 夜雨聆风
夜雨聆风





OpenClaw v2026.5.10-beta.5 从预发布来猜也在打造一人团队或一人公司功能?AI团队自主开会20轮

如果你用 AI 助手超过一周,大概率遇到过这个问题:对话越往后,AI 的回答质量下降得越明显。
不是它变笨了。是一家四口挤在两室一厅里住了两周——它的上下文窗口就那么点地方,脑子里塞满了历史对话、之前读过的文件、调过的工具,还要挤出空间来理解你刚说的这句话。你以为它还在认真听,其实它已经在脑子里翻垃圾堆找重点了。
这个问题我遇到过很多次。有时候明明是很简单的指令,AI 给出的结果却像是打了一半瞌睡写的。但你没办法检查——你根本不知道它脑子里那点有限的空间,到底被什么占了。
开源 AI Gateway/Agent 框架 OpenClaw(GitHub 371k Stars,76.7k Forks,全球最大的开源 Agent 框架)早上放出了 v2026.5.10‑beta.5,虽然是一个预发版本,但有几样东西值得聊一聊。看完升级日志,挑三样最触动我的说。
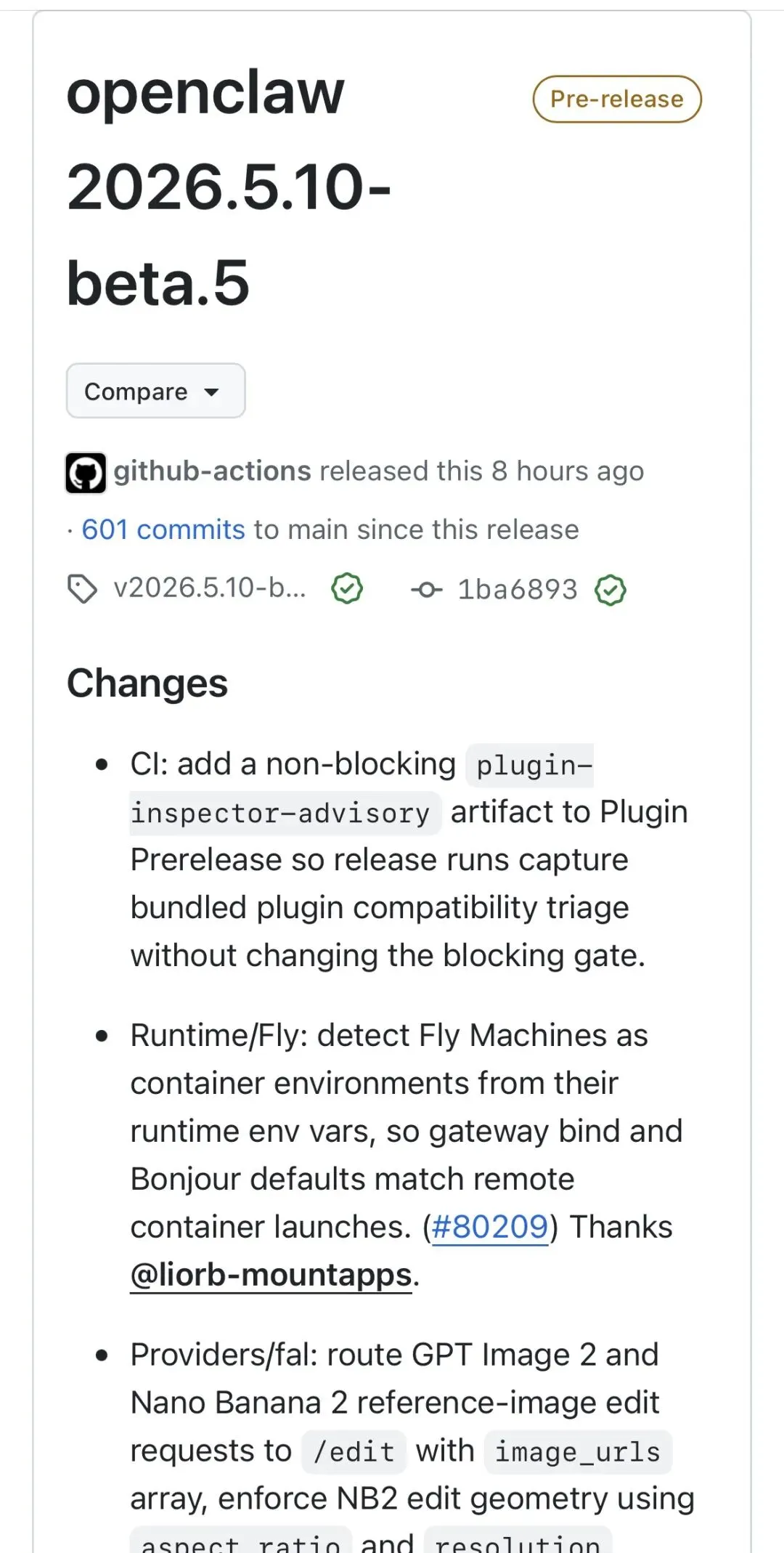
01 | 第一次能看到 AI 脑子里装了什么
新增了一条斜杠命令:/context map。发送之后,它会返回一张 treemap——一张矩形的占比图,每种颜色代表一类上下文贡献者,面积越大,占的内存越多。
翻译一下:你可以第一次「看到」AI 脑子里现在装着什么了。
哪些文件还在占据位置、哪些工具调用占了多少 token、当前对话和系统提示各占了多少——一目了然。你一看就明白,为什么刚才让它读一个 500 行日志文件之后,后面几轮对话的质量明显下降了。不是模型不行,是那 500 行日志还赖在上下文里没走。
我以前排查对话质量下降全靠猜:先怀疑系统提示太大,再怀疑是不是刚才丢了个长文档。现在不需要了。一条 /context map 发过去,它直接给你一张分布图,哪里不对一目了然。这对高频用 AI 写代码或者做分析的人来说,等于给了你自己清洗内存的权力——你至少知道到底是谁在占地方。
以前有种矛盾心理:明明觉得 AI「变笨」了,但又不敢清上下文,怕清掉之后它忘了之前的重要信息。现在有了这张图,你可以做判断了——这个 2000 token 的日志文件占着位置,但刚才的对话早就跑偏了,果断清掉。这是诊断工具,不是魔法,但对重度用户来说,它给了一个以前没有的东西:知情权。
02 | 让 AI 团队自己开会,开到 20 轮
OpenClaw 有一个 Agent-to-Agent 的协作机制:你可以让一个 AI agent 去调用另一个 AI agent,它们之间会来回通信,互相交接工作。这个机制叫 ping-pong——像打乒乓球一样,A 说完了传给 B,B 处理完传回给 A,每一来一回算一轮。
