 夜雨聆风
夜雨聆风





ggml 源码剖析(optimizer)
源码剖析
优化器
这一节我们来讲一下优化器,优化器一般在深度学习训练中使用,然而优化器的选择直接影响模型的收敛速度和最终性能。
GGML 优化器是 GGML 库中专门用于模型训练和微调的核心组件。
优化器数据集
ggml_opt_dataset: 数据提供者,负责封装训练/测试数据,在每次迭代时按需向优化器提供输入与目标输出。
ggml-opt.cpp
// GGML 优化器(optimizer)数据集结构体,包含数据集的状态和相关资源,例如计算上下文、数据张量、标签张量等
structggml_opt_dataset {
structggml_context* ctx = nullptr; // 计算上下文,表示用于存储张量和执行计算的上下文,例如模型参数、输入数据等,在优化过程中使用
ggml_backend_buffer_t buf = nullptr; // 后端缓冲区,表示用于存储数据集张量的后端缓冲区,例如在 CPU 上存储数据集张量的缓冲区,在优化过程中使用
structggml_tensor* data = nullptr; // 数据张量,表示存储数据集输入数据的张量,例如训练数据的特征,在优化过程中使用
structggml_tensor* labels = nullptr; // 标签张量,表示存储数据集标签数据的张量,例如训练数据的标签,在优化过程中使用
int64_t ndata = -1; // 数据数量,表示数据集中数据的总数量,例如训练数据的样本数量,在优化过程中使用
int64_t ndata_shard = -1; // 数据分片数量,表示数据集被分成的分片数量,在优化过程中用于分布式训练或批处理
size_t nbs_data = -1; // 数据字节数,表示数据集输入数据张量的字节数,例如训练数据的特征张量的字节数,在优化过程中用于计算内存需求和数据传输等操作
size_t nbs_labels = -1; // 标签字节数,表示数据集标签数据张量的字节数,例如训练数据的标签张量的字节数,在优化过程中用于计算内存需求和数据传输等操作
std::vector<int64_t> permutation; // 数据索引排列,表示数据集中数据的索引排列顺序,例如在训练过程中用于打乱数据的顺序,以提高模型的泛化能力
};ggml_opt_dataset 结构体主要扮演一个“数据提供者”的角色。
开发者需要创建一个实现了特定回调函数的实例,以便在优化过程中,GGML能够通过它来获取训练所需的数据。
在模型训练或微调时,优化器在每次迭代中都需要一组新的输入数据和对应的目标值(标签)来计算损失。
ggml_opt_dataset 正是用于封装这一行为。通过它,GGML 可以保持与数据源的解耦,无论是直接加载到内存的张量,还是按需从文件系统读取的流式数据,都能被统一管理。
优化器上下文
ggml_opt_context: 状态管理核心,贯穿整个优化生命周期,保存优化器参数、当前迭代状态、损失值以及 AdamW / SGD 算法的动量、历史等内部状态。
ggml-opt.cpp
// GGML 优化器(optimizer)上下文,包含优化器的状态和相关资源,例如计算图、张量、随机数生成器等
structggml_opt_context {
ggml_backend_sched_t backend_sched = nullptr; // 后端调度器,负责管理计算资源和调度计算任务
// 分配的计算图,表示已经分配了内存资源的计算图,用于执行前向传播、反向传播和优化步骤
ggml_cgraph * allocated_graph = nullptr;
// 分配的计算图副本,表示已经分配了内存资源的计算图的副本,通常用于在不同的后端上执行相同的计算图,以实现跨设备的计算
ggml_cgraph * allocated_graph_copy = nullptr;
// 静态上下文,表示用于存储静态张量的上下文,例如模型参数等,在优化过程中不会改变
structggml_context* ctx_static = nullptr;
// CPU 上下文,表示用于在 CPU 上执行计算的上下文,通常用于执行前向传播、反向传播和优化步骤
structggml_context* ctx_cpu = nullptr;
// 计算上下文,表示用于执行计算的上下文,通常用于执行前向传播、反向传播和优化步骤,可以是 CPU 上下文或其他后端上下文
structggml_context* ctx_compute = nullptr;
// 计算图副本的上下文,表示用于存储计算图副本的上下文,通常用于在不同的后端上执行相同的计算图,以实现跨设备的计算
structggml_context* ctx_copy = nullptr;
// 静态缓冲区,表示用于存储静态张量的缓冲区,例如模型参数等,在优化过程中不会改变
ggml_backend_buffer_t buf_static = nullptr;
// CPU 缓冲区,表示用于在 CPU 上执行计算的缓冲区,通常用于执行前向传播、反向传播和优化步骤
ggml_backend_buffer_t buf_cpu = nullptr;
// 随机数生成器,表示用于在优化过程中生成随机数的生成器,例如用于数据打乱、参数初始化等
std::mt19937 rng;
// 损失类型,表示用于计算损失的类型,例如平均损失、总损失、交叉熵损失等
enumggml_opt_loss_type loss_type;
// 构建类型,表示当前构建的计算图的类型,例如前向传播、反向传播或优化步骤等
enumggml_opt_build_type build_type;
// 构建分配类型,表示当前正在分配计算图的类型,例如前向传播、反向传播或优化步骤等,用于在分配计算图时区分不同类型的计算图
enumggml_opt_build_type build_type_alloc;
// 输入张量,表示优化器的输入数据,例如训练数据、标签等,在前向传播中使用
structggml_tensor* inputs = nullptr;
// 输出张量,表示优化器的输出数据,例如模型预测、损失值等,在前向传播中使用
structggml_tensor* outputs = nullptr;
// 标签张量,表示优化器的标签数据,例如训练数据的标签,在前向传播中使用
structggml_tensor* labels = nullptr;
// 损失张量,表示计算得到的损失值,在前向传播中使用
structggml_tensor* loss = nullptr;
// 预测张量,表示模型的预测结果,在前向传播中使用
structggml_tensor * pred = nullptr;
// 正确预测数量张量,表示模型的正确预测数量,在前向传播中使用
structggml_tensor * ncorrect = nullptr;
// 前向传播计算图,表示用于执行前向传播的计算图,包含前向传播的操作和张量等信息
structggml_cgraph* gf = nullptr;
// 反向传播计算图,表示用于执行反向传播的计算图,包含反向传播的操作和张量等信息
structggml_cgraph * gb_grad = nullptr;
// 优化步骤计算图,表示用于执行优化步骤的计算图,包含优化操作和张量等信息
structggml_cgraph * gb_opt = nullptr;
// 是否使用静态计算图,表示是否在优化过程中使用静态计算图,即在第一次构建计算图后不再重新构建计算图,而是重复使用同一个计算图进行前向传播、反向传播和优化步骤,以提高效率
bool static_graphs = false;
// 是否准备好评估,表示是否已经准备好进行模型评估,例如在前向传播和反向传播之后,是否已经计算出损失值、预测结果等,可以进行模型评估
bool eval_ready = false;
// 梯度累积器张量,表示用于累积节点梯度的张量,在反向传播过程中用于累积梯度,以便在优化步骤中使用
std::vector<struct ggml_tensor*> grad_accs;
// 梯度张量,表示节点的梯度信息,在反向传播过程中用于计算参数更新
std::vector<struct ggml_tensor*> grad_m;
// 梯度张量,表示节点的梯度信息,在反向传播过程中用于计算参数更新,通常用于 AdamW 优化器中的二阶矩估计
std::vector<struct ggml_tensor*> grad_v;
// 迭代次数,表示优化器已经执行的迭代次数,在优化过程中递增,用于控制训练过程的进度和学习率等参数的调整
int64_t iter = 1;
// 优化周期,表示执行优化步骤的周期,即每隔多少次迭代执行一次优化步骤,例如 opt_period=1 表示每次迭代都执行优化步骤,opt_period=10 表示每 10 次迭代执行一次优化步骤等
int32_t opt_period = 1;
// 优化器索引,表示当前正在执行的优化器的索引,例如在多优化器的情况下,用于区分不同优化器的状态和参数等信息
int32_t opt_i = 0;
// 每个数据点的损失,表示是否计算每个数据点的损失值,而不仅仅是平均损失值,以便在评估模型性能时更详细地分析模型的表现
bool loss_per_datapoint = false;
// 获取优化器参数的函数指针,表示用于获取优化器参数的函数指针,用户可以通过实现该函数来提供优化器所需的参数,例如学习率、权重衰减等,以便在优化步骤中使用
ggml_opt_get_optimizer_params get_opt_pars = nullptr;
// 获取优化器参数的用户数据,表示用于获取优化器参数的函数指针的用户数据,可以在调用函数时传递额外的信息
void * get_opt_pars_ud = nullptr;
// 优化步骤参数张量,表示存储获取优化器参数函数输出的张量,用于在优化步骤中使用,例如存储学习率、权重衰减等参数
structggml_tensor* opt_step_params = nullptr; // Stores output of get_opt_pars.
