 夜雨聆风
夜雨聆风





医学影像AI的"万能插件"? 多数据集蒸馏,一个模型搞定分割、分类、检测

🐉 龙哥读论文知识星球来了!
公众号每日8篇拆解不够看?星球无上限更AI领域论文、资讯、招聘、招博、开源代码,一站式干货,每日2分钟刷完即赚!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~
龙哥推荐理由:
这篇论文的亮点在于,它提出一个非常实用且具有普适性的框架,像一个“万能插件”,把多个来源、不同任务(分割、分类、检测)的知识通过蒸馏集成到一个学生模型里。这对于解决医学影像领域数据稀缺、标注困难、域迁移性差的痛点很有帮助。是跨多数据集、多任务特征融合的集大成者。
原论文信息如下:
论文标题:
多数据集跨域知识蒸馏用于统一的医学图像分割、分类和检测
2026年05月
发表单位:
布加勒斯特大学
原文链接:
https://arxiv.org/pdf/2605.01563v1.pdf
三阶段流水线:如何炼造“全能”医学影像分析模型?
第一阶段:训练“专科教师” (Teacher models with domain adversarial alignment)
本阶段的目标是为每个数据集训练一个优秀的教师模型。这里的“教师”有两个类型:
第二阶段:构建“武林秘籍” (Joint teacher via multi-level feature fusion)
