夜雨聆风
夜雨聆风





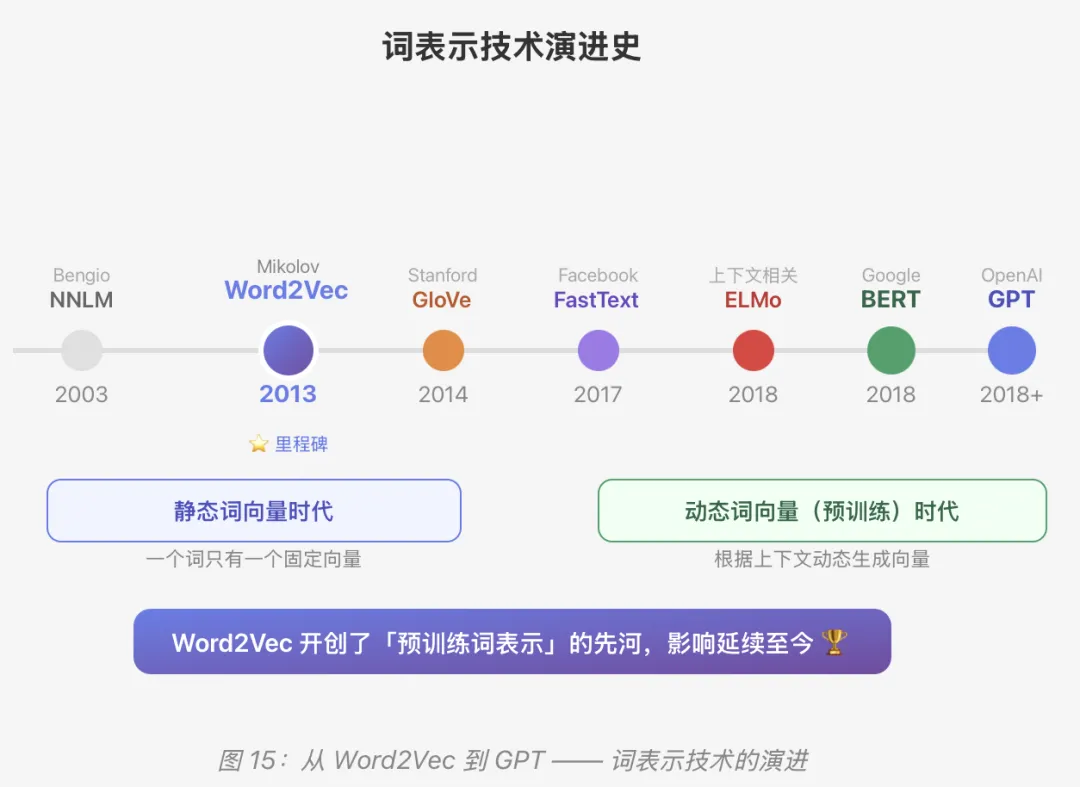
Word2Vec 模型原理详解
01、为什么需要 Word2Vec?
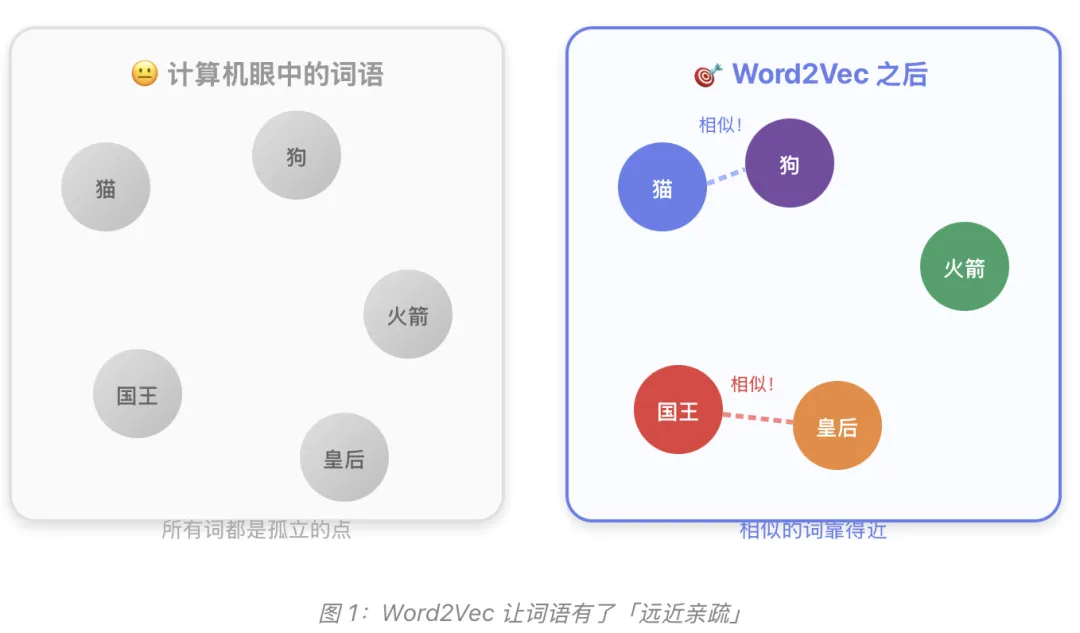
想象你是一个外星人,刚来到地球。你手里有一本字典,里面有 10 万个中文词。但你完全不知道「猫」和「狗」的关系比「猫」和「火箭」更近。
计算机就面临着同样的困境——它只认识 0 和 1,对它来说,「国王」和「皇后」跟「国王」和「土豆」一样陌生。
生活类比:通讯录 vs 社交关系