// 优化器类型,表示当前使用的优化器类型,例如 AdamW、SGD 等,用于在优化步骤中执行相应的优化算法
enumggml_opt_optimizer_type optimizer = GGML_OPT_OPTIMIZER_TYPE_ADAMW;
};ggml_opt_context 结构体是优化器状态管理的核心,负责维持一次特定优化任务的全部状态。
ggml-opt.h
// GGML 优化器损失类型枚举, 用于指定优化器计算损失时使用的损失类型, 包括平均损失、总损失、交叉熵损失和均方误差损失等常见的损失类型
enumggml_opt_loss_type {
GGML_OPT_LOSS_TYPE_MEAN, // 平均损失, 表示将所有数据点的损失值取平均值作为最终的损失值,适用于大多数回归和分类问题的训练
GGML_OPT_LOSS_TYPE_SUM, // 总损失, 表示将所有数据点的损失值求和作为最终的损失值,适用于某些特定的训练场景,例如强化学习中的奖励信号等
GGML_OPT_LOSS_TYPE_CROSS_ENTROPY, // 交叉熵损失, 表示用于分类问题的损失函数,衡量模型预测的概率分布与真实标签分布之间的差异,适用于多分类和二分类问题的训练
GGML_OPT_LOSS_TYPE_MEAN_SQUARED_ERROR, // 均方误差损失, 表示用于回归问题的损失函数,衡量模型预测值与真实值之间的差异,适用于回归问题的训练
};
...
// GGML 优化器构建类型, 用于指定当前构建的计算图的类型
enumggml_opt_build_type {
GGML_OPT_BUILD_TYPE_FORWARD = 10, // 构建前向计算图, 包含模型的前向传播和损失计算
GGML_OPT_BUILD_TYPE_GRAD = 20, // 构建反向计算图, 包含模型的反向传播和梯度计算
GGML_OPT_BUILD_TYPE_OPT = 30, // 构建优化器计算图, 包含模型参数的更新计算
};
// GGML 优化器类型, 用于指定当前使用的优化器类型
enumggml_opt_optimizer_type {
GGML_OPT_OPTIMIZER_TYPE_ADAMW, // 使用 AdamW 优化器, 包含了动量和权重衰减等功能, 适用于大多数深度学习模型的训练
GGML_OPT_OPTIMIZER_TYPE_SGD, // 使用 SGD 优化器, 即随机梯度下降, 是一种简单的优化算法, 适用于一些简单的模型或作为基线比较
GGML_OPT_OPTIMIZER_TYPE_COUNT // 仅用于计数优化器类型的数量, 不表示实际的优化器类型
};
// parameters that control which optimizer is used and how said optimizer tries to find the minimal loss
// GGML 优化器参数结构体, 包含了优化器的超参数和配置, 用于控制优化器的行为和性能
structggml_opt_optimizer_params {
struct {
// 学习率, 控制优化器在每次参数更新时的步长大小, 过大可能导致训练不稳定, 过小可能导致训练收敛缓慢
float alpha; // learning rate
// AdamW 优化器的一阶动量衰减率, 控制了动量的更新速度, 取值范围通常在 [0, 1) 之间, 较大的值会使动量更新更慢, 较小的值会使动量更新更快
float beta1; // first AdamW momentum
// AdamW 优化器的二阶动量衰减率, 控制了动量的更新速度, 取值范围通常在 [0, 1) 之间, 较大的值会使动量更新更慢, 较小的值会使动量更新更快
float beta2; // second AdamW momentum
// 用于数值稳定性的微小值, 防止除零错误
float eps; // epsilon for numerical stability
// 权重衰减, 用于控制模型参数的正则化, 取值范围通常在 [0, 1) 之间, 较大的值会增加正则化效果, 较小的值会减少正则化效果, 设置为 0.0f 可以禁用权重衰减
float wd; // weight decay - 0.0f to disable
} adamw; // AdamW 优化器的超参数, 包含了学习率、动量衰减率、数值稳定性微小值和权重衰减等配置, 用于控制 AdamW 优化器的行为和性能
struct {
// 学习率, 控制优化器在每次参数更新时的步长大小, 过大可能导致训练不稳定, 过小可能导致训练收敛缓慢
float alpha; // learning rate
// 权重衰减, 用于控制模型参数的正则化, 取值范围通常在 [0, 1) 之间, 较大的值会增加正则化效果, 较小的值会减少正则化效果, 设置为 0.0f 可以禁用权重衰减
float wd; // weight decay
} sgd; // SGD 优化器的超参数, 包含了学习率和权重衰减等配置, 用于控制 SGD 优化器的行为和性能
};
...这里还需要了解一个结构体 ggml_opt_params, 定义优化器行为的所有配置,如优化算法类型、迭代次数、学习率、AdamW / SGD 的特定超参数等
ggml-opt.h
// GGML 优化器上下文的参数结构体, 包含了优化器的配置和计算图的相关信息
structggml_opt_params {
// GGML 后端调度器, 用于管理计算资源和调度计算任务, 例如在 CPU 上执行计算、在 GPU 上执行计算等, 通过指定不同的后端调度器可以实现跨设备的计算和优化
ggml_backend_sched_t backend_sched; // defines which backends are used to construct the compute graphs
// by default the forward graph needs to be reconstructed for each eval
// if ctx_compute, inputs, and outputs are set the graphs are instead allocated statically
// GGML 计算上下文, 用于执行计算的上下文, 包含了用于存储张量和执行计算的相关信息, 例如模型参数、输入数据等, 在优化过程中使用
structggml_context* ctx_compute;
structggml_tensor* inputs; // 输入张量, 用于存储模型的输入数据, 例如训练数据、标签等, 在优化过程中使用
structggml_tensor* outputs; // 输出张量, 用于存储模型的输出数据, 例如模型预测、损失值等, 在优化过程中使用
// 优化器损失类型, 用于指定优化器计算损失时使用的损失类型, 包括平均损失、总损失、交叉熵损失和均方误差损失等常见的损失类型, 通过选择不同的损失类型可以适应不同的训练任务和模型需求
enumggml_opt_loss_type loss_type;
// 优化器构建类型, 用于指定优化器在构建计算图时的策略, 包括静态构建和动态构建等选项, 通过选择不同的构建类型可以优化计算性能和资源使用
enumggml_opt_build_type build_type;
// 优化器周期, 定义了执行优化步骤的周期, 即每隔多少次迭代执行一次优化步骤,
// 例如 opt_period=1 表示每次迭代都执行优化步骤, opt_period=10 表示每 10 次迭代执行一次优化步骤等, 通过调整优化周期可以平衡训练效率和模型性能
int32_t opt_period; // after how many gradient accumulation steps an optimizer step should be done
// 计算优化器参数的回调函数, 在每次执行优化步骤之前调用, 用于动态计算优化器的超参数和配置, 例如学习率、动量衰减率等, 通过提供不同的回调函数可以实现自定义的优化器参数计算逻辑
ggml_opt_get_optimizer_params get_opt_pars; // callback for calculating optimizer parameters