之前默认最多跑 5 轮。但 5 轮能干的事情很有限。比如你让一个写代码的 agent 去调用一个审查 agent,审查完了回来要修改,改完了再审查——5 轮通常只够两个来回。稍微复杂一点的长链条任务,中间就被截断了。
这次放开到了 最多 20 轮(默认仍然是 5,你需要自己去配置上线)。同时新增了两个控制能力:每个 agent 可以独立设置 crossContext(是否能看到其他 agent 的上下文)和 actions.allow(允许执行哪些操作)。
这意味着什么?你可以搭建一个更接近真实团队的工作流水线了。
举个例子:一个数据分析 agent 负责查数据库出报告,然后交给一个写文章 agent 把报告翻译成通俗文字,再交给一个审查 agent 检查事实准确性,有问题退回修改——这么一套下来,保守估计也要 8-10 轮。以前 5 轮上限,写到一半就断了,你睡一觉回来发现报告只写了一半。现在可以全程跑完,而且你可以把写文章的 agent 的 crossContext 关掉,让它看不到原始数据库里的敏感字段,只看到经过处理后的数据。这种权限控制之前是没有的。
这不是一个「给重度用户用」的功能,它直接改变了你使用 AI 的想象空间——从「我指挥一个 AI 干完所有事」到「我派几个 AI 去协作完成一个链条」。20 轮的上限意味着短链条可以跑完一整条链路,而不是每次都在中途鬼打墙。
03 | 本地模型,终于不用提前开机守着了
说一个痛到骨子里的事:跑本地模型。
如果你用过 Ollama 或者其他本地模型配合 OpenClaw,一定经历过这个流程:先在终端敲 ollama serve 或者 llama-server,等它启动完毕,确认端口已经监听,再回到 OpenClaw 使用。如果中途服务崩了,你打开 ChatGPT 页面之前还得先切回终端看一眼。
这事我干了两年了,每次换台机器都得重新习惯。一直觉得没什么,直到看到 v2026.5.10-beta.5 里这个改动。
新增了 localService 启动配置。在 provider 声明里直接配好本地模型的启动命令、端口、工作目录,OpenClaw 会在需要用到那个模型的时候自动帮你启动服务,用完之后随它去——你不关也行,下次复用,但它至少不要求你手动在另一个窗口里一直开着它。
很多人可能会觉得「这不就是个自动化启动嘛」。但用过本地模型的人就知道,痛点不在于点一下启动按钮的那一秒,而在于你每次想用的时候都要切换到「我还要先干点别的才能开始用」的心理模式。按需唤醒,用完不管——这个「不管」两个字,才是真正让人觉得舒服的地方。
