 夜雨聆风
夜雨聆风





DeepSeek-V4 技术报告(附下载)

关注本公众号
赠送最新2000+AI人工智能资料
01
摘要
-报告出品:deepseek
模型概览
DeepSeek-V4系列包含两个MoE语言模型预览版:
V4-Pro:1.6T总参数(激活49B),支持100万token上下文
V4-Flash:284B总参数(激活13B),支持100万token上下文
三大核心创新
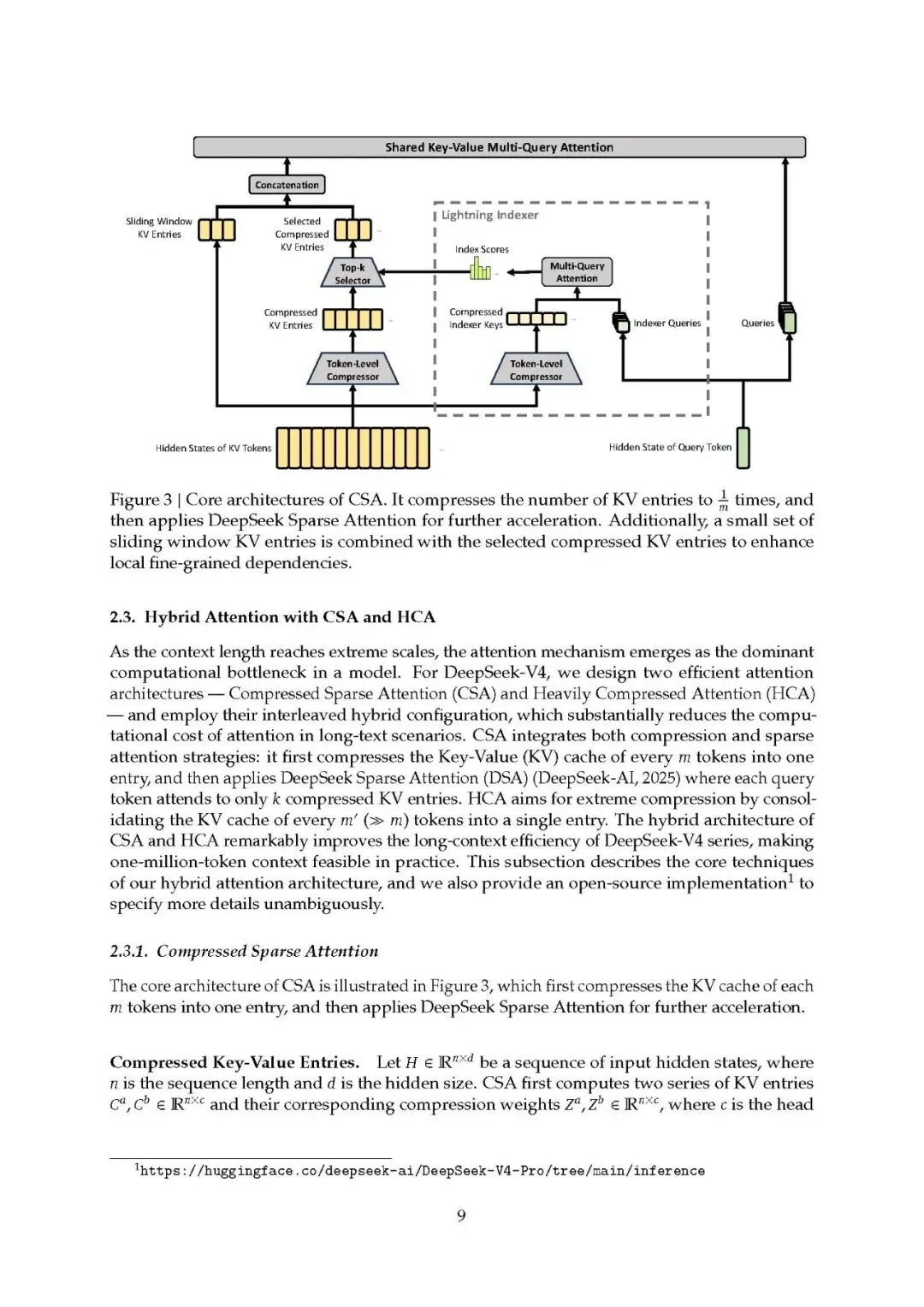
1. 混合注意力架构
CSA(压缩稀疏注意力):每4个token压缩为1个,配合稀疏选择
HCA(高度压缩注意力):每128个token压缩为1个,保持稠密注意力
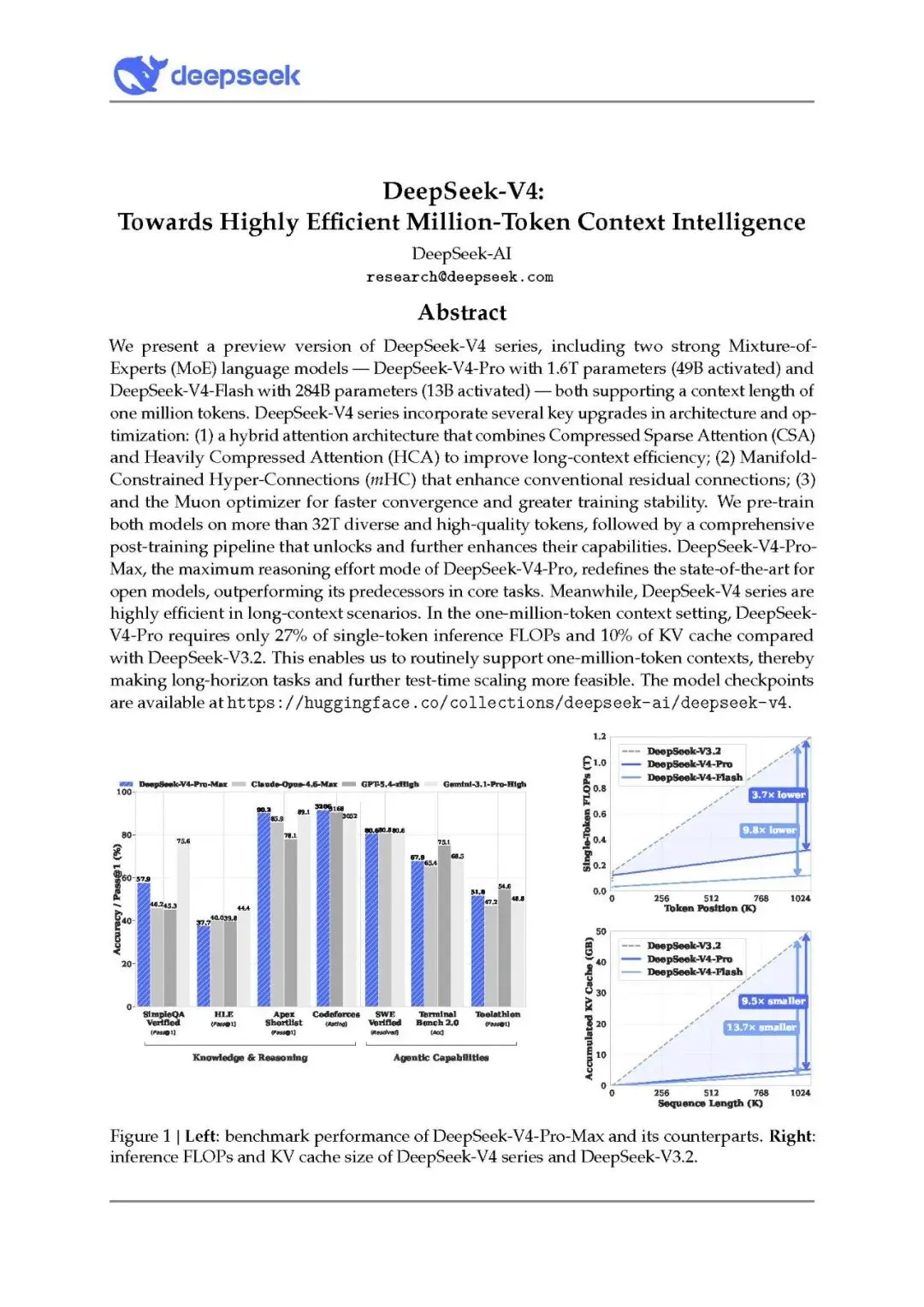
相比V3.2,百万上下文下FLOPs降低73%,KV缓存减少90%
2. Manifold-Constrained Hyper-Connections (mHC)
将残差映射约束到双随机矩阵流形,增强训练稳定性
3. Muon优化器
替代AdamW,实现更快收敛和更稳定训练
训练与性能
预训练数据:32T+ tokens
V4-Pro-Max在知识、推理、代码任务上显著超越现有开源模型
代码竞赛水平达GPT-5.4级别,Codeforces排名前23
正式数学推理(Putnam 2025)实现120/120满分
效率突破
通过FP4量化、TileLang内核、专家并行优化等基础设施创新,实现百万token上下文的实用化部署。
02
引用内容(部分)


