// 计算优化器参数的用户数据, 用于在计算优化器参数的回调函数中传递任意数据, 例如当前的训练状态、模型性能指标等, 通过提供不同的用户数据可以实现更灵活的优化器参数计算逻辑
void* get_opt_pars_ud; // userdata for calculating optimizer parameters
// only GGML_OPT_OPTIMIZER_TYPE_ADAMW needs m, v momenta per parameter tensor
// 优化器类型, 用于指定当前使用的优化器类型, 包括 AdamW 和 SGD 等常见的优化器类型, 通过选择不同的优化器类型可以适应不同的训练任务和模型需求
enumggml_opt_optimizer_type optimizer;
};优化器结果
ggml_opt_result: 通常是优化函数的返回值,它携带优化任务的结果信息。
ggml-opt.cpp
// GGML 优化结果结构体,包含优化过程中的结果和相关信息,例如损失值、预测结果、正确预测数量等
structggml_opt_result {
int64_t ndata = 0; // 数据数量,表示优化过程中处理的数据数量,例如训练数据的样本数量,在评估模型性能时使用
std::vector<float> loss; // 损失值,表示优化过程中计算得到的损失值,例如训练过程中的平均损失值,在评估模型性能时使用
std::vector<int32_t> pred; // 预测结果,表示优化过程中模型的预测结果,例如训练过程中的模型预测类别,在评估模型性能时使用
int64_t ncorrect = 0; // 正确预测数量,表示优化过程中模型的正确预测数量,例如训练过程中的模型正确预测的样本数量,在评估模型性能时使用
// 优化周期,表示执行优化步骤的周期,即每隔多少次迭代执行一次优化步骤,例如 opt_period=1 表示每次迭代都执行优化步骤,opt_period=10 表示每 10 次迭代执行一次优化步骤等,在评估模型性能时使用
int64_t opt_period = -1;
// 每个数据点的损失,表示是否计算每个数据点的损失值,而不仅仅是平均损失值,以便在评估模型性能时更详细地分析模型的表现,在评估模型性能时使用
bool loss_per_datapoint = false;
};源码
GGML 优化器提供了一个方便的接口 ggml_opt_fit(),用于训练模型。
它接受模型的计算上下文、输入输出张量、数据集、损失函数类型、优化器类型、优化器参数函数、训练周期数、批次大小等参数,并在内部执行模型的前向传播、损失计算和反向传播等操作,以更新模型的权重和偏置,从而实现模型的训练。
ggml-opt.cpp
//// GGML 优化器的高层接口函数,用于执行模型的训练过程,包括前向传播、反向传播和优化步骤,并在每个epoch结束时调用回调函数来显示训练进度和结果。
voidggml_opt_fit(
ggml_backend_sched_t backend_sched, // 后端调度器,用于管理计算资源和执行计算图。
ggml_context* ctx_compute, // 上下文计算器,用于执行计算图的计算。
ggml_tensor* inputs, // 输入数据的张量,通常是一个二维张量,其中第一维表示特征维度,第二维表示批次大小。
ggml_tensor* outputs, // 输出数据的张量,通常是一个二维张量,其中第一维表示类别数量,第二维表示批次大小。
ggml_opt_dataset_t dataset, // 数据集对象,包含训练数据和标签等信息。
enum ggml_opt_loss_type loss_type, // 损失函数类型,用于计算模型的损失值。
enum ggml_opt_optimizer_type optimizer, // 优化器类型,用于更新模型参数的算法。
ggml_opt_get_optimizer_params get_opt_pars, // 获取优化器参数的函数指针,用于在每个优化步骤中获取当前的优化器参数。
int64_t nepoch, // 训练的epoch数量,即整个训练过程将遍历数据集的次数。
int64_t nbatch_logical, // 逻辑批次大小,即每个epoch中用于训练的批次大小,通常是一个较大的值,可以包含多个物理批次。
float val_split, // 验证集的比例,用于将数据集划分为训练集和验证集,通常是一个介于0和1之间的值。
bool silent){ // 是否静默模式,如果为true,则在训练过程中不显示进度和结果,默认为false。
ggml_time_init();
constint64_t t_start_us = ggml_time_us(); // 记录训练开始的时间,用于计算整个训练过程的耗时。
constint64_t ndata = ggml_opt_dataset_data(dataset)->ne[1]; // 数据集中的数据数量
constint64_t nbatch_physical = inputs->ne[1]; // 输入张量的第二维大小表示每个物理批次的数据数量
GGML_ASSERT(ndata % nbatch_logical == 0); // 数据集中的数据数量应该是逻辑批次大小的整数倍,即每个逻辑批次的数据数量应该能够整除数据集中的数据数量
GGML_ASSERT(nbatch_logical % nbatch_physical == 0); // 逻辑批次大小应该是物理批次大小的整数倍,即每个逻辑批次的数据数量应该能够整除每个物理批次的数据数量
constint64_t opt_period = nbatch_logical / nbatch_physical; // 优化周期,即每隔多少个物理批次进行一次优化步骤,通常是一个较大的值,可以包含多个物理批次。
constint64_t nbatches_logical = ndata / nbatch_logical; // 逻辑批次的数量,即数据集中的数据数量除以逻辑批次大小。
GGML_ASSERT(val_split >= 0.0f); // 验证集的比例应该大于或等于0,即至少有一部分数据用于训练。
GGML_ASSERT(val_split < 1.0f); // 验证集的比例应该小于1,即至少有一部分数据用于验证。
// 计算训练集和验证集的分割索引,即根据验证集的比例将数据集划分为训练集和验证集,ibatch_split表示训练集的最后一个物理批次的索引、idata_split表示训练集的最后一个数据点的索引。
constint64_t ibatch_split = int64_t(((1.0f - val_split) * nbatches_logical)) * opt_period; // train <-> val split index (physical)
constint64_t idata_split = ibatch_split * nbatch_physical;
int64_t epoch = 1; // 当前的epoch索引,从1开始,表示正在训练的epoch的编号。
// 初始化优化器参数,使用默认参数,并根据传入的后端调度器和损失函数类型进行设置。
ggml_opt_params params = ggml_opt_default_params(backend_sched, loss_type);
params.ctx_compute = ctx_compute;
params.inputs = inputs;
params.outputs = outputs;
params.opt_period = opt_period;
params.get_opt_pars = get_opt_pars;
params.get_opt_pars_ud = &epoch;
params.optimizer = optimizer;
ggml_opt_context_t opt_ctx = ggml_opt_init(params); // 初始化优化器上下文,创建一个新的优化器上下文对象,并根据传入的参数进行设置和构建计算图。
// Shuffling the data is generally useful but there is only a point if not all data is used in a single batch.
