 夜雨聆风
夜雨聆风





OpenClaw 长期记忆实战:让 Agent 记住你是谁
凌晨两点。用户发来一条消息:
“上次你帮我调的那个 prompt ,我改了一下又出问题了。”
我盯着屏幕愣了三秒。哪个用户?哪个 prompt ?什么时候的事?
翻日志翻了十分钟,终于在三天前的聊天记录里找到了上下文。原来是他,原来是那件事。我把当时的修改建议复制粘贴过去,用户回了一句:”你怎么又不记得了。”
这句话让我挺尴尬的。
上一篇我们搭了多 Agent 团队——调度员、代码专家、信息助手,各司其职。但有个问题我一直没敢说:这些 Agent 都是金鱼脑子。每次对话结束,记忆就清零。用户第二天再来,一切从零开始。
多 Agent 解决了”分工”的问题,但” continuity “(连续性)的问题还没碰。
今天来填这个坑:长期记忆。
为什么协作之后,记忆成了下一个瓶颈
先说清楚,长期记忆不是”让 Agent 记得更长的对话”。
上下文窗口( context window )从 4K 拉到 128K 、 200K ,解决的是”同一次对话里能看多少字”的问题。但用户周三来问了一个问题,周五再来跟进——这中间隔了两天、几十条其他消息,窗口再大也覆盖不到。
长期记忆解决的是”跨会话”的问题。
我梳理过,没有长期记忆的 Agent 会让用户体验掉链子的地方至少有这几个:
第一,重复劳动。 用户每次都要重新介绍自己的场景、偏好、技术栈。就像去同一家理发店,每次都要重新说”我头发软、别剪太短”。
第二,上下文断裂。 用户说”按上次那个方案继续”, Agent 一脸懵——”上次?什么上次?”
第三,无法建立信任感。 真正好用的助手,应该越用越懂你。如果每次对话都像第一次见面,用户永远不会觉得”这个 Agent 是我的”。
所以问题很清晰:Agent 团队会分工了,但它们需要一张”共同的工作笔记”——记住用户是谁、聊过什么、偏好什么。
 图 1 :没有长期记忆的 Agent 就像金鱼——每次对话都是第一次见用户,上下文完全断裂
图 1 :没有长期记忆的 Agent 就像金鱼——每次对话都是第一次见用户,上下文完全断裂
请在微信客户端打开
长期记忆的三种形态
不是所有”记住”都一样。我实际做下来,长期记忆至少分三种,每种解决的问题不同:
形态一:用户画像( User Profile )
静态信息,类似于用户注册时填的资料,但由 Agent 在对话中自动提炼和更新。
比如: – 技术栈: Python / Node.js / Go ? – 角色:开发者 / 产品经理 / 运维? – 偏好:喜欢详细解释还是直接给代码? – 历史决策:上次选了方案 A 而不是方案 B ,原因是什么?
这种记忆的更新频率很低,但命中的时候价值极高。一次写入,长期受益。
形态二:对话历史( Conversation History )
动态信息,记录你和这个用户聊过什么、结论是什么、有没有待办事项。
比如: – 上周三:用户问 Redis 集群配置,建议用哨兵模式,用户说”我先试试” – 上周五:用户反馈哨兵模式在生产环境有延迟问题,改用 Cluster 模式 – 今天:用户问 Cluster 模式的扩容方案
