 夜雨聆风
夜雨聆风





OpenClaw 插件 SmartContext 开发解析(上篇):从用户痛点到对话导航系统的设计决策
在专业对话中,LLM 有一个容易被忽视的问题:它不缺知识,缺的是判断“什么重要”的能力。
这不是模型能力的问题。DeepSeek、Kimi、GPT、Claude 在面对一个长达数万字的对话历史时,依然会把用户随口说的一句“这个方案好像也行”和架构决策“数据库必须使用 PostgreSQL”放在同等位置。模型的设计目标是“关注所有内容”,但这恰恰是专业对话的灾难。
SmartContext 这个插件的设计起点,就是这个真实困境。
01
—
痛点:专业对话中的“信息平权”
我们观察到的现象很简单:在一个涉及多轮讨论、多领域交叉的对话中,LLM 会平等对待每一条信息。
用户说“我们决定采用微服务架构”,模型记住了。用户又说“这个接口命名改成驼峰吧”,模型也记住了。当上下文窗口被塞满时,模型不知道应该优先保留哪一条。它没有“架构决策比命名规范重要”这个概念。
这不是模型的错。Prompt 里没有告诉它。上下文管理机制(无论是 OpenClaw 还是其他框架)只负责“怎么存”和“怎么压缩”,不负责“什么值得存”。
这个空白,就是 SmartContext 要填补的位置。
—
错误尝试:我们一开始想的都是错的
在确定最终方案之前,我们考虑过几条路径,后来都被否决了。
第一条:让模型自己判断重要性。在 Prompt 里写“请重点关注用户的核心需求”。结果可想而知——模型对“核心需求”的理解和用户完全不同。这种模糊指令等同于没有指令。
第二条:做更智能的上下文压缩。按语义相似度聚类,保留代表性的片段。但问题在于:压缩是事后行为,信息已经丢失了。而且压缩算法无法理解“架构决策”和“闲聊”在业务语义上的天壤之别。
第三条:自动检测当前对话领域,动态加载规则。听起来很智能,但我们放弃了。原因很简单:引入 LLM 做领域判断,意味着每次对话多一次推理调用,且判断可能出错。用户无法确定当前哪些规则在生效,这是不可接受的。
这些错误尝试让我们意识到一件事:导航不是让模型更聪明,而是给它一个明确、稳定、可预期的判断框架。
03
—
核心洞察:什么是“对话导航系统”
SmartContext 的定位,从一开始就与“记忆管理”划清了界限。
OpenClaw 负责上下文存储、压缩、持久化。SmartContext 不碰这些。它只做一件事:在每次构建 Prompt 之前,注入一套分级的、领域特定的重要性准则。
这套准则不是告诉模型“应该关注什么”,而是告诉模型“当你在不同层级的信息之间做取舍时,按这个顺序来”。它是一个排序规则,而不是一个内容补充。
我们把这种机制称为“对话导航系统”。它不改变模型的推理能力,不增加模型的“知识”,它只改变模型对已有信息的注意力分配。
这个定位的确立,决定了后续所有的架构选择。
04
—
架构决策:为什么选择 before_prompt_build
OpenClaw 插件 SDK 提供了多个扩展点。其中有两个看起来都可用于注入上下文准则:registerMemoryPromptSection和 before_prompt_build。
第一个是专门为 memory 类插件设计的,它会在 memory 插槽中注入内容。如果 SmartContext 使用这个钩子,就会和 memory-core 等插件争抢同一个位置。用户只能二选一,或者承受不可预知的覆盖行为。
第二个钩子 before_prompt_build在 OpenClaw 构建完整 Prompt 之前触发,返回的内容会被前置到系统提示词开头。它不与任何 memory 插槽冲突,可以和 memory-core 共存。
我们选择了后者。这是一个典型的“无侵入集成”决策:不抢占资源,不假设自己是唯一重要的插件,只做增量贡献。
另一个关键决策是:准则在每次对话生成时实时构建,而不是预先生成后缓存。这是因为用户的配置(活跃领域、角色标签、手动标记)可能随时通过命令修改。实时生成确保每次 Prompt 都使用最新规则。
05
—
职责边界:不做什么,比做什么更重要
SmartContext 的设计文档中有一张表,清晰地划分了与 OpenClaw 的职责边界:
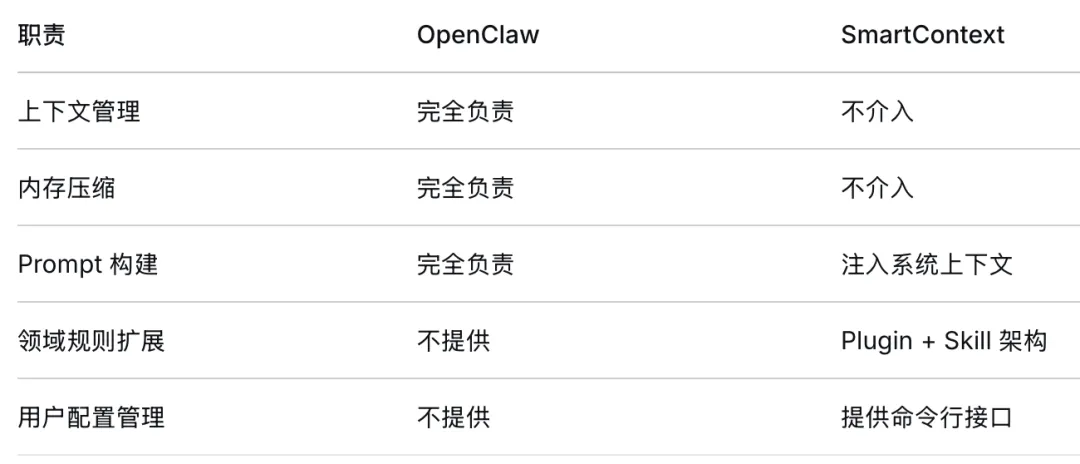
这张表不是形式主义。它反映了我们对“插件”的理解:插件应该做核心系统不做的事,而不是替代核心系统做的事。
如果 SmartContext 试图自己管理上下文、自己做压缩,它就会和 OpenClaw 的未来演进产生冲突。OpenClaw 升级压缩策略,SmartContext 就需要跟着改。这种耦合对双方都没有好处。
所以 SmartContext 的代码里,没有任何一行涉及消息存储、历史截断、token 计数。它只做一件事:生成一段文本,然后交给 OpenClaw。
06
—
小结:从痛点到决策的推导链条
回顾一下这个推导过程:
-
观察到痛点:LLM 在长对话中无法区分信息的重要性层级。
-
排除错误方案:模糊指令、智能压缩、自动检测——都有根本性问题。
-
明确核心定位:做导航系统,不做记忆管理。
-
选择集成点:用
before_prompt_build而非 memory 插槽,避免冲突。 -
划定职责边界:不碰上下文存储和压缩,只注入准则文本。
这个链条中,每一个决策都有明确的“为什么”,而不是“别人怎么做我也怎么做”。
上篇到此为止。我们解决了“应该做什么、不该做什么”的问题。但还有一个更棘手的问题没有回答:如何设计一套规则,让 LLM 真正理解并执行“什么比什么更重要”?
这是中篇要讨论的内容——五层优先级(Tier 0-4)的设计逻辑与规则工程。