// 如果逻辑批次大小小于数据集中的数据数量,则对数据集进行洗牌,以增加训练的随机性和泛化能力。
if (nbatch_logical < ndata) {
// 洗牌数据集,打乱数据的顺序,以增加训练的随机性和泛化能力。
ggml_opt_dataset_shuffle(opt_ctx, dataset, -1); // Shuffle all data (train + validation).
}
ggml_opt_result_t result_train = ggml_opt_result_init(); // 初始化训练结果对象,用于存储训练过程中的损失值、预测结果和正确分类数量等信息。
ggml_opt_result_t result_val = ggml_opt_result_init(); // 初始化验证结果对象,用于存储验证过程中的损失值、预测结果和正确分类数量等信息。
// 定义一个epoch回调函数,如果silent参数为true,则不使用回调函数,否则使用ggml_opt_epoch_callback_progress_bar函数来显示训练进度和结果。
ggml_opt_epoch_callback epoch_callback = silent ? nullptr : ggml_opt_epoch_callback_progress_bar;
// 训练循环:从当前的epoch索引开始,直到指定的epoch数量(nepoch)。
// 在每个epoch中,首先检查逻辑批次大小是否小于数据集中的数据数量,如果是,则对数据集进行洗牌。
// 然后,重置训练结果和验证结果对象,以准备存储当前epoch的结果。
// 接下来,如果不是静默模式,则打印当前epoch的编号。
// 最后,调用ggml_opt_epoch函数来执行当前epoch的训练和验证过程,并传递相应的回调函数来显示训练进度和结果。
for (; epoch <= nepoch; ++epoch) {
if (nbatch_logical < idata_split) {
ggml_opt_dataset_shuffle(opt_ctx, dataset, idata_split);
}
ggml_opt_result_reset(result_train); // 重置训练结果对象,以准备存储当前epoch的结果。
ggml_opt_result_reset(result_val); // 重置验证结果对象,以准备存储当前epoch的结果。
if (!silent) {
fprintf(stderr, "%s: epoch %04" PRId64 "/%04" PRId64 ":\n", __func__, epoch, nepoch);
}
// 执行当前epoch的训练和验证过程,并传递相应的回调函数来显示训练进度和结果。
ggml_opt_epoch(opt_ctx, dataset, result_train, result_val, idata_split, epoch_callback, epoch_callback);
if (!silent) {
fprintf(stderr, "\n");
}
}
// 计算整个训练过程的耗时,并根据是否静默模式来决定是否打印训练耗时的信息。
if (!silent) {
int64_t t_total_s = (ggml_time_us() - t_start_us) / 1000000;
constint64_t t_total_h = t_total_s / 3600;
t_total_s -= t_total_h * 3600;
constint64_t t_total_m = t_total_s / 60;
t_total_s -= t_total_m * 60;
fprintf(stderr, "%s: training took %02" PRId64 ":%02" PRId64 ":%02" PRId64 "\n", __func__, t_total_h, t_total_m, t_total_s);
}
ggml_opt_free(opt_ctx); // 释放优化器上下文,清理相关资源。
ggml_opt_result_free(result_train); // 释放训练结果对象,清理相关资源。
ggml_opt_result_free(result_val); // 释放验证结果对象,清理相关资源。
}
...
// 进行一个训练周期的优化过程,包括训练阶段和评估阶段。
// 在训练阶段,使用训练集的数据进行前向传播、反向传播和优化步骤,并在每个批次结束时调用回调函数来报告训练状态。
// 在评估阶段,使用评估集的数据进行前向传播,并在每个批次结束时调用回调函数来报告评估状态。
voidggml_opt_epoch(
ggml_opt_context_t opt_ctx, // 优化器上下文,包含优化器状态和计算图等信息。
ggml_opt_dataset_t dataset, // 数据集,包含训练数据和评估数据等信息。
ggml_opt_result_t result_train, // 训练结果,包含训练过程中计算的损失值、预测结果和正确分类数量等信息。
ggml_opt_result_t result_eval, // 评估结果,包含评估过程中计算的损失值、预测结果和正确分类数量等信息。
int64_t idata_split, // 训练集和评估集的划分点,表示使用前idata_split个数据进行训练,剩余的数据进行评估。如果idata_split小于0,则使用整个数据集进行训练。
