 夜雨聆风
夜雨聆风





OpenClaw �� Memory Wiki ,让AI的记忆从一堆笔记变成知识库.
使用用 OpenClaw 有一段时间了,每天用它写文章、写日报、整理笔记。但我发现一个问题,记忆文件越来越多了。memory 目录下面堆了三个月的记录,MEMORY.md 越来越臃肿,速度越来越慢。
我就想,OpenClaw 记了这么多东西,但这些笔记真的变成了知识吗?
我在文档里翻到一个内置插件,叫 Memory Wiki。当时第一反应是,OpenClaw 不是已经有 memory 了吗又来一个 wiki?这不就是换皮吗?
然后我仔细读了一下,发现事情没那么简单。
这个功能解决了一个我一直觉得不太对劲的问题。AI 的记忆,到底应该是一堆日志,还是一个知识库?
Memory Wiki 给的答案是,它可以是一个知识库。
memory 和 wiki,到底啥关系
先搞清楚一个概念。OpenClaw 的「记忆」和「维基」是两回事,但它们一起工作。
记忆层负责原始数据,每天的日志、对话记录、promotion 出来的要点、模型自己做梦梦到的结论。这东西很生动,很鲜活,但你很难从里面精确找到「AI探客是什么星座」这种具体事实。
而 wiki 层负责什么呢?它把这些原始素材编译成一个结构化的知识库。每个页面有明确的分类,每条信息有出处和置信度,互相矛盾的地方会被标记出来。
打个比方你就懂了。
记忆层就像你手机相册里的几千张照片。每张照片都记录了一个真实的瞬间,但它们堆在一起,你想找到去年在敦煌拍的那张,得翻到手酸。
wiki 层就是你花了半天时间整理的那个精选相册,按地点分类、打了标签、重要的照片还加了备注。查找效率不是一个量级。
那 Memory Wiki 到底能做哪些事?
我列几个我觉得最牛逼的,你感受一下。
第一,它有个真正的知识库结构。不是一堆散装的 Markdown,而是 entities(实体)、concepts(概念)、syntheses(综述)、sources(源文件)这种分级分类。每个页面还有前部元数据,包括什么类型、谁写的、多久前更新的、置信度多少。
第二,它支持结构化声明。你可以在页面上写「AI探客的星座是狮子座」这样一条 claim,然后给它打上证据来源、置信度分数、更新时间。这就不是一条笔记了,这是一条可追溯、可验证的知识断言。
第三,它内置了矛盾检测和健康报告。如果你的 wiki 里同时有「AI探客是狮子座」和「AI探客是处女座」,lint 工具会把它揪出来。类似这种冲突多了,wiki 会自动生成 contradiction report。
说实话,我看到这里的时候,脑子里冒出的想法是,这玩意不就是给我的 AI 助手装了个结构化记忆库吗?
三种模式,选哪个
Memory Wiki 有三种工作模式,看你的需求选。
isolated 模式,最简单最干净。wiki 用自己的知识库,不依赖任何外部记忆插件。适合刚开始尝试 wiki 功能的人,或者你本来就没用 QMD 这些高级记忆插件。
bridge 模式,稍微复杂一点。它会从活跃的记忆插件里读取公开的制品,比如记忆文件、dream report、daily notes,然后编译到 wiki 里。适合你已经在用 QMD 做记忆管理,但又想要 wiki 的结构化知识层的情况。
unsafe-local 模式,官方自己都说了是实验性的。它允许你直接读取本地文件系统的私有路径。我寻思了一下,这玩意如果不是真有特殊需求,别碰。
我自己用的是 isolated 模式。原因很简单,我先跑通再说,不想一上来就搞复杂的联动。
wiki 长什么样
初始化一个 wiki 之后,它的目录结构是这样的。
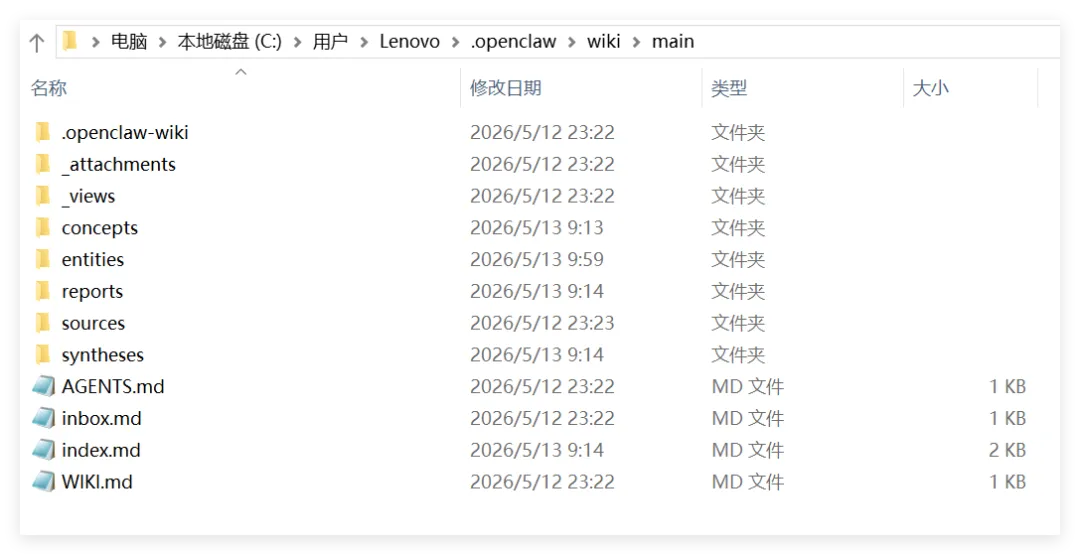
main/ AGENTS.md WIKI.md index.md entities/ concepts/ syntheses/ sources/ reports/ _attachments/ _views/ .openclaw-wiki/你注意看这些目录的名字,它们本身就是一种分类思想。
