 夜雨聆风
夜雨聆风





Word2Vec:让机器真正“理解”文字

Word2vec是 Google 在 2013 年推出的一款用于训练词向量(Word Embedding)的开源工具,由 Tomas Mikolov 领导的团队开发。
它的核心意义在于:将语言转换成数字。
一、核心思想:通过“邻居”了解你
Word2vec 基于语言学中的“分布假说”——即具有相似上下文的词,其语义也是相似的。
例如,在“我喜欢吃苹果”和“我喜欢吃香蕉”中,“苹果”和“香蕉”都出现在“喜欢吃”的后面,于是 Word2vec 就会认为“苹果”和“香蕉”在向量空间中应该靠得很近。
二、两种训练模型
Word2vec 主要通过两种神经网络结构来训练词向量:
-
CBOW (Continuous Bag-of-Words):
-
做法: 根据上下文的词来预测中间的词。
-
特点: 训练速度快,在小型数据集上表现不错。
-
打个比方: 填空题。已知“我喜欢吃__果”,预测中间是“苹”。
-
Skip-gram:
-
做法: 根据中间的一个词来预测周围的词。
-
特点: 能更好地处理生僻词,在大型数据集上效果更好,是目前更主流的选择。
-
打个比方: 根据“苹果”,预测它周围可能会出现“喜欢”、“吃”、“红色的”。
三、Word2vec 的两大杀手锏
A. 语义计算(词法类比)
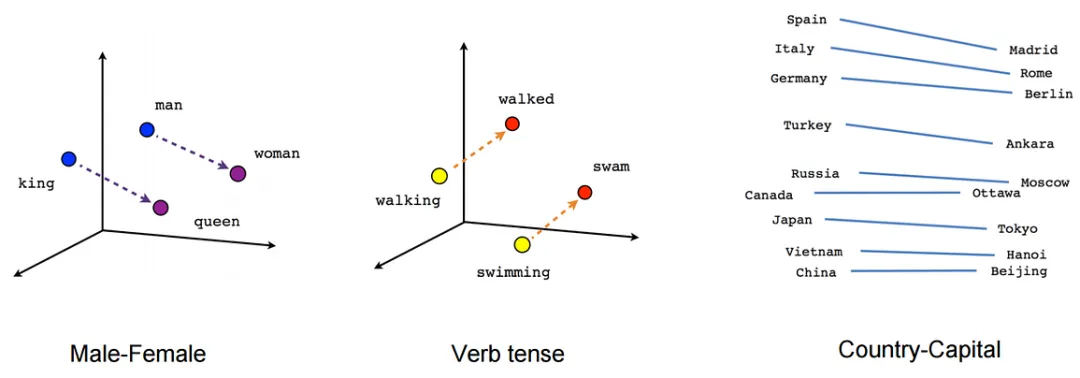
Word2vec 最著名的发现是词向量之间存在代数关系。词向量能够捕捉到许多语言规律。最经典的例子是:
Vector(King) – Vector(Man) + Vector(Woman) ≈ Vector(Queen)
这意味着模型捕捉到了“性别”这一抽象概念。
B. 降维与聚类
原本一个词库如果有 10 万个词,用传统的 One-hot 编码需要 10 万维的稀疏向量。Word2vec 可以将其压缩到仅有 100 到 300 维 的稠密向量,不仅节省空间,还让计算机能够通过计算“余弦相似度”来判断两个词有多像。