你的手机通讯录里,「张三」和「李四」只是两个不同的名字(就像 One-Hot 编码)。
但在现实中,张三是你的同事、李四是你的大学室友——他们之间有丰富的关系。Word2Vec 就是帮计算机建立这种「社交关系图谱」的工具!
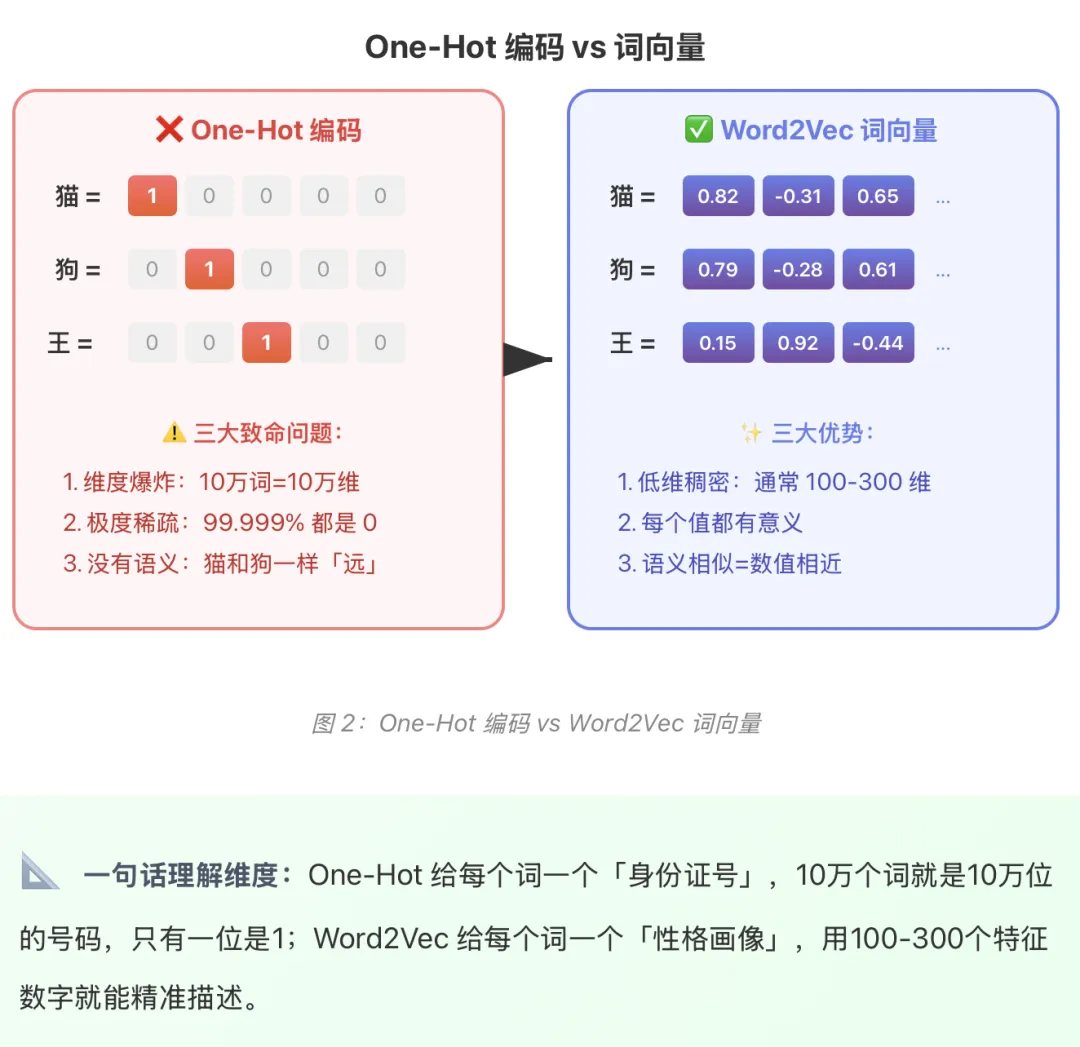
02、从 One-Hot 到词向量:编码进化史
在 Word2Vec 之前,计算机用一种叫One-Hot 编码的方式表示词语。这就像给每个学生分配一个编号:
03、核心思想:物以类聚,词以群分
Word2Vec 背后最核心的语言学假设非常简单:「你能通过一个词的邻居,了解这个词的含义」
生活类比:看朋友圈猜身份
