkPermissions(): PermissionCheck;// UI 渲染(React/Ink)renderToolUseMessage(): ReactNode;renderToolResultMessage(): ReactNode;renderToolUseProgressMessage(): ReactNode;}
设计关键洞察:工具自描述自己——工具携带自己的描述、权限规则、并发特性。主流框架是”框架理解工具”,Claude Code 反过来让”工具向框架声明自己”。前者随工具增多框架越臃肿,后者框架始终保持轻薄。
完整工具清单与分类
| 类别 | 工具 | 特征 |
|---|---|---|
| 文件操作 | FileRead, FileEdit, FileWrite, NotebookEdit | Edit 强制要求先 Read(防盲改) |
| 搜索发现 | Glob, Grep (基于 ripgrep), ToolSearch | ToolSearch 实现延迟加载 |
| 执行 | Bash, PowerShell | 9,707 行安全校验;system prompt 明确要求优先用专用工具 |
| 网络 | WebFetch, WebSearch | 15 分钟自清理缓存;小模型做内容摘要 |
| Agent/Task | AgentTool, SendMessage, TaskCreate, TaskUpdate | 扁平化子 Agent,深度限制 1 |
| MCP | MCPTool(动态), ListMcpResources, ReadMcpResource | mcp__<server>__<tool> 命名空间 |
| 记忆/规划 | TodoWrite→TaskCreate/Update, MemoryRead/Write, EnterPlanMode, ExitPlanMode | Todo 作为外部工作记忆 |
| 用户交互 | AskUserQuestion, Brief | |
| 技能 | SkillTool, DiscoverSkills | /skill-name 调用 |
| 隐藏/未发布 | SleepTool, WebBrowser, Monitor, REPL, Tungsten, PushNotification… | 44 个 feature flag 控制 |
ToolSearch:Agent 世界的 Code Splitting
当连接大量 MCP 服务器时(Anthropic 内部曾达到 134K tokens 的工具定义),Claude Code 不将所有工具定义加载到 context 中。非核心工具标记为 defer_loading: true,模型初始只看到一个 ToolSearch 元工具。需要时,模型传入关键词动态加载具体工具定义——token 使用量最多降低 85%,这本质上是 Web 开发中 code-splitting 思想在 agent 领域的应用。
工具调用全链路
每次工具调用必须经过完整管线:
LLM 输出 tool_use → Zod 参数校验 → 工具自检 → Pre-hooks 执行 →canUseTool() 权限检查 → 实际执行 → Post-hooks → 结果格式化 →追加到 messages[] → 返回主循环
4.上下文管理:Claude Code 的核心竞争壁垒
三层记忆架构
Claude Code 的上下文管理是整个系统中工程投入最大的模块,实现了热-温-冷三层架构:
热层(Short-term):当前会话的 messages[] 数组,包含所有对话历史和工具结果。这是 LLM 实际处理的上下文。
温层(Medium-term):CLAUDE.md 文件(四级加载:组织→用户→项目→本地,40,000 字符容量)、会话 scratchpad(getScratchpadInstructions())、TaskCreate/TodoWrite 创建的任务列表。关键事实:CLAUDE.md 是唯一能在压缩后存活的上下文——这是架构约束,不是偶然选择。
冷层(Long-term):.jsonl 会话转录文件(可通过 Grep 搜索)、memdir/ 结构化记忆目录(索引 + 主题文件)。autoDream 在空闲期运行四阶段记忆整合:收集原始日志→提取关键信息→去重合并→写入结构化文件。
5 步压缩管线(深入细节)
原始消息 → Snip(裁剪超长输出) → MicroCompact(清除旧工具结果,保留最近5条,零API调用) → ContextCollapse(折叠冗余上下文) → AutoCompact(完整压缩) → 组装 API 请求