ggml_opt_epoch_callback callback_train, // 训练回调函数,在每个训练批次结束时调用,用于报告训练状态和结果。
ggml_opt_epoch_callback callback_eval){ // 评估回调函数,在每个评估批次结束时调用,用于报告评估状态和结果。
GGML_ASSERT(ggml_opt_static_graphs(opt_ctx) && "ggml_opt_epoch requires static graphs");
structggml_tensor* inputs = ggml_opt_inputs(opt_ctx); // 输入数据的张量
structggml_tensor* labels = ggml_opt_labels(opt_ctx); // 标签数据的张量
structggml_tensor* data = ggml_opt_dataset_data(dataset); // 数据集中的数据张量
GGML_ASSERT(data->ne[0] == inputs->ne[0]); // 数据集中的数据数量应该与输入张量的第一维大小相同
constint64_t ndata = data->ne[1]; // 数据集中的数据数量
constint64_t ndata_batch = inputs->ne[1]; // 输入张量的第二维大小表示每个批次的数据数量
GGML_ASSERT(data->ne[1] % inputs->ne[1] == 0); // 数据集中的数据数量应该是输入张量的第二维大小的整数倍,即每个批次的数据数量应该能够整除数据集中的数据数量
constint64_t nbatches = ndata / ndata_batch; // 计算总的批次数量,即数据集中的数据数量除以每个批次的数据数量
idata_split = idata_split < 0 ? ndata : idata_split; // 如果idata_split小于0,则将其设置为ndata,即使用整个数据集进行训练
GGML_ASSERT(idata_split % ndata_batch == 0);
constint64_t ibatch_split = idata_split / ndata_batch; // 计算训练集的批次数量,即idata_split除以每个批次的数据数量
int64_t ibatch = 0; // 批次索引,从0开始,直到总的批次数量(nbatches)。
int64_t t_loop_start = ggml_time_us();
// 训练阶段:从第0批次开始,直到训练集的批次数量(ibatch_split)。
// 在每个批次中,首先调用ggml_opt_alloc函数进行内存分配,然后调用ggml_opt_dataset_get_batch函数获取当前批次的输入数据和标签数据,并将它们存储在inputs和labels张量中。
// 接下来,调用ggml_opt_eval函数执行前向传播、反向传播和优化步骤,并将结果存储在result_train中。
// 如果提供了callback_train回调函数,则在每个批次结束时调用该函数,传递当前的训练状态、优化器上下文、数据集、训练结果以及当前批次的索引和总批次数量等信息。
for (; ibatch < ibatch_split; ++ibatch) {
ggml_opt_alloc(opt_ctx, /*backward =*/true); // 内存分配,准备计算图进行前向传播、反向传播和优化步骤。
ggml_opt_dataset_get_batch(dataset, inputs, labels, ibatch); // 获取当前批次的输入数据和标签数据,并将它们存储在inputs和labels张量中。
ggml_opt_eval(opt_ctx, result_train); // 执行前向传播、反向传播和优化步骤,并将结果存储在result_train中。
if (callback_train) {
callback_train(true, opt_ctx, dataset, result_train, ibatch+1, ibatch_split, t_loop_start);
}
}
t_loop_start = ggml_time_us();
// 评估阶段:从训练集的批次数量(ibatch_split)开始,直到总的批次数量(nbatches)。
// 在每个批次中,首先调用ggml_opt_alloc函数进行内存分配,然后调用ggml_opt_dataset_get_batch函数获取当前批次的输入数据和标签数据,并将它们存储在inputs和labels张量中。
// 接下来,调用ggml_opt_eval函数执行前向传播步骤,并将结果存储在result_eval中。
// 如果提供了callback_eval回调函数,则在每个批次结束时调用该函数,传递当前的评估状态、优化器上下文、数据集、评估结果以及当前批次的索引和总批次数量等信息。
for (; ibatch < nbatches; ++ibatch) {
ggml_opt_alloc(opt_ctx, /*backward =*/false); // 内存分配,准备计算图进行前向传播步骤。
ggml_opt_dataset_get_batch(dataset, inputs, labels, ibatch); // 获取当前批次的输入数据和标签数据,并将它们存储在inputs和labels张量中。
ggml_opt_eval(opt_ctx, result_eval); // 执行前向传播步骤,并将结果存储在result_eval中。