当所有老师们都练好各自的武功后,本论文并不直接让他们去教学生,而是先把他们的知识整合起来,形成一本更强大的“秘籍”。该阶段会构建一个联合教师模型。具体做法是:将第一阶段训练好的所有教师模型(包括目标教师和源教师)的编码器和瓶颈层全部冻结,然后通过交叉注意力机制(Cross-Attention),将他们在不同抽象层级(多级特征)上所学到的特征图进行融合。这相当于把多位专家的观点综合起来,提炼出一套更全面、更鲁棒的特征表示。
第三阶段:传授“武林秘籍” (Curriculum-driven knowledge distillation)
最后一步,就是用这本“秘籍”来训练一个轻量级的学生模型。这个学生模型的目标是尽可能去模仿联合教师的行为。但这里的“模仿”不是生搬硬套,而是一个循序渐进的、有组织的过程,即课程式知识蒸馏。训练过程不仅包括常规的监督信号(让学生自己根据真实标签做预测),还引入了多层次的蒸馏损失,比如特征对齐、余弦相似度等,确保学生模型不仅学到了“术”(输出结果),更深层次地学到了“道”(特征表示的内在逻辑)。
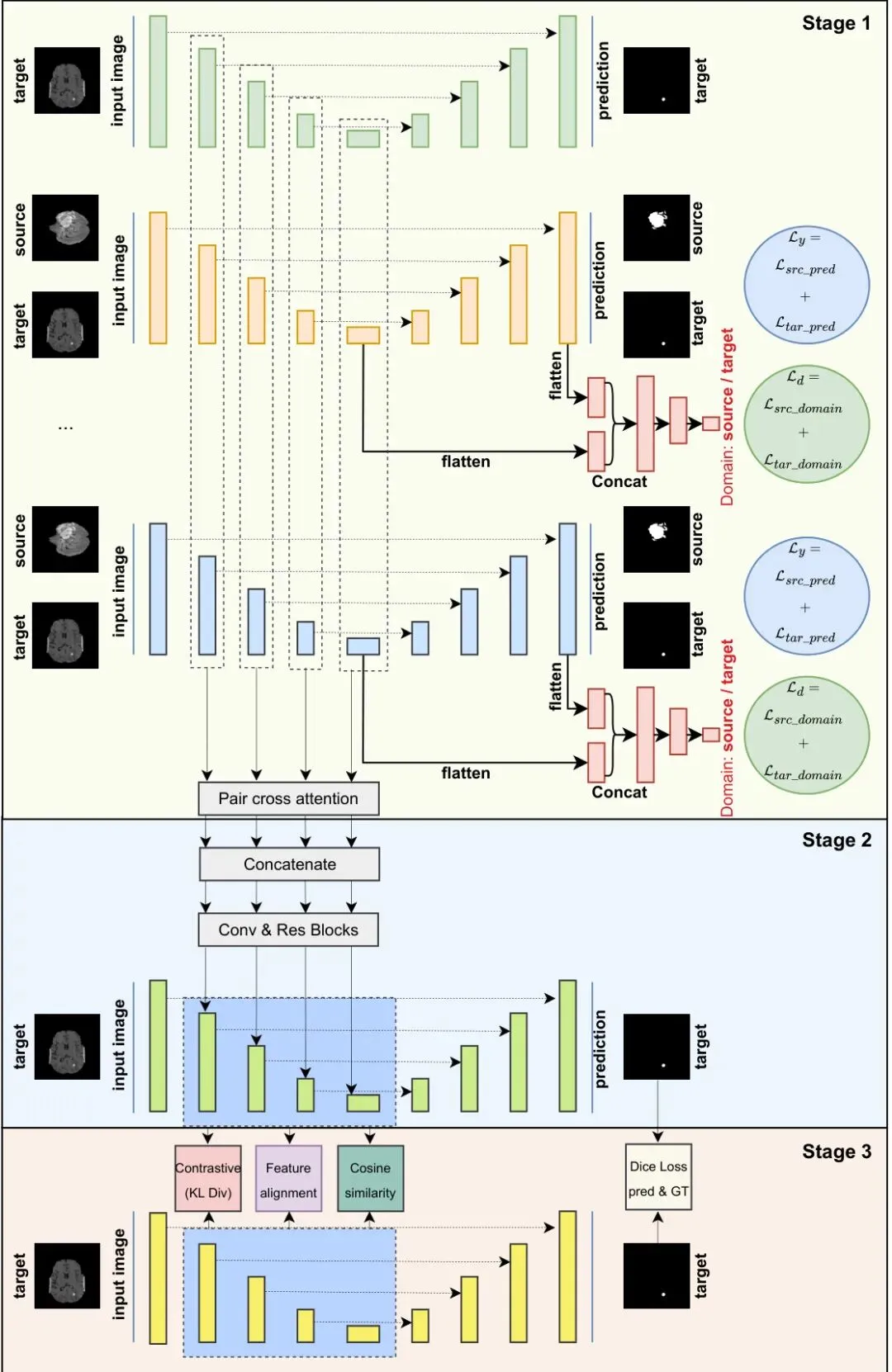
输入:目标数据集 Dt,多个源数据集 {Ds1,...,Dsm},对应的教师模型和联合教师与学生模型。
输出:训练好的学生模型参数。
1. 阶段1: 训练目标教师 (使用 Dice Loss)
2. 阶段1: 训练源教师 (使用域对抗损失,结合 Dice Loss)
// 对于每个源教师 T_sk:
// 在保持分割性能的同时,通过对抗训练使编码器学习域不变特征。
