 夜雨聆风
夜雨聆风





CodeBurn:你的 AI 编程助手到底烧了多少 token
AI 编程助手的 token 花费是个盲区。Claude Code 的计费页只给一个总数字,Cursor 更是连这个都没有。你想知道某个项目花了多少、哪类操作最烧钱、Opus 和 Sonnet 各占多少比例——目前没有官方工具能做到。
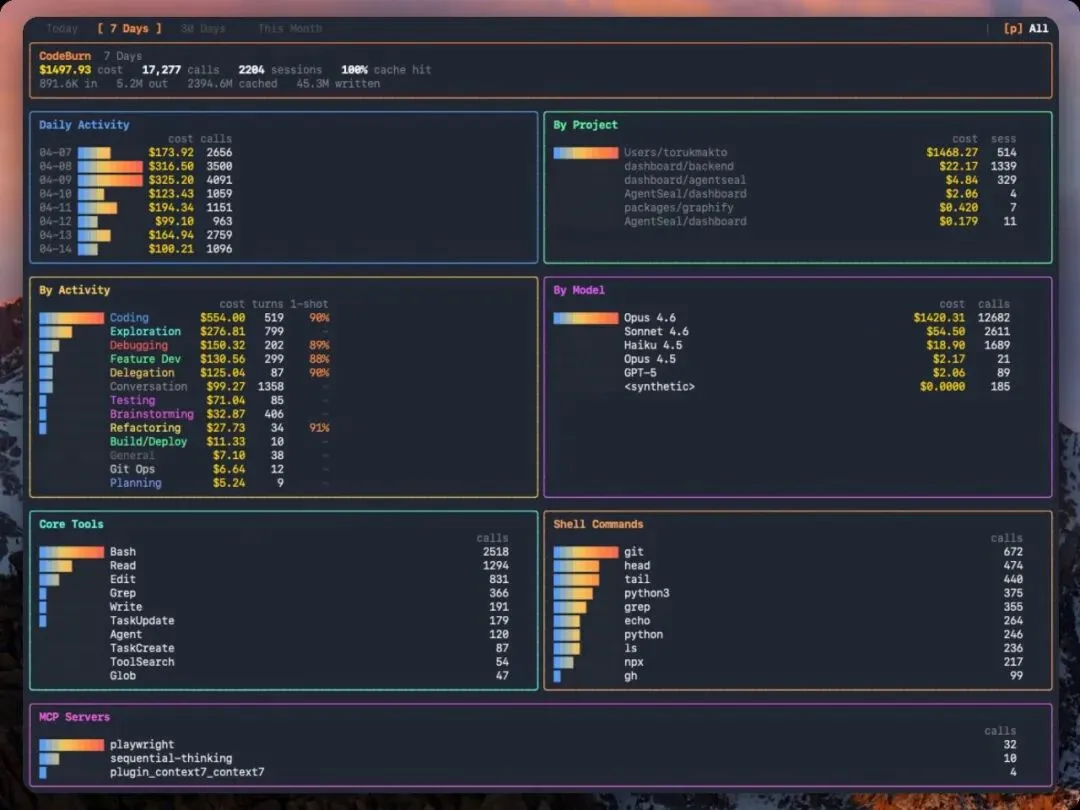
CodeBurn 直接从磁盘上读 session 日志,在一个终端 TUI 里把这些数据拆开给你看。
项目卡片
项目:CodeBurn[1] 状态:v0.7.1 / 2.5k stars / 5 天发布 8 个大版本 一句话判断:目前最完整的 AI 编程成本观测工具,从”看数据”进化到了”给方案”
我一开始以为它要做 proxy 或者 wrapper,看了源码才发现思路更直接:Claude Code 的 session 文件就存放在 ~/.claude/projects/ 下面,每个 session 是一个 JSONL 文件,里面完整记录了每次 API 调用的模型、token 用量(input / output / cache read / cache write)、工具调用和时间戳。
CodeBurn 直接读这些文件,解析、去重、分类、算钱。不需要你配任何东西。
定价数据来自 LiteLLM[2] 的模型价格表,自动缓存 24 小时。本地还硬编码了一份 fallback,覆盖所有 Claude 和 GPT 系列模型,离线也能算价。
代价也有:它只能统计本机的数据,多机用户得分别跑。
这类工具我之前只见过只支持单一 provider 的(比如 ccusage 只看 Claude)。CodeBurn 从 0.4.0 开始搭了 provider 插件系统,现在覆盖 7 个数据源:
| Provider | 数据位置 | 备注 |
|---|---|---|
| Claude Code | ~/.claude/projects/ |
最完整的数据,支持所有面板 |
| Claude Desktop | ~/Library/Application Support/Claude/ |
macOS 代码标签页 |
| Codex (OpenAI) | ~/.codex/sessions/ |
工具名已标准化映射 |
| Cursor | SQLite 数据库 | Auto 模式下按 Sonnet 估算 |
| OpenCode | ~/.local/share/opencode/ |
SQLite |
| Pi | ~/.pi/agent/sessions/ |
JSONL |
| GitHub Copilot | ~/.copilot/session-state/ |
仅统计输出 token |