AutoCompact 触发机制:当 token 使用达到上下文窗口的 ~83.5%(200K 窗口约 167K tokens),预留 33K token 缓冲区用于压缩过程本身。可通过 CLAUDE_AUTOCOMPACT_PCT_OVERRIDE 环境变量调整。
压缩算法:fork 一个独立的 Claude 实例,使用 services/compact/prompt.ts 中的摘要 prompt,在 <analysis> 标签内进行链式思维推理,然后生成九段式结构化摘要:
-
会话目标
-
已完成任务
-
未完成任务
-
关键决策及其理由
-
代码变更摘要
-
发现的问题
-
待验证的假设
-
用户偏好
-
关键上下文信息
formatCompactSummary() 去除 CoT 推理过程后注入新上下文。旧消息被替换,但最近 5 条工具结果始终保留。一个曾经导致全球每天浪费约 250,000 次 API 调用的 bug(压缩连续失败时无限重试)通过 MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3 的三行修复解决。
“搜索,而非索引”——对 RAG 的否定
Claude Code 早期尝试过 RAG(使用 Voyage embeddings),但最终完全抛弃,转向基于 ripgrep 的 agentic search。Boris Cherny 在播客中明确表示:”我们试过 RAG,但发现让 AI 自己决定搜索什么效果好得多。” MinusX 团队将此比喻为”LLM 时代的 Camera vs Lidar”——Claude Code 用 Glob 和 Grep 进行 just-in-time 的上下文检索,完全绕开了索引同步、安全性和陈旧数据问题。
Anthropic 官方的 context engineering 博客文章进一步阐释了这一理念:“好的上下文工程意味着找到最小的、高信号的 token 集合,最大化某个期望结果的可能性。” Claude Code 的混合模型是 CLAUDE.md 预加载 + grep/glob 即时检索。
记忆存储的”怀疑主义”原则
memoryTypes.ts 中的 WHAT_NOT_TO_SAVE_SECTION 明确列出不应保存的信息:代码模式和架构(应该直接读代码)、git 历史(git log/blame 是权威来源)、调试方案(修复在代码里,上下文在 commit 中)、CLAUDE.md 中已有的内容、临时任务详情(用 Task 系统)。Agent 被明确指示将记忆视为提示,行动前必须对照实际代码库验证。
5.权限与安全模型:四层纵深防御
安全系统是 Claude Code 中最复杂的部分,总计超过 9,700 行代码,仅 Bash 安全校验就有 2,500+ 行。
四层防御架构
第一层——静态模式匹配(bashSecurity.ts):23 个编号安全检查,18 个被阻止的 Zsh 内置命令,防御 Zsh 等号展开(=curl 绕过权限)、Unicode 零宽空格注入、IFS 空字节注入、格式错误的 token 绕过(HackerOne 审计发现)。stripSafeRedirections() 使用 (?=\\s|$) 尾部边界正则防止 /dev/nullo 攻击。
第二层——语义分析(bashPermissions.ts):使用 tree-sitter WASM 解析器构建每条命令的 AST,理解实际意图——读取了哪些文件、写入了哪些路径、工作目录范围。
第三层——AI 分类器:对小模型发起侧查询,产出 Zod 校验的结构化 JSON(非简单的允许/拒绝)。超时或失败时回退策略始终是”询问用户”——无法证明安全时,提示人类确认。
第四层——用户确认:选择(允许/拒绝)可被记忆为 alwaysAllow/alwaysDeny 规则。Auto Mode 下小型 LLM 在后台静默评估安全性;频繁拒绝触发优雅降级。
原生客户端认证(反逆向)
system.ts 中 API 请求包含 cch=00000 占位符,Bun 的原生 Zig 级 HTTP 栈在发送时将零覆盖为计算哈希,服务端验证请求来自正版 Claude Code 二进制文件。同长度占位符避免 Content-Length 变化。
6.SubAgent 系统:为什么选择”扁平化”而非复杂编排
架构设计
Claude Code 的子 Agent 实现为普通工具调用——AgentTool 只是工具注册表中的又一个工具,没有单独的多 Agent 运行时。这是最关键的设计决策之一。
主 Agent(query.ts 主循环) │ ├── Fork Agent → 子进程,全新 messages[],共享文件缓存 ├── In-Process → 同进程,异步上下文,共享状态 ├── Worktree → 隔离 git 工作树 + fork └── Remote Agent → 桥接到 Claude Code Remote / 容器