如果一个人的朋友圈经常出现「手术刀」「病房」「处方」「体检」这些词,你很容易猜到——这人大概率是个医生。
同样,如果「猫」和「狗」经常出现在相似的句子中(比如「我养了一只___」「___在沙发上睡觉」),那它们的意思一定很接近!
上下文窗口:观察的范围
Word2Vec 用一个滑动窗口在句子上移动,捕捉每个词的「邻居」。窗口大小通常设为 5(左边2个词 + 右边2个词):
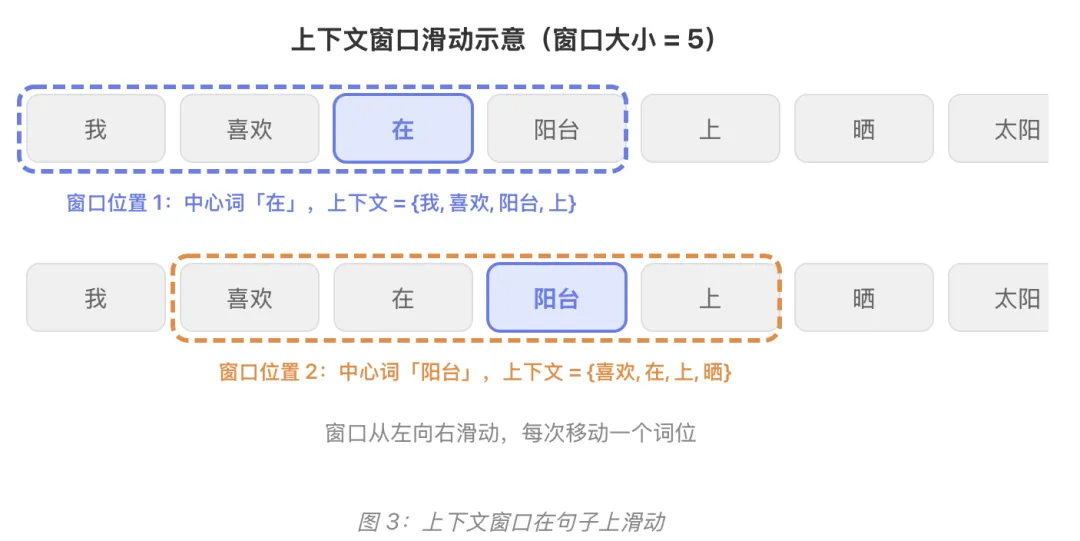
窗口每滑动一步,就产生一组训练数据。整个语料库有几百万个句子,每个句子滑动多次——海量训练数据就这样自动产生了,完全不需要人工标注!