没有这段历史,今天的回复可能就是”推荐哨兵模式”。但有了历史, Agent 应该知道”用户已经试过哨兵,现在用 Cluster ,问的是扩容”。
形态三:外部知识( External Knowledge )
不是”记住用户”,而是”记住世界”。 Agent 需要访问企业内部的文档、数据库、 API ,才能把回复从”通用知识”升级为”业务知识”。
比如: – 公司内部的技术文档 – 产品的历史版本变更记录 – 用户自己的代码仓库和注释
这种记忆通常用 RAG ( Retrieval-Augmented Generation ) 实现——先把文档切片存入向量数据库,用户提问时检索相关片段,再拼进 prompt 里让模型生成回答。
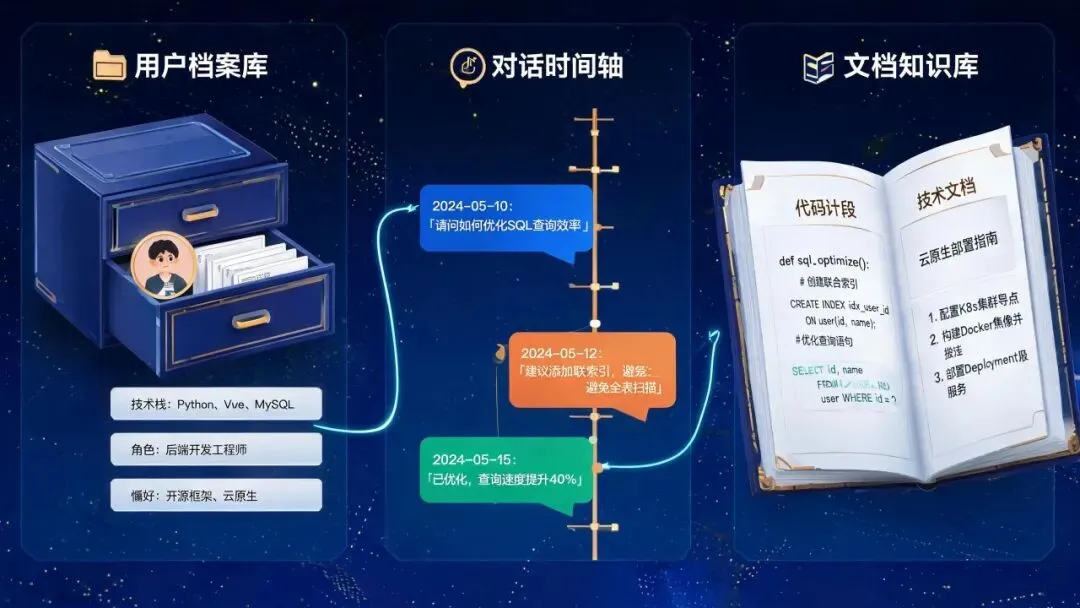 图 2 :三种记忆形态——用户画像(静态档案)、对话历史(时间线)、外部知识(企业文档库)
图 2 :三种记忆形态——用户画像(静态档案)、对话历史(时间线)、外部知识(企业文档库)
请在微信客户端打开
OpenClaw 里的 Memory 模块怎么用
好消息是, OpenClaw 从设计上就考虑了记忆的问题。它的架构里有一个 Memory 层,可以用来存储和检索跨会话的信息。
坏消息是,这部分文档写得比较简略,我踩了不少坑才跑通。
基础配置:启用 Memory
在 config.yaml 里,给需要记忆的 Agent 加上 memory 字段:
agents:-name:code-agentsystemPrompt:"你是资深工程师..."provider:openaimodel:gpt-4omemory:enabled:truetype:"session"# 可选:session / user / globalstorage:"redis"# 可选:memory / redis / file三个 type 的区别:
我实际用的是 user + redis 的组合。 Redis 持久化之后,即使 OpenClaw 服务重启,记忆也不会丢。
用户画像的实现
OpenClaw 没有内置的”用户画像”模块,但可以用 Redis Hash 自己搭一个。
我的做法是在 Agent 的 system prompt 里埋一条指令:
systemPrompt:|你是资深工程师。在回复用户之前,请先检查以下用户画像:{{user_profile}}如果用户提到了新的偏好或信息,请在回复结束后更新用户画像。然后在 OpenClaw 的消息处理流程里加一层中间件:
user:{user_id}:profile{{user_profile}} 占位符<update_profile> 标签,解析内容并更新 Redis这个方案不算优雅,但够用。关键思路是:prompt 工程 + 外部存储 = 记忆。
 图 3 : OpenClaw Memory 层的工作流程——用户消息进来时先读记忆、再生成回复、最后写回更新
图 3 : OpenClaw Memory 层的工作流程——用户消息进来时先读记忆、再生成回复、最后写回更新
用向量数据库做 RAG :让 Agent 记住”你们聊过什么”
对话历史的存储比用户画像更复杂,因为聊天记录是时序数据,不能简单存成一个 KV 对。
我的方案是:把每次对话的摘要存入向量数据库,需要时做语义检索。