六种内置 Agent 类型
| Agent 类型 | 职责 | 工具权限 | 触发条件 |
|---|---|---|---|
| general-purpose | 复杂多步任务 | 全部工具 (*) |
复杂任务分解 |
| Explore | 只读代码搜索 | Glob, Grep, Read, 安全 Bash | 查询次数 ≥ 3 |
| Plan | 架构规划 | 只读 + 增强 prompt (636 tokens) | 新特性、多方案、架构决策 |
| Verification | 对抗性验证 | 完整工具 | 编辑 ≥ 3 个文件后 |
| claude-code-guide | 文档查询 | Read | 使用疑问 |
| statusline-setup | 状态栏配置 | Read, Edit | 配置请求 |
上下文隔离与缓存共享(关键经济学)
子 Agent 的核心设计是上下文完全隔离:任务从主上下文提取 → 作为子 Agent 的初始 prompt → 执行过程中产生的”脏上下文”(中间工具调用、探索性输出)全部留在子上下文中 → 仅最终摘要以 tool_result 形式返回主上下文。
但 fork 模式有一个精妙的缓存优化:子 Agent 继承父 Agent 的 prompt cache 前缀(字节级相同副本),因此启动 5 个并行子 Agent 的 token 成本几乎等同于 1 个。这使得大规模并行探索在经济上可行。
为什么不做复杂的多 Agent 编排
Anthropic 在多篇博客中反复阐述这个选择的理由:
“有些需要所有 agent 共享相同上下文或涉及大量 agent 间依赖的领域,不适合多 Agent……大多数编码任务的真正可并行化部分比研究类任务少得多,LLM agent 尚不擅长实时协调和委派。”(来自多 Agent 研究系统博客)
Claude Code 创始工程师的表述更直接:“每次有新模型发布,我们就删一批代码。” 4.0 模型发布时删除了约一半的 system prompt。子 Agent 功能仅用 3 天构建(其中 2 天的工作被丢弃)。这种”可删除性”只有在架构足够简单时才可能。
深度限制为 1是刻意设计——子 Agent 不能再产生子 Agent。这防止了递归爆炸,也避免了多层 Agent 间的信息衰减(”电话游戏”效应)。Anthropic 的研究系统博客明确建议”子 Agent 将工作输出到文件系统以最小化信息传递损耗”。
自定义 Agent(.claude/agents/ 目录)
# .claude/agents/debugger.md---name: debuggerdescription: 错误调试专家tools: Read, Edit, Bash, Grep, Globmodel: claude-sonnet-4hooks: PreToolUse: - matcher: "Bash" hooks: - type: command command: "./scripts/security-check.sh"---你是一个调试专家。分析错误信息,定位根因,提出修复方案。
Agent 定义文件的 Markdown body 就是 system prompt,YAML frontmatter 声明工具、模型和钩子。
7.System Prompt 工程:动态组装与缓存经济学
动态组装流程
System prompt 不是静态文本——它由 getSystemPrompt() 函数从 25+ 个条件组件动态拼装:
[静态部分 — 全局可缓存]├── Intro(身份声明)├── System Rules(工具权限、prompt injection 防护、上下文压缩规则)├── Doing Tasks(编码哲学:编辑前先读、最小改动、不过度工程化)├── Executing Actions with Care(可逆性和影响范围指南)├── Using Your Tools(优先专用工具而非 Bash;因 repl_mode/task_tool 而异)├── Tone and Style(无 emoji、引用文件路径、GitHub 链接格式)├── Output Efficiency(内部版:工具调用间 ≤25 词;外部版:直奔主题)│──── __SYSTEM_PROMPT_DYNAMIC_BOUNDARY__ ──── ← 缓存分界线│[动态部分 — 每会话变化]├── Session Guidance(Agent 工具、Explore/Plan Agent、Skills、验证 Agent)├── Memory Prompt(持久化记忆系统指令)├── Environment Info(工作目录、平台、shell、模型名、git 状态、知识截止日期)├── Language(首选语言)├── Output Style(自定义输出风格)├── MCP Server Instructions(每个连接的 MCP 服务器指令,每轮重算)├── Git Status Snapshot(当前分支、最近提交、工作树状态)└── Append System Prompt(--append-system-prompt 自定义文本)