// 如果提供了callback_eval回调函数,则在每个批次结束时调用该函数,传递当前的评估状态、优化器上下文、数据集、评估结果以及当前批次的索引和总批次数量等信息。
if (callback_eval) {
callback_eval(false, opt_ctx, dataset, result_eval, ibatch+1-ibatch_split, nbatches-ibatch_split, t_loop_start);
}
}
}
...
// 执行计算图,进行前向传播、反向传播和优化步骤。
voidggml_opt_eval(ggml_opt_context_t opt_ctx, ggml_opt_result_t result){
GGML_ASSERT(opt_ctx->eval_ready);// 断言:必须先调用 ggml_opt_alloc 来准备计算图和分配内存,然后才能调用 ggml_opt_eval 来执行计算。
// 如果当前分配的计算图是优化图(gb_opt),则需要更新优化器参数。
if (opt_ctx->allocated_graph == opt_ctx->gb_opt) {
// 获取优化器参数,并进行断言检查,确保参数的合理性。
const ggml_opt_optimizer_params & opt_pars = opt_ctx->get_opt_pars(opt_ctx->get_opt_pars_ud);
switch (opt_ctx->optimizer) {
case GGML_OPT_OPTIMIZER_TYPE_ADAMW: { // 如果使用 AdamW 优化器,则需要检查并设置 AdamW 的相关参数。
GGML_ASSERT(opt_pars.adamw.alpha > 0.0f);
GGML_ASSERT(opt_pars.adamw.beta1 >= 0.0f);
GGML_ASSERT(opt_pars.adamw.beta1 <= 1.0f);
GGML_ASSERT(opt_pars.adamw.beta2 >= 0.0f);
GGML_ASSERT(opt_pars.adamw.beta2 <= 1.0f);
GGML_ASSERT(opt_pars.adamw.eps >= 0.0f);
GGML_ASSERT(opt_pars.adamw.wd >= 0.0f);
GGML_ASSERT(opt_pars.adamw.wd <= 1.0f);
// beta1, beta2 after applying warmup
constfloat beta1h = 1.0f / (1.0f - powf(opt_pars.adamw.beta1, opt_ctx->iter));
constfloat beta2h = 1.0f / (1.0f - powf(opt_pars.adamw.beta2, opt_ctx->iter));
float * adamw_par_data = ggml_get_data_f32(opt_ctx->opt_step_params);
adamw_par_data[0] = opt_pars.adamw.alpha;
adamw_par_data[1] = opt_pars.adamw.beta1;
adamw_par_data[2] = opt_pars.adamw.beta2;
adamw_par_data[3] = opt_pars.adamw.eps;
adamw_par_data[4] = opt_pars.adamw.wd;
adamw_par_data[5] = beta1h;
adamw_par_data[6] = beta2h;
} break;
case GGML_OPT_OPTIMIZER_TYPE_SGD: { // 如果使用 SGD 优化器,则需要检查并设置 SGD 的相关参数。
GGML_ASSERT(opt_pars.sgd.alpha > 0.0f);
GGML_ASSERT(opt_pars.sgd.wd >= 0.0f);
GGML_ASSERT(opt_pars.sgd.wd <= 1.0f);
float * sgd = ggml_get_data_f32(opt_ctx->opt_step_params);
sgd[0] = opt_pars.sgd.alpha;
sgd[1] = opt_pars.sgd.wd;
} break;
default:
GGML_ABORT("fatal error");
}
}
// 调用 ggml_backend_sched_graph_compute 来执行当前分配的计算图,并根据计算结果更新优化器状态和结果。
ggml_backend_sched_graph_compute(opt_ctx->backend_sched, opt_ctx->allocated_graph_copy);
opt_ctx->iter += opt_ctx->allocated_graph == opt_ctx->gb_opt;
opt_ctx->opt_i = (opt_ctx->opt_i + 1) % opt_ctx->opt_period;
// 优化器上下文中的 gf 是前向传播图,gb_grad 是反向传播图,gb_opt 是优化器图。
// allocated_graph 是当前分配的计算图,allocated_graph_copy 是当前分配的计算图的副本。
if (!opt_ctx->static_graphs) {
opt_ctx->gf = nullptr;