3. 阶段2: 构建 & 训练联合教师
// 冻结所有教师模型的编码器和瓶颈,用交叉注意力融合其多级特征。
// 仅在目标数据集上训练一个新解码器,得到联合教师 T_*。
4. 阶段3: 知识蒸馏到学生
// 冻结联合教师,让学生模型模仿其多级特征。
// 总损失 = 任务损失 (Dice/CE等) + 课程式蒸馏损失(对比、对齐、余弦相似度)
域对抗训练与特征融合:让模型“见多识广”的关键
域对抗训练的作用原理
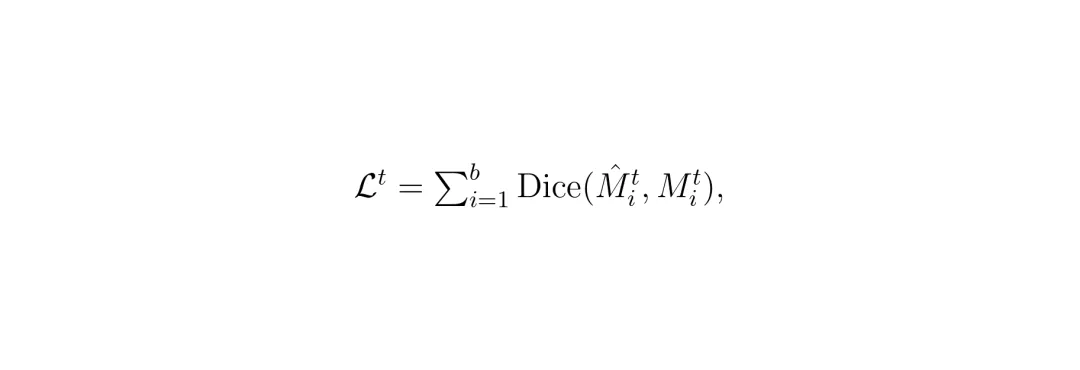 )之上,增加一个域判别器。这个域判别器的作用,是去分辨编码器提取出的特征到底来自源数据集(比如肝脏CT),还是目标数据集(比如脑部MRI)。整个训练过程是一个博弈:
)之上,增加一个域判别器。这个域判别器的作用,是去分辨编码器提取出的特征到底来自源数据集(比如肝脏CT),还是目标数据集(比如脑部MRI)。整个训练过程是一个博弈: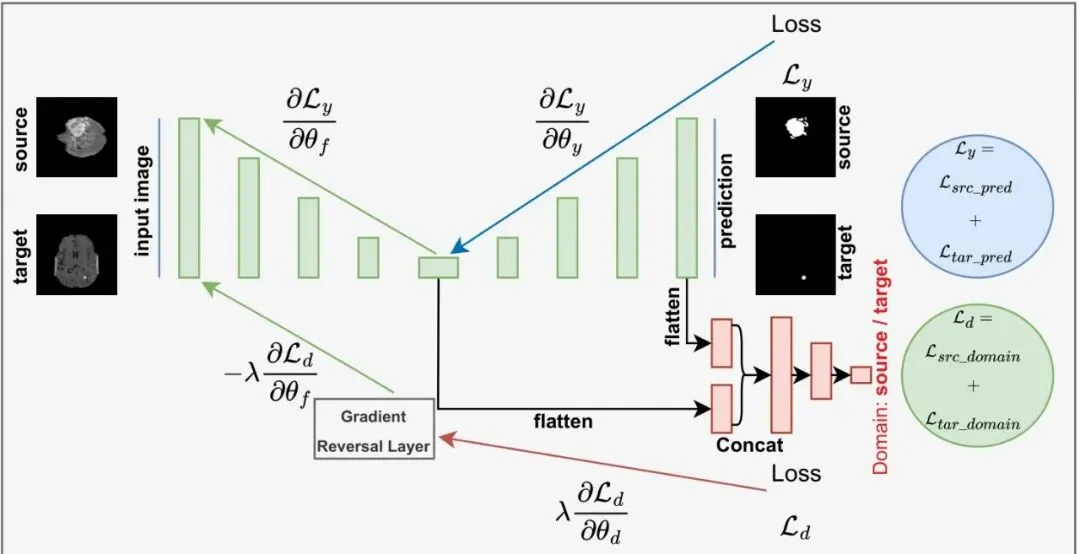
多级特征融合的奥秘
课程式知识蒸馏

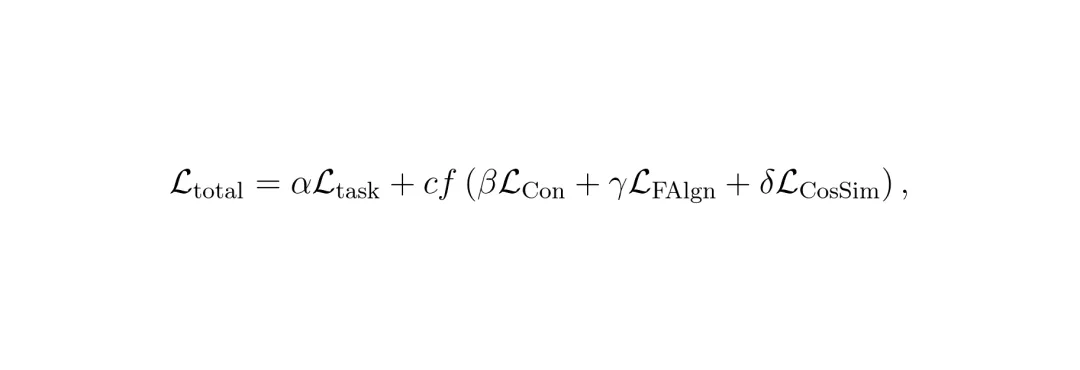
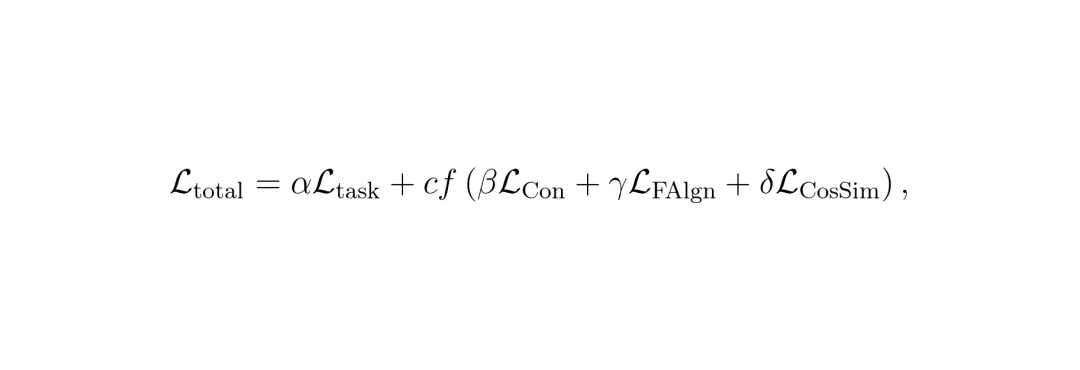 L_task:基础任务损失,使用目标数据的真实标签进行监督学习(如Dice损失或交叉熵损失),确保学生模型的基本能力。
L_task:基础任务损失,使用目标数据的真实标签进行监督学习(如Dice损失或交叉熵损失),确保学生模型的基本能力。