缓存分界线(SYSTEM_PROMPT_DYNAMIC_BOUNDARY)是 Claude Code 最精巧的工程决策之一:分界线之前的所有内容(指令、工具定义)跨所有组织全局缓存;之后的内容(CLAUDE.md、git 状态、日期)是会话特定的。团队追踪 14 个独立的缓存失效向量,包括:
-
工具确定性排序:工具按字母序排列(内置前缀 + MCP 后缀),防止排序变化导致缓存失效
-
状态外部化:Agent 列表从工具描述移到消息 Attachments——减少约 10.2% 的 Cache Creation Tokens
-
内容哈希路径:配置文件路径使用内容哈希而非原始路径
-
Sticky latches:防止模式切换打破缓存;
promptCacheBreakDetection.ts追踪 14 个缓存失效向量
系统提醒注入(~40 条动态提醒)
除了 system prompt,Claude Code 还在对话流中动态注入系统提醒:
-
system-reminder-start:第一条用户消息前,动态加载环境信息 -
system-reminder-end:第一条用户消息后,检查是否有 Todo 短期记忆需要加载 -
Plan mode 激活/重新进入提醒
-
Token 使用量统计
-
USD 预算统计
-
Task 工具使用提醒
-
TodoWrite 提醒
总 prompt 开销:约 2,800 tokens(system prompt)+ 约 9,400 tokens(工具描述)+ 1,000-2,000 tokens(CLAUDE.md)= 每次请求 ≥13,000 tokens 的固定开销。
8.MCP 集成与 Hooks 系统
MCP 动态工具发现
MCP 服务器通过 .mcp.json(项目级)或 ~/.claude/.mcp.json(用户级)配置,支持 stdio(本地进程)和 http/sse(远程)传输。所有 MCP 工具以 mcp__<server>__<tool> 命名空间出现。
MCP 输出限制:警告阈值 10,000 tokens,默认上限 25,000 tokens(可通过 MAX_MCP_OUTPUT_TOKENS 或工具声明的 anthropic/maxResultSizeChars 调整)。System prompt 包含一条实用规则:”如果 MCP 提供了 web fetch 工具,优先使用它而非内置 WebFetch(可能限制更少)”。
Hooks 系统:21 个生命周期事件 × 4 种处理器
Hooks 是 Claude Code 最强大的扩展点,提供 21 个生命周期事件:
最关键的是 PreToolUse(可阻断,exit code 2)——在工具执行前拦截,是最强力的控制点。此外还有 PostToolUse、Stop、SubagentStop、UserPromptSubmit、PreCompact/PostCompact、SessionStart/End、FileChanged 等。
四种处理器类型:Command(shell 命令,stdin 接收 JSON,exit code 控制)、HTTP(POST 到 URL)、Prompt(单轮 LLM 评估)、Agent(产生具有工具访问权的子 Agent 做深度验证)。
Hook 优先级:企业管理级(最高,不可禁用)→ 用户级 → 项目级 → 插件级 → Skill/SubAgent frontmatter 级。
9.设计哲学提炼:七条核心原则
综合 Anthropic 官方博客(”Building Effective Agents”、”Context Engineering”、”How We Built Claude Code”、多 Agent 研究系统)和源码分析,Claude Code 的设计哲学可以提炼为以下核心原则:
原则一:模型够强就不要堆架构。 Boris Cherny 说:”很多编码产品在模型前面加了太多脚手架,让模型感觉像用一条腿跑步。” Anthropic 的 harness 设计博客更明确:”harness 中的每个组件都编码了一个关于模型做不到什么的假设,这些假设值得反复压力测试,因为它们可能本来就是错的,而且随着模型进步会迅速过时。“
原则二:让模型做决策而非用代码硬编码流程。 所有执行路径都是 emergent 的——模型自己决定用哪个工具、何时委派、如何分解任务。Claude Code 团队”尽可能少写业务逻辑”。