4、CBOW 模型:完形填空游戏
Word2Vec 有两种模型架构,第一种叫CBOW(Continuous Bag of Words,连续词袋模型)。它的思路特别好理解:
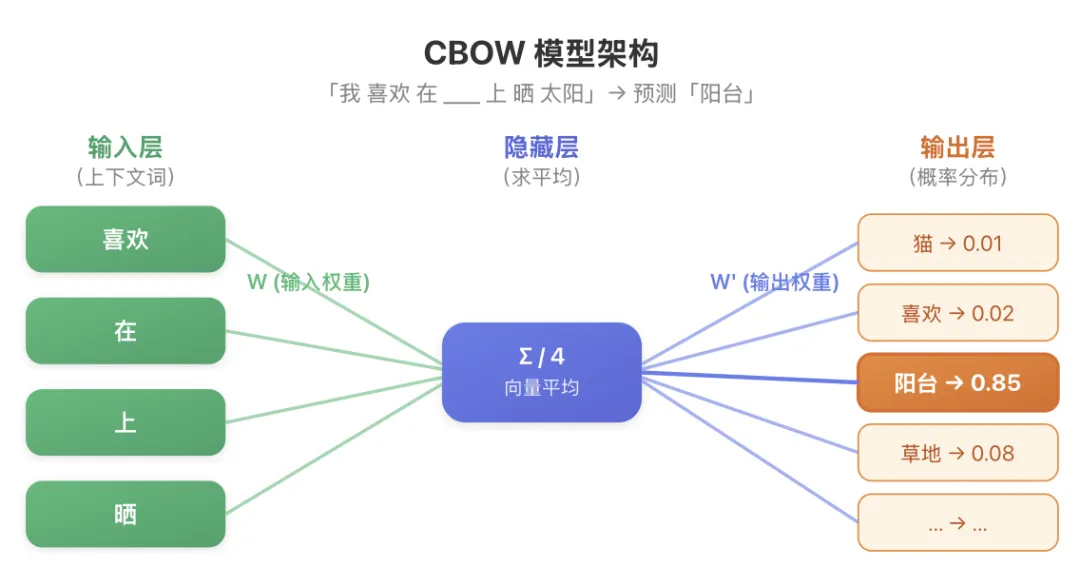
① 把上下文词的词向量取出来 → ② 求平均得到一个向量 → ③ 通过输出层计算概率 → ④ 概率最高的就是预测结果。训练时:如果预测错了,就调整权重矩阵 W 和 W’,让预测越来越准
图 4:CBOW 模型 —— 用上下文预测中心词
为什么叫「词袋」?因为 CBOW 把上下文词「装进一个袋子里」求平均,不关心词的顺序。「喜欢 在 上 晒」和「上 在 喜欢 晒」对 CBOW 来说一样。这是它的简化之处,也是它的局限。
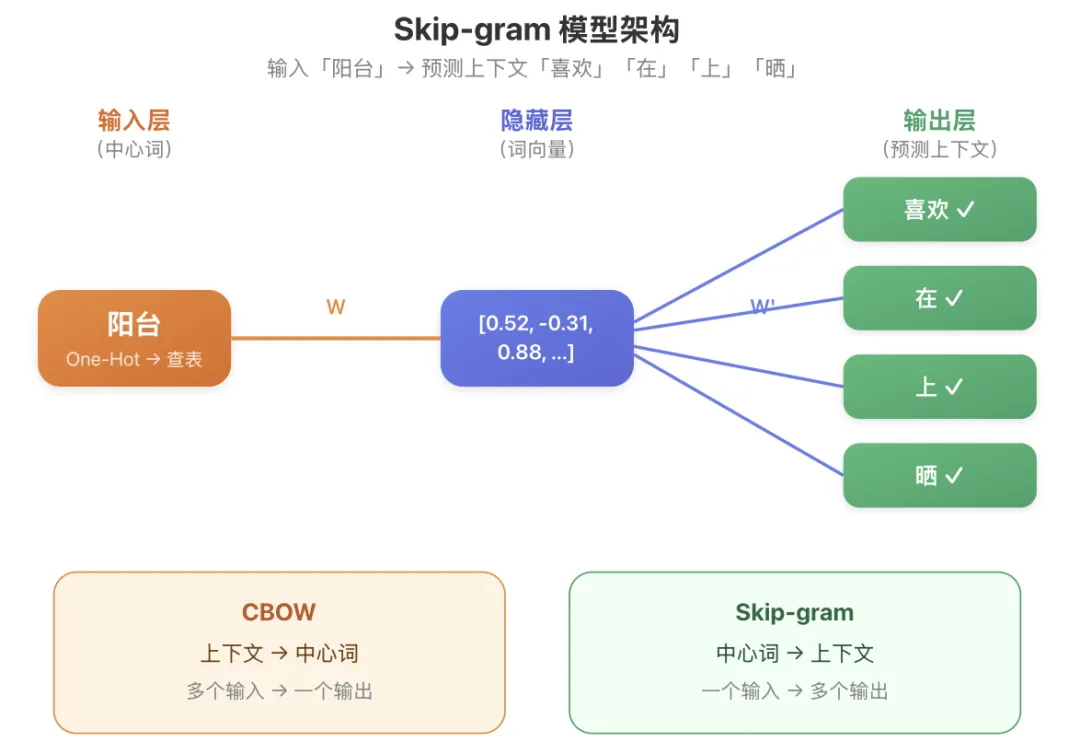