entities 放的是「事物」,比如人物、系统、项目、设备。比如你有一个实体页面叫 entity.laowang,里面记录了AI探客的所有相关信息。
concepts 放的是「概念」,比如模式、政策、抽象思想。比如 OpenClaw 的技能加载机制、cron 调度原理。
syntheses 放的是「综述」,就是把多个来源的信息编译成一个统一的总结。
sources 放的是「源材料」,导入的原始内容,每个页面都会保留来源元数据。
reports 放的是「报告」,自动生成的 dashboard,包括 open questions、contradictions、stale pages 等等。
你看这个设计,每个分类都有明确的用途。跟你的记忆目录里一锅乱炖完全不一样。
怎么用 wiki 工具
Memory Wiki 提供了几组工具,我用最常用的几个来举例。
wiki_search 和 wiki_get,这两个是查东西的。
你用 wiki_search 搜索的时候,可以指定搜索模式。比如你想找一个人的信息,用 --mode find-person 就会优先匹配别名、昵称、社交媒体账号这些字段。你想找某个问题的答案,用 --mode route-question 会优先匹配 agent card 里的「ask for」提示。
wiki_get 更直接,根据页面 ID 读取内容。比如 wiki_get entity.laowang 就能看到AI探客的完整资料页。你还可以指定从第几行开始读、读多少行,方便只看关键部分。
wiki_apply,这个是写东西的。
它不是让你直接编辑 Markdown,而是通过 API 做精确修改。比如你想给某个实体页面更新一条 claim,或者添加一个问题、标记一个矛盾,都可以用 wiki_apply 完成。这样就不会手抖把 managed block 搞坏了。
wiki_lint,这个是查错的。
跑一遍 lint,它会告诉你哪些页面有结构问题、哪些 claim 缺少证据来源、哪些信息互相矛盾、哪些页面太久没更新了。
我的习惯是,每次做了重要更新之后都跑一遍 lint。就像你写代码改完逻辑跑一遍 lint 一样,不跑心里不踏实。
wiki compile,这个是编译的。
它会把所有 wiki 页面重新编译一遍,生成两份机器可读的文件,.openclaw-wiki/cache/agent-digest.json 和 claims.jsonl。这样 AI 助手不用去翻 Markdown 文件,直接读编译好的摘要就能知道 wiki 里有什么。
如果你开启了 dashboard 功能,compile 还会刷新 reports 目录下的所有报告页面,包括 open questions、contradictions、stale pages 这些。
wiki ingest,这个是导入的。
你可以把本地文件或者网页 URL 直接导入到 wiki 的 source 层。导入的内容会自动保留来源元数据,方便以后追溯。
结构化声明,不只是笔记
这个功能我觉得是 wiki 最核心的设计,值得单独拿出来聊聊。
普通的笔记,你写「AI探客的星座是狮子座」,它就是一行文字。没有来源,没有置信度,没有时间戳。三个月后你再看,你都不知道这条信息是哪里来的、靠不靠谱。
而 wiki 的 claim 系统,让每条信息都自带「身份证」。
一条 claim 可以包含:
一个唯一的 ID,方便引用和追溯。一段文字描述,就是这条 claim 本身。一个状态标记,比如 supported、contested、refuted。一个置信度分数,0 到 1 之间。一个证据列表,每条证据都标注了来源、路径、行号、权重。最后还有一个更新时间戳。