原则三:工具是薄封装,安全规则内嵌在工具描述中。 安全规则在使用点(工具描述内)而非独立策略层。LLM 在指令紧邻动作上下文时注意力更强。
原则四:上下文是第一公民。 上下文窗口是有限且贬值的资源。”好的 context engineering 意味着找到最小的高信号 token 集合。” 工具输出限制 25K tokens,压缩管线五步精细化,just-in-time 检索优于预计算。
原则五:每次模型升级,删代码。 4.0 模型发布删了一半 system prompt。”不断删工具、实验新工具。” 这要求架构本身高度可删除。
原则六:可中断性和可观测性。 每个工具声明 interruptBehavior,用户可随时 Ctrl+C。h2A 消息队列支持执行中转向。21 个 Hooks 生命周期事件提供全面的可观测性。OpenTelemetry 追踪覆盖交互、LLM 请求、工具调用、钩子。
原则七:用便宜模型做便宜决策。 超过 50% 的重要 LLM 调用使用 claude-3-5-haiku(更小更便宜的模型)——配额检查、主题检测、会话摘要、安全分类。只有核心推理使用 Sonnet/Opus。
10.与主流 Agent 框架的对比分析
| 维度 | Claude Code | LangGraph | AutoGen | CrewAI |
|---|---|---|---|---|
| 核心模式 | while 循环 + 工具调用 | 有向图/状态机 | 对话式群聊 | 角色团队 + 任务管线 |
| 决策者 | 模型(隐式) | 代码(显式图边) | 模型(发言者选择) | 代码 + 模型 |
| 状态管理 | 扁平消息历史 | 图状态 + 检查点 | 会话历史(内存) | 任务输出顺序传递 |
| 上下文管理 | 5 步压缩 + 9 段摘要 + CLAUDE.md | 无内置压缩,靠开发者 | 无内置压缩 | 有限持久化 |
| 工具系统 | 自描述 + Zod 校验 + 权限内嵌 | 图节点 + 显式控制流 | Agent 携带工具 | 700+ 预建工具 |
| 多 Agent | 扁平子 Agent(深度 1) | 显式图编排 | 群聊辩论 | 角色委派 |
| 可观测性 | Hooks + OTel + 转录文件 | LangSmith 时间旅行调试 | Azure Monitor + OTel | 有限 |
| 代码搜索 | Agentic(ripgrep) | RAG/向量数据库 | 因实现而异 | 因实现而异 |
| 学习曲线 | 低(概念简单) | 中高(图概念) | 中 | 低 |
| 适用场景 | 通用编码/任务 Agent | 需要可预测保证的生产流程 | 迭代精炼/辩论 | 快速原型 |
根本哲学分歧:Claude Code 信任模型的自主判断(执行路径是涌现的),LangGraph 信任代码的显式控制(所有路径必须预定义)。这不是非此即彼——Anthropic 自己说:”如果 workflow 能解决,就不要用 autonomous agent。” 2026 年正在出现的混合模式是:LangGraph 做 workflow 骨架,Claude Agent SDK 在每个节点内做重型工作——兼得编排保证和执行力。
对多 Agent 系统的借鉴启示
可以直接搬用的模式
子 Agent 即工具调用:不引入独立的多 Agent 运行时,将 Agent 产生保持为普通工具调用。这保持了架构扁平、可组合、易调试。Agent 的产出以 tool_result 形式回到主上下文,与其他工具输出处理逻辑完全一致。
缓存共享的并行经济学:如果子 Agent 不能与父 Agent 共享 prompt cache,每个并行 Agent 都要支付完整的 cache creation 成本。Claude Code 通过 fork 子 Agent 继承父 Agent 的字节级相同 prompt 前缀,使并行化几乎免费。在设计多 Agent 系统时,缓存共享应从第一天就考虑。
模型分层:用便宜模型做安全分类、路由决策、摘要生成;贵模型只用于核心推理。Anthropic 的研究系统用 Sonnet 做子 Agent、Opus 做 Lead——token 使用量解释了性能方差的 80%。
结构化压缩而非简单截断:AutoCompact 的九段式摘要保留了决策理由和未完成任务,远优于简单的”保留最近 N 条消息”。MicroCompact(零 API 调用的本地清理)应作为第一道防线。
“怀疑主义记忆”:记忆是提示而非事实,行动前必须对照实际状态验证。这在多 Agent 系统中尤其重要——Agent A 的记忆可能与 Agent B 的操作结果矛盾。
Hooks 生命周期:PreToolUse/PostToolUse 模式为工具执行提供了可编程拦截点,无需修改工具本身。这在多 Agent 场景中可扩展为 Agent 间的策略层。