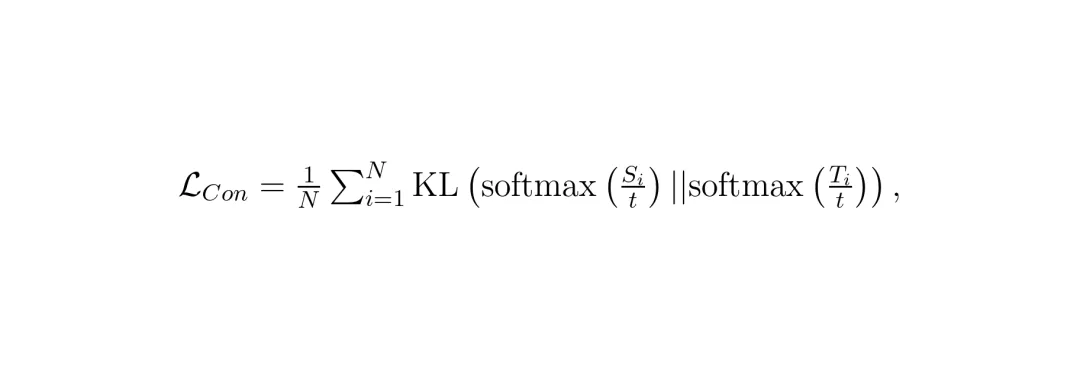 (对比损失): 鼓励学生模型学到与教师模型一致的、具有辨识力的特征表示。
(对比损失): 鼓励学生模型学到与教师模型一致的、具有辨识力的特征表示。
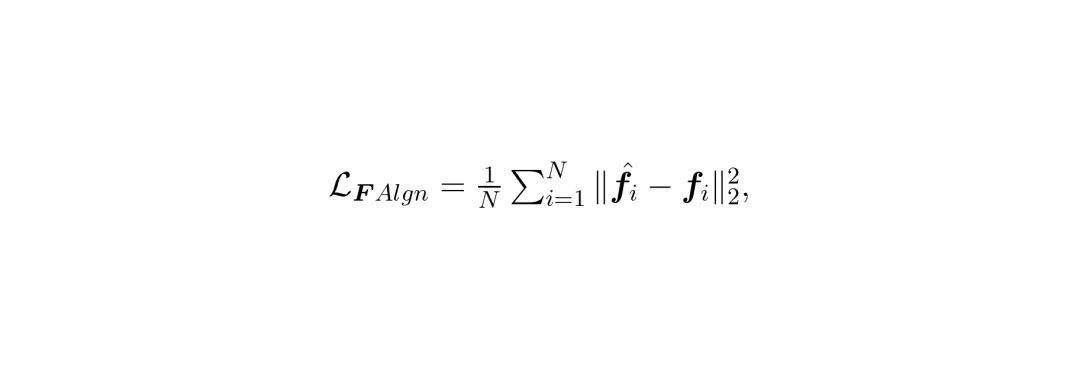 (特征对齐损失): 强制学生模型在中间层生成的特征图与教师模型的对齐,这是学习“术”(即内部处理逻辑)的关键。
(特征对齐损失): 强制学生模型在中间层生成的特征图与教师模型的对齐,这是学习“术”(即内部处理逻辑)的关键。
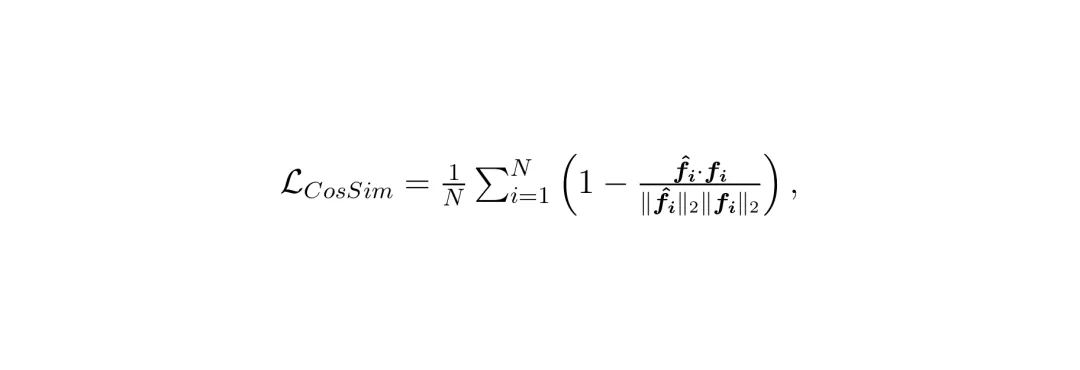 (余弦相似度损失): 确保学生模型和教师模型特征的方向一致性,进一步约束特征质量。
(余弦相似度损失): 确保学生模型和教师模型特征的方向一致性,进一步约束特征质量。
cf:是一个随训练轮次变化的权重,它被称为“课程式因子”(curriculum function)。训练初期较小,让学生优先专注于基础任务(L_task);随着训练深入,它逐渐增大,让学生更多地模仿教师的深层特征。这种循序渐进的策略,避免了学生模型刚开始就“消化不良”,训练过程更稳定、更高效。
跨模态、多任务实验:真金不怕火炼
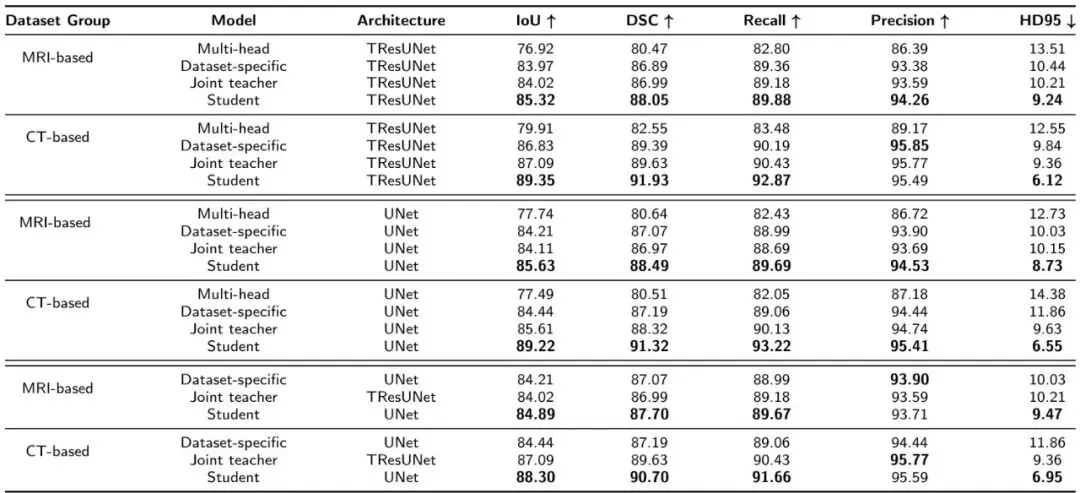
分割任务:多数据集验证