opt_ctx->gb_grad = nullptr;
opt_ctx->gb_opt = nullptr;
opt_ctx->allocated_graph = nullptr;
opt_ctx->allocated_graph_copy = nullptr;
}
opt_ctx->eval_ready = false;
// 如果 result 不为 nullptr,则根据计算结果更新 result 中的损失值、预测结果和正确分类数量等信息。
if (!result) {
return;
}
// 如果 result 中的数据数量为0,则将损失值是否按数据点计算和优化周期等信息从 opt_ctx 中复制到 result 中;否则,断言这些信息与 opt_ctx 中的一致。
if (result->ndata == 0) {
result->loss_per_datapoint = opt_ctx->loss_per_datapoint;
result->opt_period = opt_ctx->opt_period;
} else {
GGML_ASSERT(result->loss_per_datapoint == opt_ctx->loss_per_datapoint);
GGML_ASSERT(result->opt_period == opt_ctx->opt_period);
}
// 根据计算结果更新 result 中的数据数量、损失值、预测结果和正确分类数量等信息。
// 具体来说,首先获取当前批次的数据数量,并将其累加到 result 中的数据数量中;
// 然后获取当前批次的损失值,并将其添加到 result 中的损失值列表中;
// 如果存在预测结果,则将其添加到 result 中的预测结果列表中;
// 如果存在正确分类数量,则将其累加到 result 中的正确分类数量中。
constint64_t ndata = opt_ctx->outputs->ne[1];
GGML_ASSERT(result->ndata == ndata*int64_t(result->loss.size()) && "varying batch size not supported");
result->ndata += ndata;
GGML_ASSERT(ggml_is_scalar(opt_ctx->loss)); // 断言:损失值应该是一个标量,即一个单独的数值,而不是一个向量或矩阵。
GGML_ASSERT(opt_ctx->loss->type == GGML_TYPE_F32);
float loss;
// 从 opt_ctx 中获取当前批次的损失值,并将其添加到 result 中的损失值列表中。
ggml_backend_tensor_get(opt_ctx->loss, &loss, 0, ggml_nbytes(opt_ctx->loss));
result->loss.push_back(loss);
// 如果存在预测结果,则将其添加到 result 中的预测结果列表中。
if (opt_ctx->pred) {
GGML_ASSERT(opt_ctx->pred->type == GGML_TYPE_I32);
std::vector<int32_t> pred(ndata);
// 从 opt_ctx 中获取当前批次的预测结果,并将其添加到 result 中的预测结果列表中。
ggml_backend_tensor_get(opt_ctx->pred, pred.data(), 0, ggml_nbytes(opt_ctx->pred));
result->pred.insert(result->pred.end(), pred.begin(), pred.end());
}
// 如果存在正确分类数量,则将其累加到 result 中的正确分类数量中。
if (!opt_ctx->ncorrect || result->ncorrect < 0) {
result->ncorrect = -1;
return;
}
GGML_ASSERT(ggml_is_scalar(opt_ctx->ncorrect)); // 断言:正确分类数量应该是一个标量,即一个单独的数值,而不是一个向量或矩阵。
GGML_ASSERT(opt_ctx->ncorrect->type == GGML_TYPE_I64);
int64_t ncorrect;
// 从 opt_ctx 中获取当前批次的正确分类数量,并将其累加到 result 中的正确分类数量中。
ggml_backend_tensor_get(opt_ctx->ncorrect, &ncorrect, 0, ggml_nbytes(opt_ctx->ncorrect));
result->ncorrect += ncorrect;
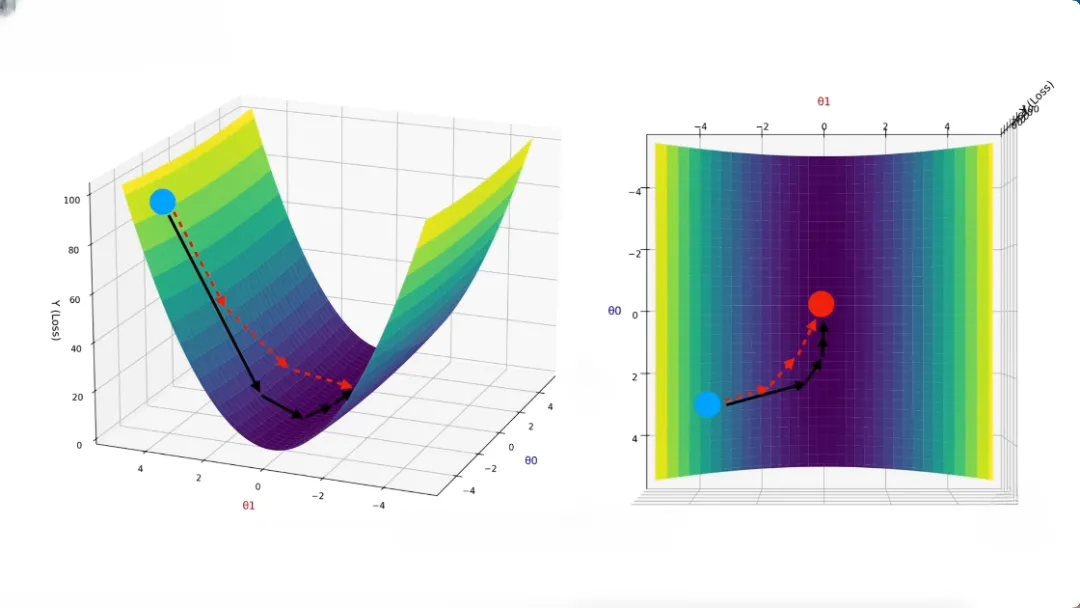
}为了方便理解,这里画出来函数调用流程图:
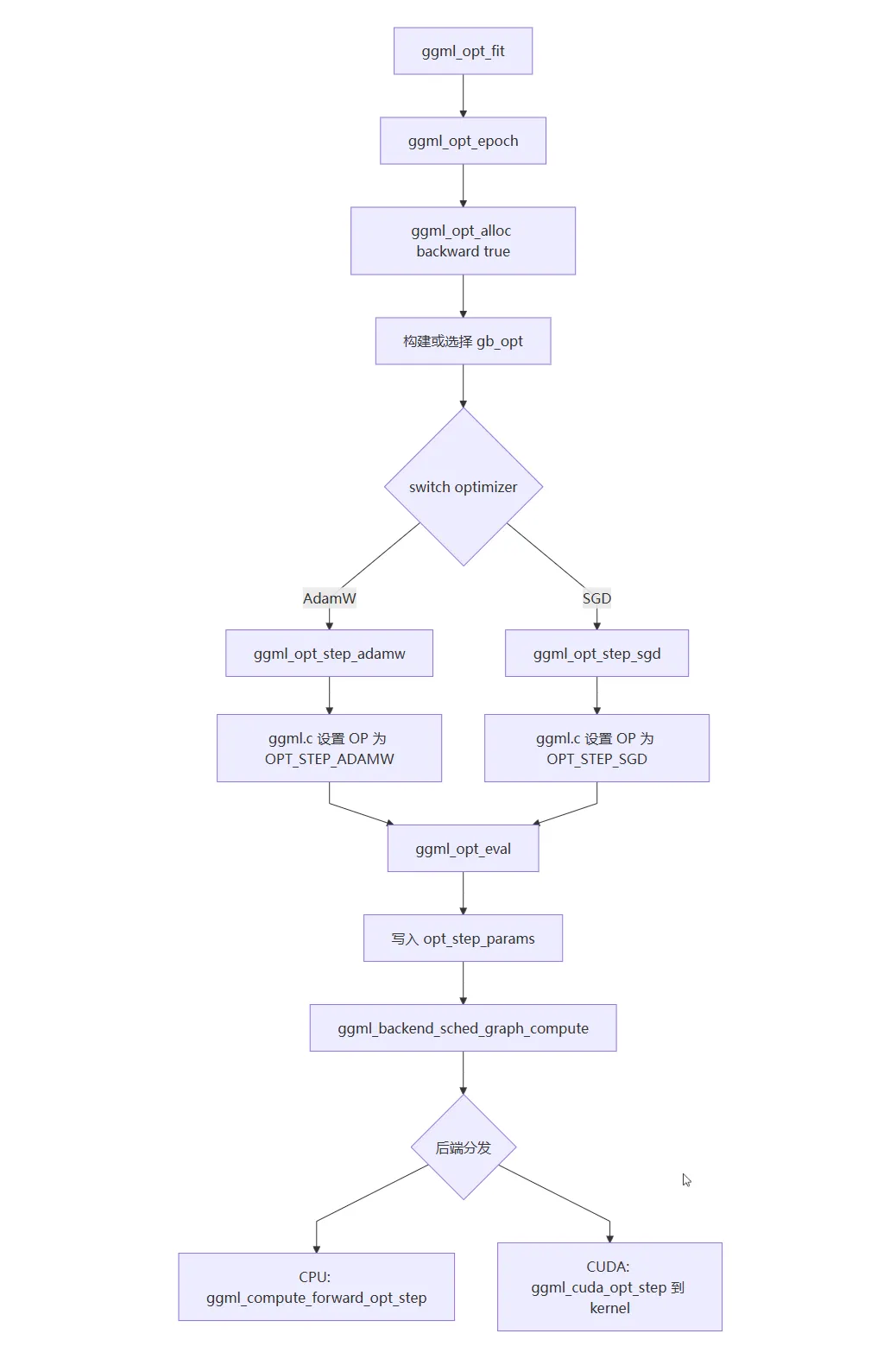
至此我们先关注到 ggml_backend_sched_graph_compute(...) 函数的调用,后续在向下分析后端代码。
算法
根据上述代码,可以了解到优化器的两个核心算法:
-
• SGD:Stochastic Gradient Descent(随机梯度下降) -
• AdamW:Adaptive Moment Estimation with Decoupled Weight Decay(自适应矩估计与解耦权重衰减)