具体流程
第一步:对话摘要。
每次对话结束后,让 GPT-4o-mini 生成一段摘要:
用户问了 Redis 集群配置,推荐哨兵模式,用户决定尝试。 摘要长度控制在 50 字以内,太长检索时会噪声太多。
第二步:向量化存储。
用 embedding 模型(比如 OpenAI 的 text-embedding-3-small)把摘要转成向量,存入 Milvus 或 Pinecone。每条记录带 metadata :user_id、timestamp、session_id。
第三步:检索增强。
用户新消息进来时,先对消息做 embedding ,然后在向量库里检索”这个用户历史上最相关的 3 条对话摘要”。
比如用户今天问”Cluster 模式怎么扩容”,检索结果可能是: – “用户问了 Redis 集群配置,推荐哨兵模式,用户决定尝试”(相关性 0.82 ) – “用户反馈哨兵模式有延迟问题,改用 Cluster 模式”(相关性 0.91 ) – “用户问 Redis 持久化配置”(相关性 0.45 )
把相关性高的摘要拼进 prompt :
以下是该用户的历史对话摘要,供你参考: - 用户反馈哨兵模式有延迟问题,改用 Cluster 模式 - 用户问了 Redis 集群配置,推荐哨兵模式,用户决定尝试 用户问题:Cluster 模式怎么扩容? 这样 Agent 就知道”用户已经不用哨兵了,现在用 Cluster”,不会给错建议。
一个坑:摘要质量决定一切
如果摘要写得太笼统,比如”用户问了技术问题”,那检索出来也没用。我现在的 prompt 是这样的:
请用一句话总结这次对话的核心内容,包含: 1. 用户的问题或需求 2. 给出的建议或方案 3. 用户的反馈或决策(如果有) 限制:50 字以内,不要出现"用户"二字,用第三人称客观描述。 效果比让模型自由发挥好得多。
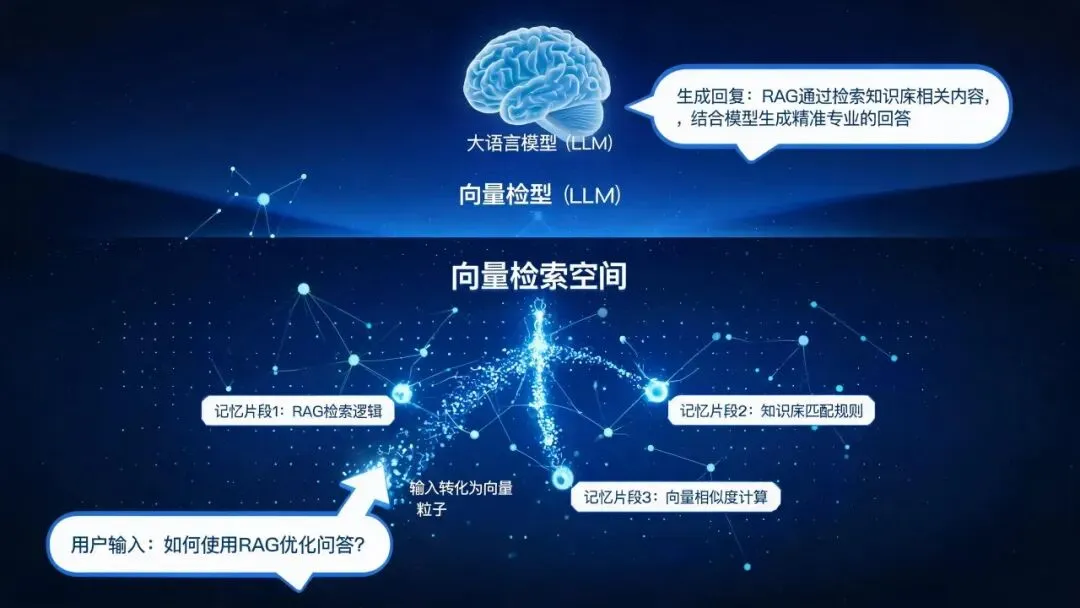 图 4 : RAG 流程——对话摘要 → 向量化 → 语义检索 → 注入 prompt ,让 Agent”想起来”用户之前聊过什么
图 4 : RAG 流程——对话摘要 → 向量化 → 语义检索 → 注入 prompt ,让 Agent”想起来”用户之前聊过什么
个性化:从”通用回复”到”懂你的回复”
记忆最终服务的目的是个性化。
同一个问题,不同用户应该得到不同风格的回复。这个我在第 3 篇讲 prompt 调优时提过,但当时没展开——因为那时候 Agent 还不记得用户是谁。
现在有了用户画像,可以这么做:
示例一:技术深度自适应
用户画像里记录”角色:初级开发者”, Agent 的回复就多给代码示例、少讲原理。如果记录”角色:架构师”,回复就侧重设计思路和权衡分析。
示例二:沟通风格自适应
有的用户喜欢直接给答案:”改这行代码。”有的用户喜欢完整解释:”这里的问题是… 修改的原理是…”
用户画像里加一条 communication_style, Agent 在生成回复时自动匹配。
示例三:主动跟进
如果对话历史里记录”用户三天前说要试用哨兵模式,还没反馈结果”, Agent 可以在下次对话开头主动问:”上次推荐的哨兵模式试了吗?有没有遇到什么问题?”