MRI数据集:BrainMetShare(脑转移瘤)、ISLES (缺血性脑卒中病变)、BraTS(脑肿瘤)。
CT数据集:Lung MSD(肺部肿瘤)、LiTS(肝脏及肝肿瘤)、KiTS(肾脏及肾肿瘤)。
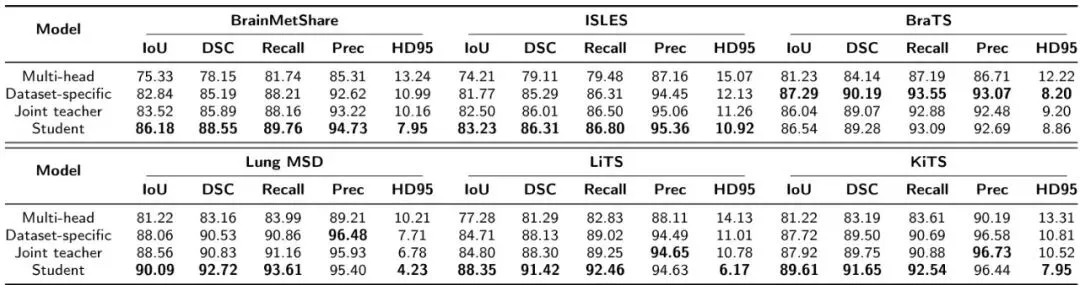
分类任务与检测任务
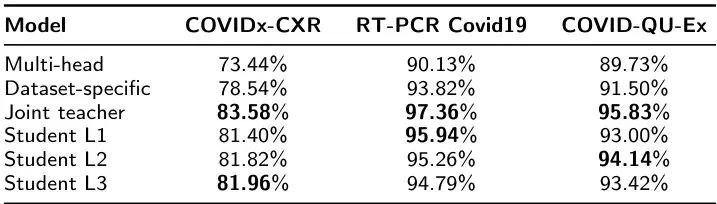

结果解读与局限:这套方案到底有多强?
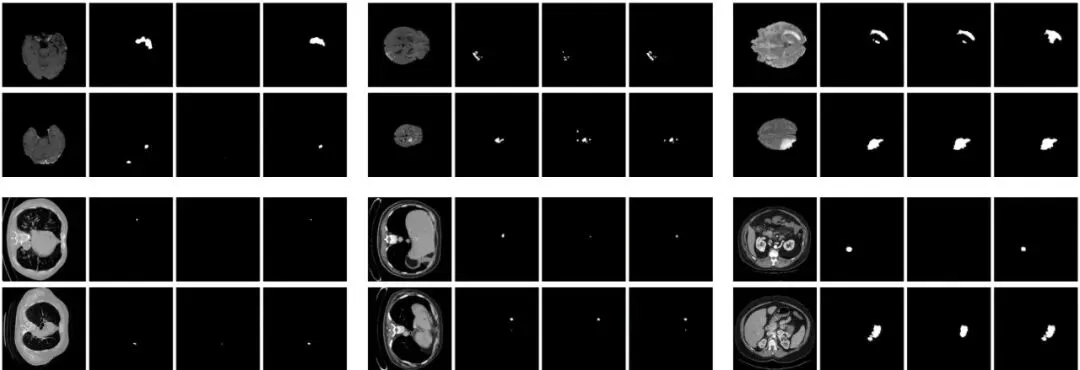
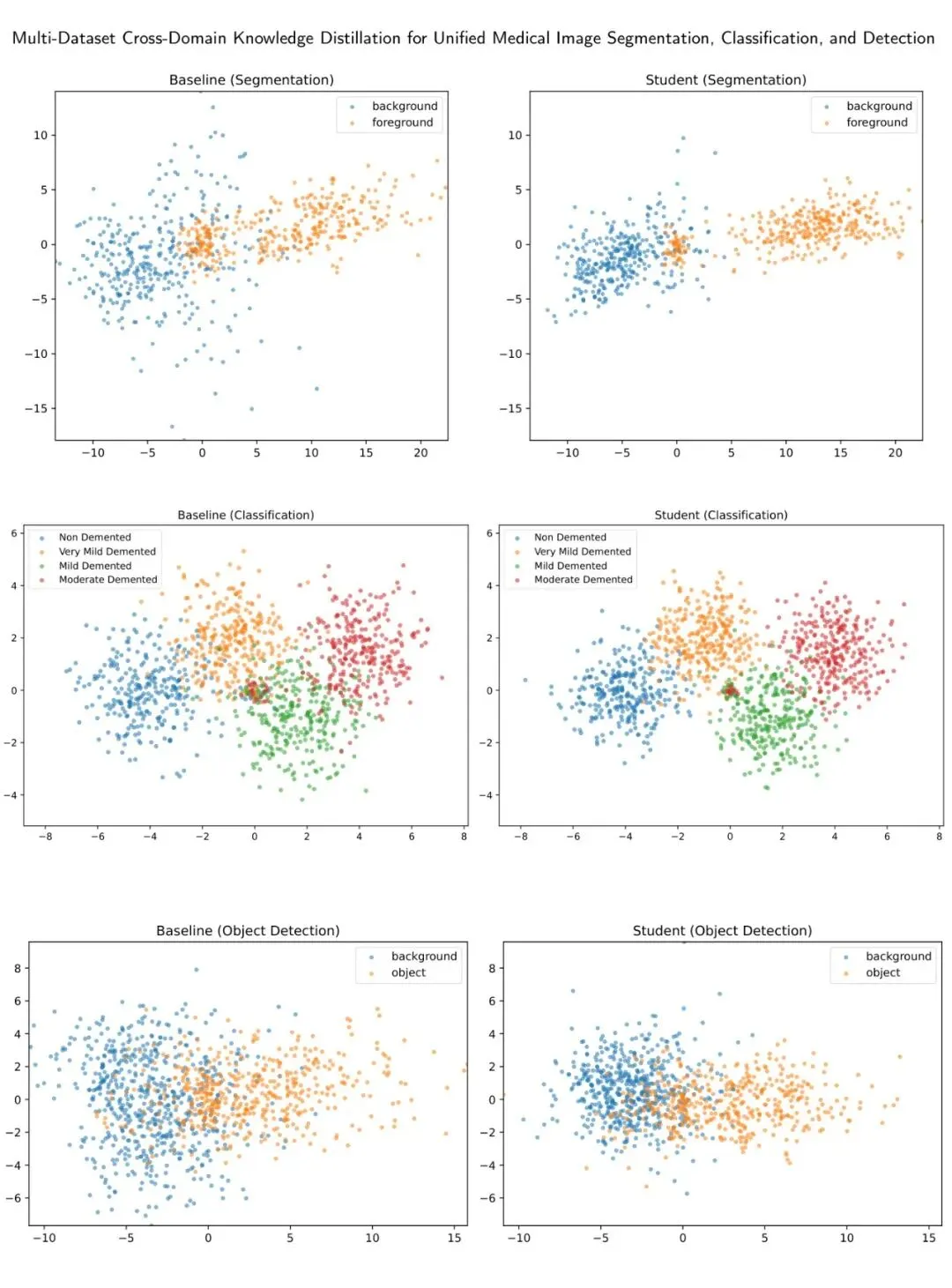
提升显著且全面:在所有三个任务(分割、分类、检测)上,MCD-KD的学生模型都一致性地超越了相应的单数据集基线模型,实现了“全面提升”,这不仅表现在平均性能上,更是在绝大多数单个数据集的评价指标上取得领先。
强大的泛化能力:论文展示了在跨架构(如用TResUNet当老师、UNet当学生)场景下的迁移能力,充分证明了学到的“域不变”特征是网络架构无关的,具有更强的泛化能力。
实用的课程式蒸馏设计:课程式的学习策略不是简单的炫技,它在实验中显示出更稳定的收敛和更优的性能,验证了“由简到繁”教学方法的有效性。
训练成本较高:三阶段流水线的训练需要大量的GPU资源和时间,尤其是在第一阶段需要为每个源数据集单独训练并保存教师模型。实际操作中,资源受限是应用的主要挑战。
假设目标数据可用:虽然作者验证了半监督(r=0)的可行性,但框架在大多数使用场景下仍需要一定量的目标域标注数据来训练最终的头部网络,对无标注目标域场景的适应性仍有提升空间。