需要适配的模式
深度 1 限制:Claude Code 的单层子 Agent 适合编码场景,但研究型多 Agent 系统可能需要更深的委派层次(如 Lead → Specialist → Sub-specialist)。适配方案:保持”任务描述 → 执行 → 摘要返回”的模式,但允许可控深度(如最大 2-3 层),每层都有独立的上下文隔离和摘要压缩。
隐式委派 vs 显式委派:Claude Code 让模型自己判断何时委派,这在代码任务中工作良好但在需要审计轨迹的场景(如金融、合规)中不够透明。适配方案:在 Tool 描述中编码明确的委派策略(”当任务满足 X 条件时,必须使用 Agent 工具”),同时在 Hooks 中记录完整的委派决策链。
CLAUDE.md 的静态注入:CLAUDE.md 每次查询都重新读取并注入,对于多 Agent 系统需要考虑共享 vs 私有配置的问题。适配方案:区分全局配置(所有 Agent 共享)和角色配置(特定 Agent 专属),通过命名空间管理。
单一对话线程:Claude Code 的扁平 messages[] 对于需要 Agent 间协商、辩论或共享中间结果的场景不够用。适配方案:引入共享工作空间(文件系统或结构化存储),Agent 间通过文件/任务板通信而非直接消息传递——这正是 Claude Code 实验性 Swarm 模式采用的方式。
Claude Code 中对多 Agent 系统而言是反模式的设计
单线程假设:Claude Code 的扁平消息历史 + 单主线程对于真正的对等协作(peer-to-peer collaboration)是不够的。如果你的场景需要 Agent 间的实时协商(如 AutoGen 的群聊辩论),这个模式需要被替换为更丰富的通信拓扑。
模型锁定:Claude Code 的缓存共享、prompt caching 策略与 Claude API 深度耦合。如果你的多 Agent 系统需要混用不同提供商的模型(如 Claude 做推理 + GPT 做代码生成 + 本地模型做安全分类),这些优化策略无法直接移植。
上下文压缩的信息损失:研究发现,对于超长会话,全上下文重置(从 handoff artifact 启动新 Agent 实例)有时优于压缩。在多 Agent 研究系统中,每个子 Agent 本身就是”全新上下文”,这天然解决了压缩损失问题——这也正是 Anthropic 研究系统的做法。
安全模型的集中化:Claude Code 的四层安全防御假设了单一用户在本地终端操作的场景。多 Agent 系统需要 Agent 间的互信评估(Agent A 是否信任 Agent B 的输出?)、权限传递(Lead 的写权限是否自动授予 Worker?)、以及操作冲突检测(两个 Agent 同时编辑同一文件),这些在 Claude Code 当前架构中缺乏原生支持。Swarm 模式的文件锁定和任务板是朝这个方向的初步尝试。
结论:harness 思维与 Agent 系统的未来
Claude Code 最深刻的启示不在于任何具体技术细节,而在于它对”Agent 系统中什么是真正困难的”的回答。512,000 行代码中,核心 Agent 逻辑可能只占千分之一——其余都是 harness:让模型安全地与世界交互的上下文管理、权限系统、工具接口、缓存优化、可观测性和错误恢复。
这颠覆了”Agent 框架应该提供智能编排”的常见假设。Claude Code 说的是:编排应该尽可能少,环境应该尽可能好。模型的推理能力是指数增长的,而你为弥补模型不足而写的编排代码,每次模型升级都可能变成技术债。
对于构建通用任务 Agent 和研究型多 Agent 系统的架构师,最实用的行动建议是:
-
先建 harness,后建编排——投入 80% 精力在工具质量、上下文管理和安全系统上
-
以”可删除性”为架构指标——如果明天模型能力翻倍,你的系统哪些部分可以直接删掉?
-
上下文工程优先于 prompt 工程——压缩管线、缓存策略、just-in-time 检索的工程投入回报远高于调 prompt
-
子 Agent 即工具调用 + 缓存共享——这个模式在多数场景下是最优的起点,只在确实需要更复杂拓扑时才引入额外抽象
-
用评估驱动一切——Anthropic 从 20 个测试用例开始,用 LLM-as-judge 做可扩展评估,人工测试捕捉自动化遗漏的问题(他们的早期 Agent 持续选择 SEO 优化的内容农场而非权威来源,这是人工评估发现的)
Anthropic 在 context engineering 博客的结尾写道:”随着模型能力提升,agentic 设计将趋向于让智能模型智能地行动,逐步减少人工策展。鉴于该领域的快速进展,’做最简单有效的事’可能仍将是我们最好的建议。” 这句话本身就是 Claude Code 全部设计哲学的最佳总结。