05、Skip-gram 模型:反向猜词
Skip-gram 是 CBOW 的「镜像版」,思路恰好反过来:已知中间的词 → 猜周围的词就像看到一个人,猜他的朋友圈!给你「阳台」这个词,你能联想到哪些常常和它一起出现的词?「晒太阳」「花盆」「衣服」「风景」…… Skip-gram 就是训练机器做这种联想。
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
06、神经网络结构拆解:权重矩阵的秘密
前面提到了 W 和 W’ 两个权重矩阵,这才是 Word2Vec 的核心宝藏。我们来看看它们长什么样:

生活类比:字典查词
W 矩阵就像一本「特殊词典」。普通词典查到的是释义文字,而 W 矩阵查到的是一组数字——这组数字就精确地编码了这个词的语义特征。训练 Word2Vec 的过程,就是不断修正这本「数字词典」,让每个词的「数字释义」越来越准确。
07、Softmax:把数字变成概率
神经网络输出的是一堆原始分数(logits),我们需要把它们变成概率——也就是每个词被预测的可能性。这时候 Softmax 函数登场了:

08、负采样:聪明的偷懒
完整的 Softmax 要计算词汇表中每一个词的概率,太费劲了。负采样(Negative Sampling)说:我们不用考虑所有词,只需要关注一小撮就行!
生活类比:考试不用考所有题
想象你在学英语单词。老师不可能每次考你全部 5000 个单词,而是挑 1 个正确答案 + 5 个干扰项,看你能不能区分出来。
负采样的思路一模一样:1 个正样本 + K 个随机抽取的负样本,每次训练只更新这 K+1 个词的参数。

负样本怎么抽?
负样本不是完全随机抽的,而是按照词频的3/4 次方来采样:

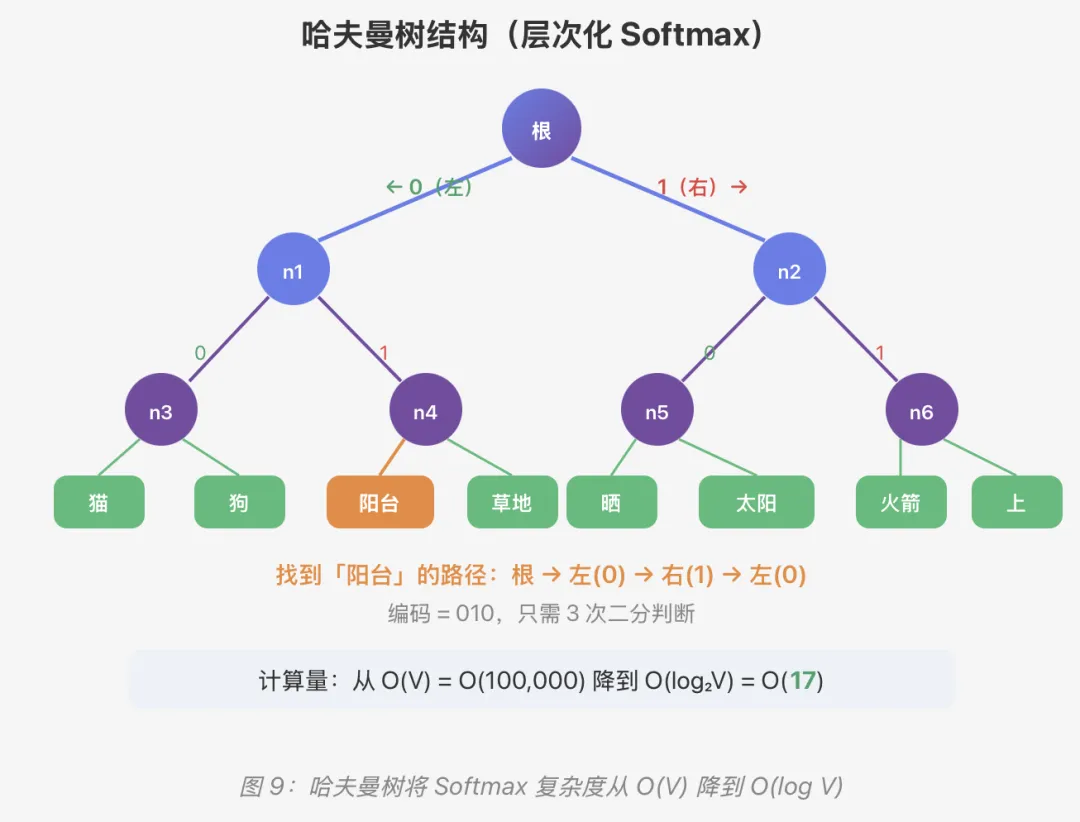
09、层次化 Softmax:用二叉树加速
除了负采样,还有另一种加速方式——层次化 Softmax(Hierarchical Softmax)。它用一棵哈夫曼树来替代输出层。
生活类比:二十个问题游戏
你在玩「猜动物」游戏。与其从 10 万个动物里一个个猜,不如这样问:
「是哺乳动物吗?」→「是猫科吗?」→「是家养的吗?」→「是猫!」
只用了 3-4 个问题就从 10 万个里找到了答案。每个问题把搜索范围砍一半,这就是二叉树的威力!
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10、词向量的魔法运算 ✨
Word2Vec 最令人惊叹的发现是:训练好的词向量居然可以做语义算术!
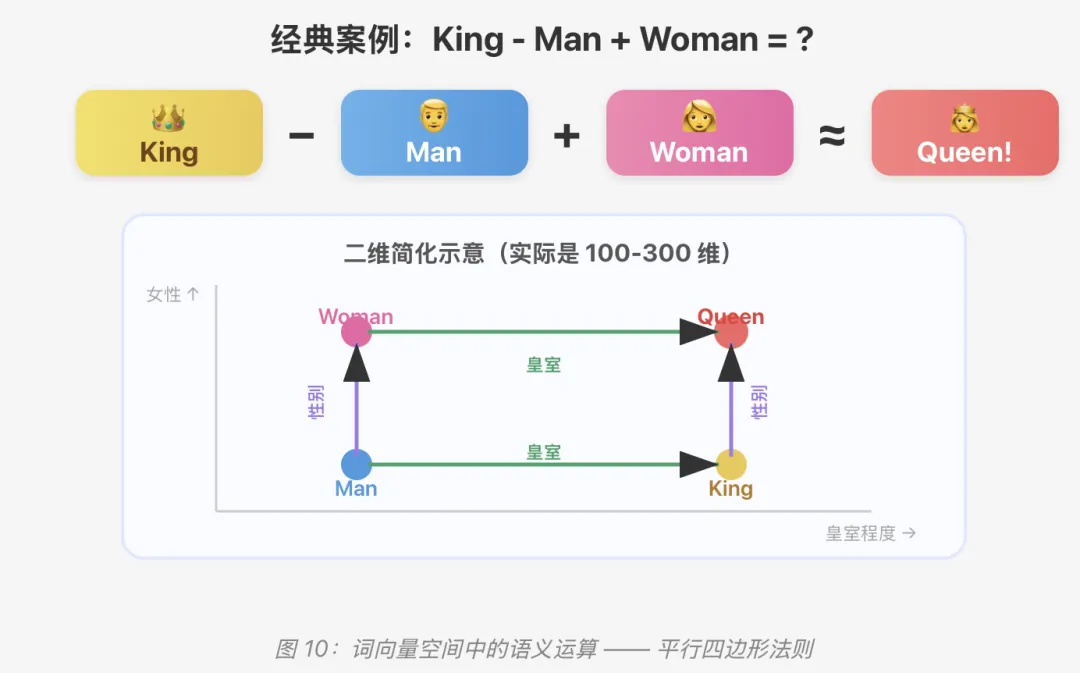