添加新 provider 只需要写一个文件,实现 discoverSessions() 和 createSessionParser() 两个方法。Cursor 和 OpenCode 因为依赖 better-sqlite3,作为 optional dependency 延迟加载,不影响只用 Claude 的用户。
Dashboard 用 Ink(React for terminals)构建,支持键盘导航,左侧时间维度(Today / 7 Days / 30 Days / Month / All Time),下面是多个面板:
Overview:总花费、API 调用次数、session 数、缓存命中率。缓存命中率值得盯——如果持续低于 80%,说明你的系统提示词或上下文不够稳定,每次 session 都在重写缓存。
By Project:每个项目的花费和 session 数,还有新增的 context overhead 列,展示每个项目每次 session 的系统提示词 + 工具定义 + CLAUDE.md 的 token 开销。
By Activity:13 个任务分类。这不是 LLM 分类,而是纯确定性规则——根据工具调用模式和用户消息关键词分类。
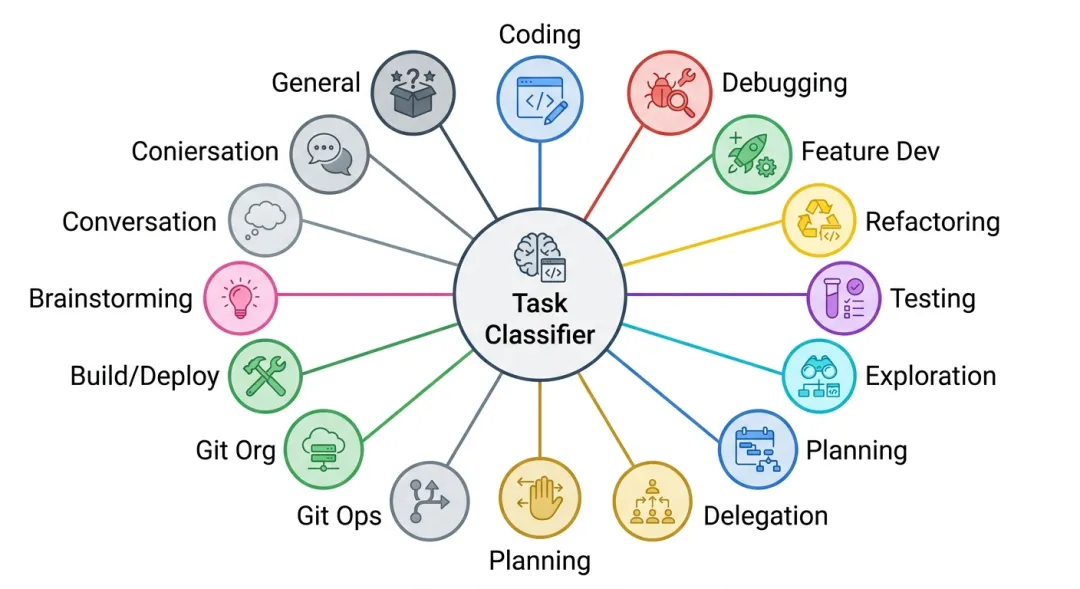
分类器逻辑分三层:先看工具模式(有没有 Edit、有没有 Bash、有没有 Agent 调用),再用关键词精炼(有 “fix” 就是 debugging,有 “refactor” 就是 refactoring),最后对无工具的纯对话单独处理。
最有价值的是 one-shot rate(一次成功率)。对于涉及编辑的分类,CodeBurn 检测 Edit → Bash → Edit 的重试循环。Coding 一次成功率只有 30% 意味着 AI 在反复改——要么你的需求不够清晰,要么该换个模型。
By Model:各模型的调用次数和花费。如果你看到 Opus 4.6 在简单任务上主导了成本,那就是用牛刀杀鸡。
Core Tools / Shell Commands / MCP Servers:看 AI 都在调什么工具、跑什么命令、连什么 MCP server。
0.7.0 引入的 codeburn optimize 是我判断这个项目”不只是个看板”的关键。
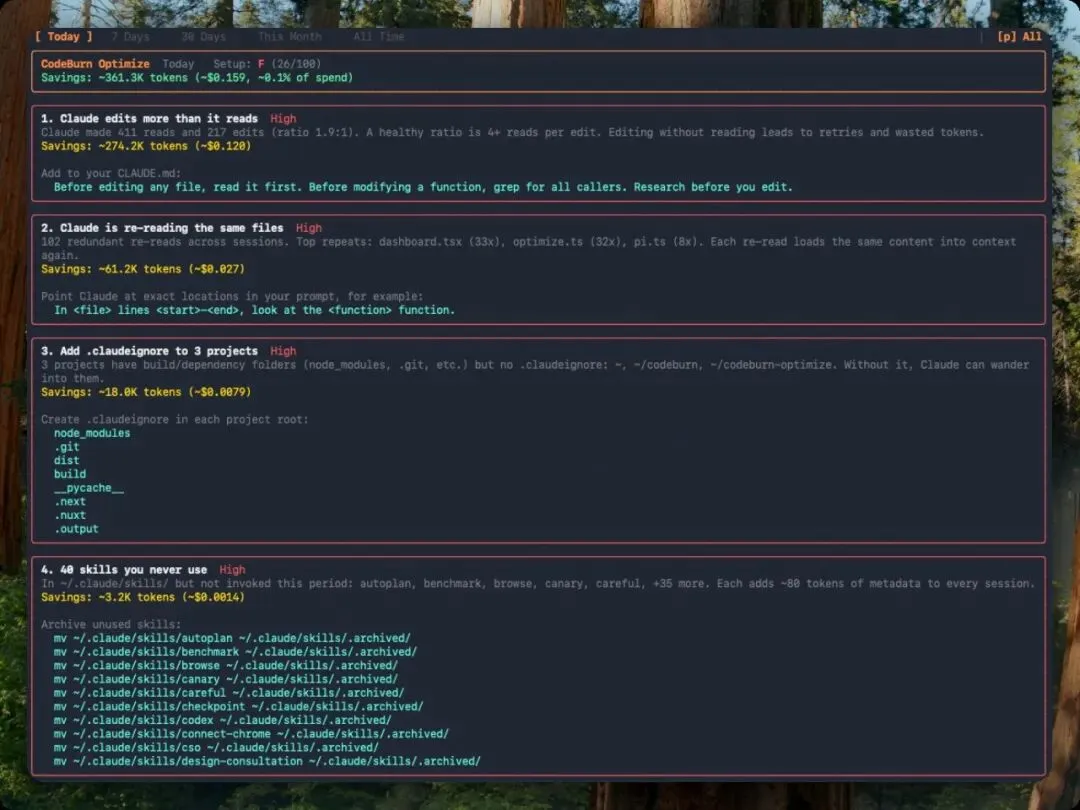
它不只是展示数据,而是扫描你的 session 和 ~/.claude/ 配置,找出 11 种常见的 token 浪费模式,每条发现都附带可以直接复制粘贴的修复建议:
-
重复文件读取:同一个文件在多个 session 里反复读,每次都要消耗 input token -
垃圾目录读取:AI 在读 node_modules/、.git/、dist/等生成目录 -