融合机制尚显简单:联合教师模型的融合仅用了交叉注意力和卷积块,没有涉及到更复杂的动态路由或专家混合(Mixture-of-Experts,MoE)机制,存在进一步优化的可能性。
龙迷三问
这篇论文解决什么问题?AAA:这篇论文旨在解决医学影像分析中的一个核心痛点:如何利用有限的不同来源、不同任务(分割、分类、检测)的数据,训练出一个在多个任务上都能表现优异的模型。它提出了一个多数据集跨域知识蒸馏框架,通过将多个教师模型的知识融合并蒸馏到一个学生模型中,显著提升了模型在跨域、跨任务场景下的泛化能力和鲁棒性。
文章中提到的“域对抗训练”具体是怎么工作的?AAA:域对抗训练是这样工作的:在训练源教师模型时,除了分割/分类/检测等主任务损失外,还加入一个域判别器。这个域判别器试图判断编码器输出的特征是来自源数据集还是目标数据集。训练时,会通过梯度反转层让编码器朝着迷惑域判别器的方向更新参数。这样一来,编码器不得不学习那些不随数据集变化而变化的“域不变”特征,从而提升模型的跨域泛化能力。
“课程式知识蒸馏”中的课程因子cf(e)有什么作用?AAA:课程因子cf(e)是一个在训练过程中动态变化的权重。在训练初期,cf(e)值很小,这样蒸馏损失的比重很低,学生模型主要关注基础的监督学习任务(L_task),从而先打好基础。随着训练进行,cf(e)逐渐增大,蒸馏损失的权重上升,学生模型开始更多地模仿联合教师模型的多级特征,从而学习到更深层次的、更泛化的知识。这种由简到繁的策略让训练过程更加稳定高效。