这种”被记得”的感觉,是建立长期信任的关键。
我踩过的坑
坑一:记忆太多反而干扰。
刚开始我把用户所有历史对话都塞进 prompt ,结果模型被干扰得一塌糊涂——十条历史里八条无关,模型抓不住重点。
解决:摘要 + 检索 Top-K,不要全量塞。 K 设成 3-5 条,只给最相关的。
坑二:记忆更新不及时。
用户说”我改主意了,不用 Python 了,转 Go”,但 Agent 下次还是按 Python 推荐。因为用户画像更新有延迟。
解决:关键偏好在对话中实时更新,不要等对话结束。我在 Agent 的 system prompt 里加了一条:”如果用户明确表示偏好改变,立即更新画像。”
坑三:多 Agent 之间的记忆隔离。
CodeAgent 记住了用户的技术栈,但 InfoAgent 不知道。用户问 InfoAgent 问题时,回复风格又变回默认。
解决:共享用户画像层。所有 Agent 共用同一个 Redis key (user:{id}:profile),但各自维护自己的对话历史摘要。
坑四:隐私和安全。
记忆多了之后,敏感信息(比如用户的业务数据、内部架构)也存进去了。如果 Redis 没有密码、没有加密,风险很大。
解决:Redis 必须开认证 + TLS,敏感字段做脱敏。另外,给用户一个”清除记忆”的指令,让用户有控制权。
五篇文章,一条完整的进阶路线
写到这,五篇文章的脉络终于闭环了。
第一篇:选框架——OpenClaw vs Hermes ,为什么选 OpenClaw 。第二篇:搭起来——从 0 到 1 部署,把桥通车。第三篇:调好单 Agent——prompt 工程、插件开发、监控告警,让一个人能扛事。第四篇:多 Agent 协作——分工、评审、链式,让团队取代个人。第五篇:长期记忆——让 Agent 团队记住用户是谁、聊过什么,从”工具”变成”伙伴”。
五篇看完,你手里有的不只是一个会聊天的机器人,而是一个有记忆、会协作、越用越懂你的 Agent 系统。
但这还不是终点。
如果把这五层能力叠在一起,下一步真正让人兴奋的,可能是自主进化——Agent 不只是记住历史,还能从历史里学到规律,主动优化自己的行为。但这个话题已经超出”实战”的范畴,更像是”研究”了。
等我真的跑通了,再来开新坑。
先把记忆搭起来吧。记住用户,是建立信任的第一步。
💡 温馨说明: 本文内容由「青城源码」团队结合 AI 辅助创作与人工校对整理而成,所有核心观点与实操步骤均经过人工验证。
如果你也对 AI 自动化内容生成、 AI Agent 框架搭建、技术落地实操感兴趣,或是有相关项目开发、学习交流的需求,欢迎在后台私信咨询,我们会为你提供专属的技术交流与学习建议。
摘要: 多 Agent 协作解决了分工问题,但记忆断层让用户体验掉链子。用户画像、对话历史、外部知识三种记忆形态, OpenClaw Memory 模块配置, RAG 向量检索实战,以及我踩过的四个坑。
标签: #OpenClaw #AI Agent #长期记忆 #RAG #向量数据库 #个性化
关键词: AI Agent 长期记忆、 OpenClaw Memory 、 RAG 检索增强、向量数据库、用户画像、对话历史、个性化回复