在实际中 AdamW 则是近年来在大型模型(尤其是 Transformer 类架构)中占据主导地位的自适应优化器,但 SGD 是经典,是深度学习道路中必经之路。
这里我花一些时间,讲一下 SGD 如何 一步一步进化到 AdamW 的。
SGD
先从梯度下降讲起,梯度下降(Gradient Descent)本质上是迭代法的一种,可以用于求解最小二乘法(线性和非线性都可以)。
在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一。
在求解损失函数的最小值时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数和模型参数值。
反过来,如果我们需要求解损失函数的最大值,这时就需要用梯度上升法来迭代了。
梯度下降的本质:是一种使用梯度去迭代更新权重参数使目标函数最小化的方法。
这里经典有直观的例子,就是下山问题:
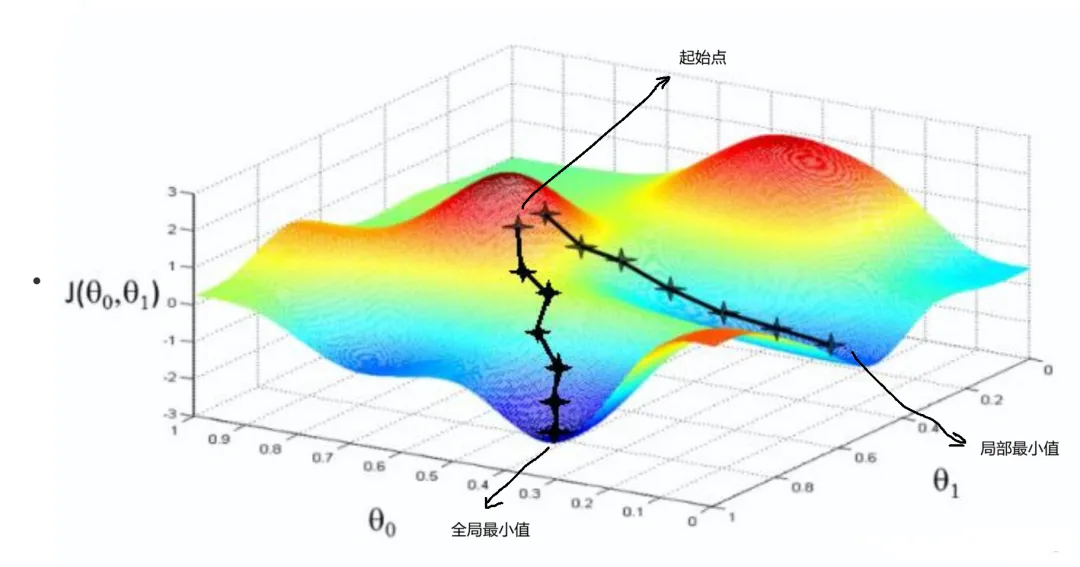
比如我们在一座大山上的某处位置,由于我们不知道怎么下山,于是决定走一步算一步,也就是在每走到一个位置的时候,求解当前位置的梯度,沿着梯度的负方向,也就是当前最陡峭的位置向下走一步,然后继续求解当前位置梯度,向这一步所在位置沿着最陡峭最易下山的位置走一步。
这样一步步的走下去,一直走到觉得我们已经到了山脚。当然这样走下去,有可能我们不能走到山脚,而是到了某一个局部的山峰低处。
从上面的解释可以看出,梯度下降不一定能够找到全局的最优解,有可能是一个局部最优解。
当然,如果损失函数是凸函数,梯度下降法得到的解就一定是全局最优解。
原理懂了,我们开始从最简单的梯度下降开始:
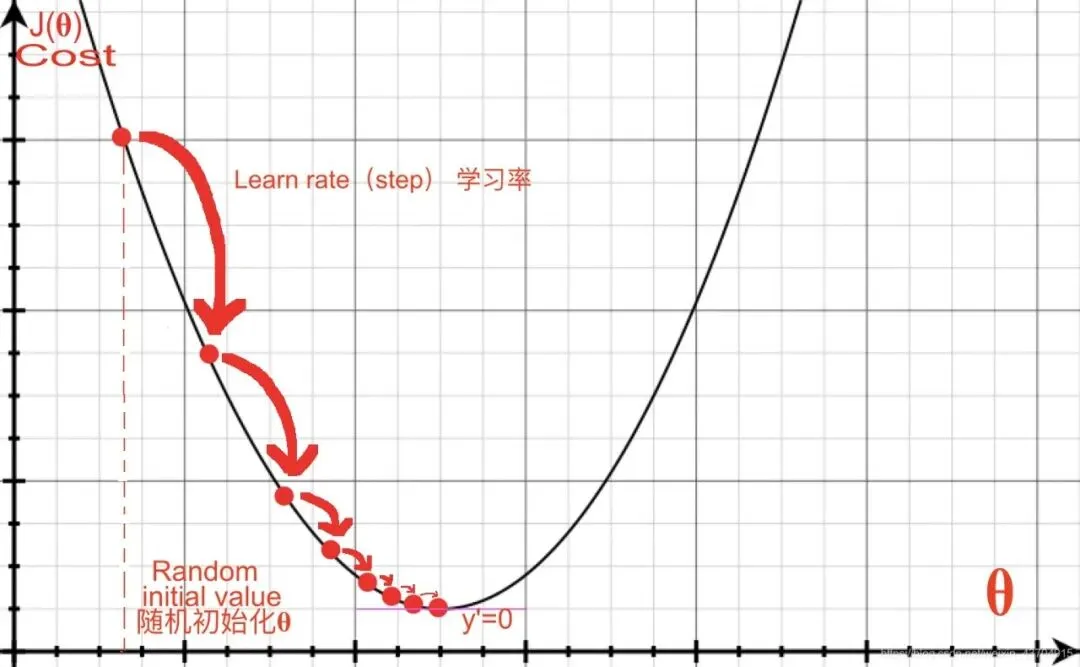
一个极简的凸函数,我们随机初始化 , 最基本的随机梯度下降每次迭代用一个小批量(mini-batch)的梯度来更新参数:
其中 是第 步的模型参数, 是学习率, 是损失函数关于参数的梯度。最终可得出 SGD 公式:
-
• :当前参数 -
• :学习率(步长) -
• :通过求导得到的梯度
假设损失函数是均方误差 :
这里 是参数向量, 是特征向量, 是标签,常见做法,用 1/2 为了消除梯度中的2。
一元函数进行求导数,如果是多元函数即求偏导数即可,得出梯度:
将梯度代入 SGD公式:
当然,其还涉及到梯度爆炸、梯度震荡、梯度消失、学习率过小导致无法收敛等情况,因此通常需要调优参数来解决相应的问题 。
SGD with Momentum
为了更好的理解,我们假设损失函数是一个碗状,下面是它的俯视图和顶视图。
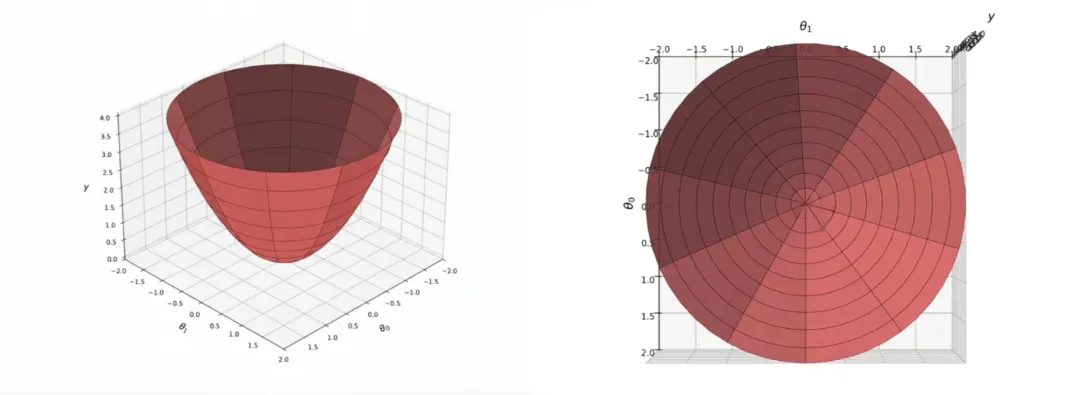
在实际情况下,由于数据的差异性,做梯度下降可能是下面的情况:
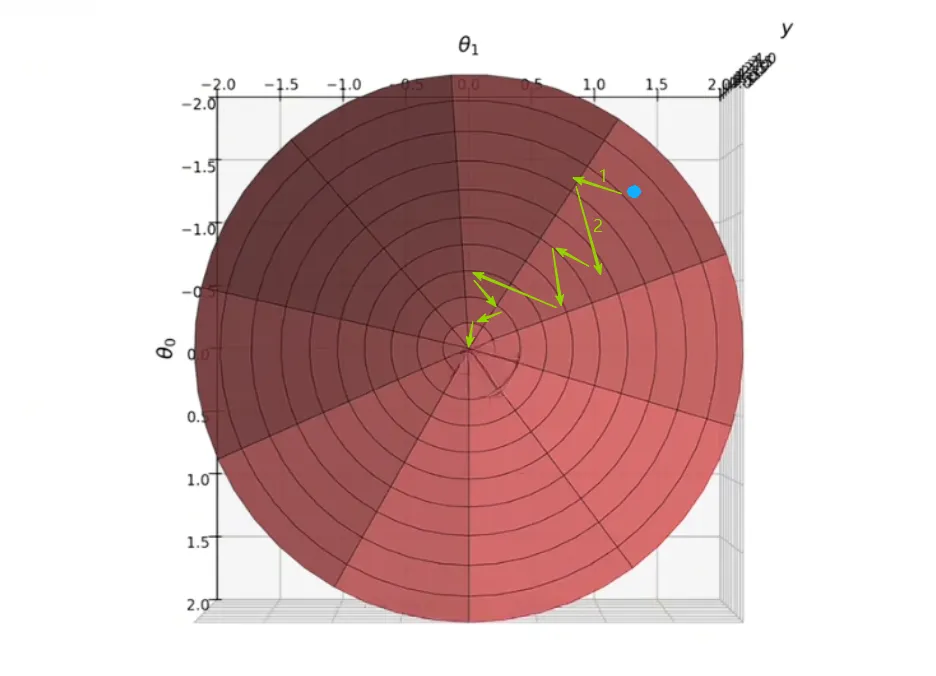
那么如果可以讲震荡相互抵消一下,而冲向最小值的速度就会加快,从而减少了计算次数抵达最优解。
以向量1、2为例,如果我们在移动向量2的时候,移动的是向量1+2的和,震荡便抵消了很多,每一次迭代还会向前移动,这样是不是又快又稳。
那么这一步加速的过程便称为动量(Momentum),因此便有了SGD with Momentum。
为加速收敛并抑制震荡,引入动量项,让更新方向不仅依赖当前梯度,还融合历史更新方向:
-
• :动量系数(常用 0.9) -
• :学习率 -
• :累积的速度(动量) -
• :当前参数 处的梯度
RMSprop
继续思考问题,如果学习率始终是固定的话,梯度下降时,当快到达最小值时,会有些弊端,容易冲过最小值导致梯度震荡。
为了更好理解,我们再次更换损失函数形状来理解该问题:
在图中可以看出纵向坡度较大而横向坡度较缓的情况下,使用同样的学习率:
-
• 纵向由于梯度较大在乘以学习率后容易冲过头 -
• 横向由于梯度较小在乘以学习率后步子便更小,导致停止不前
图中黑色先时 SGD with Momentum 的实现,而红色先是期望实现的效果,便是 RMSprop。
那么我们应该如何动态改变学习率?
RMSprop(Root Mean Square Propagation)通过自适应调整每个参数的学习率,有效处理非平稳目标与稀疏梯度。
它维护梯度平方的指数移动平均,然后按逐参数缩放的学习率进行更新。
-
• :当前参数 处的梯度 -
• :梯度平方的指数移动平均(其平方根称为RMS,故得名 RMSprop) -
• :衰减率(典型值 0.9) -
• :学习率 -
• :防止除零的小常数(如 )
Adam
Adam 的全称是 Adaptive Moment Estimation(自适应矩估计)。
那么 Adam 就是既要又要的思想,将 SGD with Momentum 和 RMSprop 相结合,最终成为深度学习优化器集大成者。
Adam 将动量(一阶矩)和 RMSProp(二阶矩)结合在一起,并对偏差进行校正:
-
• :当前参数 处的梯度 -
• ,:为衰减率(通常 , ) -
• :防止除零的小常数(如 ) -
• :学习率
AdamW
AdamW 的全称是 Adaptive Moment Estimation with Decoupled Weight Decay(自适应矩估计与解耦权重衰减)。
-
• Adam 来自 Adaptive Moment Estimation(自适应矩估计), -
• W 代表 Weight Decay(权重衰减)
合在一起强调将权重衰减从梯度更新中解耦出来的设计,将 Adam 再次进化的结果:
其中 是权重衰减系数。
注意:有时也写作先做权重衰减:,再用Adam更新。本质上等价。
至此,讲述了优化器的进化史,希望对你有所帮助,可以更好了解它,应用它~