龙哥点评
论文创新性分数:★★★★✰
本论文提出了一种新颖且统一的跨域知识蒸馏框架,将域对抗训练、多级特征融合和课程学习有机结合。虽然每个模块都不是全新的,但它们的组合方式及其在医学影像多任务场景下的系统化应用具有较高的创新性。在分类、检测任务的扩展上也展现了很好的通用性。
实验合理度:★★★★✰
实验设计非常扎实。在多个数据集、多种任务和多种架构上进行了详尽的对比实验,涵盖同架构和跨架构蒸馏。设置了充分的消融研究来验证各组件的贡献,实验结论具有很强的说服力。
学术研究价值:★★★★✰
该框架为解决医学影像领域数据稀缺、域迁移性差等核心问题提供了新的思路,具有很高的学术研究价值。它启发了后续研究可以如何更有效地整合多个异构数据源,并为多任务学习提供了可借鉴的范式。
稳定性:★★★★✰
框架在众多不同数据集和任务上均表现出稳定且一致的提升,证明了其强大的鲁棒性。部分缺失目标标签的消融实验也显示出其半监督/无监督设定的潜力。
适应性以及泛化能力:★★★★★
5星满分。该方法从设计上就天然要求跨源数据、跨任务域的泛化性。实验结果完美验证了其在分割、分类、检测三大任务上的泛化能力,在跨架构实验中也表现出色,表明学到的“域不变”特征具有极高的通用性。
硬件需求及成本:★★✰✰✰
训练成本很高。三阶段流水线需要为每个源数据集单独训练教师模型,且需要大量GPU内存进行特征融合和蒸馏训练。但推理时的学生模型是一个轻量级网络,因此实际部署成本很低。考虑到其带来的巨大性能提升,这种训练投入是值得的。