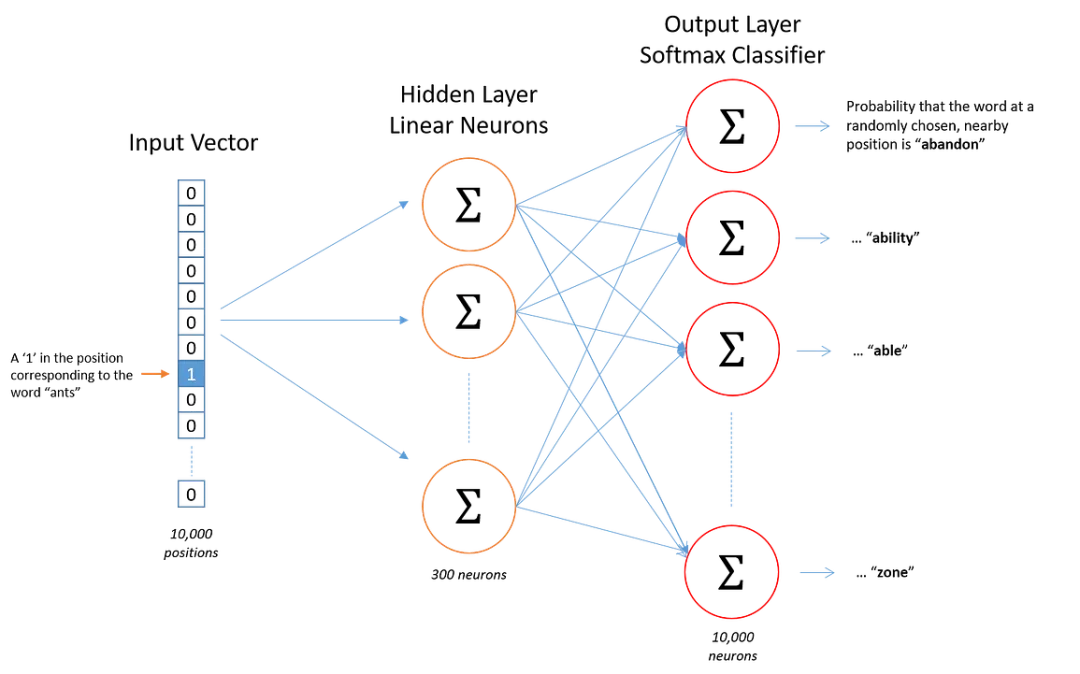
word2vec架构由隐藏层和输出层组成
Xin Rong创建了一个非常简洁的可视化演示,展示了词嵌入是如何训练的,在页面可以练习。
演示页面:https://ronxin.github.io/wevi/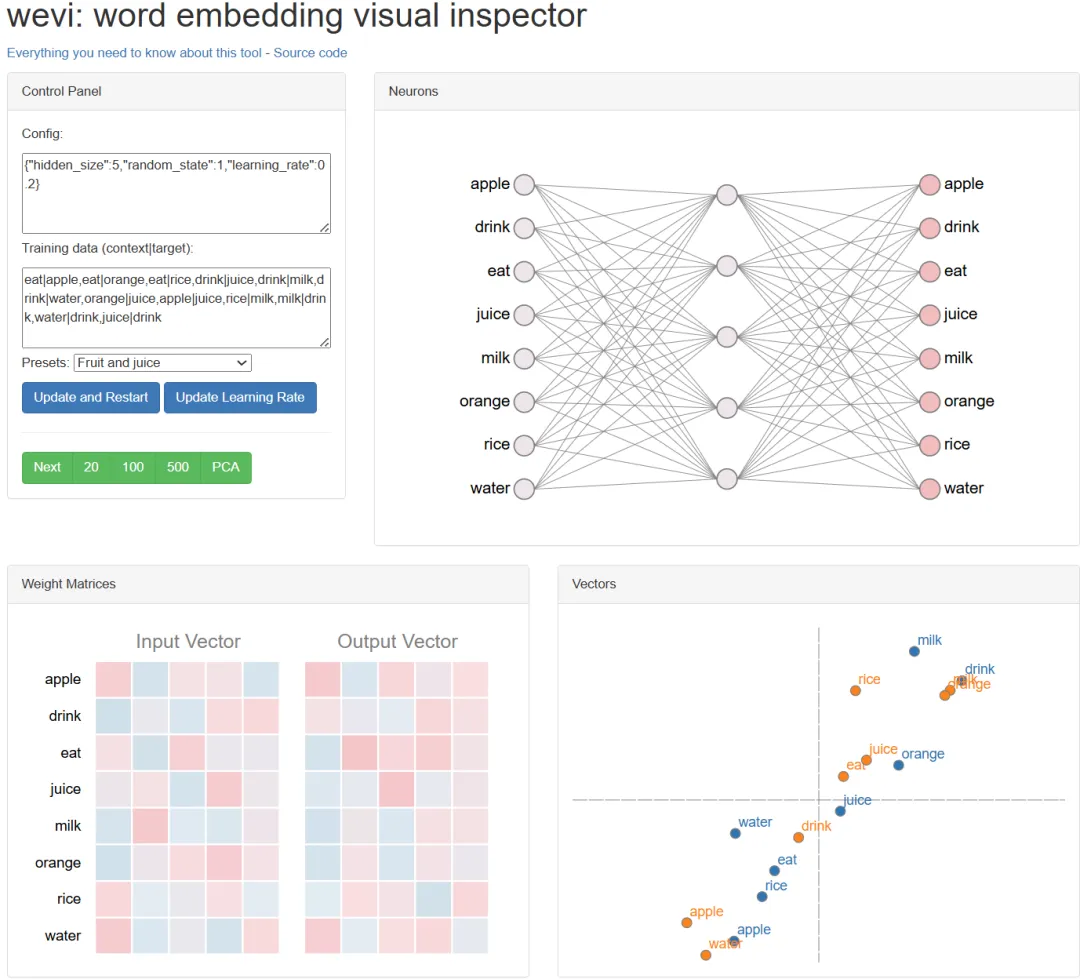
嵌入矩阵的大小等于词数乘以隐藏层神经元的数量(即嵌入大小)。因此,如果有 10,000 个词和 300 个隐藏单元,则矩阵的大小为 10,000×300(因为我们使用独热编码向量作为输入)。计算完成后,获取词向量只需快速查找结果矩阵中对应的行即可,时间复杂度为 O(1)。

所以,词汇表中第 4 个条目的单词的向量是 (10,12,19)。
因此,每个词都有一个关联的向量,故得名:word2vec。
四、为什么现在提它变少了?
虽然 Word2vec 开启了深度学习在 NLP(自然语言处理)领域的黄金时代,但它也有局限性:
-
一词多义问题: 在 Word2vec 中,每个词只有一个固定向量。但在“我想买个苹果(手机)”和“我想吃个苹果(水果)”中,“苹果”的含义不同,Word2vec 无法区分。
-
后浪推前浪: 后来出现的 BERT、GPT 等基于 Transformer 架构的模型,可以根据上下文动态生成词向量(Contextualized Word Embeddings),完美解决了多义词问题,因此在大多数任务中取代了 Word2vec。
五、总结
Word2vec 是 NLP 历史上的里程碑,它教会了计算机如何通过数学坐标来“理解”词语之间的逻辑和关系。
参考资料:
https://code.google.com/archive/p/word2vec/