我试了一下,读配置的方式很直接,就是声明式的:在 provider 配置里写上 "localService": {"command": "ollama serve", ...} 就好了。OpenClaw 会在发送 OpenAI 兼容请求前自动唤醒,发送完也不会强行 kill——留着你下次复用更快。说实话,这个改动看起来小,但它是那种「一旦有了就回不去」的东西。
04 | 速览:这次还改了什么
上面三条是这次最值得说的,但剩下的改动里也有几个值得关注:
技能包 ZIP 安装:gateway 管理员可以在配置里打开 skills.install.allowUploadedArchives,允许通过上传 zip 文件安装私有技能包。之前技能包安装只能从公开仓库拉,现在企业内部可以自己做私有的技能包随手分发了。对团队协作来说,这个很实用。
Discord 语音频道限制:新增了 voice.allowedChannels 配置,可以限制机器人只能加入特定的语音频道。之前 bot 加你语音频道没有限制,现在管理员可以精确控制哪些频道可以接入 OpenClaw 的语音能力——对社区用 Discord 的服务器来说,少了被捣乱的烦恼。
Slack 链接预览控制:新增了 unfurlLinks 和 unfurlMedia 配置,可以在 bot 回复中控制是否展开链接的预览卡片。以前 Slack 里每发一条消息自动展开链接预览,不仅刷屏也占空间,现在终于能关掉了。
还有很多底层改进——pnpm 11 升级、TypeScript 更严格的编译检查、插件 SDK 的一系列清理——但这些对普通用户来说不那么直接,就不逐一展开了。
说句实话,我看了这个 beta 版本,最深的感受不是某个功能多好用,而是 OpenClaw 团队开始认真对待一个以前没人好好解决的问题:AI 的使用体验不止是模型的能力,还有人对这个系统的感知和控制力。/context map 给你知情权,localService 给你启动上的省心,20 轮上限给你更长的自主链条——每一处都在减少你作为用户的「不知道」和「不想做但被迫做」。
不过话说回来,beta 就是 beta,我试的这几个beta版本里也碰到过一次 /context map 生成图片后预览不出来的情况,刷新就好了。我不确定是不是我的环境问题,如果你也翻到了这个版本,可以告诉我你的体验。
最后问一个具体的问题:你是什么时候开始觉得 AI「越聊越笨」的——是对话超过多少轮之后,还是丢了一个大文件之后?这个版本里的 /context map 也许能帮你找到答案。
⭐点赞、转发、关注和推荐一键三连⭐