复现难度:★★★✰✰
论文提供了非常详尽的算法伪代码、超参数配置和实验细节(如表1所示),主干网络也都是公开成熟的模型。但训练步骤繁琐,需要较强的工程能力来复现整个三阶段流程。如果能够开源代码,复现难度会显著降低。
产品化成熟度:★★★★✰
框架在学术数据集上表现优异,并且其设计逻辑非常贴近真实临床场景(多个来源、多种任务)。但产品化还需考虑训练成本、模型更新频率、以及在不同硬件平台上的推理速度等工程细节。学生模型轻量化的优势使其具备良好的产品化落地潜力。
可能的问题:
融合机制相对简单,没有采用更高级的MoE或动态路由,有进一步优化的空间。训练流程复杂,计算资源消耗高。此外,虽然验证了半监督设定,但在完全无标注目标域的极端场景下,其性能如何仍有待检验。参考文献部分略显庞大,可能部分引用与核心贡献关联系不高。
主要参考文献
*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的“阅读原文”,查看更多原论文细节哦!

欢迎加入龙哥读论文粉丝群,扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。一定要备注:研究方向+地点+学校/公司+昵称(如 医学影像+上海+交大+小张),根据格式备注,可更快被通过且邀请进群。📊
『龙哥读论文』微信群目前包含:图像处理、大模型及智能体、自动驾驶及机器人、AI医疗及AI金融5个群。💡