完整PDF报告已上传知识星球,扫描下方图片二维码进入查阅下载

报告研究社让你时刻了解行业现状、市场特征、企业特征、发展环境、竞争格局、发展趋势。
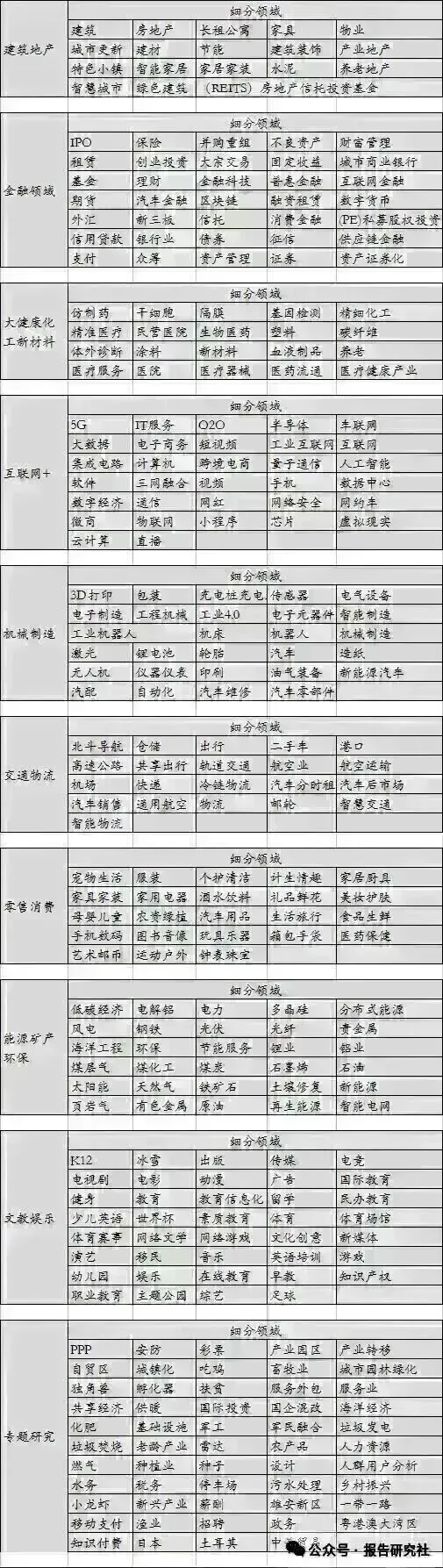
附报告覆盖行业范畴

免责声明:以上报告均系本平台通过公开、合法渠道获得,报告版权归原撰写/发布机构所有,如涉侵权,请联系删除;资料为推荐阅读,仅供参考学习,如对内容存疑,请与原撰写/发布机构联系。