更多有趣的向量运算
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
11、超参数调优:窗口大小与向量维度
训练 Word2Vec 时,有两个最重要的超参数需要选择:

12、训练过程可视化
让我们把 Word2Vec 的完整训练流程串起来:
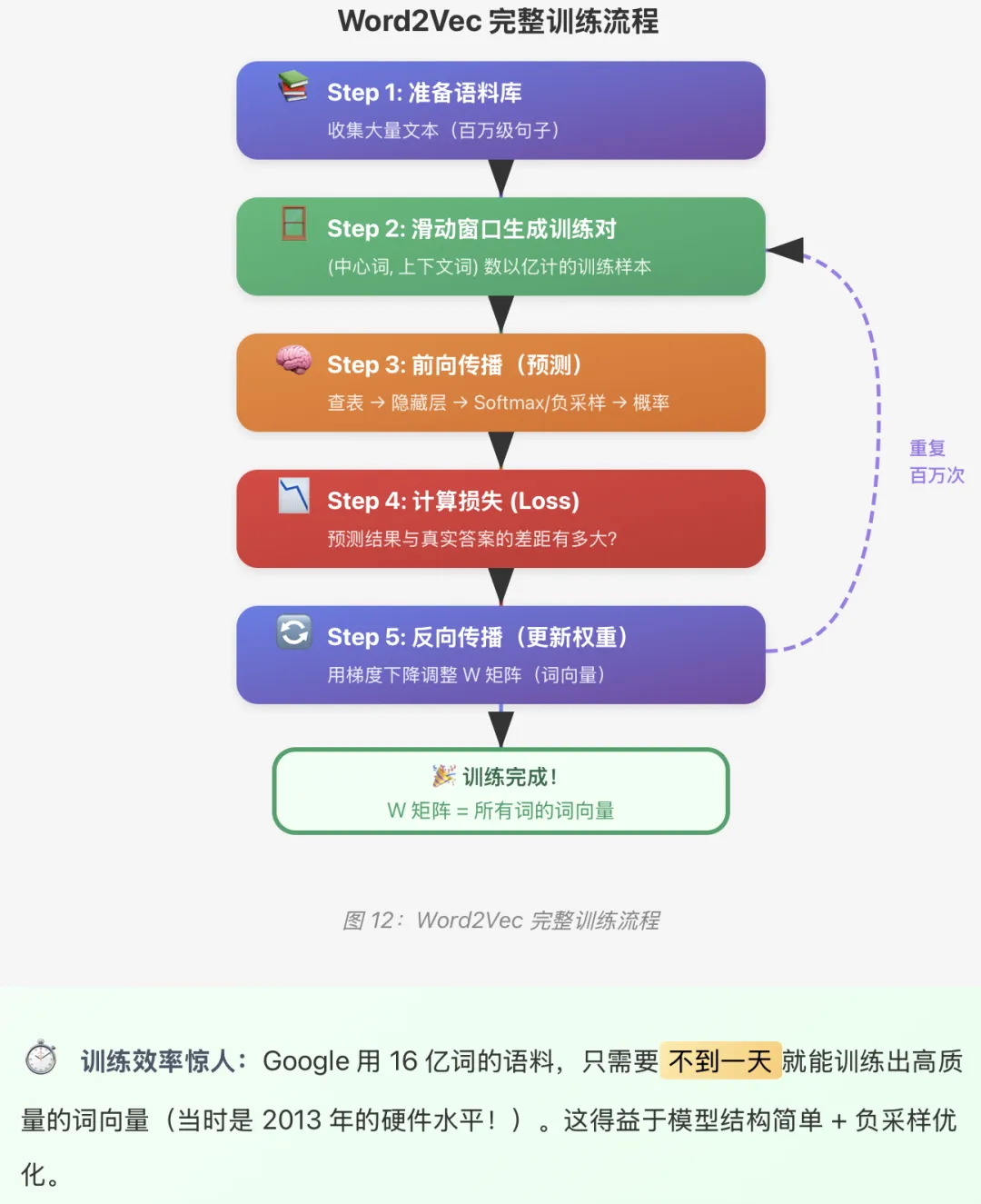
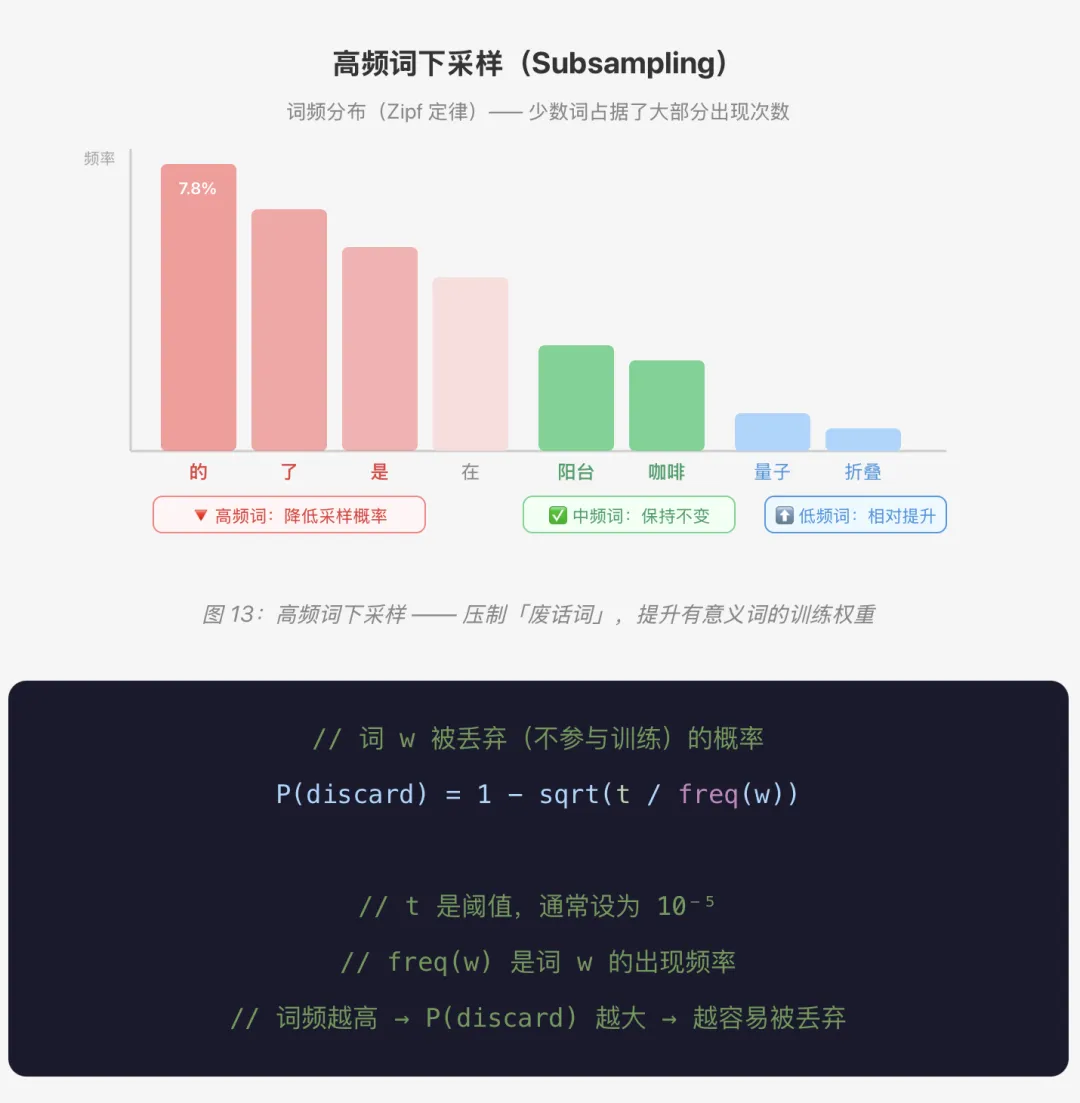
13、高频词处理:下采样的智慧
在任何语言中,「的」「了」「是」「在」这些词出现频率极高,但信息量却很低。如果不做处理,训练时大量时间都在学习这些「废话词」。
14、Word2Vec 的局限性
Word2Vec 虽然是划时代的工作,但也有明显的局限:

15、Word2Vec 的历史地位与发展脉络