Read:Edit 比例过低:编辑之前不读文件,导致反复修改 -
未使用的 MCP server:配置了但从没调用过,每次 session 白加载工具 schema -
幽灵 agent/skill/命令:定义了但从未使用,每次 session 都白白占用 token -
臃肿的 CLAUDE.md:展开 @-import后超过 200 行,每次 API 调用都多付钱 -
bash 输出限制过大:默认 30K 字符的上限,大部分输出 15K 就够了 -
cache 创建开销异常:session warmup 的 cache_creation 中位数超出基线
每条发现标注影响等级(high/medium/low)和预计可节省的 token 数,按紧急程度排序。重复运行还能追踪趋势——同一个问题是持续、改善还是已修复。
最终汇总成一个 A-F 的健康评分,让你一眼看出自己的 AI 编程环境有多”浪费”。
npm install -g codeburn
codeburn
前提是你本机有用过 Claude Code / Codex / Cursor 之类的工具,让 CodeBurn 有 session 数据可读。其他什么都不用配。
codeburn report # 交互式 dashboard
codeburn optimize # 检测浪费模式
codeburn export -f json # 导出 JSON
codeburn status # 一行摘要
codeburn --provider cursor # 只看 Cursor 的数据
macOS 用户还能装一个 SwiftBar 菜单栏插件,实时显示今天的花费。
CodeBurn 5 天内迭代了 8 个大版本,0.7.1 就完成了外部安全审计(原型链污染、文件读取越界、菜单栏注入等问题都修了),209 个测试用例。迭代速度和质量控制都超出预期。
局限也值得说清:只统计本机、Cursor Auto 模式下按 Sonnet 估算价格、Copilot 只记录输出 token 会偏低。多机用户目前只能各看各的。
但我愿意推荐它的理由很简单:npm install -g codeburn 之后就真的能用了。它告诉你钱花在哪、哪些花得不值、以及具体怎么改——这对任何一个月 token 账单超过 50 美元的 AI 编程用户来说,值得花 10 分钟试一下。
如果这篇对你有用,建议点个关注。我会持续把 GitHub 上值得用的 AI 工具拆成「最短上手闭环 + 坑点清单 + 可复用配置」,让你少走弯路。
引用链接
[1]CodeBurn: https://github.com/AgentSeal/codeburn
[2]LiteLLM: https://github.com/BerriAI/litellm