证据本身也有结构。每条证据可以标注它的类型,比如 maintainer-whois、discrawl-stat、manual-review。可以标注它的来源页面 ID。可以标注它在源文件中的具体位置。甚至可以标注隐私等级,比如 public、local-private、sensitive。
你想想看,这跟普通的 Markdown 笔记完全是两个物种。
普通笔记是「我记了,信不信由你」。
wiki 的 claim 是「我记了,来源在这里,置信度 0.9,上次验证是三天前,你判断一下要不要用」。
这就是我前面说的,从笔记堆到信仰层的进化。
自动生成的 dashboard
如果你开启了 render.createDashboards,compile 之后 reports 目录下会自动生成一堆报告页面。
我列几个我觉得最有用的
open-questions.md,列出所有页面上标记了但还没回答的问题。比如你给某个实体页面加了一个问题「这个人的邮箱是什么」,它就会出现在这里,提醒你还没填。
contradictions.md,列出所有互相矛盾的 claim。比如你的 wiki 里同时有「AI探客是狮子座」和「AI探客是处女座」,它会把这两条 claim 和它们各自的来源都列出来,让你去核实。
stale-pages.md,列出太久没更新的页面。如果你三个月前建了一个实体页面,之后再也没碰过,它会提醒你该刷新了。
low-confidence.md,列出置信度低于某个阈值的 claim。这些信息可能不太靠谱,需要你手动确认。
person-agent-directory.md,这个比较有意思。如果你给实体页面加了 person card 元数据,它会自动生成一个通讯录式的目录,方便 AI 助手快速找到谁负责什么。
这些 dashboard 不是一次性生成的,每次 compile 都会刷新。所以你的 wiki 用得越久,这些报告越有价值。
推荐的配置
如果你想试试,我建议的配置是这样的。先只开 wiki,用 isolated 模式
{ plugins: { entries: { "memory-wiki": { "enabled": true, "config": { "vaultMode": "isolated", "vault": { "path": "~/.openclaw/wiki/main", "renderMode": "native" }, "ingest": { "autoCompile": true }, "search": { "backend": "shared", "corpus": "wiki" }, "render": { "createBacklinks": true, "createDashboards": true } } } },}跑起来了之后,再考虑要不要切 bridge 模式跟 QMD 联动。
文章写到这里,我想聊聊我自己的感受。
我一开始觉得 Memory Wiki 就是个花架子。毕竟 OpenClaw 已经有 memory 功能了,再来一个 wiki 不是重复建设吗?
但真正用了一段时间之后,我的看法完全变了。
memory 和 wiki 不是同一个东西的两个版本。它们解决的是不同层面的问题。memory 解决的是「我记得什么」,wiki 解决的是「我知道什么」。
很多 AI 工具的记忆功能,本质就是一个更大的上下文窗口,你记住的东西越多,越难找到对的。而 Memory Wiki 的做法是,别只当记事本,试着当一个知识管理者。
把松散的信息变成结构化的知识,把隐含的矛盾变成明确的待办,把零散的事实变成可追溯的证据链。这不只是给 AI 用的,也是给你自己用的,当你的 AI 助手有了一个靠谱的知识库,它给你的回答质量自然会不一样。
我已收集好了OpenClaw的资料并已打好包,关注后发消息:小龙虾获取。
以上,如果觉得不错,随手点个赞、在看、转发三连吧~谢谢你看我的文章,我们,下次再见。
文章内容基于OpenClaw版本2026.5.7。

我的Openclaw教程